안녕하세요. 오늘은 아직 publication된건 아닌데 WACV-2023에 붙은 Generic event boundary detection 논문을 가져왔습니다. 이 task가 생긴지 얼마 안되서 정말 간간히 나오네요. (참고로 저희 이번 논문에도 이 task reference로 하나 추가해서, 열심히 읽은 보람이 있었습니다.) 아무튼 시작해보겠습니다. 물론 시작하기전에 Task 자체에 대한 내용은 **[CVPR-2022] UBoCo : Unsupervised Boundary Contrastive Learning for Generic Event Boundary Detection**에서 확인하실 수 있습니다.
Introduction
Task에 대한 설명을 읽고 오셨을 것이라고 생각하고 본론으로 바로 넘어가겠습니다. 일단 Generic event boundary detection(GEBD)에서 어려운 점은 spatial한 다양성과 temporal한 다양성에서 기인합니다. Spatial한 다양성에서는 low-level change(밝기)과 high-level change(촬영 각도 및 촬영 중인 물체 변화)로 정의될 수 있고, Temporal한 다양성은 이제 action이 시간에 흐름에 따라 변한다는 것으로 정의할 수 있습니다.
여러분들이 Action 비디오 데이터셋으로 분류될 수 있는 ActivityNet이나 UCF 같은 데이터셋 말고, EPIC-kitchen과 같은 데이터셋을 알고 있다면 이해가 쉬울 것 같은데요. 하나의 주제(행동)는 맞는데, 다양성이 높다고 표현할 수 있는 장면들이 많이 등장합니다.
그래서 이 논문에서는 이 어려움을 해결을 해야 한다는 것에 중점을 맞췄습니다. 이를 위해서 Contribution을 아래 3가지로 정리할 수 있습니다.
- VCLR(Video Contrastive Learning with Global Context) 이라는 simple self-supervised method을 기반으로 하여, 비디오를 frame-level와 clip-level로 분할하여 학습을 수행하는 cVCLR을 제안
- 다른 모달리티를 사용하는 앙상블 방법론 없이 self-supervised 방식의 SOTA 달성
- Motion-feature 없이도 self-supervised를 통해 motion을 학습할 수 있음을 보임
Method
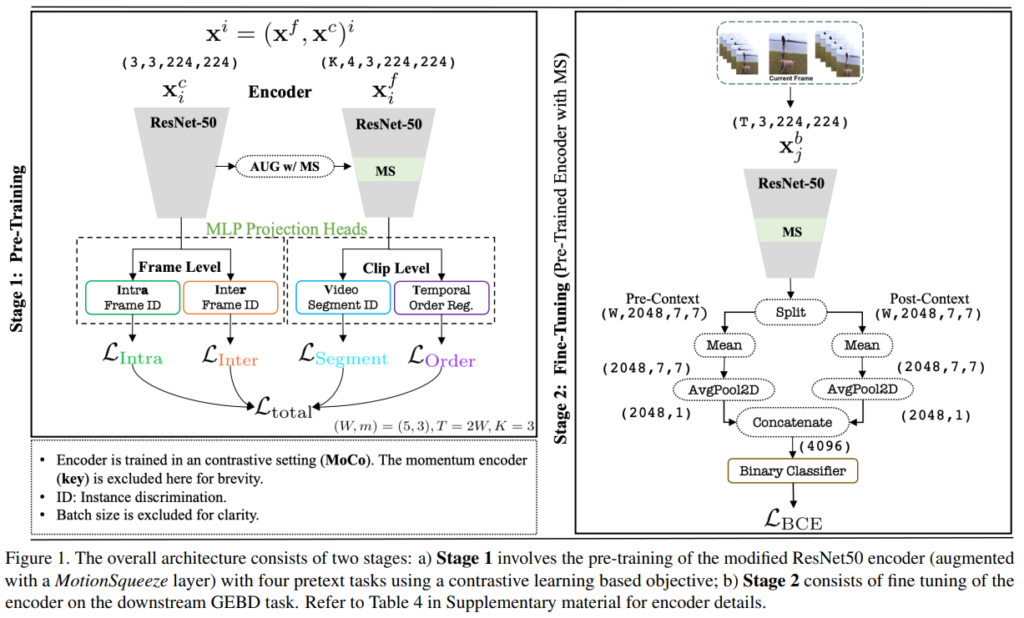
기본적인 모델을 보면, VCLR의 방법론을 기본적으로 따릅니다. VCLR의 경우에는 MoCo를 사용하기 때문에 여기서도 MoCo를 사용하고요. 그럼 VCLR이 무엇이냐? Video-level feature와 Clip-level feature를 활용하는 contrastive learning이라고 정리할 수 있을 것 같습니다.
SSL for Video Representation Learning
Preliminary
그림에서는 일단 4가지 Loss가 있는데, 하나하나 순차적으로 알아보기 전에… 기본적으로 학습하는 규칙에 대해서 먼저 알아보겠습니다. 각각의 Loss는 InfoNCE Loss를 통해서 학습을 수행합니다. InfoNCE는 x_p, x_q, x_n을 바탕으로 학습이 되는데요. Q는 anchor(자기자신), P는 Q의 augmentation을 적용한 이미지. 그리고 N은 negative sample이라고 보면 됩니다. 그래서 Q-P는 유사도가 가까워지게, Q-N은 멀어지는 형태로 표현력을 학습을 수행합니다. 추가적으로 Resnet50 encoder를 f(-)로 표현하고, MLP projection head는 g(-)로 표현합니다.
또, 이제 학습을 어떻게 하는지 알아보기 전에 알아야할 것이 하나 더 있습니다. 바로 그림의 Frame-Level과 Clip-Level에 대한 내용인데요. 먼저 frame-level pretext task를 보면 Intra-Frame ID와 Inter-Frame ID로 구분되는 것을 볼 수 있습니다. 이 프레임들은 비디오 내에서 랜덤으로 선택됩니다. (이 프레임들을 v_1, v_2, v_3로 정의) 여기서 v_1과 v_2에 같은 augmentation을 붙이고, v_3와 v_1에 같은 augmentation을 적용하여 각각 v_1^a과 v_1^+를 만들 수 있습니다. 최종적으로 query encoder에는 v_1^a만 태워서 f_q(v_1^a)로 표현하고, key encoder에는 나머지를 태워서 f_k(-)로 표현할 수 있습니다.
Clip-level pretext task의 경우에는 비디오를 K(논문에서는 3으로 설정)개 만큼 분할한 세그먼트로 나눕니다. Notation이 되게 많은데 뒤에 내용을 읽어보니, 그냥 이 세그먼트를 페어로 구성해서 t^a = \{c_1^a,c_2^a...c_K^a\}와 t^+ = \{c_1^+,c_2^+...c_K^+\}로 표현할 수 있는데 여기서 이 t^a와 t^p가 각각 anchor tuple, positive tuple이라는 점만 알면 될 것 같네요. 비디오를 나눠서 튜플 페어를 만든다 정도로 정리할 수 있을 것 같습니다.
자 이제 진짜 메인 학습은 이제 L_{total}로 적힌 Loss를 학습시키는 것인데요. Self-supervised 분야에서는 이걸 pretext task라고 부르더라고요. 아무튼 이 4가지 pretext task를 학습시키는 방법에 대해서 알아보겠습니다. (참고로 VCLR에서도 이렇게 학습한다고 하네요.)
Pretext tasks
Infra-frame ID task
Sptial한 다양성을 보장하기 위해서 학습을 하는 task 입니다. 이 Task에서는 v_1^+만 positive로 두고, v_2와 v_3는 negative로 가정합니다. 그래서 2번 InfoNCE Loss를 학습을 하는데요. 각각의 수식은 밑에 정리해 두었습니다.
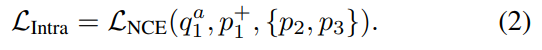
- Anchor : q_1^a = g^r_q(f_q(v_1^a))
- Positive : p_1^+ = g_k^r(f_k(v_1^+))
- Negative : p_2 = g_k^r(f_k(v_2)), p_3 = g_k^r(f_k(v_3))
즉, Infra-frame ID task에서는 같은 비디오 내의 프레임들 끼리의 구분할 수 있는 표현력을 학습하는 것을 목적으로 합니다.
Inter-frame ID task
이벤트 경계면을 탐지하려면 temporal한 구조에 대한 학습을 할 필요가 있습니다. 이를 위해서 이 Task에서는 v_1^a를 anchor 프레임으로 두고, (v_1^+, v_2, v_3)를 positive 프레임으로 둡니다. Negative는 다른 비디오에서 샘플링하는 N^-를 쓰고요. 그래서 여기서도 정리를 해보면 아래와 같습니다.
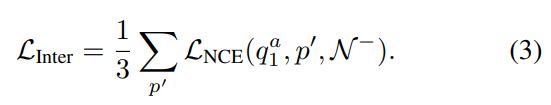
- Anchor : q_1^a = g^e_q(f_q(v_1^a))
- Positive : p_1^+ = g_k^e(f_k(v_1^+)), p_2 = g_k^e(f_k(v_2)), p_3 = g_k^e(f_k(v_3))
- Negative : N^-
Inter-frame ID task에서는 서로 다른 비디오 끼리의 프레임을 구분할 수 있는 표현력을 학습한다고 보시면 됩니다.
Video segment based ID task
Long range temporal diversity를 학습하는 것이 GEBD에서는 중요한데요. 이러한 Temporal 한 정보를 학습하기 위해서는 video-level의 global information을 활용하는 것이 중요합니다. 이를 위하여 앞선 두 task는 frame-level의 학습이었지만, 여기서부터는 clip 단위의 학습을 수행합니다.
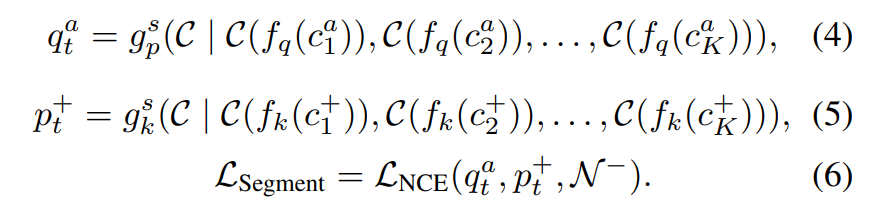
4/5번 수식은 이제 anchor, positive clip이 어떻게 구성되는지를 보여주는데요. Preliminary랑 비교해서 보셔야 notation이 이해가 갈 것 같긴 한데, 어쨋든 비디오 내의 clip을 평균을 취해서 video-level embedding을 수행해주면 q_t^a, p_t^+가 나온다고 보면 될 것 같습니다. Loss와 목적 자체는 Inter-frame ID task과 유사한데, 차이점은 이제 clip 단위로 수행된다는 점이 다릅니다.
Temporal order regularization task
위에서 설명하는 task는 다 VCLR에서도 사용하고 있습니다. VCLR과 이 논문의 가장 큰 차이점이 바로 이 부분에서 발생합니다. 이 논문에서는 시간에 따른 정보를 잘 학습하기 위해서 학습 과정에서 ID 값들이 정렬되도록 regularization을 적용해주었습니다. 이 부분이 L_{Order}이고, 이 차이로 인하여 이 방법을 cVCLR(clip VCLR)이라고 명명했다고 합니다.
Motion Estimation
Optical Flow없이 motion 정보를 어떻게 잘 추론할 것인가에 대한 해답으로, [그림 1]에도 등장하는 MS(Motion Squeeze) module을 사용합니다. 간단하게만 요약하면, 기존의 feature map에서 flow 정보를 대체할 수 있는 D^{(t)}를 구해서, 이 D^{(t)}로 부터 relveant motion feature M^{(t)}를 구해서, 기존의 Feature map F^{(t)}에 더해주면 모션 정보를 활용할 수 있다고 합니다.
이 모듈을 이 논문에서 제안한 것은 아니고, ECCV 2020에 나왔던 논문을 잘 활용했다고 하네요. 이해를 해서 정리를 해드리고는 싶은데, 이 논문에서도 디테일은 reference 가서 보라고 되어있고 안보니까 이해가 잘 안되네요… 나중에 해당 논문을 읽어서 따로 리뷰를 작성하겠습니다.
Optimisation
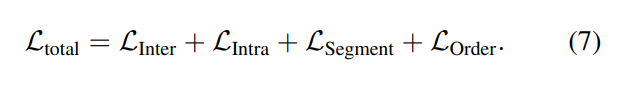
그래서 최종적으로는 위의 4가지 Loss를 모두 더하는 형태로 학습을 진행하는데요. MS 모듈 덕분에 visual 적인 측면과 motion 측면에서 둘 다 잘 보도록 encoder를 학습할 수 있었다고 합니다.
Experiment
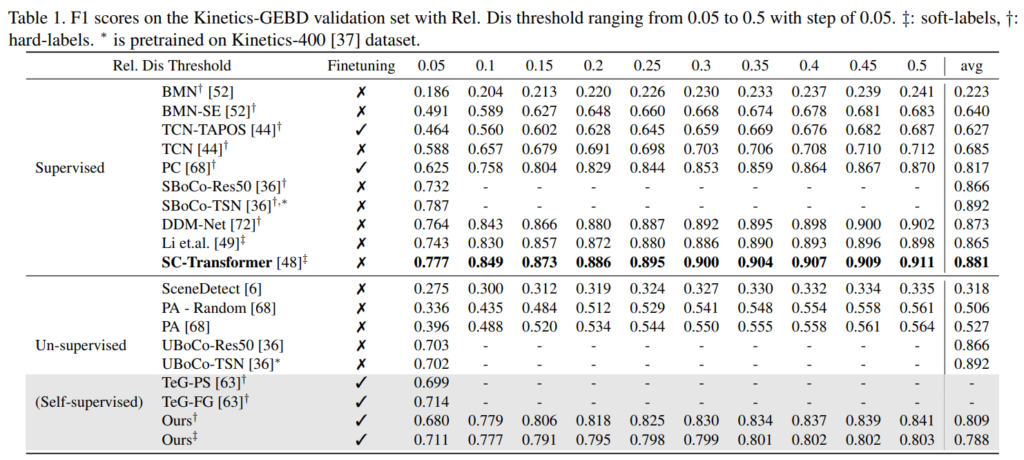
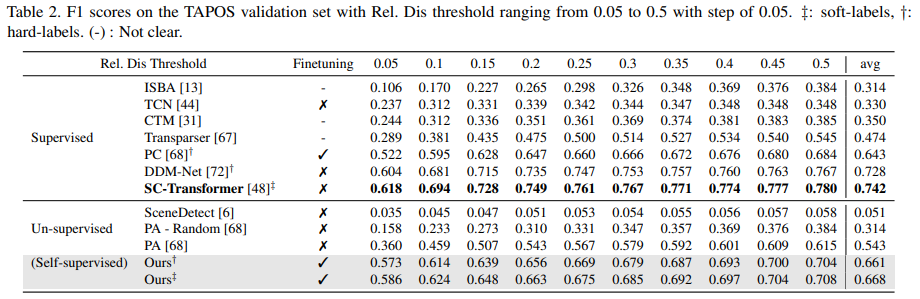
그래서 성능 부분을 보자면 두 데이터셋에서 모두 Self-supervised 기반 방법론에서 높은 성능을 보이는 것을 볼 수 있습니다. 다만 그 높은 성능이 finetuning을 적용한 성능이고, 안 했을 경우에는 제가 최근에 리뷰한 un-supervised 기반의 UBoCo보다 낮은 것을 볼 수 있습니다. (참고로 Finetuning은 이벤트 경계면을 탐지할 수 있게 T 프레임을 슬라이딩하면서 이진 분류 학습을 추가로 수행했다고 보시면 됩니다.)
그렇다고는 하지만 해당 모델이 Kinetics-GEBD에서만 학습을 수행하고 TAPOS 데이터셋에서 평가를 하는 것을 감안하고 [표 2]를 보면 데이터셋이 바뀌었음에도 불구하고 높은 성능을 보이는 것을 확인할 수 있습니다. 논문에서는 MS 모듈이 일반화된 모션 정보를 잘 학습했기 때문이라고 분석합니다.

실제로 GT와 비교를 해보면 뭔가 좀 아쉬운 것 같긴 한데 성능을 생각해보면 당연한 결과 같기도 합니다. 그래도 비교군과 대조해보면 그래도 잘 맞추는 것을 볼 수 있습니다. 아마 다른 방법론들이 코드 공개를 안해서 challenge때 공개된 대조군으로만 비교해서 더 그렇것 같긴 하네요.

마지막으로 motion을 얼마나 잘 보는지 정량적 결과를 볼 수 있는데요. 이게 잘 보일지는 모르겠는데, 잘 확대해서 보면 이미지에서 action이 있는 부분이 잘 캐치되고 있는 것을 확인할 수 있습니다. 참고로 학습 데이터셋과 다른 데이터셋에서 평가한 결과라 일반화된 motion 정보를 잘 학습했다는 말을 잘 증빙하고 있는 것 같습니다.
좋은 리뷰 감사합니다.
이벤트를 잘 구분하기 위해 여러 loss term을 이용하여 이벤트의 구분력을 높인 논문으로 보입니다.
한가지 궁금한 것은 이 논문이 제안한 것으로 보이는 order regularization이 어떻게 작용하는지 입니다. L_order가 수식적으로 어떻게 이루어져있는지나 작동 원리에 대해 설명해주실 수 있을까요??
논문에 기타 작동 원리가 세세하게 설명되어 있지는 않아서요. VCSL에서 페어를 구성할때 입력 순서를 신경쓰지 않는다면, 여기서는 페어를 학습할 때 입력 순서를 고려한다고 보면 좋을 것 같습니다. 자세한 내용은 VCSL을 봐야 이해가 될 부분이라… 나중에 보면 좀 연계해서 리뷰 추가하겠습니다.
리뷰 감사합니다. 궁금한 부분이 생겨 질문드립니다.
MS(Motion Squeeze) module의 동작 과정에 대해 아예 언급이 없나요?
예를 들면 frame 간의 difference를 구하던지, feature map간의 difference를 구한던지 등등
감사합니다.
T프레임과 T+1 프레임간의 correlation을 바탕으로 displacement matrix를 계산한다고 합니다. 하는 방법만 나와있고 원리는 없네요. 아무래도 원문을 봐야할 것 같습니다.