오늘도 SSL 논문들 들고왔는데요. Temporal한 정보를 활용하는 논문의 원조격 논문같더라고요. 그래서 읽어봤습니다.
Introduction
SSL(Self-supervised learning)은 라벨링 없이 학습이 가능하다는 장점 때문에 많은 연구에서 시도되고 있습니다. 비디오에서도 이러한 연구들이 시도되고 있지만, 이미지 대비해서는 아직 갈길이 먼 상황인데요. 기본적으로 이러한 SSL에서 학습하는 방식은 데이터에 대해 spatial transformation(random cropping, horizontal flipping 등등)을 적용해서 “invariance”를 학습함과 동시에 다른 데이터들에 대한 “discriminate”을 학습하는 것입니다.
근데 비디오는 spatial transformation 이외에도 temporal augmentation을 적용해볼 수 있습니다. 그래서 본 논문에서는 알려진 temporal transformation을 이용하여 supervision 형태로 활용하는 것을 제안했는데요.

[그림 1]을 보면 두개의 영상에서 추출한 4개의 영상 클립을 볼 수 있습니다. 같은 다이빙인데… 위의 두 클립과 아래의 두 클립의 시각적인 특징이 다른 것을 볼 수 있는데요. 이러한 관점에서 “motion”정보를 구별하는 것이 중요하다는 것을 알 수 있습니다. (배경에 bias 되지 않고, 액션을 구분하기 위해서는 motion 정보가 중요하다는 뜻) 그래서 본 논문에서는 temporal transformation을 적용한 입력의 “equivariance”한 표현력을 학습하기 위해서 contrastive learning한 접근을 제안합니다.
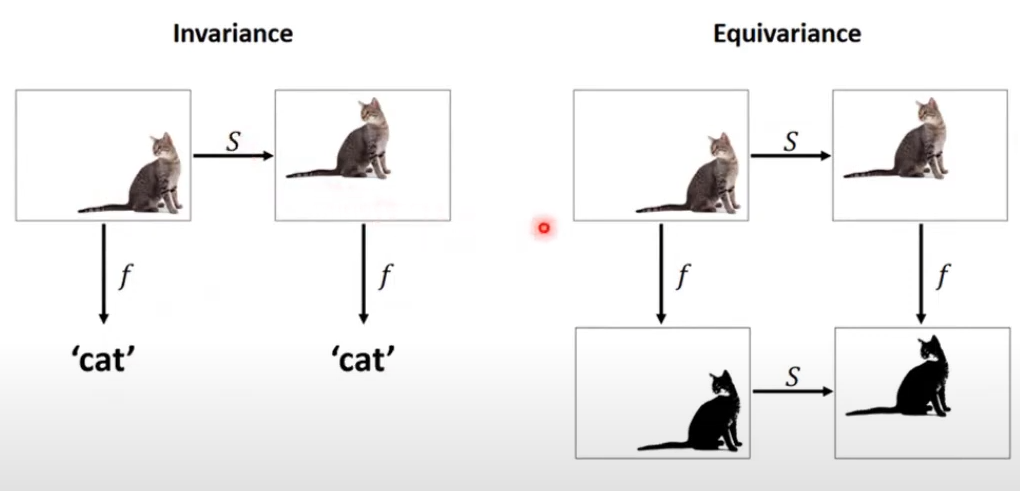
그럼 equivariance는 무엇이길래 학습해야한다는 걸까요? 유튜브 영상에서 예시 그림을 가져왔는데요. Invariance는 CNN의 회전불변성 할때도 나오는 개념이니까 다들 아실 것 같고, 비교를 해서 생각해보면 됩니다. 특정 행동에 대한 움직임은 배경에 종속되지 않고 영상 내의 어느 영역에서도 등장할 수 있습니다. 따라서, equivariance를 학습하면 TASK에 중요한 액션 정보를 잘 학습할 수 있다는 뜻이 되는거죠.
또한, temporal한 학습을 위해서 reverse playback, playback 등과 같은 augmentation 방식들을 이용합니다. (이후에 논문들이 활용하게 된 계기를 제공) 이는 temporal equivariance와 motion 정보의 보존은 성능을 끌어올리기 때문입니다. 하지만 spatial equivariance를 학습하는 것 보다 temporal equivariance를 학습하는 것이 더 어렵다고 하네요. (Motion 정보를 학습하는 것이 중요하지만, random crop 같은 방식을 적용하면 연속적인 motion 정보가 깨지기 때문에 temporal transformation이 더 성능이 좋다고 이해하면 됩니다.)
그래서 논문에서는 3가지 pretext task를 정의하는데요.
- non-overlapping with correct temporal order
- overlapping
- non-overlapping with an incorrect order
를 이용하여 학습하고, playback과 관련된 transformation을 학습하는 분류 문제를 정의해서 기존 연구들에 적용해서 성능 향상을 확인했다고 합니다. 그래서… Contribution을 정리해보면…
- transformation 기반으로 표현력을 학습할 수 있는 contrastive learning 방식 제안
- temporal or spatial transformations의 equivariance가 표현력에 미치는 영향 분석
- temporal equivariance learning을 위한 새로운 pretext task 제안 (clip overlap/order prediction)
- time-equivariant한 표현력을 달성했다는 것을 증명하기 위해, SOTA 성능 보임
Model
Notation이 조금 많아서 유념하고 읽으셔야하는데요… 먼저 데이터셋에 있는 비디오들을 D = \{x_1, x_2, ... , x_N\} 로 표현합니다. 여기서 이제 F가 neural network()고, F(x_i) \in \R^D가 이제 x_i의 학습될 표현력이 됩니다. 여기서 두가지 종류의 tranformation이 적용되는데…
- temporal transformation set T에 해당하는 augmentation을 \tau로 정의
- spatial augmentation and color jittering set S에 해당하는 augmentation을 \sigma로 정의
입니다. 거기에 MLP레이어는 \psi(\cdot)로 정의됩니다.
Temporal Equivariance Learning
해당 방법을 설명하려면 equivariance를 학습하기 위한 기존의 방법들에 대한 간략한 설명이 필요합니다.
- temporal transformation set T가 유한한데, 결과물(\tau_i(x))을 구별할 수 있다면?
- \tau_i(x) 만 가지고 적용된 transformation에 대한 분류 문제로 학습 가능
- 재생 방향이나, 재생 속도 등을 맞추는 문제가 여기에 해당
- \tau_i(x) 만 가지고 적용된 transformation에 대한 분류 문제로 학습 가능
- temporal transformation set T는 유한한데, 결과물(\tau_i(x)) 단독으로는 구별할 수 없다면?
- (x, \tau_i(x)) 페어에 대해 적용된 transformation에 대한 분류 문제로 학습 가능
- Temporal ordering과 같이 순서 맞추는 문제가 여기에 해당
- (x, \tau_i(x)) 페어에 대해 적용된 transformation에 대한 분류 문제로 학습 가능
- temporal transformation set T가 무한하다면?
- 무한하다는 뜻은… 특정 파라미터 값에 의해 무한한 결과값이 나올 수 있다는 뜻인데요. 이 경우에는 이제 (x, \tau_i(x)) 페어에 대해 적용된 파라미터 값 \theta를 regression 하는 문제로 학습이 가능합니다.
이런식으로 학습이 되는데요. 여기까지 읽으셨으면 대충 아셨겠지만… 여기서 contrastive learning은 feature의 표현력에 기반한 학습을 하는것이 목표가 아닙니다. 일반적으로 positive pair끼리는 유사한 영상이니까 유사도가 높게 학습… 뭐 이런 설명을 들어보셨을텐데요. 여기서 positive pair는 이제 같은 temporal transformation이 적용된 영상을 의미합니다. 이건 이제 보다 일반적인 케이스들에서 학습을 수행하기 위해서 equivariance를 학습하기 위함인데요. equivariance가 좀 난해할 수 있는데… “invariance VS equivariance”를 검색하면 자세한 설명이 나옵니다.
Equivariance via Transformation Discrimination
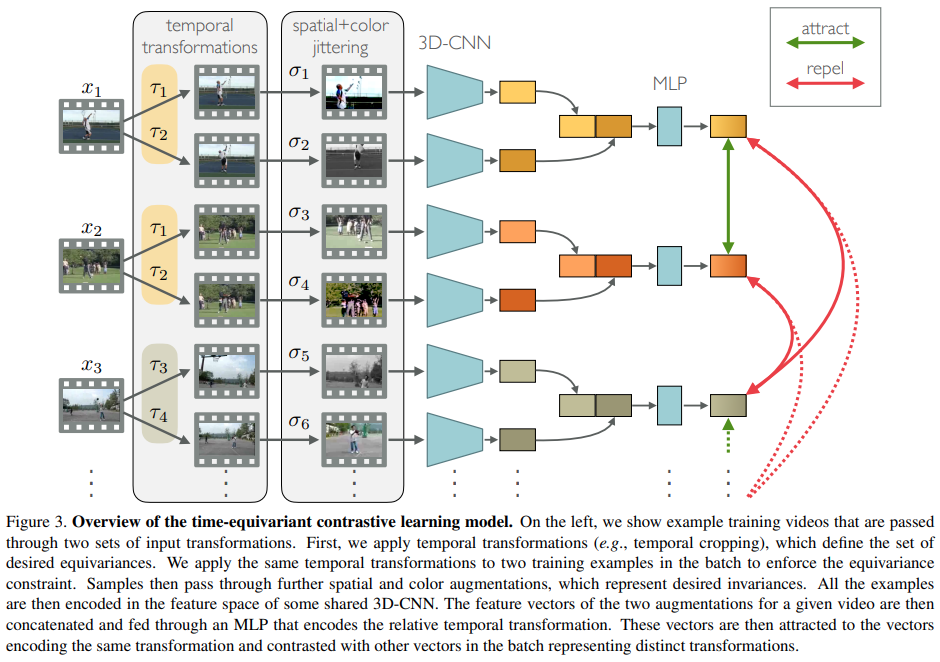
학습되는 전반적인 구조는 [그림 3]과 같습니다. 정말 단순하게 요약하면 temporal transformation은 positive pair 끼리는 같게 주고, negative는 다르게 줍니다. 그리고 spatial transformation은 무조건 다르게 줍니다. 이 상태에서 contrastive learning을 수행하는건데요.
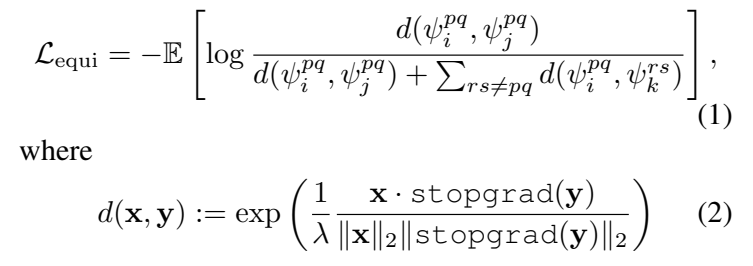
수식으로는 위와 같습니다. \psi는 위의 notation에서도 설명했듯이 MLP레이어인데요. \psi_i^{pq} = \psi([F(\tau_p(x_i))^T,F(\tau_q(x_i))^T]) \in \R^D라는 점을 감안하고 수식을 다시 보면, 같은 영상에 서로 다른 augmentation을 적용한 영상이라는 것을 알 수 있습니다. 이걸 감안하고 [수식 2]를 보면 y에는 백프롭을 막아주는 stopgrad가 적용되어 있는데요. 이건 이제 positive 영상의 그래디언트는 tranformation에서 사용하는 parameter에 영향을 미치지 않게 추가한 부분입니다. 이를 통해서 \tau를 통해서 equivariance를 학습한다고 하네요.
(이건 “SimSiam”의 학습 방법을 생각해보면 되는데요. Simsiam에서도 학습할 때 이와 비슷하게 한쪽 입력에 대해서 gradient가 흐르지 않게 학습합니다.)
Auxillary Temporal SSL Objectives
초기 네트워크에서는 temporal한 특징들을 잘 탐지하지 못해서, Temporal Equivariance Learning만으로는 학습이 어렵다고 합니다. 그래서 이를 보조하기 위한 추가 목표들을 설정해주었는데요. 3개가 있습니다.
- Speed Classification
- playback speed의 변화(1,2,4,8배속)를 분류하는 것으로 학습하는 Task입니다. 각각의 속도에 맞는 non-linear 분류기를 붙여서 학습합니다.
- Direction Classification
- 재생 방향의 변화를 분류하는 Task로 정방향/역방향 재생에 대한 분류기를 이용해서 학습합니다.
- Overlap-/Order Classification
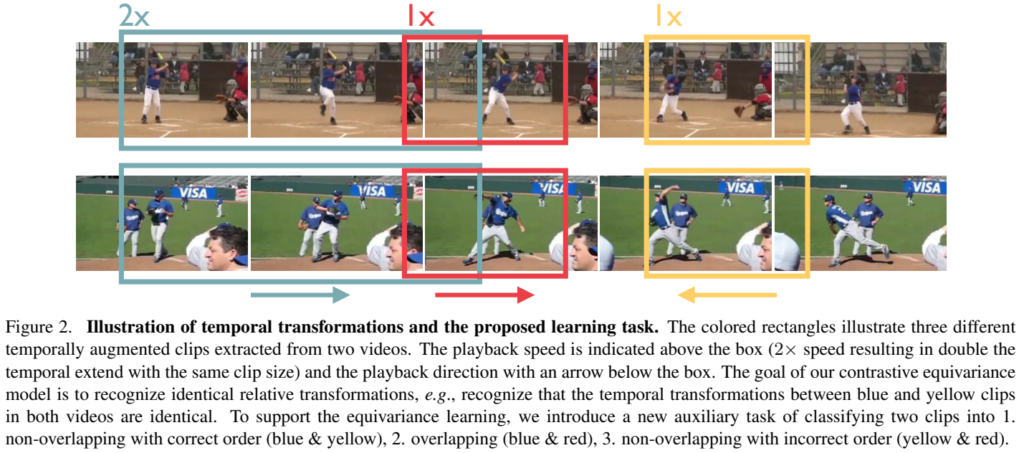
- 이게 이 논문에서 제안하는건데요. 상대적인 시간 변화에 대한 인식을 수행하는 Task입니다. [그림 2]를 보면 되는데요. 에메랄드색과 빨간색을 보면 겹쳐있는 것과 같은 방식을이용합니다. 분류 자체는 임의의 클래스를 정해서 학습하는데요.
- \tau_p(x)는 \tau_q(x)의 앞에 위치한다.
- \tau_p(x)는 \tau_q(x)의 뒤에 위치한다.
- 두개가 살짝이라도 겹친다.
- 와 같이 두 클립 사이의 상대적인 정보를 클래스로 정하고, 이를 바탕으로 학습을 수행합니다.
- 이게 이 논문에서 제안하는건데요. 상대적인 시간 변화에 대한 인식을 수행하는 Task입니다. [그림 2]를 보면 되는데요. 에메랄드색과 빨간색을 보면 겹쳐있는 것과 같은 방식을이용합니다. 분류 자체는 임의의 클래스를 정해서 학습하는데요.
섹션이 나눠져있긴 하지만 pretext task를 몇개 추가로 정의해줬다 정도로 보면 될 것 같네요.
Instance Discrimination Objective
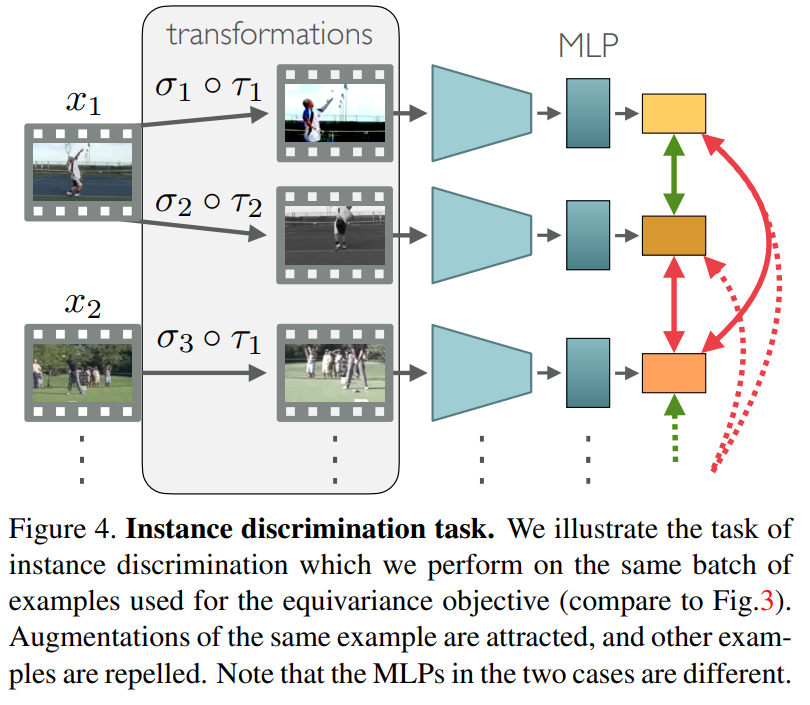
SSL에서는 비디오에 대한 표현력 차이를 학습하는 것도 중요하기 때문에 instance discrimination에 대한 성능도 중요한데요. 따라서 일반적인 instance contrastrive loss도 사용합니다. [그림 4]와 같이 사용하는데요. 이 경우는 다른 방법론들과 똑같이 같은 비디오에 서로 다른 augmentation을 줘서 생성한 페어를 positive로 두고, 아닌 비디오는 negative로 둡니다.
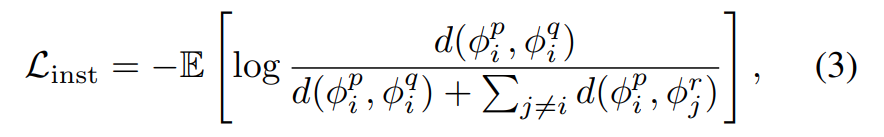
수식으로 보면 [수식 ]3과 같은데, 일반적인 InfoNCE Loss입니다. 앞선 Loss들이랑 다르게 얘는 정말 feature representation으로 학습을 수행합니다.
Experiments
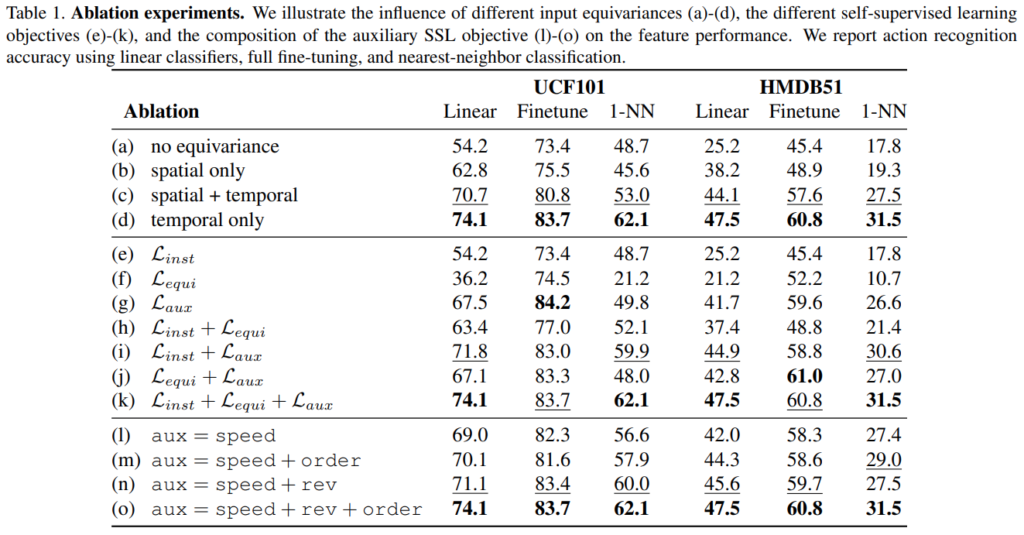
[표 1]은 ablation 실험 결과인데요. 논문에서 중요하게 강조하는게 “Equivariance vs. invariance”라고는 하는데, [표 1-(a)~(d)]를 보면 됩니다. 결론적으로 temporal equivariance과 spatial invariance를 같이 학습하는 모델이 제일 성능이 좋았다고 합니다. (c)의 경우가 temporal equivariance과 spatial equivariance를 같이 학습한 경우인데 오히려 성능이 안좋았습니다.
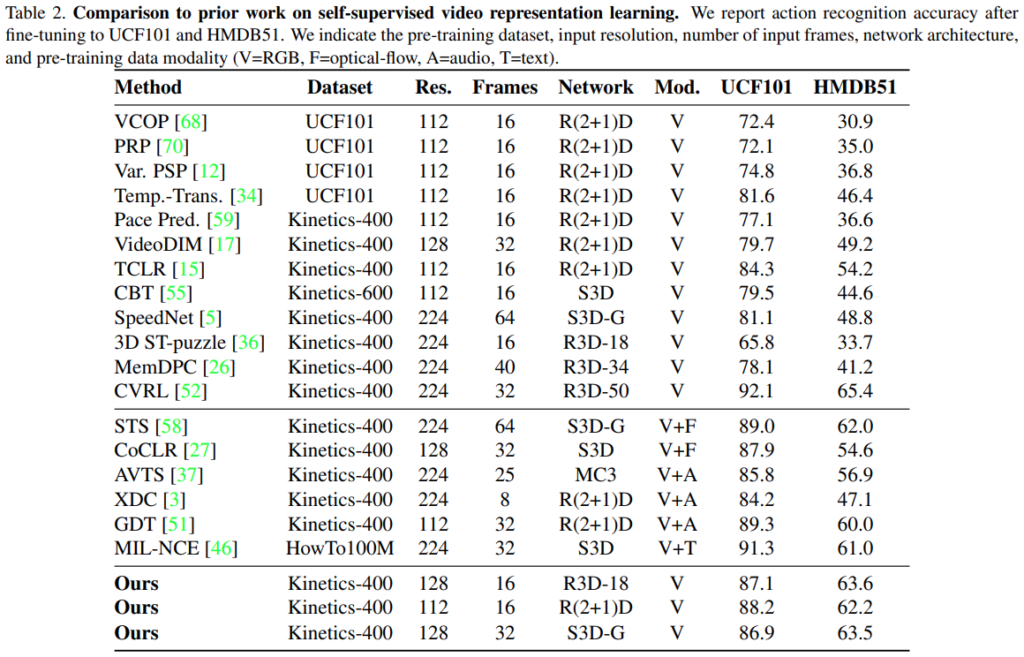
[표 2]는 action classification에서의 벤치마크인데요. 제안하는 방법론이 SOTA… 는 아닌 것 같은데… 비교가 좀 어렵게 실험을 해서 대충 어림짐작 해보면 비슷한 성능같긴한데 모르겠네요. 논문 저자들도 이 부분에 대해서는 Fair comparison이 좀 어렵다고 리포팅하고 있는데요. 논문 내용 읽어보면 이정도는 맞출 수 있었을 것 같은데 이상하네요.
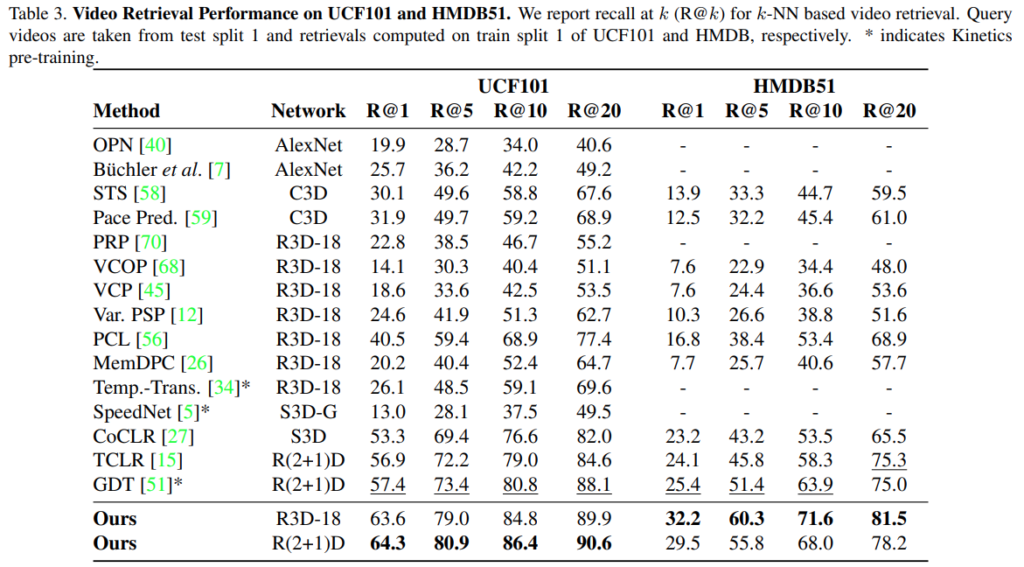
[표 3]은 Retrieval에 대한 벤치마크인데, 여기서는 확실히 좋은 성능을 보입니다. 분류랑 학습 목표가 비슷하긴 하지만 retrieval이 feature 표현력을 보는 성능 지표가 될 수 있는데요. 이러한 결과를 통해서 Temporal equivariance과 instance discrimination의 학습이 표현력 향상에 큰 도움이 되었음을 입증합니다.
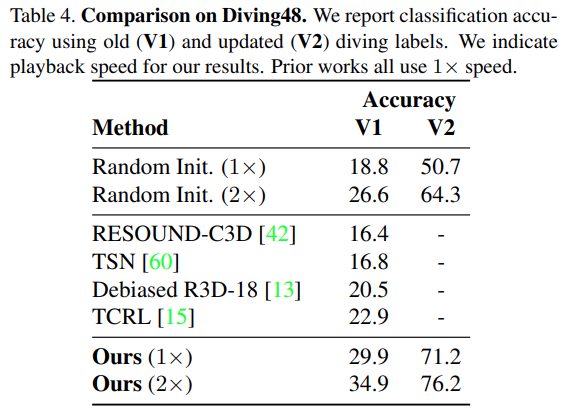
논문 첫페이지에 있는 다이빙 데이터셋에서도 좋은 성능을 보입니다. 잘 안쓰는 데이터셋이라 참고만 하시면 됩니다.
21년도 논문이라 그런지 temporal 차원에서의 간단한 pretext task를 가지고 당시에는 좋은 성능을 보여주고 있네요.
궁금한건 제 생각엔 비디오에서 정적인 구간에 대해서는 효과가 없을 것 같은데 저자가 밝히는 limitation이 따로 있을까요?
저자가 밝히는건 따로 없는데, 제가 읽은 바로 생각해봤을 때 정적인 구간에서도 모션 자체는 정적이지 않아서 아마 성능이 오르긴 할 것으로 생각됩니다. 영상이 정적이라는 것도 제가 리뷰한 적 있긴 한데, 어떻게 보면 그 정적이라는 것도 한정된 데이터셋 내에서 학습하다보니 하나의 정보가 되는 것 같습니다.
안녕하세요 좋은 리뷰 감사합니다.
리뷰 중간 equivariance를 학습하기 위한 loss에서 tranformation에서 사용하는 parameter에 영향을 미치지 않게 stopgrad를 추가하였다고 이해했습니다. transformation이 곧 augmentation과 같은 것으로 생각되는데, augmentation 과정에 관여하는 parameter나 layer에는 어떤 것이 있나요? 파라미터 기반으로 수행되는 augmetnation이 잘 떠오르지 않아 질문 드렸습니다.
tranformation이 augmentation은 맞습니다. augmentation에 관여하는 레이어는 없고 파라미터는 현우님이 아시는 crop 어떤 비율로 할지 같은 그런 랜덤 하이퍼 파라미터가 있다고 생각하면 됩니다. 설명이 파라미터라 그렇지, 레이어에 영향주는 파라미터는 아닌데 좀 그렇게 읽혔나보네요. (입력 데이터 augmentation의 파라미터만을 말함) Stopgrad는 Positive에서 학습하는 gradient를 모델에 학습에 반영하지 않게 하기 위해서인데요. 이건 이미지 기반 SSL에서 그렇게 했을때 성능이 좋았다를 기반으로 하는거라… SimSiam 리뷰 읽어보시면 왜 그렇게 했는지 이해가 가실겁니다.