이번 리뷰에서 다룰 논문의 제목은 <Self-Supervised Spatiotemporal Representation Learning by Exploiting Video Continuity>로, 2022년 AAAI에 게재되었습니다.
원래는 저번 X-Review에서 Part.1까지만 작성되어 있던 논문의 뒷부분을 마무리하려 했는데, 방법론 중에 설명이 잘 납득되지 않는 부분이 있어 추후 정식 publish가 되면 다시 정리하여 작성하도록 하겠습니다.

해당 논문에서 수행하는 task는 제목에서 알 수 있다시피 Self-Supervised Video Representation Learning(SSVRL)이고, 아무 annotation이 없는 비디오로부터 어느 downstream task에 적용해도 잘 동작하는, 즉 일반성을 갖춘 feature를 추출하는 것이 목적입니다.
본 논문에서는 Action recognition, Video retrieval, Action localization으로 성능을 측정하고 있고, 이러한 downstream task에서 잘 작동하는 feature를 추출하기 위해 “Video continuity”를 키워드로 삼고 있습니다.
그럼 바로 논문의 Introduction을 살펴보겠습니다.
1. Introduction
기존 Self-supervised learning 연구 흐름이 Contrastive learning과 Pretext-task 두 갈래로 나뉜것은 SSVRL 연구에서도 그대로 적용되었습니다. 각각을 간단히만 설명드리고 넘어가겠습니다.
Contrastive learning based methods
Contrastive learning 기반의 방식은 비디오를 클립으로 쪼개어 하나의 클립을 anchor로 둔 후 다른 클립들을 저자의 기준에 따라 positive 혹은 negative로 지정한 뒤 클립 feature간의 거리를 조절하며 instance discrimination을 수행하는 것입니다.
대표적인 방법론들을 간단하게만 소개해드리자면,
- 비디오 내에서 시간적 거리가 적절히 가까운 클립일수록 positive로, 먼 클립일수록 negative로 두고 InfoNCE loss를 적용하는 CVRL(이광진 연구원님의 리뷰)
- 비디오의 RGB, flow feature를 가지고 있을 때 각자의 positive와 negative를 서로 다른 모달의 정보를 활용해 찾아오는 CoCLR
가 있었습니다.
Pretext task based methods
그와는 다르게 Pretext-task 기반의 방법론들은 unlabeled 비디오로부터 임의로 얻어낼 수 있는 라벨을 활용해 backbone network의 표현력을 학습하는 방식입니다. 비디오의 특징인 시간 축을 잘 활용하여 원본 비디오의 클립 순서를 섞은 뒤 모델이 실제 순서를 맞추게하거나, sampling rate를 임의로 다르게 적용한 후 빠르게 또는 느리게 재생되는 듯한 비디오의 sampling rate를 맞추는 등의 다양한 방법론들이 존재하였습니다.
더 많은 방법론들은 제 X-Review나 다른 연구원분들의 X-Review에 소개되어 있으니 궁금하신 분들은 참고하시기 바랍니다.
본 논문에서는 두 갈래 중 Pretext-task 기반의 방법론을 소개하고 있습니다.
기존 pretext task 기반의 방법론들에서 소개된 비디오의 순서를 맞추거나 속도를 맞추는 방식은, 사람의 시각 인지 시스템의 작동 방식으로부터 영감을 얻은 것이라고 합니다. 이러한 관점에서 문제를 해결하고자 한 이전 방법론들이 좋은 결과를 만들어냈고 발전을 이뤄냈다는 점에 착안하여, 저자는 모델이 사람의 시각 인지 시스템과 더욱 유사한 방식으로 동작할수록 일반성을 갖는 feature를 추출할 수 있을 것이라고 생각합니다.
그렇다면 인간의 인지 과정에서는 필수적이면서, 모델이 갖춘다면 도움이 될만한 포인트는 무엇이 있을까요?
인지 과학에서는 실제로 사람이 시각 환경에서 무언가를 지속적으로 인지하고 이해할 때, 시간적인 연속성이 중요한 역할을 수행한다고 합니다.

그림 1에서는 “멀리 뛰기” action에 대한 비디오가 재생되고 있는데요, 노란 테두리가 쳐진 프레임에서는 도움닫기가 진행되다가 빨간 테두리가 쳐진 프레임들에서는 실제 멀리 뛰는 모습을 볼 수 있습니다. 이 때 빨간 프레임들을 잘 보시면 도움 닫기 후 점프를 시작하자마자 다음 프레임에서 착지를 준비하는 모습을 볼 수 있습니다. 아래 초록 테두리에 해당하는 중간 과정의 프레임들이 잘린 것입니다.
만약 사람이 비디오를 보다가 저렇게 불연속적인 빨간 프레임들을 봤다면 바로 뭔가 이상함을 느낄 수 있겠죠. 그리고 이러한 불연속적 프레임에 대해 이상함을 느끼는 이유는 사람이 “멀리 뛰기”라는 action에 대한 의미론적 과정을 파악하고 있어서, 내가 현재 보고 있는 비디오에 대한 시간적 연속성을 바탕으로 기대하던 장면이 매끄럽게 나오지 않았기 때문입니다.
바로 이 포인트가 저자들이 키워드로 삼은 “Video continuity”이고, 저자는 비디오에서 시간 축에 따라 흘러가는 프레임들의 연속성들을 모델이 명시적으로 학습할 수 있도록 아래 3가지 pretext task를 설계합니다.
- Continuity justification
- Discontinuity localization
- Missing section approximation
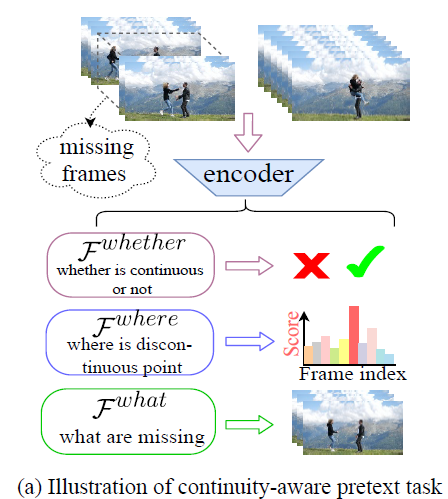
그림 2의 \mathcal{F}^{whether}, \mathcal{F}^{where}, \mathcal{F}^{what}이 각각 순서대로 위에서 말씀드린 pretext task에 해당합니다.
먼저 \mathcal{F}^{whether}는 비디오 클립을 feature로 만든 뒤 해당 feature에 불연속적인 부분이 있는지 없는지를 이진 분류하는 pretext task입니다. 여기서 모델은 전체 비디오의 global 정보를 파악해야만 본 pretext task를 제대로 수행할 수 있습니다. 멀리 뛰기 비디오를 예로 들었을 때, 단순히 사람이 천천히 뛰다가 빨리 뛴다고해서 discontinuity가 발생하는게 아니듯, local 정보가 아닌 멀리 뛰기가 무엇인지 global 한 그 의미론적 과정을 전부 파악해야 그 속에서 불연속 발생 여부를 제대로 판단할 수 있다는 것입니다.
다음으로 \mathcal{F}^{where}은 임의로 생성한 불연속을 포함하는 클립 중 어느 지점에서 불연속이 발생했는지 위치를 찾아내는 pretext task입니다. 모델은 여기서 global 정보보다는 비디오 부분부분에서 극적으로 모션이 변화하는 local 지점을 찾아내는 능력을 필요로 할 것입니다.
마지막은 \mathcal{F}^{what}인데요, 앞선 pretext task를 수행하면서 불연속 클립의 불연속 지점이 어디인지까지 파악했다면 이제는 그곳에 무엇이 들어가야할지 파악하는 pretext task입니다. 이 pretext task를 수행하기 위해 모델은 비디오 전체에서 어떤 일이 벌어지는지 알아야 할 것이고 불연속 지점의 앞뒤 motion 패턴을 파악하는 고수준의 문맥 정보 이해 능력이 필요할 것입니다.
물론 pretext task이니까 원본 비디오로부터 임의로 일부 구간을 떼어내어 discontinuity를 만들어내는 방식으로 위 과정을 수행할 것입니다. 저자가 제안한 Self-supervised 프레임워크를 Continuity Perception Network (CPNet)라 칭하였고, 논문의 contribution을 정리한 후에 자세한 학습 방식을 알아보겠습니다.
Contributions
- To the best of our knowledge, this is the first work that explicitly exploits video continuity to obtain supervision signals for self-supervised video representation learning
- We propose CPNet to solve novel continuity-aware pretext tasks and promote the model to learn coarse- and fine-grained motion and context features of the videos
- We conduct comprehensive ablation studies and experiments on multiple downstream tasks to validate the utilities of the proposed CPNet – SOTA performances on Action recognition, Video retrieval
2. Method
Overview
간단히 notation을 정리하고 넘어가겠습니다.
라벨이 없는 N개의 비디오들은 V = \{v_{i}\}_{i=1}^{N}으로 표현되고, 각 비디오 v_{i}에서 샘플링한 클립 c_{i}는 파라미터 \theta{}_{f}를 갖는 인코더 F_{\theta{}_{f}}를 통해 video continuity 관련 정보를 담고 있는 feature f_{i}로 임베딩시킬 것입니다. 물론 이러한 표현력을 갖춘 모델 F_{\theta{}_{f}}를 학습하는 것이 목적이겠죠.
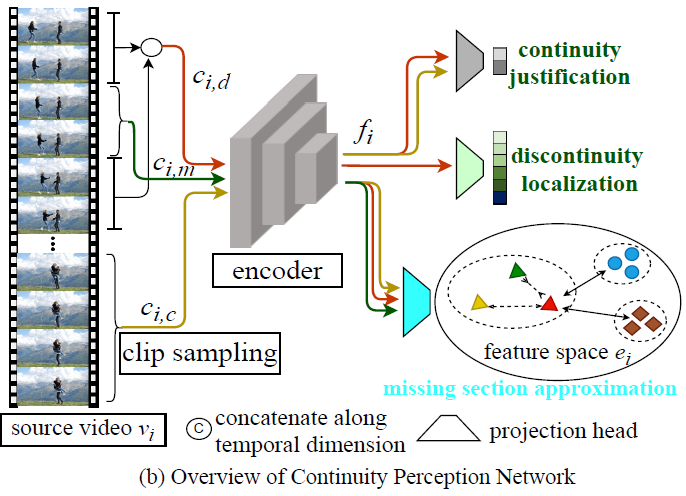
그림 3은 비디오로부터 3가지 pretext task가 수행되는 과정을 나타내고 있습니다. 클립 c_{i, d}는 중간에 missing된 클립 c_{i, m}을 제외하고 남은 불연속적 클립을 의미하고, 클립 c_{i, c}는 같은 비디오 내에서 연속적으로 진행되고 있는 클립을 의미합니다. 각각이 인코더를 통과하고, 각 feature들을 이용해 pretext task가 수행됩니다. 그렇다면 c_{i, d}, c_{i, m}, c_{i, c}가 어떠한 기준으로 구성되는지 알아볼 필요가 있겠죠.
2.1 Continuity Perception Task Preparation
Data and supervision acquisition
우선 저자는 한 비디오 내 불연속적 지점의 개수를 하나라고 정합니다. l_{n}은 c_{i, d}의 길이, l_{m}은 c_{i, m}의 길이라고 했을 때, 먼저 비디오에서 l_{n} + l_{m} 길이의 초기 클립을 샘플링합니다. 그리고 불연속성을 만들기 위해 제거할 구간의 시작 지점 j_{i} \in{} [1, l_{n}-1]을 임의로 정합니다. 인덱스는 0부터 시작하기 때문에 저 구간 내에서 제거 시작 지점을 정하면 제거된 지점 앞뒤로 불연속적인 클립이 무조건 존재하겠죠.
이렇게까지 수행을 했을 때 중간에 제거한 l_{m} 길이의 클립이 c_{i, m}이 되고, c_{i, m}을 제외하고 남은 l_{n} 길이의 클립이 concat되어 c_{i, d}가 되는 것입니다. 두 번째 pretext task에서 불연속 지점이 어디인지 맞춘다고 하였는데, 이 task는 1 ~ l_{n} - 1 중 어디가 불연속의 시작 지점인지를 분류하는 방식으로 수행됩니다. 이에 대한 정답 라벨은 j_{i}일 것입니다.
이후 c_{i, c}는 비디오 중 c_{i, d}, c_{i, m}이 아니면서 연속적인 임의의 구간으로 선택되고, 길이는 마찬가지로 l_{n}입니다.
2.2 Continuity Perception Self-Supervision
본격적으로 pretext task 수행 방법론에 대한 설명입니다.
Continuity justification
첫 pretext task는 해당 비디오의 불연속 지점 존재 유무 분류였는데요, 수식으로 바로 설명드리겠습니다.
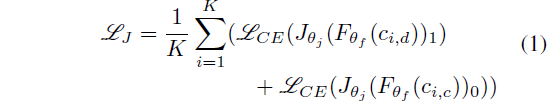
수식 1은 Continuity Justification loss \mathcal{L}_{J}입니다. 식에서 K는 한 배치 내 비디오의 개수를 의미하고, J_{\theta{}_{j}}는 분류를 위한 projection head입니다.
앞선 데이터 정의 과정에 따르면 한 비디오마다 연속적 클립, 불연속적 클립을 모두 가지고 있습니다. 연속적/불연속적 클립을 주고 각 경우에 따라 CrossEntropyLoss를 활용해 0/1로 학습하는 것을 볼 수 있네요.
저자의 주장에 따르면 Positive와 negative가 결국 하나의 비디오로부터 만들어졌기 때문에 해당 pretext task를 올바르게 수행하기 위해 모델이 연속적/불연속적 클립 각각에만 집중하는 것이 아니라, 두 클립을 모두 보며 비디오의 전체적인 motion 일관성을 파악하려고 노력하게 될 것이라 합니다.
Discontinuity localization
다음은 불연속 클립 중 어느 구간이 끊겨있는 것인지 분류를 통해 맞추는 pretext task입니다. 수식으로 바로 보겠습니다.
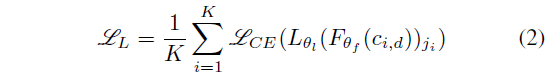
수식 2에서도 마찬가지로 L_{\theta{}_{l}}은 projection head를 의미하고, 2.1절에서 설명드렸듯 j_{i}를 불연속 시작점의 라벨로 두고 1 ~ l_{n} - 1 중 정답을 맞추는 것입니다.
첫 번째 pretext task보단 조금 더 local하고 세부적인 정보를 파악할 수 있는 능력이 갖춰져야 올바르게 불연속 시작 지점을 찾아낼 수 있겠죠.
Missing section approximation
세 가지 pretext task 중 앞 두 가지는 단순 CrossEntropyLoss로 학습이 수행되었는데, 마지막은 triplet loss와 InfoNCE loss로 학습합니다.
불연속 클립 사이 빠져있는 부분 c_{i, m}에 무엇이 들어갈지 맞추기 위해 비디오의 RGB 프레임을 복원하는 것은 아니고 feature-level에서 metric learning을 수행하는 방식으로 학습이 이루어집니다. 현재 저희가 학습을 위해 지정한 클립은 c_{i, d}, c_{i, m}, c_{i, c}인데요, c_{i, d}와 c_{i, m}은 원래 비디오에서 연결되어있는 부분이기 때문에 feature-level에서도 시간적으로 연결되어 있고 유사하다고 볼 수 있습니다.
그래서 저자는 c_{i, d}를 anchor로 두었을 때 c_{i, m}과는 가까워지고, 같은 비디오에 속하지만 c_{i, c}와는 시간적으로 떨어져 있기 때문에 멀어지는 방향으로 triplet loss를 설계합니다.
여기서 c_{i, d}와 c_{i, c}는 결국 같은 비디오에 속하는데 feature의 거리가 멀어지도록 학습해도 되는지 의문이 들 수 있는데요, 저자도 이에 대응할 수 있는 장치를 하나 설계합니다. c_{i, d}와 c_{i, c}가 너무 멀어지는 것을 방지하고자, 이 둘의 거리를 c_{i, d}와 다른 비디오의 클립들과의 거리보다는 가깝게 만들어주는 것입니다. 이것이 InfoNCE loss로 설계되어있고, 수식은 아래와 같습니다.
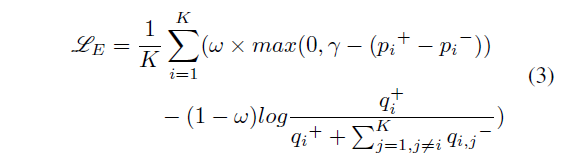
- p_{i}^{+} = sim(e_{i, d}, e_{i, m})
- p_{i}^{-} = sim(e_{i, d}, e_{i, c})
- q_{i}^{+} = exp(sim(e_{i, d}, e_{i, c})/\tau{})
- q_{i, j}^{-} = exp(sim(e_{i, d}, e_{j, d})/\tau{}) + exp(sim(e_{i, d}, e_{j, c})/\tau{})
j는 한 배치 내 다른 비디오를 의미하고, \tau{}는 temperature입니다. 수식의 의미는 위에서 설명드린 바와 같고, \omega{}는 0~1 사이의 값으로 1에 가까울수록 현재 보고있는 비디오 내에서의 feature 거리 조절에 집중할 것이고, 0에 가까울수록 현재 비디오와 배치 내 타 비디오와의 feature 거리 조절에 집중하게 될 것입니다.
세 번째 pretext task를 통해 모델은 background나 비디오 내 물체들, fine-grained한 모션의 변화 등에 해당하는 문맥적 특징들에 집중하게 될 것입니다.
Multi-task joint optimization
Backbone 네트워크는 앞서의 세가지 loss를 한 번에 학습하며 저자가 의도한 표현력을 갖춘 모델로 거듭나게 됩니다.
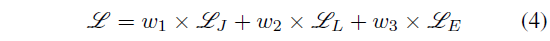
3. Experiments
실험과 성능 부분입니다.
저자는 Action recognition, Video retrieval, Action localization task에서 성능을 측정하였고 사전학습은 UCF101과 K400 데이터셋으로 수행했다고 합니다.
3.1 Ablation Studies
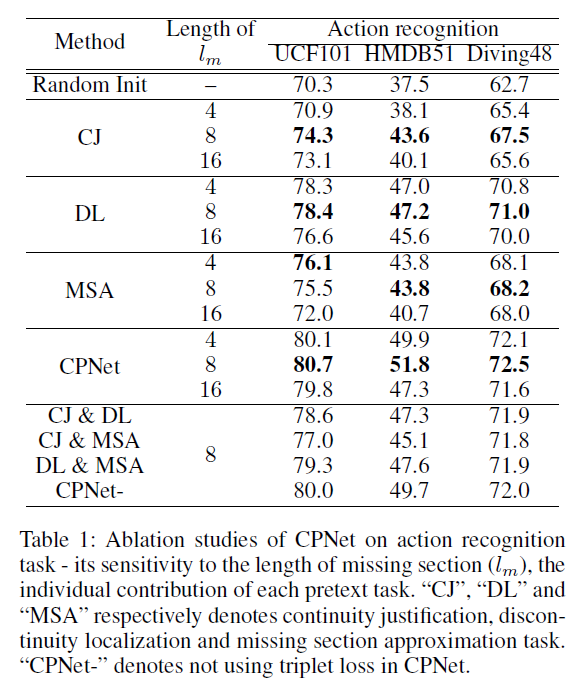
표 1은 CPNet의 Action recognition task에 대한 ablation 실험 성능입니다.
표에서 CJ, DL, MSA는 각각의 pretext task를 순서대로 의미하며, 먼저 중간에 제거된 클립의 길이 l_{m}에 대한 하이퍼파라미터 실험에서 저자는 pretext task가 너무 쉽거나 너무 어려워 애매해서는 안된다는 기존 연구와 동일한 결론을 낸다고 이야기합니다. 하이퍼파라미터에 대한 실험이니 큰 의미를 두기보단 결국 중간 8개의 프레임을 제거했을 때 모델이 가장 좋은 성능을 보였다는 것을 이야기하고, 참고로 나머지 클립들의 길이 l_{n}은 16으로 설정되어있습니다.
또한 표 1에서 각 pretext task에 대한 ablation 성능도 확인할 수 있는데, 두 번째인 discontinuity localization task가 가장 효과적이었음을 알 수 있습니다. 모델이 불연속 클립 중 어느 지점이 실제 불연속적인지를 맞추는 과정에서 각 프레임 별 시간 축에 대한 motion 변화를 밀도있게 관찰해야하다 보니 fine-grained한 정보를 잡아냈다고 볼 수 있습니다. 물론 나머지 pretext task들도 합쳐졌을 때 성능을 더욱 끌어올려주며 보완적 역할을 수행하였습니다.
3.2 Evaluation of Self-Supervised Representation
다음은 각 downstream task에서의 벤치마크 성능입니다.
Action recognition
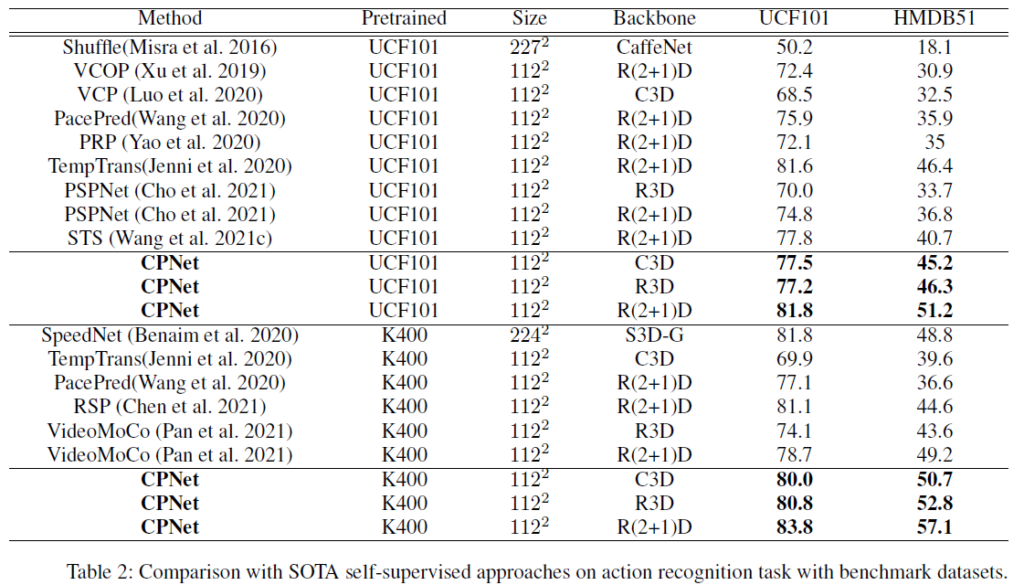
벤치마크 성능에 대해 저자가 별다른 분석을 제시하고 있지는 않습니다. 사전학습 시 입력되는 프레임의 개수도 함께 적혀있으면 비교하기 더욱 쉬웠을 것 같은데 아쉽습니다. 어쨌든 모델 구조상 비디오의 모든 프레임을 활용하는 방법론이 아님에도 효율적으로 높은 성능을 보여준다는 점이 인상깊습니다.
Video retrieval
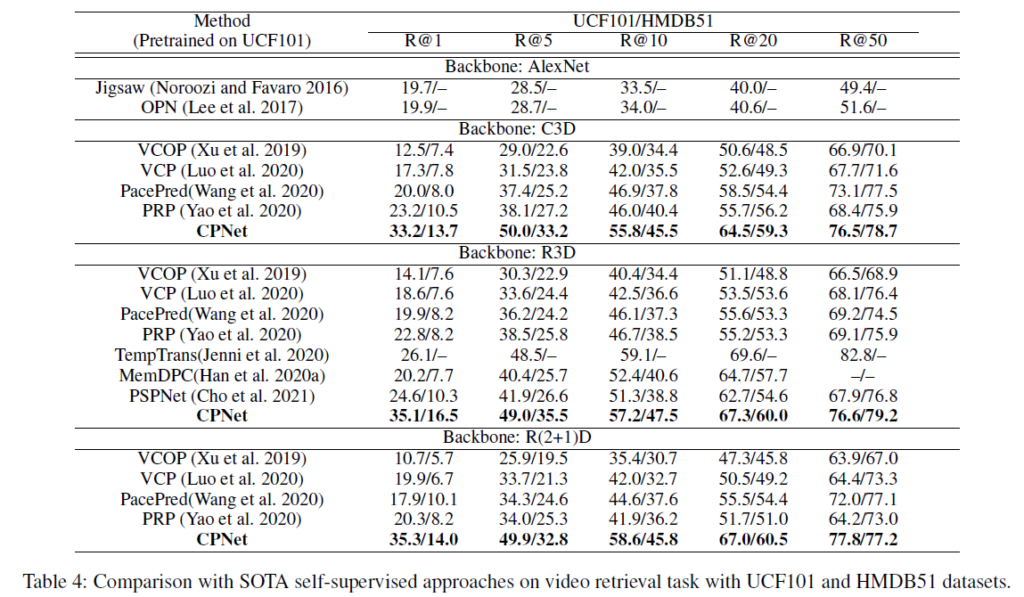
표 4의 retrieval 성능에서, 여러 K에 대한 recall 값을 보면 압도적으로 이전 방법론에 비해 높은 성능을 보이고 있습니다.
Temporal Action Localization
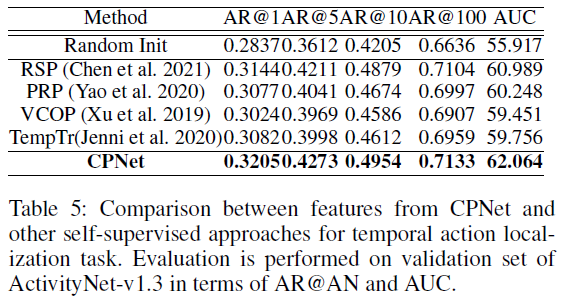
표 5가 가독성이 좀 떨어지긴 하지만 다른 사전학습 방법론들에 비해 저자가 제안하는 CPNet이 높은 성능을 보여주고 있긴 합니다. 평가 지표도 그렇고 BMN 알고리즘을 가지고 성능을 측정했다는 것을 보니 엄밀히 따지면 Action localization이 아니라 Action proposal에 대한 성능으로 보입니다.
3.3 Complementary With Existing Methods
마지막으로 타 방법론에 CPNet의 discontinuity localization task를 함께 수행하는 경우의 실험 성능을 보여줍니다.
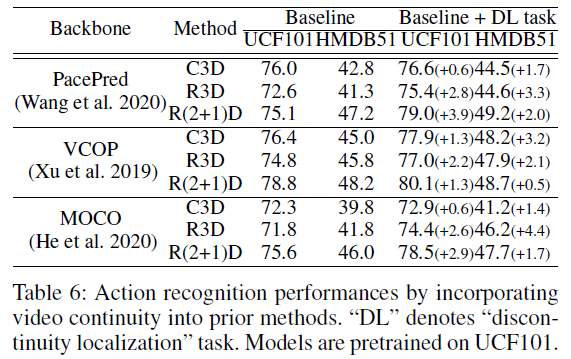
표 6은 UCF101 데이터셋으로 각 backbone 네트워크를 사전학습할 때 (기존 방법) / (기존 방법 + discontinuity localization)의 성능 비교입니다.
저자가 제안한 여러 pretext task 중 굳이 DL을 넣은 이유는 구현이 간단하면서도 큰 추가 메모리 cost나 연산량을 필요로 하지 않기 때문입니다. Introduction 부분에서 저자가 기존의 SSVRL 방법론들이 coarse한 정보만 잡아내는 경향이 있다고 주장했었는데, 상대적으로 fine-grained한 정보를 잡아내는 DL이 다른 방법론들에 붙으면서 성능 향상이 일어난 것을 보여주며 주장에 대한 근거를 뒷받침하고 있습니다.
4. Conclusion
인지 과학 분야에서 사람의 시각적 인지 과정에 필요한 요소를 찾아 이를 보완하려고 한 점이 인상깊었습니다. 방법론이 대단한 것은 아니었지만 필요성을 강조하는 과정에서 독자를 잘 설득하고 있는 논문이라는 생각이 들었습니다. 좋은 실험 결과를 얻었지만 그에 대한 분석보다는 단순히 향상된 수치만을 나열한 점이 조금은 아쉬웠습니다.
이상으로 리뷰 마치겠습니다.
안녕하세요.
좋은 리뷰 감사합니다.
읽다가 가벼운 의문이 생겨 질문드립니다.
[latex]c_{i,,d}[/latex]가 앵커이자 영상에서 중간 클립이 제거된 영역이고, [latex]c_{i,,m}[/latex]이 제거된 부분, [latex]c_{i,,c}[/latex]는 같은 영상에서 추출된 다른 시간대의 클립으로 이해하였는데, <그림 3>을 보면 이 클립들이 모두 어떤 인코더를 거쳐 projection head로 필요한 클립들만 전달되는 것 같습니다.
그러면, 한번 데이터가 forwarding될 때, 이 encoder에는 세 클립이 각각 통과되어 특성으로 변환되고, 이걸 3가지 projection head에 태워 각각의 pretext task를 수행한 다음, 역전파를 진행하는 건가요?
세 가지 pretext task가 점점 어려워지는 느낌이 있어 순차적으로 pretext task를 어렵게 바꿔가며 학습시키는 것인가 하였는데 한번에 하는 것이라 신기하였습니다.
감사합니다.
본 논문에서 3가지 loss를 한 번에 학습하는 것이 맞습니다. 만약 3가지의 pretext task를 따로따로 학습한다면, 총 3번에 걸쳐 상대적으로 파라미터 수가 매우 많은 backbone network를 학습해야 하는 큰 cost가 소모되기 때문에 일반적으로는 저자들이 제안하는 방법론이 아예 결이 다른 task가 아닌 이상 한 번에 최적화를 수행하는 경우가 대부분입니다.
그리고 하나의 pretext task씩 최적화를 한다면 모델이 pretext task 간의 암시적인 관계를 고려하지 못하고 매 번 목표로 하는 pretext task에만 최적화될텐데, 저자가 원하는 것은 그러한 모델이 아니라 pretext task끼리의 암시적 관계를 고려하면서 세 가지 태스크를 동시에 잘 해결하는 최적의 파라미터를 찾는다는 점도 장점으로 작용할 수 있습니다.
좋은 리뷰 감사합니다. 개인적으로는 지난번 리뷰를 이어서 작성해주기를 바랬는데 논문이 어려웠나 봅니다.
결국 전체적인 컨셉은 masking 후 이를 learning signal로 활용하는 것 같네요.
의문이 드는 것은 motion이 별로 없는 부분은 masking을 해도 계속해서 continuity가 보존될 것 같은데 이러한 케이스에 대해서는 논문에서 얘기한 것이 있을까요?
해당 케이스에 대해 논문에서 언급한 바는 없습니다만, 사실 완전히 정적인 프레임이 계속 이어지지만 않는다면, 오히려 미세하게 변화하는 비디오 속에서도 학습을 통해 discontinuity를 찾아낼 수 있다면 모델이 더욱 세부적인 인지 능력까지 갖출 수 있지 않을까.. 생각하고 있습니다.