KCCV 참관 후기
안녕하세요, 허재연입니다. 이번에 좋은 기회로 KCCV2023에 참관할 수 있었습니다. KCCV2023은 8.7~8.9(월-수)는 코엑스에서 대면으로 진행되었고, 마지막 날(8.10 목)은 온라인으로 진행되었습니다. 원래는 월요일부터 전부 참석하고 싶었지만 이전에 계획되었던 가족 여행과 겹쳐 8.9일만 코엑스에 가게 되어서 개인적으로 많이 아쉽습니다. 학회에 참석한 것이 처음이기도 하고, 저희 연구실 인원 외 다른 연구자들과 한국어로(!) 질답을 할 수 있는 기회라 저에게는 정말 신선한 경험이었습니다. 아직은 지식이 얕아 발표자들이 하는 설명을 이해하기가 쉽지 않은데, 내년에는 비전 분야 전반에 대한 follow-up을 잘 해두어서 학회를 온전히 즐기고 싶습니다. 개인적으로 많은 동기부여가 되었습니다.

KCCV는 우리가 아는 일반적인 학회와는 약간 다릅니다. 논문을 심사하고 출판하는 형식이 아닌, 세계 우수 학회(NIPS, CVPR, ECCV 등)에 게제된 다양한 논문들을 저자와 교수님들이 직접 발표하며 연구 성과와 굵직한 흐름을 나누는 자리입니다. 논문 저자들과 한국어로 직접 질답을 할 수 있다는 것은 평소 얻기 힘든 좋은 기회입니다. 진행은 초청 발표, 구두 발표, 포스터 발표, 패널 토의 등으로 구성되었습니다. Doctoral Colloquium과 Industry 발표도 있었는데, 월요일에 진행되어 저는 아쉽게도 보지 못했습니다. 구두 발표는 저희가 평소에 하는 세미나와 비슷하게 진행됩니다. 발표자가 20분간 발표 및 질답을 하며, 각 대학 교수님들이 돌아가며 좌장을 맡아 진행하셨습니다. 포스터 발표는 각 연구자가 자신의 연구 성과를 포스터에 압축적으로 정리하여 질문자들과 질답을 하는데, 질문자와 발표자가 이야기 하는 것을 옆에서 듣기만 해도 많은 공부가 되었었습니다.
수요일 학회는 어떻게 진행되었는지 간략히 정리해보겠습니다.
Invited Talk
초청 강연은 UC Berkeley의 Angjoo Kanazawa교수가 ‘From Videos to 4D Worlds and Beyond’라는 주제로 1시간가량 진행하셨습니다. 사정상 zoom으로 발표하셨습니다. 해당 발표를 한 문장으로 요약하자면, ‘image 및 video에서의 4D human perception’ 정도로 표현할 수 있을 것 같습니다. video에서는 사람들의 motion, 위치, pose가 실시간으로 변하며 camera motion도 동시에 변하기 때문에 depth와 scale을 정확하게 탐지하는게 쉽지 않았다고 하며, 해당 문제를 어떻게 풀어나가고 있는지 framework를 강연하셨습니다(중간부터 전혀 모르는 내용이라 깊게 이해하지는 못하고 어떤 흐름이구나 정도만 이해하려 했습니다. NeRF에 대한 이해가 있으신 분들은 재밌게 들었을 것 같습니다). 저희 연구실의 로보틱스 팀 연구원 분들의 연구와 맞닿아있는 느낌을 강하게 받았습니다.
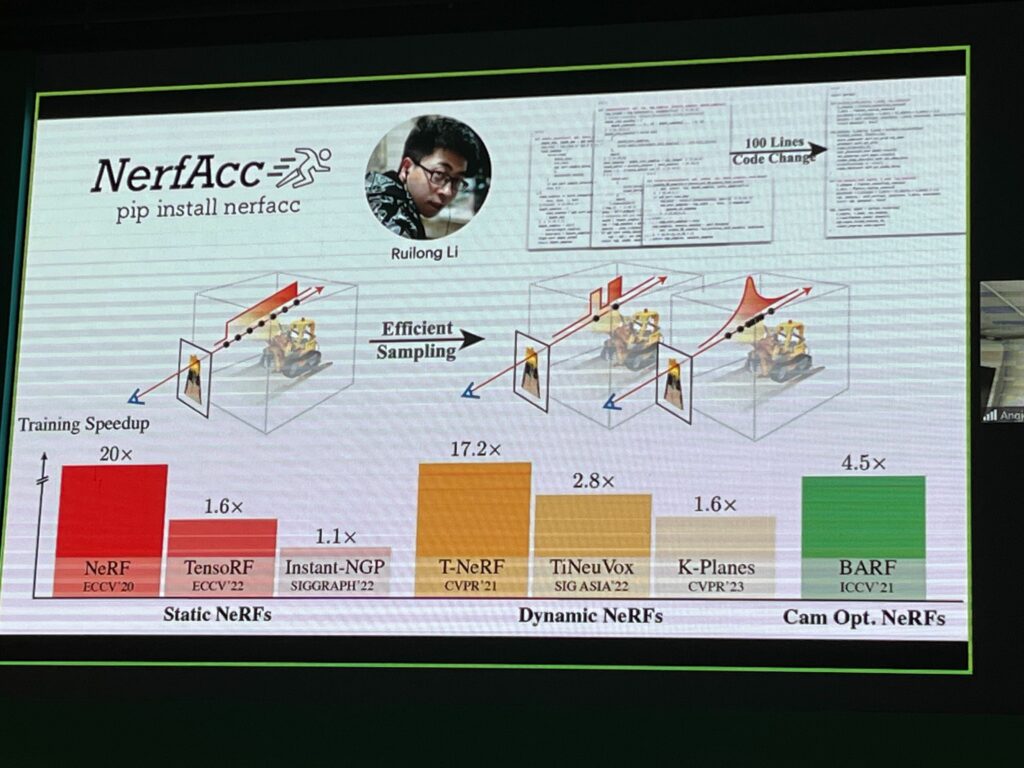
Oral session
초청 강연 이후에는 구두 발표가 이어졌습니다. 구두 발표는 앞에서 말씀 드렸듯 각 논문의 교신 저자로 보이시는 대학 교수님들이 직접 진행하셨는데, 발표자 당 약 20분 간 발표 및 질의 응답 시간이 주어졌습니다. 교수님들의 세미나를 직접 들을 기회는 흔치 않은데, 확실히 발표 진행이 매우 매끄러운게 인상적이었습니다. 기존의 문제가 무엇인지, 어떤 문제를 해결하고자 했는지, 무엇에 집중하고 어떻게 문제를 풀어나갔는지 등등 시간이 허락하는 한 최대한 친절히 설명해주셨습니다. 평소에는 저에게 주어진 공부를 하느라 나무만 보고 있는 느낌이었는데, oral을 쭉 들으면서 비전 연구의 큰 흐름을 약간이나마 느낄 수 있었습니다. 가만히 앉아있으면 계속 좋은 정보들을 떠먹여주시는데 그걸 씹어 넘기지 못하는것이 슬펐습니다. 내년엔 부족한 부분을 더 메꿔서 발표를 잘 이해하는 것을 목표로 해야겠습니다.
저희 분야는 워낙 트렌드가 빨리 변하는것으로 알고 있습니다. KCCV2023 oral발표를 쭉 들으면서 반복되었던 키워드는 ‘multi-modal’과 ‘생성’ 인 것 같습니다. 이외에도 depth estimation, video understanding, human/object reconstruction 등 기존의 주제들이 많긴 했지만 유독 멀티모달과 생성이 눈에 띄었습니다. 언젠가는 저 분야들도 공부를 하지 않을 수는 없을 것 같습니다. 잘 활용하면 좋은 아이디어 소스가 될 수 있을 것 같네요
Panel Discussion

개인적으로 Panel discussion이 가장 재미있는 시간이었습니다. 다섯 패널분들의 토크쇼 같은 느낌으로 진행되었는데, 패널분들이 다루는 주제들이 하나같이 관심이 갈 수 밖에 없는 이야기들이어서 모두 재밌게 들었습니다. 주제는 사진에서 보이다시피 ‘거대 모델 시대에서 AGI로 가기 위한 컴퓨터 비전의 역할과 발전 방향’이었는데, 각 대학에서 비전을 연구하고 계신 교수님, 기업에서 근무하시는 패널, 비전이 전공이 아니신 분들의 다양한 시각이 짬뽕되어 대화가 진행되었습니다. KAIST 권인소 교수님과 함께 한국 컴퓨터비전의 거장으로 거론되시는 이경무 교수님도 계셨습니다(TPAMI 편집장이신걸로 알고 있습니다)
개인적으로 bow나 transformer 등 NLP에서 vision으로 넘어온 방법론들이 많은 부분에서, 왜 비전은 항상 자연어 분야보다 한 발 느릴까? 라는 의문을 평소에 갖고 있었는데, 그 궁금증이 어느 정도 해소되었습니다. 데이터의 특수성에서 비롯된 것인데, 결국 text는 output으로 모델이 어느 정도의 이해력, 성능이 나오는지 직관적으로 어느 정도 파악이 되는 반면(chatgpt한테 말을 걸면 생성해주는 글을 보고 이 친구가 어느 정도의 수준까지 올라왔구나, 이런 부분은 잘 못하네 파악하기 용이하죠), 비전에서는 output의 이미지, 동영상을 보고 이 모델의 표현력, 이해력이 어느 정도인지 NLP보다는 비교적 파악하지 쉽지 않기 때문이라는 말들이 오갔습니다.
점점 모델과 데이터셋이 거대해지며 기업 연구팀 수준에서나 가능한 연구들이 많아지고 있는데, 일반 대학 연구실에서는 이런 문제를 어떻게 풀어나가야 할까? 우리는 어떤 연구를 해야 하나? 라는 주제도 흥미로웠고, 점점 모델과 방법론들이 정교해지고 있으며 대부분 일들은 이것들이 다 해 줄 것인데, 이렇게 빠른 발전 맥락 속에서 비전 연구자들은 이제 뭘 해야하나? 라는 주제도 흥미로웠습니다. 인공지능에게 밥그릇을 뺏기지 말고 이를 도구로 적절히 활용하면 더 의미 있는, 새로운 시도가 가능해질 것이다 라는 방향으로 흘러갔는데, 결국 더 치열한 고민이 요구되고 소수가 독점하는 구조로 가지 않을까 싶네요. 연구원 다들 마음 한켠에 계속 가지고 있어야 할 고민이라는 생각이 들었습니다.
많은 생각 거리를 던져주는 세션이었습니다. 이 세션은 계속 유지되면 좋을 것 같습니다.
Poster session
포스터 세션은 논문 저자가 포스터 앞에서 본인 연구에 대해 질문을 받고 함께 토의하는 세션 입니다. 포스터 세션 시간에는 별다른 발표(oral 등)는 없고 포스터 진행 장소에서 여러 포스터가 동시에 오픈되어 저희는 자유롭게 관심 있는 저자, 연구, 논문, 분야의 포스터를 찾아가 질문하면 되었습니다. 제가 이해할 수 있는 분야는 한정적이어서 representation learning, contrastive learning이라는 키워드를 중심으로 찾아 돌아다녔습니다. 인상적이었던 포스터는 두 개였습니다.
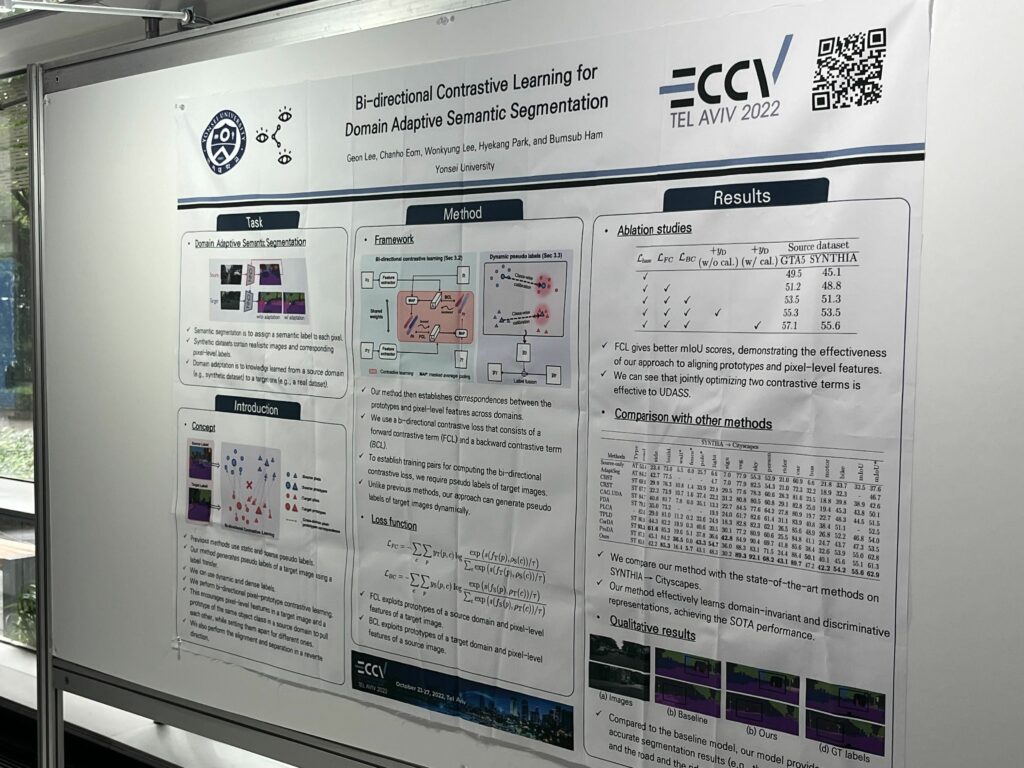
첫 번째 포스터는 ECCV2022에 게제된 ‘Bi-directional Contrastive Learning for Domain Adaptive Semantic Segmentation’이었습니다. 흥미로운 주제였는지 처음부터 끝까지 사람이 많이 몰려있었습니다. 몰려있었는데.. 문제는 어디에도 발표자가 없었습니다. 처음에는 잠시 자리를 비운건가 계속 다시 와봤었는데 끝까지 보지 못했었습니다. 논문의 컨셉같은걸 물어보고 싶었는데 좀 당황스러웠습니다. 어디 가신 걸까요? 결국 해당 포스터에서는 별다른 성과가 없었습니다.

다음 포스터는 KAIST에서 낸, NeurIPS2022에 게제된 ‘Energy-Based Contrastive Learning of Visual Representations’라는 논문입니다. visual representation learning 인데, 방법론을 아주아주 간단히 축약하자면.. 결국 contrastive loss에 항을 하나 더 추가한 EBCLR이라는 방법론을 제안한 것입니다. contrastive learning을 진행할 때 단순히 positive pair끼리는 가까이, negative pair끼리는 멀리 학습 시키는데 이렇게 단순히 거리를 주는 건 말이 안되는것 같으니 의미 있는 거리를 부여하자! 라는 아이디어입니다. 익숙한 주제이기도 하고 신기하기도 해서 꽤 오랫동안 이것저것 물어봤습니다. experiment에 CIFAR, MNIST 등 너무 간단한 데이터셋만 리포팅되어 있어서 이 점을 물어봤는데 iteration의 폭증 때문에 이미지넷 같은 데이터는 학습을 돌려보지도 못했다고 하네요(..) 리소스 한계는 어딜 가든 있나 봅니다.
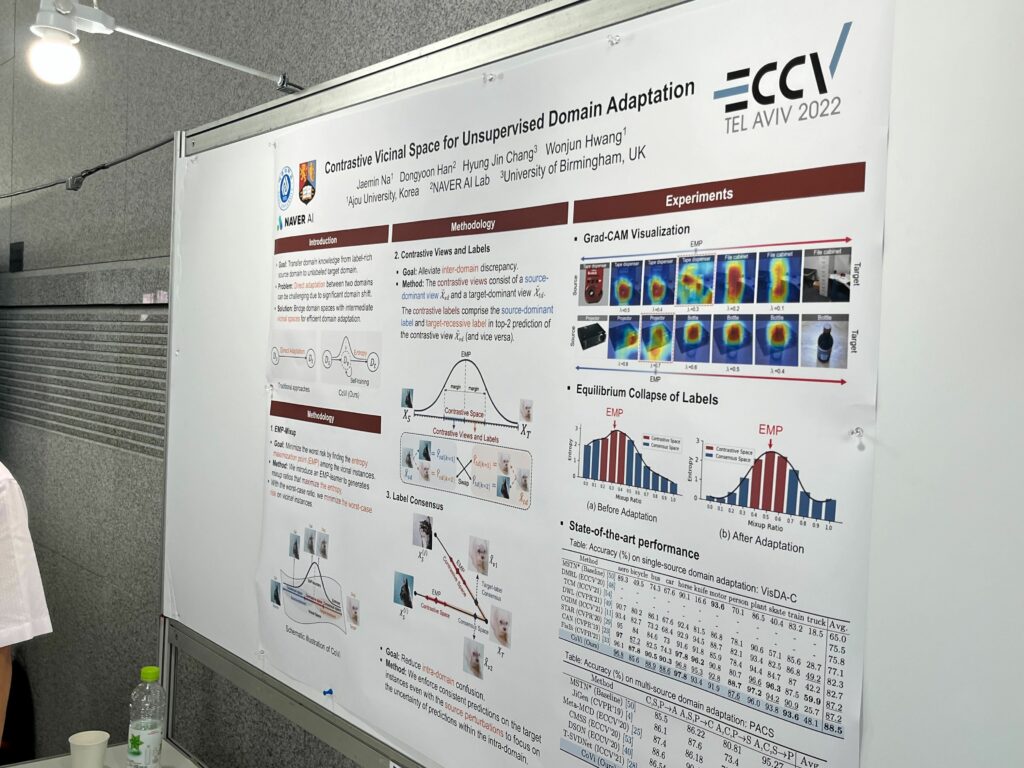
이 포스터는 contrastive 라는 키워드가 있길래 들렀는데, 포스터 앞에 학생이 아니라 교수님이 계셨습니다. 학생이 교수님께 포스터 발표를 부탁드린 것으로 보이는데, 교수님이 가차없이 논문을 디스하시는게 잊을 수 없습니다. 아주대에서 낸 논문이고 ECCV2022에 게제된 논문입니다. contrastive가 제목에 들어있지만 contrastive learning은 사용되지 않고 domain adaptation 논문이었습니다. 이 부분을 발표하시는 교수님이 엄청 지적하셨습니다. 저 말고도 contrastive learning인줄 알고 오신 분이 많긴 했습니다. 방법론 설명을 너무 깔끔하게 잘 하시는데 확실히 다른 학생 발표자와는 달랐습니다. domain adaptation에 관심 있으신 분은 해당 논문을 한 번쯤 살펴보면 좋지 않을까 합니다.
마치며
여러모로 새로운 경험이었고, 동기부여가 많이 되었습니다. 본 것도 많고 느낀 것도 많았습니다. 3일 모두 대면 참석하면 정말 좋았을텐데.. 라는 생각이 들지만 이것도 경험이라고 생각하고 내년에는 준비를 잘 해서 가야겠다 다짐했습니다. 특히 관심 있는 논문은 미리 간단히 읽어두고 가는게 더 의미있는 질문을 할 수 있을 것 같습니다.
마지막으로 함께 가 주신 분들, 이것저것 알려주신 분들, 학회 참관의 기회를 주신 분들께 감사드립니다.