갑작스럽게 웬 2015년 논문이야? 싶지만… 제가 듣는 수업에서 transformer에 대해서 발표하게 되어서 transformer 논문을 읽기 시작했는데 제 이해도 부족으로 논문 이해도가 굉장히 떨어져 안되겠다는 마음이 들었습니다. 그래서 이해도 향상을 위해 transformer 이전에 나온 attention 논문 리뷰를 작성하게 되었습니다. attention이 왜 등장했고 어떻게 사용되는지에 대해서 궁금하신 분들께서 흥미롭게 읽으실 것 같습니다. 그러면 리뷰 시작합니다.
<0. Abstract>
2015년도에는 인공신경망 기계 번역이 최근에 고안된 방식으로, 기존의 통계적 기계 번역과는 달리 인공신경망 기계 번역은 번역 성능을 극대화하기 위해 jointly하게 tuning할 수 있는 단일 신경망을 구축하는 것을 목표로 합니다. 인공신경망 기계 번역에서 최근에 고안된 모델은 encoder-decoder 형태를 띄는 모델에 속하는 경우가 많으며, source sentence를 고정된 길이의 vector로 인코딩 합니다. 이때 고정된 길이의 vector로 디코더가 번역을 수행합니다. 이 논문에서는 고정된 길이 vector를 사용하는 것이 basic encoder-decoder 구조의 성능 향상에 bottleneck이라고 가정하고, 모델이 target word를 예측하는 것과 관련된 source sentence의 part를 자동으로 검색할 수 있도록 하여 모델을 확장시킵니다. 이러한 새로운 접근을 통해서 영어-프랑스어 번역에서 SOTA를 달성하였습니다.
<1. Introduction>
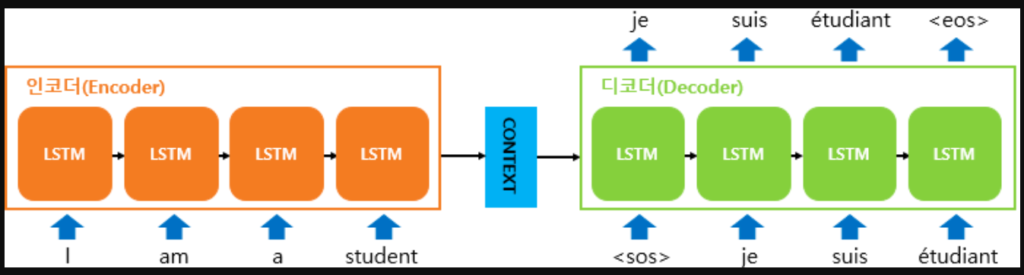
위에서 언급한 것처럼 2015년에는 인공신경망 기계 번역이 기계 번역의 새로운 접근하는 방식이었는데, 대부분의 인공신경망 기계 번역 모델은 encoder-decoder 구조를 띕니다. 여기서 encoder란 입력을 read하고 source sentence를 고정된 길이의 vector로 encoding 합니다. 이렇게 encoder가 encoding을 수행하면 decoder는 encoding된 vector로부터 번역을 수행합니다. 영어-프랑스어처럼 language pair에 대해서 encoder와 decoder로 구성된 encoder-decoder 시스템은 주어진 source sentence에 대해서 올바른 번역에 대한 확률을 극대화하도록 jointly하게 학습됩니다.
이러한 encoder-decoder 접근 방식은 하나의 문제를 가지는데 바로 source sentence의 information을 고정된 길이의 vector로 압축해야 한다는 것입니다. 이로 인해 신경망은 긴 문장, 특히 학습 과정에서 들어왔던 길이의 문장보다 긴 문장이 들어온다면 이를 제대로 처리하지 못하게 됩니다. 실제로 입력 문장의 길이가 길어질수록 basic encoder-decoder의 성능이 저하된다고 합니다.
논문에서는 이러한 문제를 해결하기 위해서 jointly하게 align과 translate를 학습하는 encoder-decoder 모델의 확장판을 소개합니다. 제안된 모델은 번역하는 과정에서 단어를 생성할 때마다 source sentence에서 가장 관련된 정보가 집중된 위치 set을 검색합니다. 그런 다음 모델은 이러한 source position과 관련된 context vector와 이전에 생성한 모든 target word를 기반으로 현재의 target word를 예측합니다.
basic encoder-decoder과 이 접근 방식과의 가장 큰 중요한 차이는 “전체 input sentence를 하나의 고정된 길이의 vector로 encoding하지 않는다”는 것입니다. 대신 input sentence를 일련의 vector로 encoding하고 translation을 decoding하는 동안 adaptively하게 vector의 subset을 선택합니다. 이렇게 진행하면 모델이 길이에 관계없이 source sentence를 고정된 길이의 vector로 쪼갤 필요가 없어집니다. 그렇기 때문에 모델은 긴 문장에 더 잘 대처할 수 있음을 보여줍니다.
<2. Background : Neural Machine Translation>
위에서 계속 인공신경망 기계 번역이 최근에 등장한 것이라고 언급하였는데 그러면 기존의 방법론은 무엇일까요? 기존의 방식인 확률론적 방법은 기계 번역을 source sentence x가 주어졌을 때 y 의 조건부 확률을 최대화하는 target sentence y를 찾는 것과 같습니다. (즉, argmax_y{p(y|x)}과 동일합니다.) 인공신경망 기계 번역에서는 병렬 training corpus를 이용하여 sentence pair의 조건부 확률을 극대화하도록 model을 fit 합니다. 번역 모델에 의해서 conditional distribution이 학습되면, source sentence가 주어지는 경우 조건부 확률을 최대화하는 sentence를 검색하여 해당 번역을 생성할 수 있습니다.
이 논문 이전에는 많은 수의 논문이 직접적으로 conditional distribution을 학습하는 인공신경망을 제안하였습니다. 이러한 인공신경망 기계 번역 접근 방식은 전형적으로 2개의 요소로 구성되어 있는데, 첫번째 구성요소는 source sentence x를 encoding하고, 두번째 구성요소는 target sentence y를 decoding 합니다. 예를 들어, 두개의 recurrent neural network가 있다고 해봅시다. 이 RNN을 통해 가변 길이의 sorce sentence를 고정된 길이의 vector로 인코딩한 뒤, vector를 가변 길이의 target sentence로 디코딩 합니다.
<2.1 RNN Encoder-Decoder>
위에서 계속 언급된 RNN Encoder-Decoder 구조에 대해서 더 자세히 보도록 합시다. Encoder-Decoder Framework에서는, encoder는 input sentence x=(x_1, x_2, …, x_{T_s})을 고정된 길이의 벡터 c로 변환시킵니다. [식 1-1]은 h_t \in \mathbb{R}^n은 time t에 대한 hidden state를 의미하며, [식 1-2]의 c는 hidden state의 sequence로부터 생성한 벡터를 의미합니다. f와 g는 nonlinear fuction을 의미합니다.
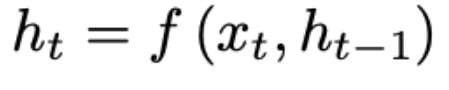
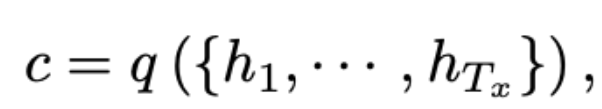
decoder는 이전에 예측한 결과 {y_1, … ,y_{t’-1}와 context vector c가 주어진 상태에서 다음 단어 y_{t’}을 예측합니다. 번역된 결과 y=(y_1, …, y_{T_y})는 [식 2]와 같은 조건부 확률을 기반으로 생성됩니다. 조건부 확률은 바로 직전 time인 (t-1)에서 예측한 결과 y_{t-1}과, RNN의 hidden state s_t, 그리고 nonlinear function g를 이용해서 구할 수 있습니다. ([식 3]참고)
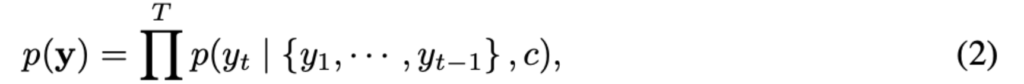
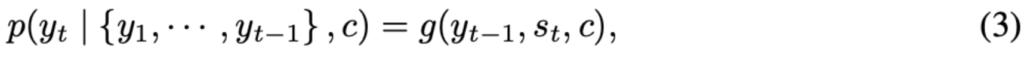
<3. Learning to align and translate>
이 파트에서는 논문의 저자가 제안한 방법(즉, attention)에 대해서 설명하고자 합니다. 동일하게 encoder-decoder 구조를 가지며, encoder로 bidirectional RNN을 사용합니다. 논문에서는 attention을 강조하기 위함인지 decoder를 먼저 언급하였지만, 저는 이해를 돕기 위해 encoder부터 먼저 설명드리고자 합니다.
<3.1 Encoder: Bidirectional RNN for Annotating Sequences>
보통의 RNN은 첫번째 글자부터 마지막 글자까지 순차적으로 읽습니다. 하지만 논문에서는 이전 단어와 다음 단어 모두에 대한 annotation을 담기 위해 bidirectional RNN을 제안합니다.
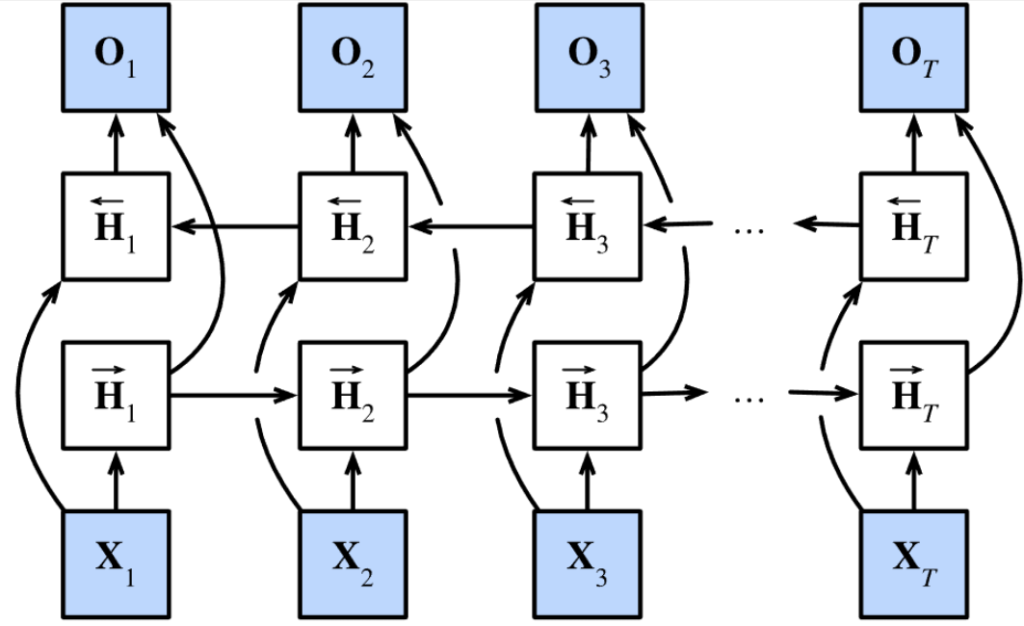
BiRNN은 forward와 backward로 구성되어 있는데, forward \vec{f}는 순방향으로 input sequence를 읽어 forward hidden state(\vec{f}i, …, \vec{f}{T_x})를 계산하고, backward \overleftarrow{f}는 sequence를 역방향으로 읽고 backward hidden state (\overleftarrow{h}1, …, \overleftarrow{h}{T_x})를 계산합니다. 이후에는 forward hidden state \vec{h}_j와 backward hidden state \overleftarrow{h}_j를 concat하여 (hj = [\vec{f}^T_j, \overleftarrow{h}_j^T]) word x_j에 대한 annotation을 만듭니다. 이렇게 만든 annotation h_j는 이전 단어와 다음 단어에 대한 정보를 가지고 있게 됩니다. RNN은 새로 들어온 입력을 더 잘 표현하는 경향이 있기 때문에 annotation h_j는 x_j 주변 단어에 집중하게 될 것입니다. 이러한 annotation sequence는 나중에 alignment model에서 context vector를 계산하는데 사용됩니다.
<3.2 Decoder : General Description>
자 이제 decoder part 입니다. encoder part에서는 기존의 방법론에서 딱히 특별한 차이점이 보이지 않았는데요. decoder part부터는 논문의 저자가 제안한 방법론을 본격적으로 설명합니다.
논문의 저자가 제안한 모델 구조에서, 각 조건부 확률을 아래와 같은 식으로 정의하였습니다.
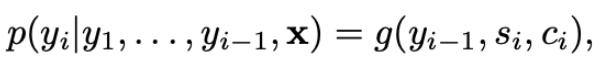
여기에서 s_t는 time t에서 RNN의 hidden state를 의미하며 s_t 계산 식은 아래와 같습니다.
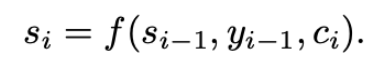
기존의 존재하는 encoder-decoder 방식과는 달리, context vector c_i는 target word y_i에 고유한 값입니다. encoder 파트에서 설명한 것처럼 context vector c는 annotation이라 불리는 h_i, … h_{T_x}값에 의해 결정되며, h_i는 input sequence에서 i번째 word 주변에 focus된 정보를 포함하고 있습니다. c_i는 h_i의 weighted sum으로 계산되는데 식은 아래와 같습니다.
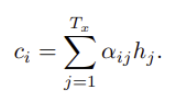
wighte a_{ij}는 아래의 식으로 계산됩니다.
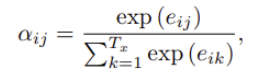
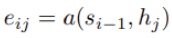
여기서 e_{ij}는 input의 j번째 주변과 output의 i번째가 얼마나 잘 match되는지에 대한 score를 의미하는데요. 여기서 a를 alignment model이라 부르는데 feedforwad neural network로 만들어지며, 전통적인 MT에서와 달리 latent variable가 아닌 직접적으로 계산됩니다.
위를 통해 모든 annotation에 대해 weighted sum을 하는 것은 모든 가능한 alignment에 대해 기대값을 계산하는 것으로 이해할 수 있습니다. 예를 들어서, a_{ij}를 target word y_i가 source word x_j일 확률이라고 해봅시다. 그러면 i번째 context vector c_i는 모든 annotation에 대한 기대값을 의미합니다. next state s_i를 결정하고 y_i를 생성할 때, 확률 a_{ij} 혹은 energy e_{ij}는 이전 hidden state s_{i-1}을 이용하여 annotation h_j의 중요성을 반영합니다.
이러한 메카니즘을 attention이라고 부릅니다. decoder에서 attention을 수행함으로써, encoder가 내source sentence에 대해 모든 벙보를 고정된 크기의 vector에 담아야 되는 부담을 덜어줍니다.
<4. Experiment Setting>
<4.1 Dataset>
- WMT ’14의 English-French parallel corpora를 사용.
- monolingual data는 사용하지 않음.
<4.2 Models>
실험을 위해서 2개의 모델을 사용하였습니다.
- RNN Encoder-Decoder (RNNencdec)
- (논문에서 제안한 모델) RNNsearch
위 두개의 모델을 각각 두번 학습 시킵니다. 첫 학습에는 최대 30개 단어로 구성된 문장에 대해서 학습하고 (이를 RNNencdec-30, RNNsearch-30라고 부릅니다), 두 번째 학습에는 최대 50개 단어로 구성된 문장에 대해서 학습 합니다. (이를 RNNencde-50, RNNsearch-50이라고 부릅니다)
RNNencde의 경우 encoder와 decoder가 1000개의 hidden unit을 보유합니다. RNNsearch의 경우, encoder는 forward/backward 각각 1000개의 hidden unit을 보유하며, decoder도 마찬가지로 1000개의 hidden unit을 보유합니다.
세부 디테일로는 minibatch SGD를 사용했으며, minibatch는 80개의 문장으로 구성되었고, 총 5일 동안 학습하였습니다.
<5. Results>
<5.1 Quantitative Results>
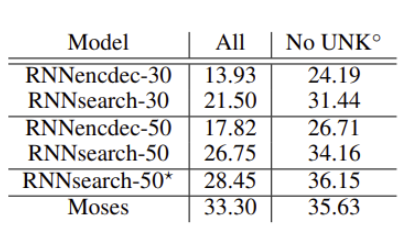
번역 성능은 BLEU score기반으로 측정하여 평가였습니다. Table1에 두 번째 열은 모든 문장에 대해서 성능 평가를 했을 때, 세 번째 열은 모르는 단어가 없는 문장에 대해서 성능 평가를 진행한 점수를 의미합니다. 여기에서 RNNsearch-50*은 성능이 더 이상 향상되지 않을 때까지 학습시켰음을 의미합니다.
Table1을 보면 모든 경우에서 RNNsearch가 RNNencdec에 비해서 높은 성능을 기록한 것을 확인할 수 있습니다. Table 1에서 Moses는 기존의 구문 기반 번역 시스템을 의미하는데, 역시나 RNNsearch가 Moses에서 더 높은 성능을 보여주는 것을 확인할 수 있습니다. (RNNsearch-50* 36.15 > Moses 35.63)
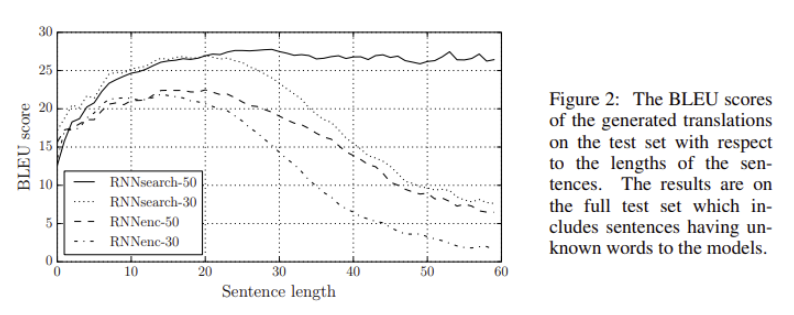
논문에서 제안한 모델의 가장 큰 장점 중 하나는 source sentence를 하나의 고정된 길이의 벡터로 변환하지 않아도 된다는 점입니다. source sentence를 하나의 고정 길이의 벡터로 변환하는 경우, Figure 2를 통해 문장의 길이가 길어질수록 성능이 하락하는 것을 확인할 수 있습니다. 하지만 RNNsearch-30, RNNsearch-50의 경우, source sentence가 길어져도 어느정도 일관된 성능을 제공하는 것을 확인할 수 있고, 특히 RNNsearch-50은 50 단어 이상의 단어로 구성된 문장에서도 (즉, 문장의 길이가 길어져도) 성능 저하가 없다는 것을 확인할 수 있습니다.
<5.2 Qualtative Analysis>
<5.2.1 Allignment>
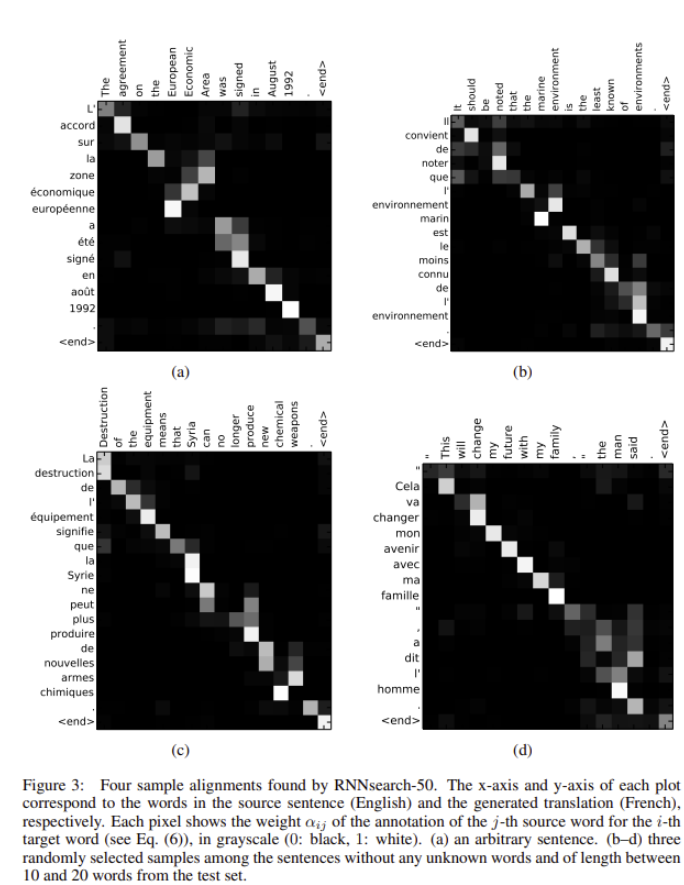
Figure 3는 annotation weghts a_{ij}를 시각화 한 것입니다. plot의 각 행은 annotation과 관련된 가중치를 나타냅니다. 이를 통해 source sentence에서 어느 위치가 더 중요하게 고려되었는지 확인할 수 있습니다.
<5.2.2 Long Sentences>
Figure 2를 보면 RNNsearch가 기존의 모델RNNencdec에 비해서 훨씬 더 긴 문장이 들어왔을 때 성능이 높습니다. 이는 RNNsearch가 긴 문장을 고정된 길이의 vector로 인코딩할 필요 없이 입력 문장에서 특정 단어를 둘러싼 부분만 정확하게 인코딩하면 되기 때문입니다. 예를 들어서 확인해봅시다.

RNNencdec-50이 번역한 문장을 살펴보면, [medical centre]까지 제대로 번역하였으나 밑줄 친 부분부터는 제대로 번역하지 못한 것을 확인할 수 있습니다.

반면에 RNNsearch는 제대로 번역을 수행한 것을 확인할 수 있습니다. (위의 문장)
논문을 읽기 전에 transformer 논문인 ‘attention is all you need’를 읽은 상태에서 리뷰를 하였는데, 쿼리, 키, 값이 정확히 무엇을 의미하고 어떻게 들어가는지에 대해서 논문에서 다루는 줄 알았으나 오히려 쿼리, 키, 값 같은 단어가 한 번도 등장하지 않아 흥미로웠습니다. 아마 이 이후에 나오는 논문들을 통해서 attention이 자리 잡으면서 쿼리, 키, 값 같은 단어가 등장한 것은 아닌가 싶습니다. 이렇게 리뷰 마치도록 하겠습니다. 읽어주셔서 감사합니다.
안녕하세요, 좋은 리뷰 감사합니다.
최근에 Chat-GPT의 애용자로서 NLP 분야도 관심을 가지고 있어 주연님의 논문 리뷰를 보게 되었습니다.
Bidirectional RNN에 대해 설명을 해주셨는데 이는 순방향과 역방향을 하면서 분명 computational cost가 클 것 같은데 이와 비교해서 최근 방법론들도 역방향으로 하는 연산을 똑같이 수행하는지 궁금합니다.
감사합니다.
안녕하세요. 댓글 감사합니다.
chatGPT 애용자를 만나 영광입니다^^ Bidirectional RNN을 사용하는 이유는 희진님 말씀대로 양방향 모두 보기 위해서 사용합니다. RNN을 두 layer로 사용하니 순방향 RNN에 비해서 당연히 computational cost가 클 것입니다. 최근 방법론도 양방향으로 보는데 차별점이 있다면 RNN을 사용해서 보지 않습니다. transformer를 사용하여 양방향을 보죠. 그 유명한 bert가 양방향으로 입력을 보는 transformer 기반의 모델입니다. 두 layer의 RNN을 사용해서 양방향으로 보는 것이 아니기 때문에 computational cost는 정확히 비교한 것은 아니지만 작을 것 같네요.
감사합니다
안녕하세요, 김주연 연구원님. 좋은 리뷰 감사합니다.
안 그래도 최근 논문 리뷰를 보면 ViT를 적용하지 않은 모델이 없어서 attention->transformer로 이어지는 모델 발전 흐름에 대해 follow-up 해야겠다는 생각을 계속 하고 있었는데, 마침 김주연 연구원님이 좋은 리뷰를 작성해주어서 읽어보게 되었습니다.
리뷰를 짧게 요약하지면, ‘기존 인공신경망 기계번역 모델은 encoder-decoder 모델에서 source sentence를 고정길이vector로 바꾸어 처리하기 때문에 긴 문장이 들어왔을 때 제대로 처리하지 못하는 문제가 있었는데, 논문에서 제안한 방법론은 (decoder에서 attention을 수행해서) 이러한 단점을 해소하고, 긴 문장이 들어왔을때의 성능을 개선하였다’ 정도가 될 수 있을 것 같습니다.
혹시 논문 제목 중 ‘jointly learning to align and translate’ 부분에서, ‘jointly’와 ‘align’이 정확히 무엇을 의미하는지 알 수 있을까요? 해당 task에 대해 잘 알고 있는게 아니라서 그런건지 잘 와닿지가 않습니다.
감사합니다.
안녕하세요. 댓글 감사합니다.
허재연 연구원님께서 이해하신 바가 정확히 맞습니다. 논문 제목에서 jointly라는 것은 encoder와 decoder를 jointly하게 학습한다는 것으로 저는 이해하였고, 여기서 align은 attention을 의미하는 것으로 이해하였습니다. 논문에서는 attention이라는 워딩은 사용하지 않았고 alignment model이라고 표현하여 사용하였기 때문입니다.
감사합니다.