안녕하세요. 이번 논문은 감정인식 과제를 진행하면서 마주한 문제점에 대해서 참고하고자 리뷰하였는데요. 한국어 데이터셋이 가변 길이인데, 이것을 어떻게 가져가야 성능이 좋아질까 라는 생각을 하면서 읽었습니다. 리뷰 시작하겠습니다.
1. Introduction
Introduction에서 기존의 Speech Emotion Recognition에서 binary classification loss를 사용해서 model을 학습 시켰을 때 positive 쌍과 negative 쌍의 차이가 분명하지 않다는 것을 언급하며 이를 해결하기 위해서 triplet loss function을 사용한다고 말하고 있습니다. triplet loss function에 대한 자세한 설명은 아래에서 하도록 하겠습니다.
또한, Speech Emotion Recognition의 어려움으로 발화가 가변 길이를 가진다는 것을 꼽았는데, 본 논문에서는 이 부분을 해결하여 좋은 성능을 내었다고 말하고 있습니다.
2. Model
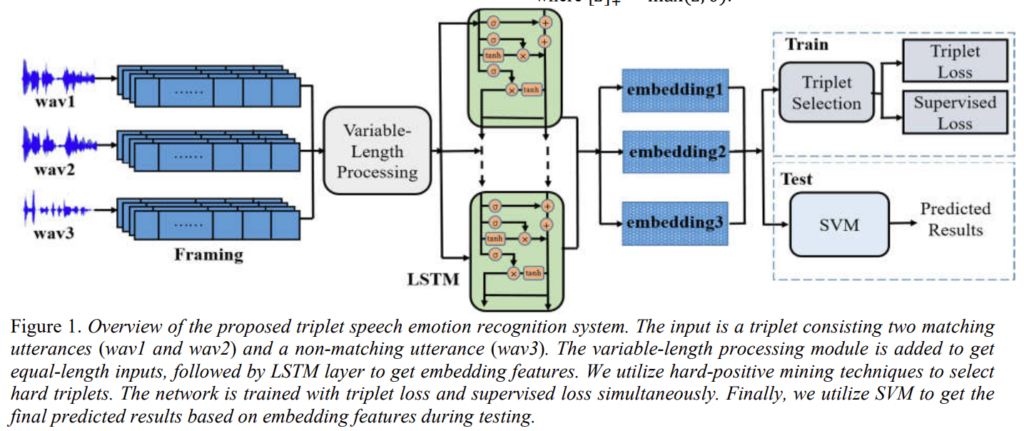
Figure 1을 통해 제안된 triplet speech emotion recognition system의 구조를 확인할 수 있습니다. 구조를 간략히 설명하면 이렇습니다.
system의 input은 두개의 매칭되는 발화와 매칭되지 않은 발화 하나로 구성된 triplet을 입력으로 받습니다. framing 이후에는 발화의 길이가 가변적이라는 점을 고려하여 가변 길이 처리 모듈을 추가하여 동일한 길이의 입력을 받을 수 있도록 합니다. LSTM으로 embedding feature를 얻습니다. 이후에는 학습을 효과적으로 하기 위해서 triplet을 선택하는 작업을 합니다. system은 triplet loss를 계산하여 positive pairs와 negative pairs와의 거리를 넓히고, 동시에 supervised loss를 계산하여 class label 정보를 통합합니다. 임베딩이 생성되면 SVM을 사용하여 테스트 중에 최종 예측 결과를 얻습니다.
이렇게 과정을 쭉 살폈지만 이해가 가지 않는 부분이 많으실 거라고 생각됩니다. 디테일한 부분은 아래를 설명을 통해 이해할 수 있도록 하였습니다.
2.1 Variable-length processing
제가 가장 궁금했던 부분입니다.
입력이 가변 길이를 가지는 경우, 대부분의 연구자들은 동일한 길이의 입력으로 맞추기 위해서 발화를 자르거나(cut) padding을 줍니다. 그런데 이런 경우 original emotional information을 잃을 수 있어 추천하지 않습니다.
이 논문에서는 이러한 문제를 다루기 위한 3가지 방법을 제시합니다. 우선 최종 길이를 결정하기 위해서 적절한 값을 가진 F를 설정합니다.
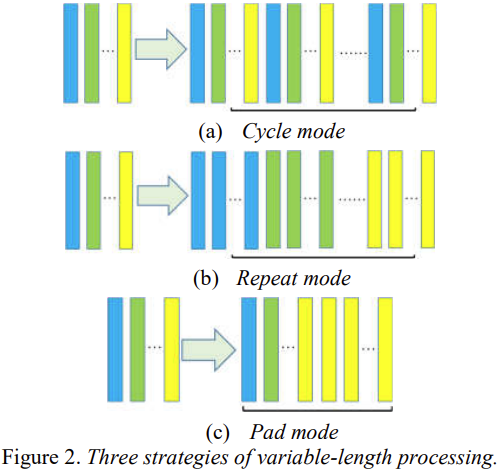
(a) Cycle mode : 최종 길이가 F 보다 클때까지 발화를 반복합니다. 모든 턴에서 발화 전체를 반복합니다.
(b) Repeat mode: (a)와 마찬가지로 최종 길이가 F 보다 클때까지 발화를 반복합니다. 차이점은 발화 전체를 반복하는 것이 아닌 single frame을 반복합니다.
(c) Pad mode : 입력 길이가 F와 같을 때까지 마지막 frame으로 padding 합니다.
(a), (b) 혹은 (c) 방법을 통해 frame을 구했으면, 중간 부분에서 랜덤하게 F 길이만큼 연속적인 frame을 가져옵니다. 이렇게하여 길이가 같은 frame을 구합니다.
더 부가 설명하자면, (a) cycle mode의 핵심 아이디어는 emotional dynamic 순환적이고 더 길게 만드는 것이라면, (b) Repeat mode의 핵심 아이디어는 emotional dynamic을 반복적이고 길게 만드는 것입니다.
위의 설명한 방법은 입력의 길이가 F 보다 짧을 때 사용하는 것인데, 그러면 입력 길이가 F 보다 길면 어떻게 처리할까요?
발화가 F 보다 길 경우, 저자는 유효한 emotional dynamic 정보는 발화의 중간 부분에 있다고 말합니다. 이것에 대한 자세한 설명은 없었는데, 상식적으로 생각했을 때 말의 첫 시작부터 감정 정보가 있기는 힘들기 때문에 그런 것은 아닌가 싶습니다. (아니면 wav file의 처음 시작 혹은 끝부분은 음성이 있지 않는 경우가 있으니 그것을 고려하여 말한 것은 아닌가 생각합니다.)
또한, 입력의 길이가 너무 크면 감정 예측에 부정적인 영향을 미칠 수 있기 때문에 F 보다 긴 발화는 head와 tail 부분을 잘라 사용할 수 있다고 말합니다.
2.2 Loss function
앞에서 잠깐 말씀드린 triplet loss에 대한 설명이 있습니다.
네트워크는 발화 x를 d 차원으로 인코딩하고 임베딩 feature를 f(x) ∊ ℝ^d 로 표현합니다.
tirplet loss의 경우 3가지 data를 요구합니다.
- anchor : 기준 data ( 발화 x^a_i)
- positive : anchor와 같은 class에 속하는 data ( 발화 x^p_i)
- negative : anchor와 다른 class에 속하는 data ( 발화 x^n_i)
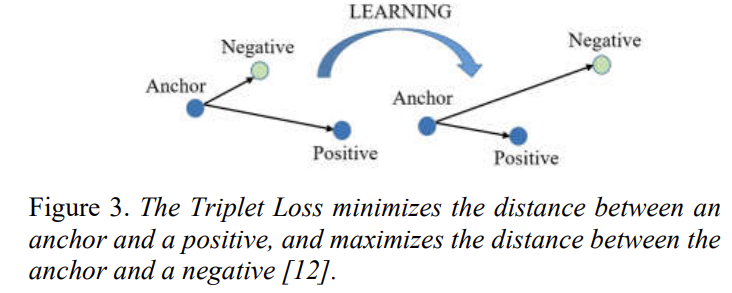
anchor x^a_i가 positive인 x^p_i와의 거리는 가깝게 하고, negative인 x^n_i와의 거리는 짧게 만드는 것을 목표합니다. Figure 3을 통해서 더 쉽게 이해할 수 있습니다.
위의 말을 식으로 정리하면 아래와 같은 식 (1)로 표현될 수 있습니다.
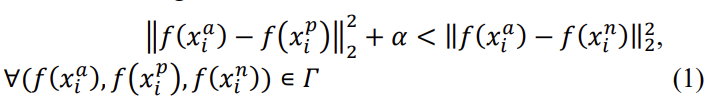
α는 positive와 negative 쌍 사이의 margin을 말합니다. 여기서 Γ는 training set에서 모든 가능한 triplet 집합을 말하며, cardinality N를 가지고 있습니다.
위의 설명을 종합하여, triplet loss는 아래 식 (2)와 같이 생겼습니다. network는 loss function L를 최소화 하는 방뱡으로 학습하게 됩니다. 즉, ||f(x^a_i) - f(x^p_i)||^2_2이 0에 수렴하고 ||f(x^a_i) - f(x^n_i)||^2_2은 ||f(x^a_i) - f(x^p_i)||^2_2 + α 보다 크게 하는 것을 목표로 학습하게 됩니다.
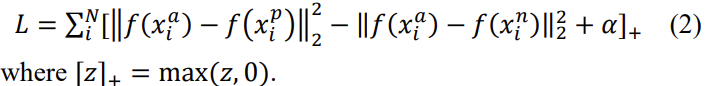
2.3 Triplet selection
여기서는 triplet을 어떻게 선택할지에 대해서 설명이 있습니다.
단순히 많은 수의 triplet을 사용했다고 학습에 도움이 되는 것도 아니고 수렴을 느리게 할 수도 있습니다. 그렇기 때문에 식 (1)에서 triplet 제한을 위반하는 triplet을 선택하는 것이 중요합니다.
이 말은 x^a_i가 주어졌을 때, x^p_i가 argmax_{x^p_i}||f(x^a_i) - f(x^p_i)||^2_2, 그리고 유사하게 x^n_i가 argmin_{x^n_i}||f(x^a_i) - f(x^n_i)||^2_2처럼 선택 되도록 하는 것을 말합니다.
그런데 설명한 것처럼 triplet을 선택한다면 argmax와 argmix를 계산해야 하는데, 전체 training set에서 argmin과 argmax는 계산하는 것이 불가능하기 때문에 mini-batch 안에서만 계산하여 선택합니다.
3. Dataset
논문에서 사용한 데이터셋은 IEMOCAP으로 Interactive Emotional Dyadic Motion Capture 데이터셋 입니다. 이 데이터셋을 가지고 총 5,531개의 발화를 사용했다고 합니다.
angry는 20%, sad는 19.6%, happy는 29.6% 그리고 neutral은 30.8%을 가진다고 합니다.
4. Experiments and Analysis
앞에서 설명한 방법론을 적용하여 실험한 결과 설명 입니다.
4.1 Effect of variable-length processing
입력이 가변 길이 일때 동일한 길이로 맞출수 있도록 제안한 3가지 방법의 성능을 비교하여 보여주고 있습니다. Figure 4를 통해 확인할 수 있습니다.
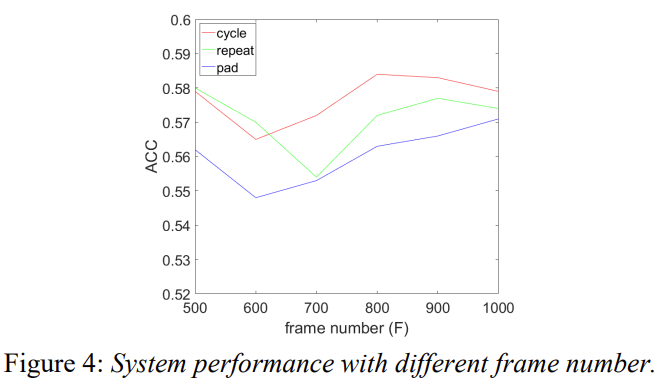
데이터셋 IEMOCAP에서 모든 발화의 평균 frame 수가 731이기 때문에 (max은 3409, min은 54, median은 654 입니다.) frame length를 0.06s로 설정하였습니다. 성능 비교를 위해서 basic LSTM network with cross-entropy objective를 사용하였습니다.
Figure 4를 보시면, cycle mode가 전반적으로 repeat mode보다 더 좋은 성능을 내는 것을 확인할 수 있고, pad mode이 성능이 가장 낮은 것을 확인할 수 있습니다. cycle mode는 F가 800에서 가장 정확도가 높았는데 repeat mode는 가장 짧은 frame 수에서 높은 정확도를 보였고 pad mode는 F가 클수록 정확도가 높습니다. 여기서 가장 의외인 것은 F가 median 값이랑 가까울때 3개의 mode 모두가 정확도가 낮았다는 것입니다.
4.2 Speech emotion recognition with triplet loss
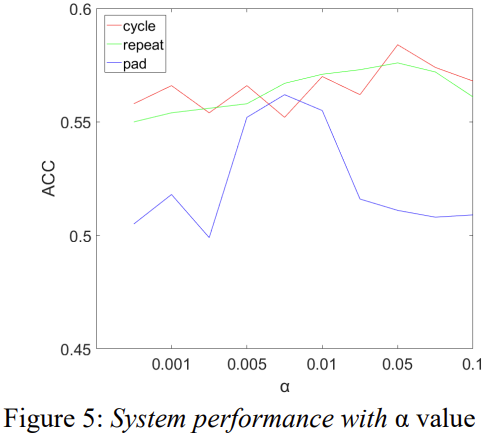
Figure 5를 통해 triplet loss의 α에 따른 성능 차이를 확인할 수 있습니다. α값이 클수록 cycle mode와 repeat mode의 성능이 증가하는 반면에 pad mode에서는 α가 중간에 있을 때 높은 정확도를 가집니다.
cycle mode와 repeat mode는 α가 약 0.05일때 성능이 가장 좋은 것을 확인할 수 있는데, α가 0.05보다 커질경우 성능이 떨어지는 모습을 확인할 수 있습니다. 이는 system이 hard positive 쌍과 hard negative 쌍 사이에서 triplet을 선택하는데 너무 harder한 triplet은 선택하지 않았음을 나타냅니다.


Table 1과 Table 2를 통해 정량적으로 성능을 확인할 수 있습니다. Table 1과 2의 차이는, 1의 경우 하이퍼 파라미터인 F만 최적으로 맞추었을 때의 성능이고, 2의 경우 하이퍼 파라미터인 F와 α를 최적으로 맞추었을 때의 성능입니다.
Table 1과 비교하여 Table 2에서 성능이 각각 0.8%, 1.1%, 1.6% 향상된 것을 확인할 수 있는데, 이를 통해서 triplet loss가 speech emotion recognition의 성능을 향상시킬 수 있다는 것을 알 수 있습니다.
5. Conclusion
사실 음성에서 가변 길이를 어떻게 다루는 지에 대해서 조언을 얻고 싶어 논문을 읽은 거지만, triplet loss 부분을 보면서 이 loss가 생각보다 유명한 loss라는 것을 알게 되었는데 공부하게 되어 뜻밖에 소득을 본 것 같아 좋습니다. 여태까지 감정 인식과 관련하여 읽은 논문들은 frame을 어떻게 가져갈지, loss는 어떤 것을 사용할지에 대해서 언급이 많이 없었는데 기존에 읽었던 것과는 다른 느낌의 논문을 읽게 되어 좋았습니다.
읽어주셔서 감사합니다.
좋은 리뷰 감사합니다.
제목 그대로 SER에 triplet loss를 적용하고, 가변 길이를 처리하기 위해 제안된 방법론이네요.
제가 리뷰를 읽으면서 궁금한 것이 두 가지가 있는데, 답변해주시면 감사하겠습니다.
1. 저자는 서론에서 positive / negative pair 차이가 분명하지 않다고 문제 정의를 하였는데, 이게 정확히 무엇을 의미하는지 모르겠네요…이에 대해 시각적으로 무엇이 문제인지 제시를 하는지? 즉, triplet loss를 적용하게 된 이유 및 분석이 있는지가 궁금합니다. 이런 음성인식 논문은 기존 연구의 문제점을 어떻게 파악하고 분석하는지를 알기 위해 질문드립니다.
2. 가변길이에 처리 방식에 대한 질문입니다.
가변 길이를 어떻게 처리하였는지를 보니, 결국 padding 의 일종으로 이를 개선시킨 것 같습니다. 이건 당장 우리 연구에도 적용시킬 수 있을 것 같긴 합니다만.. 너무 나이브 한 감이 있어서 최근 연구에서는 이런 가변적인 음성을 어떻게 처리하는 지 오히려 더 궁금해집니다. (뭔가 대단한 방식이 있을 것 같았으나 별 게 아니라 아쉬웠다고 할까요…?)
게다가 가변 길이에 대한 실험 역시 조금 아쉬운데요. 일반적으로 사용하던 padding 방식은 (c)라고 보면 되나요? 이 질문을 하는 이유가 가변 길이를 처리하는 3가지 방식을 제안하는 것에 비해 기존 padding/cut 방식과의 비교가 없기 때문입니다. 혹시 다른 데이터셋을 사용한 실험을 제시하나요? 만일 있다면 왜 (a) cycle이 가장 우수한 성능인지에 대한 분석이 있는지 궁금하네요. 우리의 데이터셋에 적용하기 위해서는 이 분석 내용을 알아야할 것 같은데….
그래도 이런 시도가 있으니 더욱 개선된 방법론이 있다는 얘기겠지요. 최신 연구들도 한번 읽고 리뷰해주시는 것을 기대해보겠습니다 ㅎㅎ
댓글 감사합니다.
1. 저자가 서론에서 positive / negative pair 차이가 분명하지 않다고 한 부분에 대해서는 정확이 이것이 무엇이다 설명한 것은 없고, 감정이라는 것이 모호한 것이고 감정을 분류하는 일은 감정끼리 큰 차이가 있지 않아 구분하기 힘들다는 것을 설명하기 위해서 나온 말입니다. 아마 triplet loss를 사용하면 positive는 가깝게, negative는 멀도록 학습이 되니까 이 점을 강조하기 위해서 넣은 말은 아닌가 싶습니다. triplet loss로 감정 간의 차이를 학습하여 감정 분류를 잘하겠다는 것이 이 논문의 주요 contribution인데, 이 부분을 어필하기 위해서는 실험 파트에서 triplet loss를 사용한 모델과 사용하지 않은 모델들과의 차이를 명확히 보여줬어야 한것은 아닌가 싶지만 실험 내용이 없어 아쉬운 부분입니다.
2. 가변길이에 대해서도 역시 아쉬운 부분입니다. 사실 이 논문에서 가변길이를 처리할 때 기존의 연구자들이 감정 정보를 하나도 살리지 못하고 그저 cut 하거나 0으로 padding 한다는 것을 지적하는데요. 그런데 정작 이 논문에서도 가변길이를 해결하기 위해서 padding을 하기 때문에 이것이 어떻게 contribution,,,? 이런 느낌도 듭니다.
(a) cycle 방식이 왜 우수한지에 대해서는 논문에서는 emotional dynamic을 잘 가져갔기 때문이라고 볼 수 있습니다. 사실 이 emotional dynamic에 대해서 별다른 설명이 없어 reference를 타고 들어가봤지만 역시 찾을 수가 없었는데, 제가 추측하면 감정이 어떤 한 부분에서 나타나는게 아니라 그 구간에서 똑같은 감정이라도 다르게 표현될 수 있는 거를 emotional dynamic이라고 표현한 것 같습니다. (a) 는 전체 발화를 반복하기 때문에 감정 정보가 손실되지 않고 들어갈 수 있는데, (b), (c)의 경우 하나의 프레임에 대해서 padding 하는것이기 때문에 정보가 손실되어 성능이 낮게 나온다고 생각하였습니다.
아마 이 논문이 18년도 논문이기 때문에 가변길이를 처리하는 방식이 나이브한 것은 아닌가 생각합니다. 다음 리뷰는 가변길이에 대해 다룬 최신 논문으로 들고오려고 합니다ㅎㅎ
감사합니다.