Intro
본 논문은 test-time adaptation에 constrastive learning을 접목한 논문이다. test-time adaptation이란, domain adaptation에 속하는 연구 분야 중 하나로, source data로 학습된 기본 모델을 target에 맞게 변형하기 위해 사용되는 기술이다. 보통 source data보다 정보량이 적은 target data를 이용해 모델을 adaptation 시키는 것을 목적으로 하며 서로 다른 두 도메인(source, target)이 분포적 유사성을 지닌 상태로 이동(shift)되었다고 기대될 때 적용가능하다. test-time adaptation은 그 중에서도 target data의 label을 필요로 하지 않는 unsupervised domain adaptation 기법으로 test time에서 얻을 수 있는 데이터를 통해 비지도학습 방식으로 모델을 업데이트 하는 방법론이다. 본 논문은 레이블이 없는 데이터를 통해 학습하기 위하여 노이즈를 개선한 pseudo label을 이용한 contrastive learning 기법을 적용하였다. 자세한 설명은 Method에 소개한다. 본 논문에서 제안한 방법론은 메모리 효율성, 하이퍼 파라미터 민감도 측면에서 우수한 특성을 보이며 주요 benchmarks와 비교해서 SOTA의 성능을 보였다고 한다.
Method
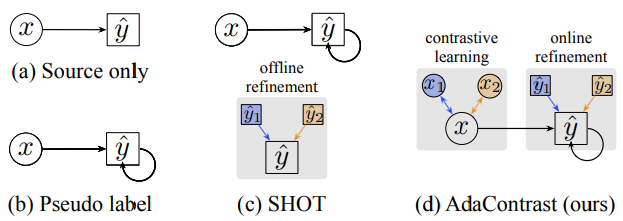
본 논문은 contrastive learning을 접목한 test-time adaptation 방법론을 제안했으며, 이름은 AdaConstrast 라고 명명하였다. 제안하는 방법론의 대략적인 소개는 fig1과 같다. (a)는 source data로 학습된 supervised learning 모델이 입력x에 대해 예측 y^을 생성하는 과정이다. (b)는 모델이 생성한 예측 y^를 다시 학습에 사용되는 pseudo label 방법론을 소개한다. 다음으로 (c)는 2020년 제안된 pseudo labeling 방법론인 SHOT[1]로, 예측y^를 바로 pseudo label로 사용하는것이 아닌, offline refinement라는 방법론을 도입해 노이즈를 개선한 pseudo label를 모델 재학습에 사용한다. 마지막으로 (d)가 제안하는 방법론인데, 입력데이터를 augmentation하여 multi-view입력으로 하고, 이를통해 생성된 예측값들로 예측값 y를 개선하여 학습에 사용한다. 그림에서 알 수 있듯이 SHOT와 다른 점은 test data를 직접적으로 사용하여 domain을 개선하며 contrastive learning의 아이디어를 도입하였다. 이어서 test-time에 어떻게 학습하는지 구체적으로 소개하겠다.
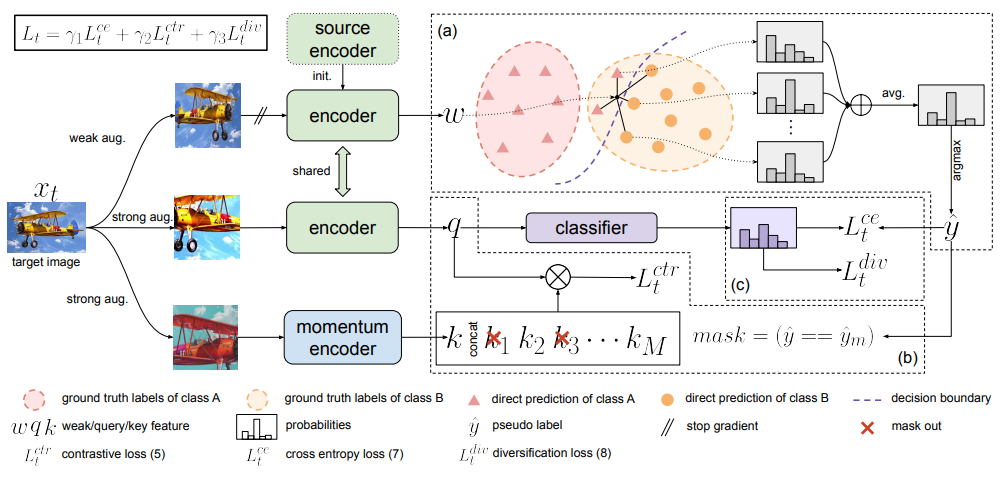
test data(이하 target data, 같은 정보를 칭하고 있음)를 통한 학습을 위해 MoCo 아케택처를 베이스로 학습을 개선했다고 한다. 먼저 입력된 target 데이터 x에 이미지 변환을 적용한다. 강한 변환을 적용한 strong aug 결과 2개(sx1′, sx2′), 약한 변환을 적용한 weak aug 결과(wx’) 한개를 통해 모델 학습을 진행한다. weak aug 데이터는 pseudo label 생성을 위해 사용되며, strong aug 중 하나는 moco 구조의 memory에 저장되어 metric learning에 사용되는 negative pair 생성을 위해 사용된다. 이때 metric learning이란 표현공간에서 의미적으로 유사한것을 가까이, 의미론적으로 먼 데이터는 멀도록 학습하는 방법론으로 의미적으로 가깝다고 판단되는 데이터를 positive pair, 멀다고 판단되는 쌍을 negative pair로 지정하여 학습에 이용한다. pseudo label 생성시 기존 방법론과 다르게 noise를 최소화하기 위한 regulation 방법론을 적용하였는데, 배치 내의 feature를 활용하여 파라미터로 지정한 k개의 최근접 이웃과의 평균을 pseudo label로 이용하였다고 한다. 제안하는 방법론은 총 3가지 loss(Loss_ce, Loss_div, Loss_ctr)를 구성하는데, 위와 같은 방식으로 생성된 pseudo label과 cross entropy loss를 통해 지도학습 방식과 유사한 메커니즘으로 학습하는것이 그림의 L_CE(Loss_ce) 이다. 다음으로 소개할 것은 L_ctr(Loss_ctr)이다. negative pair와 positive pair를 구성하여 metric learning을 적용하는 기존에 많이 사용하는 방법론을 이용했으며, negative pair로는 MoCo와 같이 batch 내에 자기자신이 아닌 모든 sample을 이용한다. 다만 차이점은 pseudo label이 있기 때문에, pseudo label상으로 같은 class에 속하는 batch 내 샘플은 negative pair로 이용하지 않는다. 위와 같은 개념을 infoNCE loss 로 설계한것이 L_ctr이다. 마지막으로 L_div는 Diversity regularization로 모델이 잘못된 pseudo label에 대헤 너무 신뢰하는 상황을 막기위해 제안한 regularization term으로 예측값의 class를 다양화하기 위한 loss이다. 식은 수식1과 같다.
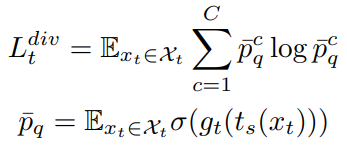
위에서 소개한 세가지 loss를 각 가중치 1로 하여 더한것이 모델의 최종 목적함수이다.
실험
실험 테이블은 총 4개로 구성되어 있으며, classification accuracy on VisDA-C, classification accuracy on DomainNet-126, VisDA-C와 DomainNet-126에 대해 기존 work인 SHOT[1]과의 상세한 비교, ablation study로 구성되었다. 또한 SHOT과 model calibration(domain adaptation 효과)를 상세하게 보이기 위한 시각화 그래프 하나와 memory queue size를 보이는 그래프도 포함된다. 앞선 내용으로 알 수 있듯이 실험은 VisDA-C 데이터와 DomainNet-126 데이터로 진행하였으며 DomainNet-126의 경우 데이터셋이 포함하는 많은 도메인 중 7가지의 도메인만 실험에 사용하였다고 한다. 기존 방법론과 비교해 제안하는 방법론의 우월성을 보이기 위한 주요 실험 두가지(classification on ~)는 아래와 같다.
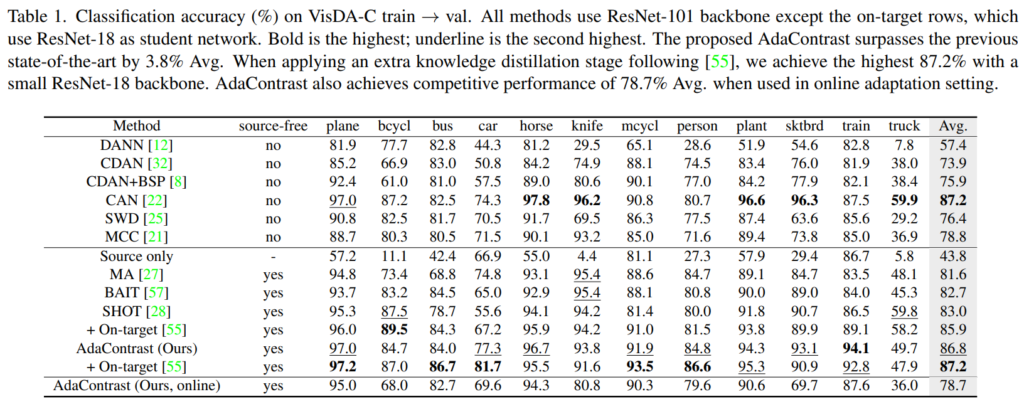
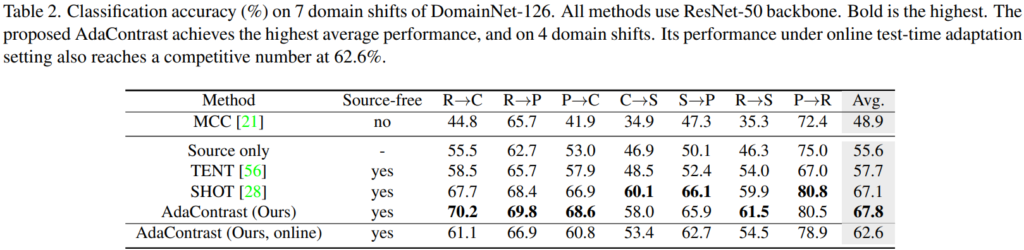
참조
[1] Liang, Jian, Dapeng Hu, and Jiashi Feng. “Do we really need to access the source data? source hypothesis transfer for unsupervised domain adaptation.” In International Conference on Machine Learning, pp. 6028-6039. PMLR, 2020.
생각할 점
contrastive learning이 잘되는 조건, test time adaptation이 잘 되는 조건 구성에 대해 생각해보자