오늘은 다소 예에에전 논문을 가져왔습니다. Active learning 의 조상님과 같은 연구인데요. 근본 중의 근본임에도 불구하고 아직 제대로 읽어보지도 리뷰해본 적도 없다는 사실이 제법 놀랐네요. Active Learning에 대해 모르시는 분들은 아래 리뷰들을 참고부탁드립니다. 바로 본격적인 리뷰에 들어가보도록 하겠습니다.
- [NeurIPS Workshop 2020] On Initial Pools for Deep Active Learning 중 Background 부분에 Active Learning 에 대해 자세하게 다루었습니다. 본 리뷰에서는 Active Learning의 배경 지식은 생략하오니 참고해주시기 바랍니다~

- Paper: [ICML 2017] Deep Bayesian Active Learning with Image Data [바로가기]
- Author Video: None
- Code: None
Introduction
우선 해당 논문이 발표된 시기는 2017년으로 본격적인 딥러닝 분야의 연구가 시작된 때입니다. 그와 동시에 대부분의 연구에서는 대규모 데이터셋을 다루게 되었습니다. 그러나 이 시기가 워낙 초창기이다 보니, 대부분의 Active Learning 연구는 이미지와 같은 고차원의 도메인이 아닌 저차원 도메인의 데이터에 집중하여 연구가 진행되고 있었습니다. 그리고 드디어 등장한 CNN은 저자로 하여금 Image 데이터셋에 적합한 Active Learning 연구를 진행하도록 이끌었습니다.
결국 이런 흐름에 따라 저자가 하고 싶은 연구는 “딥러닝을 활용한 이미지 데이터셋 기반의 Active Learning” 이라고 할 수 있겠네요. 그러나 이를 바로 적용하기에는 어려움이 하나 있었는데, 그건 바로 ‘모델의 불확실성 표현법’ 입니다. Active Learning 에서는 라벨링이 필요하다는 기준을 *acquisition function (sampling metric) 이라고 합니다. 이 acquisition function 은 대부분 모델의 불확실성을 기준으로 설계가 되지만, 저자가 말하길 딥러닝 모델은 불확실성을 표현할 수가 없었다고 합니다. (그런데 왜 불확실성을 표현하는 것이 불가능한지 저도 의문이긴 합니다.. )
*acquisition function 에 대한 설명은 [NeurIPS Workshop 2020] On Initial Pools for Deep Active Learning: Background-[2.Selection] 참고
따라서 저자는 이를 해결하기 위해 Bayesian convolutional neural networks (BCNN) 이라는 특수 모델을 사용하여 새로운 Active Learning 파이프 라인을 제안하였습니다. 결국 초창기 딥러닝 기반의 Active Learning 연구 제안하기 위해 BCNN을 사용하였다고 요약할 수 있을 것 같습니다.
Bayesian Convolutional Neural Networks
저자는 우선 우리가 알고있는 CNN의 장점을 설명하면서, CNN을 사용하려는 이유에 대해 설명합니다. 공간 정보를 고려할 수 있다 와 같은 얘기를 말이죠! 그리고 그 중에서 저자는 Bayesian equivalent of CNN이라는 구조를 사용하였습니다. (이건 큰 관점에서 봤을 때 동작 원리는 CNN 과 동일합니다.) 베이지안 CNN 모델에서 inference를 수행하기 위해, 모델을 정규화하는 데 사용되는 dropout과 같은 확률적 정규화 기법을 사용합니다.
좀 더 공식적으로 학습방식에 대해 접근해봅시다. Train dataset D_{train}가 주어졌을 때, 실제 모델 posterior p(ω|D_{train})에 대한 KL-divergence를 최소화하는 학습 가능한 distribution q_θ^∗(ω)를 찾는 것과 동일합니다. 여기서 dropout 은 variational Bayesian approximation로 해석할 수 있는데, approximating distribution는 분산이 작은 두 가우스 분포가 혼합되어 있고 가우스 분포 중 하나의 평균은 0으로 고정되어 있습니다. 따라서 가중치의 불확실성은 몬테카를로 적분을 사용하여 posterior에 대한 예측 불확실성을 유도할 수 있다고 합니다. 이에 대한 수식은 아래와 같습니다. 결국 이러한 이유로 저자는 BCNN이라는 구조를 사용하여 불확실성을 유도하고자 하였습니다.
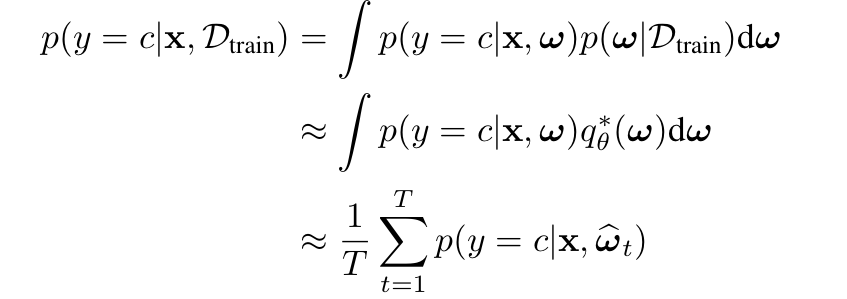
따라서 이런 BCNN을 활용하면 불확실성 정보가 표현되기 때문에, 기존 연구되고 제안된 acquisition function을 함께 사용할 수 있습니다.
Acquisition Functions
이번 섹션에서는 이미지 데이터에 적합한 다양한 Acquisition Functions들에 대해 설명합니다. 즉, 기존에 제안된 불확실성을 사용한 Acquisition function들은 무엇이 있고 간단하게 어떤 특징이 있는지를 다룹니다.
- Max Entropy: 최대의 예측 엔트로피를 가지는 데이터를 쿼리하는 방식입니다. 수식은 아래와 같습니다. 가장 대표적인 불확실성을 나타내는 지표 엔트로피를 사용하는 방식입니다.
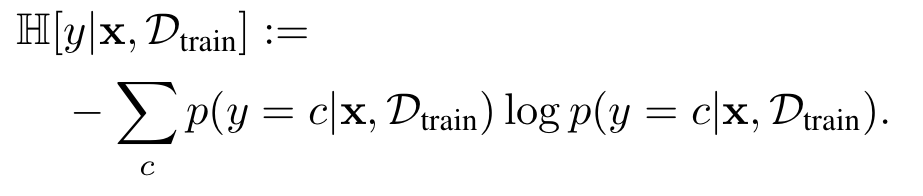
2. BALD라고 불리는 모델 파라미터에 대해 얻은 정보를 최대화할 것으로 예상되는 데이터를 선택하는 기법입니다. 이를 위해 예측과 모델 posterior 분포 사이의 상호 정보량을 최대화하는 방식입니다.
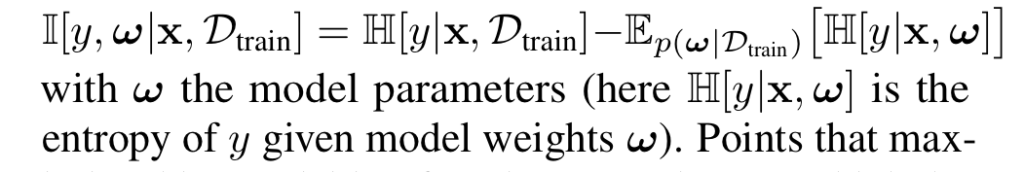
3. Variation Ratios를 최대화하는 기법입니다. 1번인 맥스 엔트로피와 마찬가지로 이 기법은 불확실성을 나타냅니다.
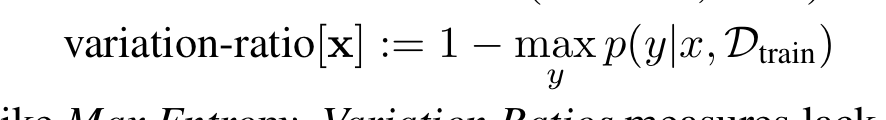
4. mean standard deviation (mSD)를 최대화 하는 기법입니다.
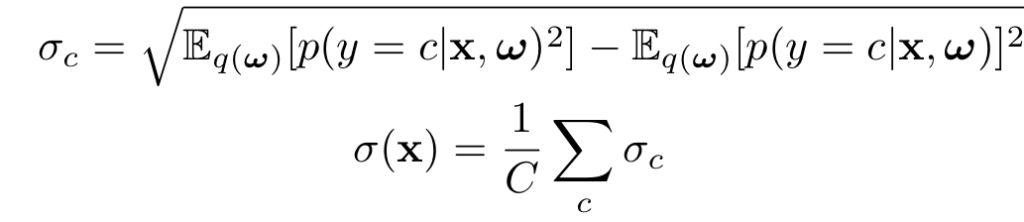
5. Random. 말그대로 임의의 점을 선택하는 기법입니다.
결국 저자는 기존에 사용하던 4개의 acquisition function을 어떻게 사용할 수 있을지에 대해 고민했고, 그에 대한 답으로 BCNN을 선택한 것이라고 할 수 있습니다. 사실 1번과 5번을 제외한 나머지 기법들은 조금 낯설긴 합니다. 최근에는 흔히 사용하는 기법이 아니기에..
Active Learning with Bayesian Convolutional Neural Networks
이제 본격적으로 BCNN을 적용한 Active Learning 결과에 대해 리포팅하는 섹션입니다. 베이지안 CNN 불확실성을 기반으로 하는 다양한 acquisition function 들을 간단한 이미지 분류 결과와 함께 동일한 acquisition function를 결정론적인 CNN에서 모델의 불확실성 중요성을 살펴보았습니다. 다음으로 SVM을 기반으로 한 이미지 데이터의 그 당시 활발하게 제안된 학습 기법과 비교하였지만, 저는 본 리뷰에서는 다루진 않겠습니다. 뿐만아니라 저자는 semi-supervised learning 기법과도 비교합니다. 이러한 학습 기법은 Active Learning 모델보다 훨씬 많은 데이터(unlabeled data)에 접근할 수 있지만, 비교적 유사한 결과를 보였다고 합니다.
Comparison of various acquisition functions
앞서 언급한 acquisition function들을 비교하기 위해 MNIST에 대한 실험 결과를 보여드리겠습니다. 신기하게 이 당시에는 모델 구조를 하나하나 서술을 하네요ㅎㅎ: convolution-relu- convolution-relu-max pooling-dropout-dense-relu-dropout- dense-softmax, with 32 convolution kernels, 4×4 kernel size, 2×2 pooling, dense layer with 128 units, and dropout proba- bilities 0.25 and 0.5
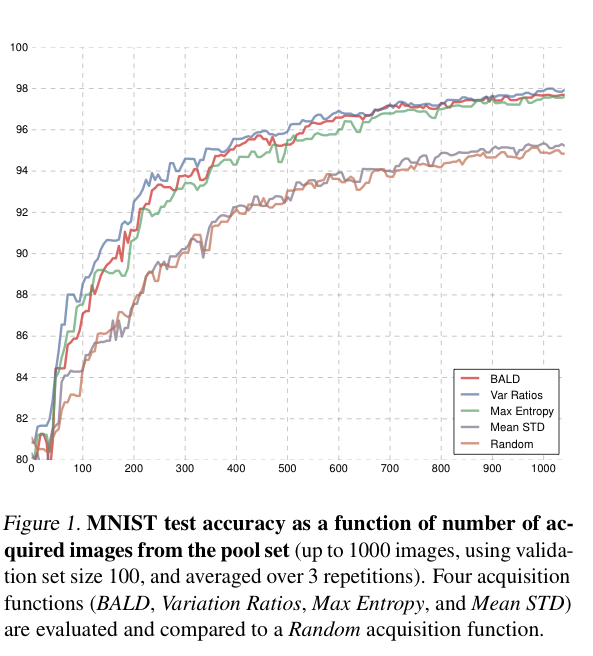
초기 데이터셋으로는 20개의 데이터만을 사용하였으며, 100개의 validation set, 1000개의 test 셋으로 실험을 진행하였습니다. 그리고 100개씩 데이터를 추가하고 10번 반복한 실험이 아래와 같습니다.
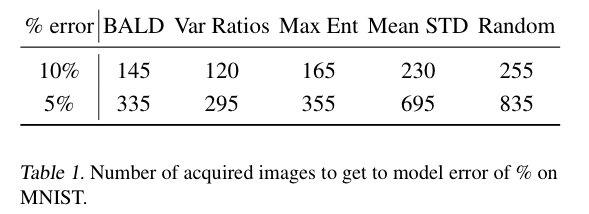
실험으로는 앞섹션에서 설명한 5개의 acquisition 함수들인 BALD, Var Ratio, Max Entropy, Mean STd, 그리ㅗㄱ ranodm을 비교하였습니다. 그 결과 아래 [그림 1]과 같이 Random과 mean STD는 BALD, Variation Ratios, Max Entropy에 비해 성능이 떨어지는 것으로 나타났습니다. Variation Ratios는 BALD 와 최대 엔트로피보다 더 빨리 높은 성능을 보입니다. 무작위로 샘플링하는 Random과 mean STD가 비슷한 성능을 보이는 것도 인상깊었습니다. 마지막으로 [표 1]에서는 5%와 10%의 테스트 오류에 도달하는 데 필요한 단계 수를 제공합니다. 표에서 볼 수 있듯이 BALD, Variation Ratios 및 최대 엔트로피는 mean STD 및 random보다 훨씬 적은 수의 데이터셋으로도 적은 오류를 달성하였습니다. 이 표는 결국 데이터 효율성의 중요성을 보여준다고 할 수 있습니다. 예를 들어 Variation Ratios 모델을 사용하는 전문가는 random하게 새 이미지를 얻을 경우 라벨링해야 하는 이미지 수의 절반도 채 되지 않기 때문이죠.
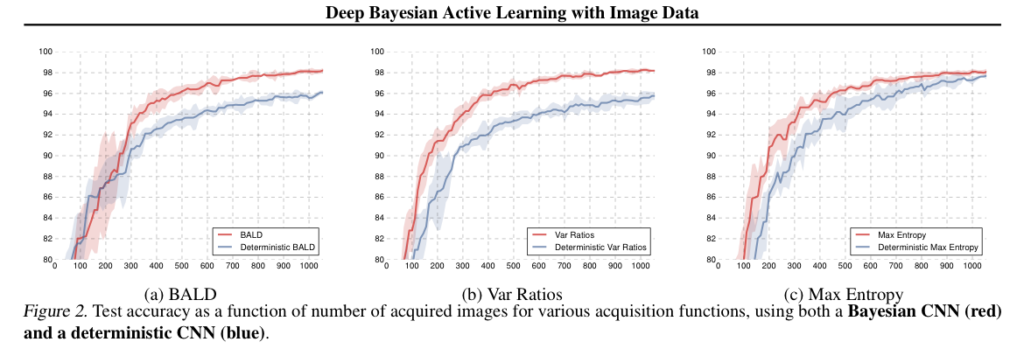
Importance of model uncertainty
저자는 세 가지 획득 함수(BALD, 변동 비율, 최대 엔트로피)를 평가하여 베이지안 CNN에서 모델 불확실성의 중요성을 평가하였습니다. 이 챕터로부터 보여주고 싶은 건 결국 불확실성이 얼마나 중요한지에 대한 이야기입니다. [그림 2]에서 바로 그 결과를 확인할 수 있는데요. 베이지안 모델은 모델 전체에 불확실성을 전파하여 초기에 더 높은 정확도를 달성하고 전체적으로 더 높은 정확도를 달성하였습니다. 저자는 이에 대해 베이지안 모델 전체에 전파하는 불확실성이 모델의 신뢰도 측정에 상당한 영향을 미친다는 것을 보여준다고 합니다.
Comparison to semi-supervised learning method
라벨링 코스트라는 문제점에서 시작된 연구는 AL 말고도 Semi-supervised learning이 있습니다. 저자는 이 semi-supervsied leanring 과의 비교를 통해 저자가 제안하는 방법론의 효과를 어필하고자 하였습니다.
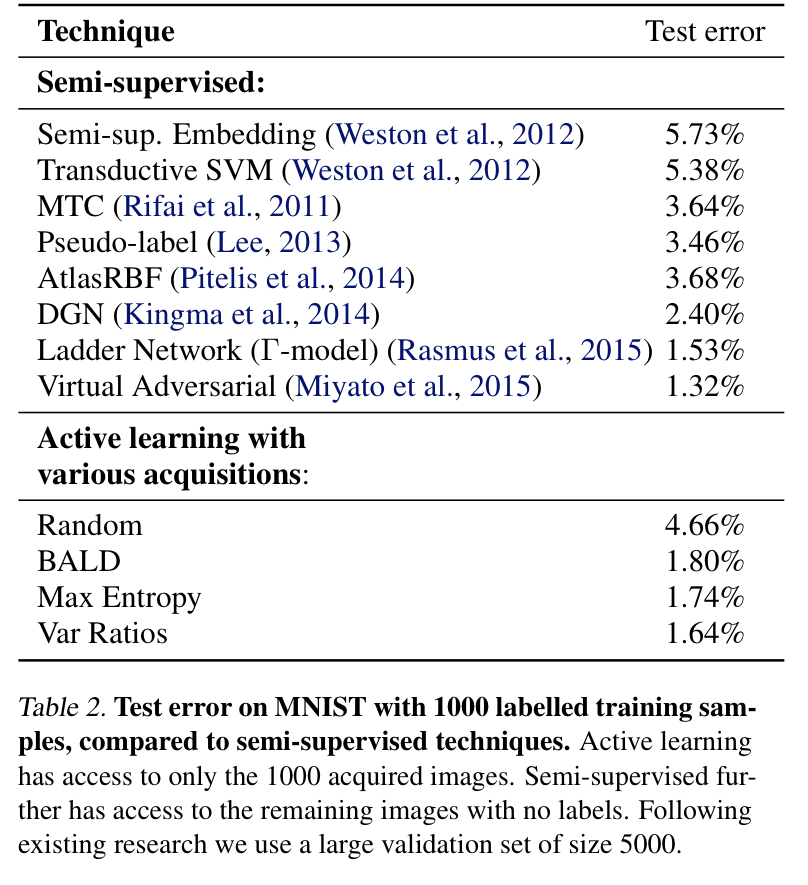
이를 위한 다양한 acquisition fucntions함수를 사용하는 AL 모델(1000개의 초기 데이터셋세)과 semi-supervised model 대한 error를 [표 2]에서 확인할 수 있습니다. 저자가 제안하는 방식은 semi-sueprvised learning 모델들과 비슷한 성능을 달성합니다. 그런데 저자는 저자가 제안하는 모델은 훨씬 가볍다는 점을 강조하였습니닏. Ladder Network는 labeled 1000개와 unlabeled 59,000개로 0.84%의 error를 달성했는데, 이를 active learning 설정과 동일하게 설정하고 성능을 비교해보면, Γ-모델의 error 1.53%인데 반해, 저자가 제안한 방법 중 Var Ratio를 사용한 경우 error가 1.64% 라는 점에서 훨씬 가벼운 모델임에도 불구 성능이 비슷하다고 주장하였습니다.
결국 이 논문은 AL에 베이지안 CNN을 적용하였다고 요약할 수 있을 것 같습니다. 뭐 그렇게 대단한가 싶을수 있겠으나 Active Learning 연구도 활발하지 않았던 때라 그 신선함에서 많은 점수를 받을 수 있지 않았나 싶습니다. 물론 해당 논문을 리뷰하면서 새로운 접근법 혹은 인사이트를 얻었다고 할 순 없습니다만, 요즘 기존 연구들을 정리하고 있는 시간을 가지고 있었기에.. 유의미한 시간이지 않나 싶습니다. 다음엔 조금더 유익하고 자세한 리뷰로 찾아오도록 하겠습니다.
안녕하세요 홍주영 연구원님 좋은 리뷰 감사합니다.
모델 불확실성의 중요성에 관한 실험 부분에서 Baysian CNN과 통상적인 CNN의 accuracy를 비교하는 그래프는 여러 번의 실험을 수행하고 그 평균값을 리포팅한 것인가요? 또 Max Entropy를 사용한 실험 결과는 다른 두 방법과는 달리 BCNN과 CNN의 accuracy가 수렴하는 모습을 보이는데 이를 불확실성의 영향을 덜 받는다고도 해석 할 수 있는지도 궁금합니다. Acquisition function중 max entropy를 제외한 방법론은 잘 사용되지 않는다고 하셔서 왜 그런지도 궁금하네요.
1. 네 3번의 실험 결과를 낸 뒤 평균을 리포팅한 것입니다.
2. 해당 테이블만 비교해봤을 때, 그렇게 해석할 수도 잇을 것 같습니다. 다만 저자가 그에 대한 자세한 언급은 없어서 아쉽네요
3. 최근에는 기존에 제안된 acquistion function이 아닌 저자가 직접 제안한 함수들을 사용하기 때문입니다.
안녕하세요, 홍주영 연구원님, 좋은 리뷰 감사합니다.
지금이야 DL 연구가 워낙 활발하지만, 초창기 논문은 지금과 감성(?)이 약간 다른 게 신선했습니다. 이 논문은 불확실성을 도입하기 힘든 Deep Learning에 acquisition function을 효과적으로 얻기 위해 베이지안 CNN을 적용하였다 정도로 이해할 수 있을 것 같습니다. 하지만 중간에 나오는 acquisition function은 잘 이해하지 못했습니다.. KL-divergence, 몬테카를로 적분 아직 제가 잘 모르는 수식이 나와 깊이 이해하기 힘들었습니다. 공부를 열심히 해서 이런 부분들을 채워나가야 할 것 같습니다.
Figure1에 보면 random과 mean STD의 성능이 비슷한데, 혹시 논문에 mean STD의 성능이 좋지 못한 이유에 대한 설명이 언급되어 있나요?
제가 해당 내용에 대해 조금 더 작성을 했어야 했는데 아쉽네요. 베이지안 네트워크에 대해서는 조금더 보충해서 재연님이 이해할 수 있도록 보충해두겠습니다.
이제 질문에 대해 답변드리자면, 저자와 동일한 부분에 대해서 언급했지만 분석에 대해서는 ‘랜덤과 meanSTD는 특이하게 저조한 성능을 보인다’ 정도로만 언급하고 유의미한 얘기를 하진 않았습니다.
좋은 리뷰 감사합니다.
1. 혹시 BCNN이 inference를 위해 dropout을 사용한다고 말씀해주신 부분에 대해 조금 더 추가로 설명해주실 수 있으신가요?
2. 그리고 BCNN이 아닌 일반 deterministic CNN에서 각 acquisition function의 수식은 posterior 확률 대신 p(y=c) 이런 식으로 대치되는 경우라고 생각하면 되는건가요?? BCNN에 대한 이해가 깊지 않아 질문이 좀 얕을수도 있습니다..