안녕하세요, 로보틱스 팀 양희진이라고 합니다.
이번에는 6D pose estimation에 대한 논문인 PoseCNN을 리뷰 해보았습니다. 일단 PoseCNN 을 읽은 이유는 6D pose estimation에서 인용수가 꽤 많은 것을 보아 해당 분야의 기반을 닦을 수 있는 내용인 것 같아 읽어보았습니다. paperwithcode에 나오는 성능 동향을 보면서 논문을 리뷰할 예정입니다.
Background Knowledge
6DoF(Degree of Freedom)
6D pose estimation 중 6D는 각 축(x, y, z)에 대한 정보와 축 회전 정도에 대한 정보(pitch, roll, yaw)를 의미합니다.
Euler Angle vs Quaternion
pose estimation을 하려면 rotation에 대해서도 고려를 해야합니다. 회전 정도를 알 수 있는 방법은 2가지가 있습니다.
- Euler Angle
- 오일러 각은 3차원 공간의 절대 좌표를 기준으로 물체의 회전을 측정하는 방식입니다.
- X, Y, Z 3개의 축을 기준으로 회전하기에 직관적이며 조작하기 쉽고 180도가 넘는 회전도 표현이 가능합니다.
- 하지만 오일러각을 계산하려면 computational cost가 상당히 크며 DoF를 상실하게 되는 짐벌락(Gimbal Lock : 회전 축 겹침 현상)이 발생하게 됩니다.
- Quarternion
- 4개의 수($x, y, z, w$)로 이루어져 있으며, 각 성분은 하나의 벡터(x, y, z)와 스칼라(w)을 의미합니다.
- 쿼터니언은 orientation과 rotation을 둘 다 representation 할 수 있습니다.
- 각 축을 한꺼번에 계산하기 때문에 짐벌락 현상이 발생하지 않습니다.
- 180도 보다 큰 회전에 대해 representation 할 수 없습니다. → 직관적으로 이해하기 어렵습니다.
즉, Euler angle representation은 Gimbal Lock 현상으로 인해 Quaternion 을 사용하는 것 같습니다.

Abstract
물체에 대해서 로봇이 6D psoe을 추정하는 것은 실제 상황에 대해서 중요한 역할을 합니다. 하지만, 이러한 Task는 꽤 어려운 상황에 직면하게 됩니다. 예를 들어 물체에 대해 Clutter scene 이나 Occlusion scene이 어려운 상황을 얘기할 수 있겠습니다. 이번 논문에서는 PoseCNN 이라는 새로운 6D pose estimation을 위한 신경망을 제안합니다. PoseCNN은 이미지 내의 중간에 localizing을 수행하고 camera로부터의 거리를 예측하여 3D 변환에 대하여 추정합니다. 먼저, 물체의 3차원 회전에 대해서 Quaternion을 이용하여 regression을 수행하고 추정합니다. 대칭적인 물체를 다루기 위해 PoseCNN은 그 당시 새로운 loss function을 사용했다고 합니다. 저자는 다음과 같은 Contibution이 있었다고 합니다.
- YCB-Video Dataset
- 6D pose estimation을 위한 large scale의 비디오 데이터셋을 만듦
- Novel loss function
YCB-Video 데이터셋과 OccludedLINEMOD 데이터셋을 이용하여 PoseCNN이 얼마나 occlusion에 강인한지 알아보기 위한 실험으로도 확장을 했다고 합니다. 해당 실험들은 input을 컬러 이미지에 대해서만 사용했고, 위치에 대해 refine을 하려고 Depth data를 이용하였더니 OccludedLINEMOD 에서 SOTA를 달성했다고 합니다.
I. INTRODUCTION
물체를 인식하고 그 물체에 대한 3차원 위치를 추정하는 것은 로보틱스 task 중 넓은 범위에서 사용되고 있습니다. 예를 들면, 물체의 3차원 위치나 방향에 대한 인식 능력이 로봇의 manipulator*에 중요한 역할 하는 것이 있습니다. 이런 중요한 역할을 하는데 실제로는 다양한 문제로 인해 어려움을 겪고 있습니다. 여기서 말하는 다양한 문제란, 이미지 내에서 3차원 물체의 포괄적으로 모양이 다른 점이 있습니다. 이런 문제는 주로 조명, occlusion에 영향이 있겠네요. 당시 6D pose estimation 을 하기 위해서는 3D 모델과 이미지 사이에서 feature point에 대해 매칭을 하도록 했는데, 하지만 이러한 방법은 풍부한 texture가 있어야 합니다. 결과적으로 texture가 풍부하지 않은 상태에서 매칭을 한 것 입니다.
texture-less를 해결하기 위해 depth camera를 이용했는데, 이를 이용한 데이터셋인 RGB-D에 대해 texture가 없는 물체를 인식하기 위한 몇 가지 방법이 제안되었습니다. template 기반의 방법은 occlusion에 대해서 상당히 인식 성능이 낮았습니다. 또한 6D pose estimation에 대해서 2차원과 3차원에 대응하기 위해 이미지 픽셀을 3차원 물체의 좌표로 regression시키는 학습을 수행하는 방법도 제안되었는데 이러한 방법은 대칭되는 물체에 대해 처리할 수 없는 문제가 있었습니다.
앞서 얘기한 한계들에 대해 해결하기 위해 해당 논문에서 저자는 6D pose estimation 프레임워크를 제안합니다. 즉, 새로운 PoseCNN 이라는 end-to-end의 6D pose estimation 을 위한 새로운 신경망을 만들었습니다. PoseCNN의 핵심 아이디어는 pose estimation 작업을 서로 다른 구성요소로 분리하는 것인데, 이를 통해 네트워크는 이들 사이의 종속성과 독립성을 명시적으로 모델링 할 수 있다고 합니다.
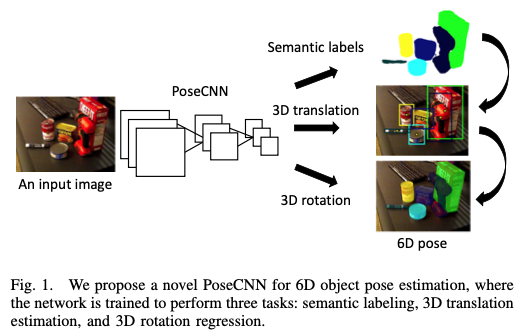
그림1은 PoseCNN의 전체적인 프레임워크를 설명하는 그림입니다.
- 첫 번째로, 입력 이미지가 들어오면 각각의 픽셀에서 물체의 라벨을 예측합니다.
- 두 번째로, 각 픽셀의 중앙으로부터 unit vector를 예측하고 물체 중앙의 2차원 픽셀 좌표를 추정합니다. semantic한 라벨 정보를 이용하여 물체와 연관된 이미지 픽셀이 이미지 내의 물체 중심 위치에 voting을 하고, 이러한 네트워크는 추가적으로 물체 중심의 distance를 추정합니다. 카메라의 성질을 이용하여 2차원 물체의 중심과 거리를 추정하면 3차원 변환 T 를 복구할 수 있습니다.
- 마지막으로, 3차원 회전에 해당하는 R은 Quarternion representation으로 regression하여 추정합니다. 저자는 R 과 T 를 추정하기 위한 회전에 대한 regression에 이어 2차원 중심에 대한 voting 방식은 textured/texture-less 에 상관없이 물체에 대해 적용될 수 있으며 물체가 occlusion 된 상태에 대해서도 물체의 중심에 대해 voting하도록 학습이 되기 때문에 occlusion에 강하다고 합니다. 서로 다른 물체의 방향이 동일한 observation을 생성할 수 있기 때문인데요. 예를 들어
대칭적인 물체를 handling하는 것은 pose estimation에 대한 또 다른 어려움이라고 합니다. 아래 그림을 보고 설명하겠습니다.

예를 들어 그림5에서 빨간 그릇이나, 바로 옆에 있는 나무 블록(?)은 orientation을 unique한 방향을 추정할 수 없습니다. 그래서 대칭성을 무시하는 벤치마크 데이터셋인 OccludedLINEMOD에서는 물체의 symmetric evaluation을 고려하므로 결국 대칭성은 학습 과정에서 무시하게 되었습니다. 하지만 추정의 결과가 물체의 대칭에 대해 정확하더라도 물체의 방향에 대해서 높은 loss 를 보이면서 일관성이 없는 결과를 보여주기 때문에 훈련 성능이 저하될 수있다고 합니다. 저자는 이러한 영감을 받고 객체의 3D shape를 일치시키는 것에 초점을 맞추고 새로운 Loss function인 ShapeMatch-Loss를 제안합니다. 해당 loss function는 대칭성을 가진 물체에 대한 우수한 추정을 한다는 것을 보여줍니다.
해당 방법은 앞서 언급한 6D pose estimation의 벤치마크 데이터셋인 OccludedLINEMOD 데이터셋에서 평가를 했다고 진행했다고 합니다. 해당 데이터셋에서 PoseCNN은 단일 컬러, RGB-D 둘 다 pose estimation 에 대해 그 당시 SOTA를 달성했다고 합니다. 좀 더 철저하게 평가하기 위해 YCB-Video 라는 대규모 RGB-D video 데이터셋을 추가로 수집하였고, 해당 데이터셋에는 물체가 서로 다른 대칭성을 나타내면서 다양한 pose와 공간 구성으로 배열되어 있으며 물체들 사이에 심각한(?) occlusion이 만들어져있습니다.
핵심적인 contribution을 요약하면 다음과 같습니다.
- PoseCNN이라는 6D pose estimation을 위한 새로운 신경망을 제안하였고 end-to-end로 6D pose estimation을 하였고 물체간의 occlusion에 강인함
- 대칭적인 물체에 대한 pose estimation을 위한 ShapeMatch-Loss를 제안함
- 6D pose estimation을 위해 대규모 데이터셋인 RGB-D video 데이터셋을 만들었고, 6D pose의 21개 클래스에 대한 annotation을 제공함
*manipulator : 인간의 팔과 유사한 동작을 제공하는 기계적인 장치
II. RELATED WORK
6D pose estimation의 방법은 크게 2개로 나눌 수 있습니다.
- Template-based
견고한 템플릿이 구성되어 입력 이미지의 다른 위치를 scan하는 데 사용됩니다. 각 위치에서 유사도를 계산하고 이러한 유사도를 비교하여 가장 적합한 match를 얻습니다. 6D pose estimation에서의 템플릿은 일반적으로 3D 모델을 렌더링하여 얻게 됩니다. 템플릿 기반의 방법은 texture-less 물체에 대한 detection 을 하는 데 유용하지만 occlusion에 대해 유사도가 낮기 때문에 물체간의 occlusion에 대해 handling 할 수 없습니다.
- Feature-based
local feature는 interest point 또는 이미지의 모든 픽셀에서 추출되고, 3D 모델의 특징과 일치하여 6D pose estimation을 복구할 수 있는 2D-3D corresponding을 설정합니다. 해당 방법은 occlusion에 대해 handling할 수 있지만 local feature에 대해 계산하기 위해서는 object의 풍부한 texture 정보가 필요합니다. texture-less object를 다루기 위해 기계학습 방법론을 적용하여 feature descriptor를 학습하는 몇 가지 방법이 제안되었습니다. 하지만 이 또한 3D reegression은 대칭적인 물체를 처리하기 어려운 상황에 직면하게 됩니다.
해당 논문에서는 네트워크가 bottom-up pixel-wise labeling과 top-down pose regression을 합치는 딥러닝 프레임워크에서 template-based 방법과 feature-based 방법의 장점을 합칩니다.
III. PoseCNN
입력이미지가 주어졌을 때, 6D pose estimation의 과제는 object coordinate system O 에서 camera coordinate system C 의 rigid transformation을 추정하는 것입니다.
object의 3D 모델을 사용할 수 있고 object ocordinate가 모델의 3D 공간에 정의되어 있다고 가정합니다. rigid transformation은 3차원 회전 행렬 R 3차원 translation 행렬 T 를 포함하는 SE(3)* transform으로 구성됩니다. R 은 object coordinate system O의 X, Y, Z축 주위의 회전 각도를 나타내고, T는 camera coordinate system C에서의 O 원점 좌표를 나타냅니다.
이미지 영상처리 과정에서 T는 영상 내의 object의 위치와 크기를 결정하고, R은 object의 3차원 모양과 texture에 따라 영상의 appearance에 영향을 줍니다. 이러한 두개의 파라미터들은 뚜렷한 visual properties를 가지고 있기 때문에 R 과 T 의 추정을 내부적으로 분리하는 CNN 아키텍쳐를 제안합니다.
*rigid transformation
- rotation transformation 과 같은 의미입니다.
**SE(3)
- Special Euclidean Group을 의미합니다. 3D Cartesian space에서 모든 적절한 rigid transformation의 group은 SE 입니다.
- Lie Group 중 하나로, 3차원 공간 상에서 강체의 변환과 관련된 행렬과 닫혀 있는 연산들로 구성된 Group을 의미합니다.
(Reference)
A. Overview of the Network
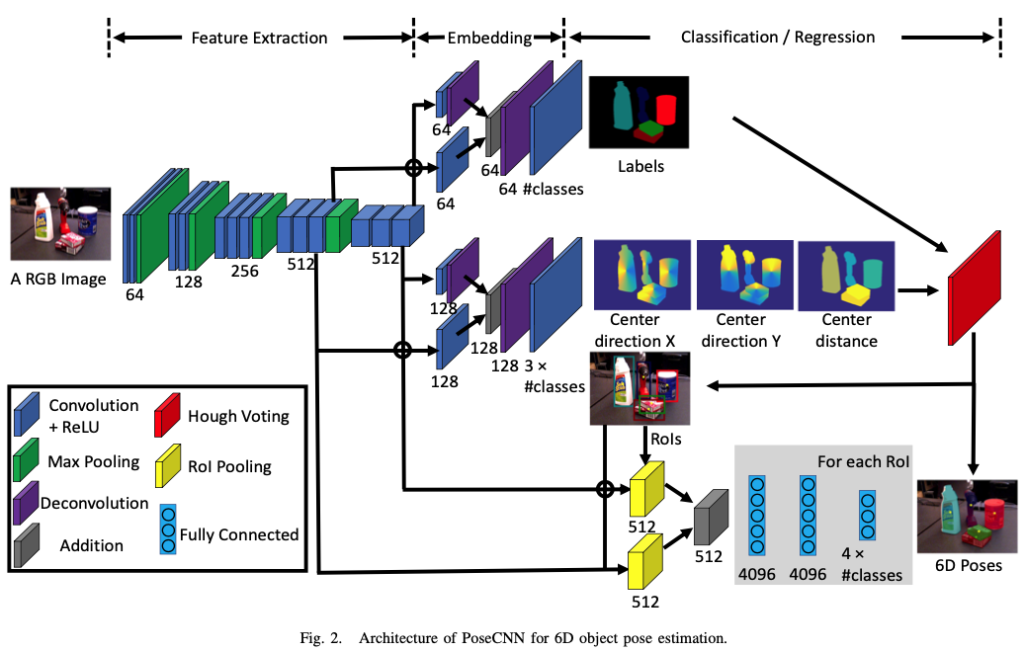
해당 그림2는 저자가 제안하는 아키텍처입니다. 해당 네트워크의 구조는 2-stage를 이루고 있습니다.
첫 번째 stage에서는 13개의 Convolution layer와 4개의 Maxpooling layer를 구성합니다. 이는 입력 이미지에 대해 다른 해상도의 feature map을 추출하기 위함이라고 합니다. 추출된 feature들이 네트워크의 모든 동작 과정에서 공유되기 때문에 해당 stage는 backbone의 역할하게 됩니다.
두 번째 stage에서는 첫 번째 stage에 의해 생성된 high-dimensional feature map을 low-dimensional의 task별로 feature에 임베딩하는 단계로 구성됩니다. 이후 6D pose estimation을 위해 sementic labeling, 3D translation estimation, 3D rotation regression 3가지 task를 수행합니다.
B. Semantic Labeling
이미지에서 object detection 하기 위해 저자는 각 이미지 픽셀을 object 클래스로 분류하는 semantic labeling을 사용합니다. bounding box보다 segmentation이 occlusion에 대해 더 다루기 좋기 때문이라고 합니다. 그림2의 임베딩 단계에서 맨 위의 branch에 해당합니다. convolution 이후 deconvolution을 하여 upsampling을 하는 이유는 좀 더 넓은 receptive field를 고려하여 semantic한 정보를 전달하기 위해 설정을 한 것으로 보입니다.
C. 3D Translation Estimation
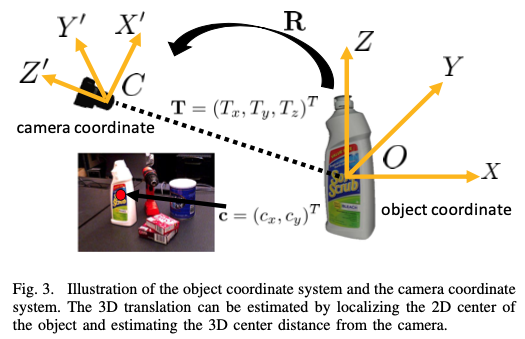
그림2에서 임베딩 단계의 중앙이 3D Translation에 대한 branch 입니다. 그림3의 T 는 camera coordinate에서 물체의 원점 좌표를 나타냅니다. naive한 방법으로 T를 이미지의 feature로부터 regression을 진행해도 되지만 이러한 방법은 이미지 내 모든 위치에 나타날 수 있기 때문에 해당 접근법은 일반화 할 수 없습니다. 또한 동일한 클래스에 대해 여러 object instance를 다룰 수 없습니다. 따라서, 저자는 이미지에서 2D object center의 중심을 localizing하고 카메라에서 object의 거리를 추정하여 3D transformation을 추정할 것을 제안합니다.
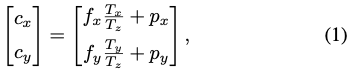
해당 방법은 image-plane에 투영된 점 c=(c_x, c_y) 를 가정합니다. 만약 네트워크가 c를 localize하고 depth인 T_z 를 추정한다면 T_x와 T_y를 구할 수 있습니다. f_x, f_y는 카메라의 focal length, p_x, p_y 는 principal point를 의미합니다.
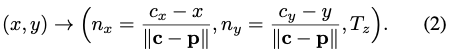
위 식은 object의 중심 좌표로부터의 방향 벡터와 depth정보를 의미하는 식입니다. 각 픽셀마다 해당 픽셀이 속한 object 중심 좌표로부터 방향벡터 x, y 성분을 구하고 해당 값에 크기를 나누어 unit vector로 정규화를 진행합니다. 정규화를 하는 이유는 학습 과정에 좀 더 모델이 수월하게 학습을 할 수 있도록 하기 위함이라고 합니다.
픽셀마다 해당 픽셀이 속한 unit vector를 구하면 모든 픽셀들에 대해 벡터장을 형성할 수 있게 됩니다. 해당 벡터장을 이용하여 중심값을 최종적으로 구할 수 있게 되는데, 이때 Hough Voting 을 사용한다고 합니다.
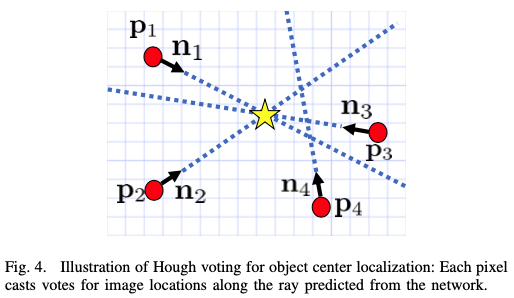
그림4는 Hough voting을 설명하는 그림입니다. 각각의 unit vector를 이용하여 voting을 하는 알고리즘입니다. unit vector 2개를 선택하고 교점을 center라고 가정했을 때, 다양한 unit vector들의 조합에 대해 여러 개의 center값들이 나오게 될 것 입니다. 여러 개의 center 값들 중, voting score가 가장 높은 center값을 사용하게 됩니다. 여기서 문제가 있습니다. 여러 개의 object가 있고 같은 class인 경우 center값을 계산하는데 어려움을 주게 됩니다. 이때 NMS(Non-Maximum Surppression) 과정을 추가적으로 적용하여 voting score에 threshold를 설정하여 threshold보다 낮은 score들은 제거하도록 합니다. thershold 보다 높은 pixel들에 대한 평균적인 depth값을 최종적으로 추정된 depth로 사용하게 됩니다.
D. 3D Rotation Regression
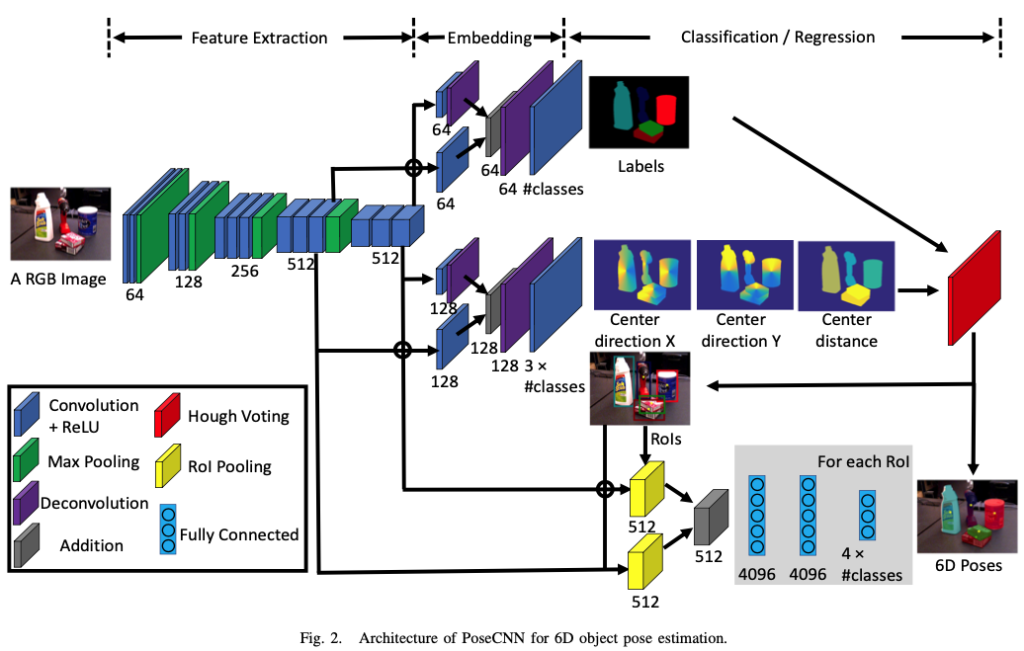
그림2에서 임베딩 단계의 가장 아래에 있는 곳을 보시면 3D rotation에 대한 branch 입니다. object의 bounding box를 Hough voting layer로부터 예측합니다. “Crop과 pool”이라고 표현을 하는 2개의 ROI(Region of Interest) pooling layer를 사용하는데, 이러한 visual feature는 3D rotation regression을 위해 첫 번째 단계에서 만들어집니다. 이렇게 pooling 된 feature map은 3개의 FC layer에 연결합니다. 각각의 클래스에 대해 FC layer의 출력은 3D rotation을 quaternion representation으로 합니다.
이때 Quaternion regression을 위한 loss function을 저자는 PoseLoss라고 칭합니다. 줄여서 PLoss라고 표기를 하네요. 식은 다음과 같습니다.
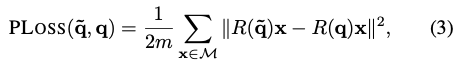
notation을 살펴보면 $M$ 은 3D 모델의 점을 나타내고 $m$은 그 점들의 개수를 나타냅니다. $R(\widetilde q)$와 $R(q)$ 는 추정된 quarternion과 실제 quarternion에서 각각 계산된 회전 행렬을 나타냅니다. 하지만 이러한 PLoss는 대칭적인 물체에 대해 핸들링을 할 수 없는 상황에 처하므로 저자는 앞서 언급된 ShapeMatch-Loss(SLoss)를 제안합니다.
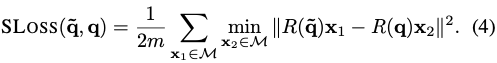
해당 loss function은 offset에 대한 측정을 각 추정된 모델의 방향에 대한 각 점과 GT와 가까운 점에 대한 거리를 측정하게 됩니다. SLOSS 는 두 3D 모델이 서로 일치할 때 minimize됩니다. 이러한 방법을 사용하면 rotation에 대한 패널티가 없게 됩니다. 즉, 대칭적인 구조를 띄는 object에 대해서도 핸들링 할 수 있게 됩니다.
IV. THE YCB-VIDEO DATASET
해당 섹션에서는 저자가 만든 YCB-Video 데이터셋을 어떻게 만들었는지에 대한 설명을 합니다.
A. 6D Pose Annotation
모든 비디오 프레임에 수동으로 annotation을 하지 않도록 각 비디오의 첫 번째 프레임에서만 object의 pose를 수동으로 지정합니다. 각 object에 대해 SDF(Signed Distance Function)* representation을 사용했다고 합니다. 첫 번째 depth 프레임에서 각 object에 대한 pose를 refinement합니다. 다음은 카메라의 궤적(trajectory)은 object pose는 고정한 상태로 depth video를 통해 object 구성을 tracking하는 형식으로 진행합니다. 마지막으로 카메라의 궤적과 상대적인 object pose는 global optimization 과정에서 refine된다고 합니다.
*SDF
- Signed Distance Function(SDF)는 3차원 공간 내에서 표면과의 거리를 나타내는 함수입니다. 이 함수는 특정 지점에서 표면까지의 거리와 방향을 모두 나타내며, 이를 이용하여 객체의 외형을 효과적으로 표현할 수 있습니다.
V. EXPERIMENTS
A. Datasets
YCB-Video 데이터셋에서 80개의 비디오에 대해 학습을 진행하였고 2949개의 프레임에대해 테스트를 진행하였다고 합니다. OccludedLINEMOD 데이터셋을 이용하여 논문에서 제안된 방법들에 대해 평가를 진행했다고 합니다.
B. Evaluation Metrics
6D Pose estimation의 평가지표는 무엇일까요?
ADD(Average distance)를 사용했다고 합니다. ADD는 GT의 pose와 estimated pose에 따라 변환된 3D 모델의 포인트 사이의 pairwise 거리의 평균을 계산합니다. 식은 다음과 같습니다.
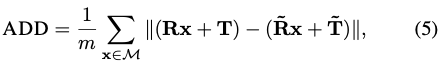
앞서 언급된 PLoss와 비슷한 형태를 가지는 equation입니다. 이 또한 symmetric object에 대해 한계가 있으므로 다음과 같은 ADD-S 라는 평가지표를 사용하게 됩니다.
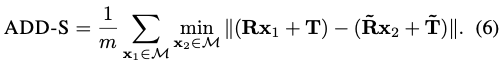
예를 들어, Eggbox나 glue 같은 대칭적인 구조를 이루는 object인 경우, 일부 view에서 점 사이의 일치성이 모호하기 때문에 가장 가까운 point distnace를 구하는 것 입니다.
해당 논문에서 제안된 loss function은 모두 위의 평가지표를 통해 영감을 얻었다고 합니다.
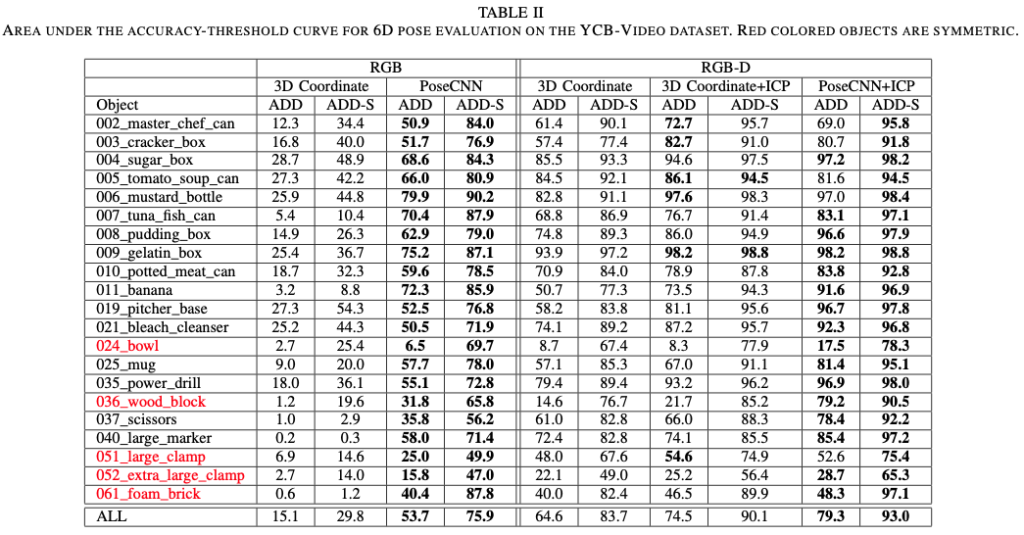
테이블2는 해당 논문의 contribution인 YCB-Video 데이터셋에서의 결과입니다, depth정보를 이용하여 추정한 결과에 대해 성능이 매우 우수한 것으로 볼 수 있습니다. 여기서 ICP는 Iterative Closest Point이며 pose에 대한 refine를 위해 도입한 알고리즘을 의미합니다. 즉 SLoss를 의미합니다. 빨간색으로 되어있는 object들은 대칭적인 구조를 이루는 object를 의미합니다.
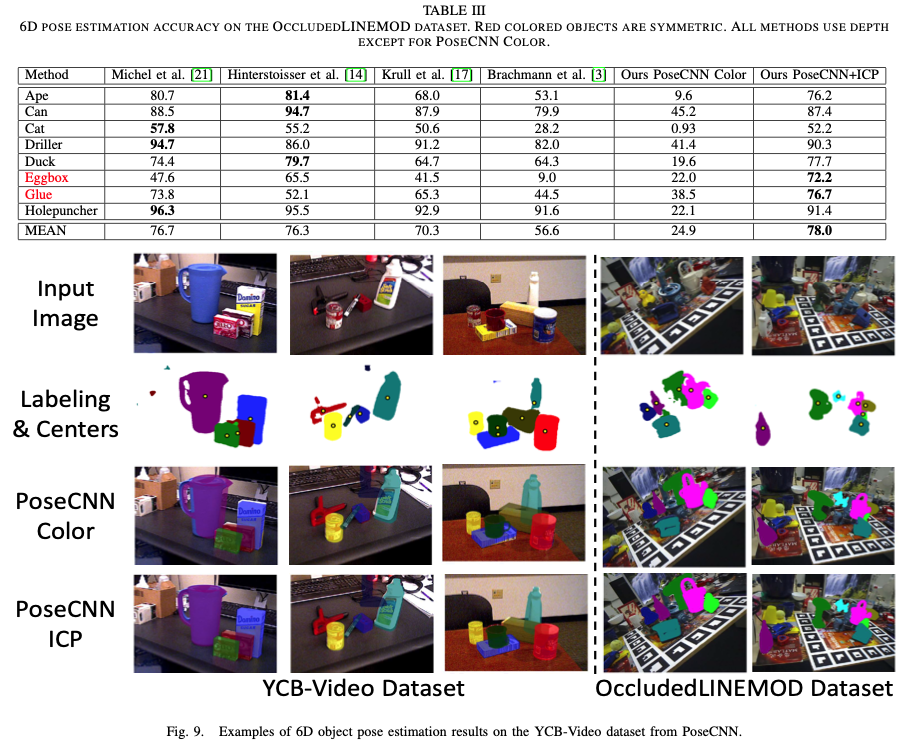
테이블3은 OccludedLINEMOD 데이터셋에 대한 결과입니다. 테이블2와 마찬가지로 빨간 글씨는 symmetric object입니다. PoseCNN color를 제외하고 모든 방법론들은 depth 정보를 사용합니다. 저자는 ShapeMatch-Loss를 사용하여 symmetric object에 대해 잘 다루었기 때문에 성능 향상이 있었음을 정량적로 보여주는 표입니다.
VI. CONCLUSIONS
해당 논문에는 새로운 CNN 구조인 PoseCNN을 제안하였습니다. PoseCNN은 추정을 3D rotation와 3D translation로 분리를 하고 이런 추정들은 객체 중심을 localizing하고 중심 거리를 예측하면서 3D translation을 추정하게 됩니다. 여기서 중요한 것은 Hough voting 방식으로 occlusion에 대해서도 강인함을 보였습니다.
3D rotation은 quarternion을 이용하여 구하는데 symmetric object에 대해 한계가 있으므로 ShapeMatch-Loss(SLoss)를 도입하였고 그 결과 symmetric object에 대해서도 핸들링 할 수 있게 되었습니다. 저자는 SLoss가 local minima에 가끔 빠질 때도 있다고 합니다. 향후 해당 문제 뿐만 아니라 좀 더 효율적인 6D pose estimation을 위한 방법을 탐구하기를 권유합니다.
6D pose estimation을 처음 작성하였는데, 내용이 너무 어려워 시간을 많이 투자함에도 부족한 것 같습니다. 개념, 용어가 하나부터 열까지 다 어려웠던 것 같습니다. 최대한 자세하게 적으려고 했으나 혼동되는 부분도 많았던 것 같습니다. 이해 안되는 부분에 대해 꼬리물기로 모르는 것들이 계속 나오고 제게는 너~~~~무 어려웠던 논문이었던 것 같습니다. 3차원 공간에 대해 다루기 위해 Lie Algebra와 같은 추가적인 공부를 하는 것이 도움이 될 것 같다는 생각이 들었습니다.
읽어주셔서 감사합니다.
좋은 리뷰 감사합니다. 6d pose estimation에 관련해서 처음 읽으신거라 어려움이 있으셨을텐데 잘 설명해주셔서 감사합니다.
혹시 euler angle에 문제점으로 지적한 짐벌락현상에 대해 조금 더 자세히 설명해주실 수 있을까요?
처음에 2d 이미지 기반으로 추정한다고 해서 궁금했는데 결국 카메라 파라미터로 depth를 추정하는 방식이었에요. 잘 읽었습니다:)
안녕하세요, 도경님. 리뷰 읽어주셔서 감사합니다.
Gimbal lock 현상은 3차원 공간에서 Euler angle을 이용하는 방식으로 회전을 다룰 때 맞닥뜨리게 되는 부작용이라고 합니다. Euler angle을 이용한 회전은 X, Y, Z축 별로 회전각을 통해 계산하는 회전 방식을 의미합니다. 즉, 특정 회전 상황에서 세 축 중 두 축이 겹치는 현상을 말합니다. 각 축의 회전 정도를 알기 위한 상황을 고려했을 때, 두 축이 겹친다는 것은 결국 하나의 축을 기준으로 회전을 한다는 의미가 되므로 예를 들어 X축 기준의 회전과 Z축 기준의 회전이 같아지면 우리가 원했던 상황이 아니게 됩니다. 그러므로 이러한 Gimbal Lock 문제를 해결하기 위해 도입된 개념이 Quarternion입니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
논문의 contribution인 SLoss가 object의 대칭성을 고려하기 위해서 3D 모델의 한 점과 동일한 3D 모델 안에서 GT와 가장 가까운 점에 대한 거리를 최소화하는 Loss라고 이해를 했는데 본문에서 “SLOSS는 두 3D 모델이 서로 일치할 때 minimize된다”라고 이야기 해주셔서 질문 드립니다. 3D 모델의 한 점과 GT와 가까운 점의 거리를 구하는 것은 결국 한 모델 안에서 이루어지는 것이 아닌가요??
또 한가지 궁금한 점은 Quarternion이 (x, y, z, w)으로 4개의 성분을 이용하고 각 축을 한꺼번에 계산하기 때문에 Euler Angle 보다 computational cost가 더 클 것 같다는 생각이 드는데 짐벌락 현상이 일어나지 않는다는 이유로 논문에서는 Quarternion이 사용되고 있네요. 두 방식의 computational cost에 대한 언급은 논문에 없었는지 궁금합니다 !
안녕하세요, 건화님. 리뷰 읽어주셔서 감사합니다.
1. 건화님이 말씀하신대로 “3D 모델 안에서 GT와 가장 가까운 점에 대한 거리를 최소화하는 Loss”가 맞습니다. 지적 감사합니다.
2. 논문에는 Euler angle, Quarternion과 같은 개념에 대한 내용은 전혀 없어서 따로 추가로 찾아 본 내용입니다. 하지만, 이러한 개념은 3D 회전에 다루기 위해서는 꼭 알아야 하는 개념이라고 합니다. Euler angle은 3개의 각도로 회전 표현하고, Quarternion은 4차원 복소수로 회전을 표현한다고 합니다. computational cost 자체는 건화님이 말씀하신대로 Quaternion의 computational cost가 좀 더 클 수 있겠지만, 회전 연산에 대한 안정성과 유연성을 제공하기 때문에 회전에 대한 representation으로 많이 사용되고 있다고 합니다.
안녕하세요. 좋은 리뷰 감사합니다. 리뷰를 읽다가 궁금증이 생겨 질문이 있습니다.
1) 오일러 각에서 언급한 DoF가 무엇인가요?
2) 데이터셋을 제안한 논문은 데이터셋을 제안했다는 것만으로도 굉장한 contribution이 된다고 생각하는데 여기에서 제안한 데이터셋이 지금도 많이 쓰여지고 있는지 궁금합니다. 데이터셋 논문은 많이 봤지만 실제로 이 데이터셋을 벤치마크로 사용하고 있는지는 많이 의문이 있는 부분이 있어…. 궁금하네요.
3) orientation을 unique한 방향으로 추정할 수 없다는 것은 대칭성 때문인가요? 사실 이 부분이 잘 이해각 가지 않아서 조금 더 설명 부탁드립니다.
감사합니다.
안녕하세요, 주연님. 리뷰 읽어주셔서 감사합니다.
1. DoF는 Degree of Freedom을 의미하며, 자유도를 나타냅니다. 기존의 3차원 공간에서 각 축의 회전에 대한 정보를 추가한 개념입니다. DoF를 상실한다는 것은 자유도가 작아진다는 것입니다. 오일러 각을 이용한 회전을 다룰 때는 특정 회전 상황에서 두 축이 겹치는 현상이 발생하게 되는데 이러한 현상을 Gimbal Lock이라고 합니다.
2. PoseCNN 논문이 2017년에 나왔는데 2021년도까지는 실험을 위한 결과로 종종 쓰이는 것 같습니다. 하지만 6D Pose Estimation에서 자주 쓰이는 LineMOD, OcclusionLINEMOD와 같은 데이터셋만큼은 자주 사용되지 않는 것 같습니다.
3. Symmetric object의 경우에는 Feature point가 상당 부분이 일치하기 때문에 Pose etimation을 하기에는 어려움이 있습니다. 즉, Feature point가 일치하여 다른 모습을 구분하기 어려울 수 있습니다. 이러한 문제를 해결하기 위해 추가적인 정보나 제약 조건을 사용하거나 다른 방법들을 적용할 수 있습니다. 해당 논문에서는 ShapeMatch-Loss를 사용함으로써 해결하였습니다.
감사합니다.
좋은 리뷰 감사합니다.
꼼꼼하게 작성해주셔서 이해하는 데 도움이 되었습니다.
제가 이해하기로, 방법론적 측면에서의 본 논문의 내용을 정리하자면 semantic label과 R,T를 각각 예측하도록 분리함으로써 이들 사이의 종속성과 독립성을 명시적으로 모델링 하고,
ShapeMatch-Loss라는 새로운 loss를 제안하여 대칭적인 물체에 대해 생기는 loss의 문제를 해결한 것으로 이해하였습니다.
PoseLoss와 해당 논문에서 제안된 ShapeMatchLoss는 수식으로 보았을 때 min의 유무 차이로 보이는 데, 두 loss는 함께 적용되는 것인가요?? 만일 대칭인 물체에 대해서는 SLoss, 아닌 경우 PLoss가 주어진다면, 이는 GT로 주어지는 정보일지 궁금합니다.
안녕하세요, 승현님. 리뷰 읽어주셔서 감사합니다.
부족한 글인데도 불구하고, 잘 이해해주셔서 감사합니다.
질문에 대한 답변은 SLoss만을 사용한 것입니다. PLoss를 사용하였더니, 대칭적인 물체에 대해서 경건하지 못한 상황 때문에 SLoss를 새롭게 적용한 것으로 보입니다. 즉, 대칭/비대칭인 물체에 경건하게 대비할 수 있는 SLoss를 사용합니다.
감사합니다.