본 서베이 [Link]는 IEEE 2017에 제출되었습니다.
Definition of Multi-Task Learning
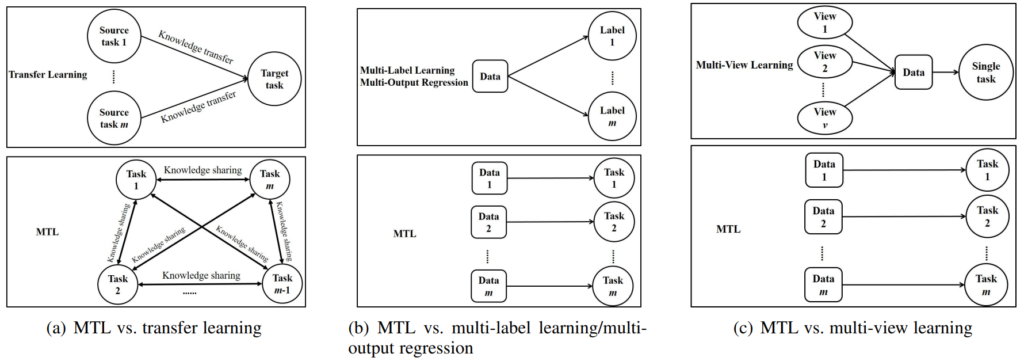
Multi-Task Learning(MTL)이란 모델이 학습을 더 잘하기 위해 m개의 tasks를 같이 학습하는 것을 의미합니다. MTL에는 다양한 접근법이 있는데, 각 접근법에 대해 소개하고, 본 서베이에서 집중적으로 소개할 MTL 방법론을 알려드리겠습니다. 가장 먼저 논문의 introduction에 적혀있는 1) MTL의 연구 배경에 대해 간단히 소개드리겠습니다. MTL 연구의 동기가된 중요 요인 중 하나는 놀랍게도 데이터셋의 양이라고 합니다. 지도학습기반의 각 테스크 모델을 학습하기 위한 가공데이터(이하, labeled data)의 수가 적을때, MTL은 테스크집합에 속한 labeled data를 모두 사용할 수 있어 데이터 부족 문제를 효과적으로 해결할 수 있습니다. 또한 MTL은 더 많은 데이터를 효율적으로 활용하기 때문에 single-task learning보다 더 좋은 성능을 보이는것이 일반적이라고 하네요. MTL과 자주 혼용되는 학습 패러다임으로 transfer learning, multi-label learning, multi-output regression이 있다고 합니다(그림1 참조). MTL은 transfer learning과 다르게 최종적으로 사용되는 target task가 하나이며, multi-label learnng, multi-output regression과 다르게 각 테스크에 할당된 여러 데이터를 사용할 수 있다고 합니다. 즉, multi-label learnng, multi-output regression의 경우 MTL의 연구 동기가 된 데이터셋 활용 능력 증가는 불가능한 것이지요. 또한 machine learning 방법론 중 하나인 multi-view learning와 비교하자면 multi-view learning는 여러 데이터를 활용하는 것이 아니라, 데이터를 통해 생성한 multi-view 데이터를 학습에 활용하여 강인한 single task 모델을 학습시키는 방법으로 MTL과는 다릅니다. 즉, MTL은 각 테스크를 학습하기 위한 여러 데이터를 한번에 학습에 사용할 수 있는 학습법입니다. 연구 동기에 대해 어느정도 소개를 마쳤으니, 2) MTL의 접근법에 대한 분류를 소개하겠습니다. 해당 분류 또한 데이터셋의 사용 방식에 따라 진행되었는데요, 4가지로 분류됩니다: heterogeneous MTL, heterogeneous-feature MTL, homogeneous MTL, homogeneous-feature MTL 이때, heterogeneous MTL와 homogeneous MTL가 대립되는 개념이고 heterogeneous-feature MTL와 homogeneous-feature MTL가 대립되는 개념입니다. 각 태스크 A와 해당 태스크의 학습데이터D(A), 태스크 B와 학습데이터 D(B)가 있다고 합시다. 모델에서 D(A)와 D(B)에 대한 feature representation space가 동일하다면 homogeneous-feature MTL이고 그 외는 heterogeneous-feature MTL입니다. 다음으로 heterogeneous MTL이란 각 태스크가 다른 종류의 학습을 포함하는 것입니다. 즉 superivsed learning, unsupervised learning, semi-supervised learning 등 다양한 학습을 포함한다는 뜻이지요. 반대로 homogeneous MTL은 하나의 학습을 의미합니다. 본 논문에서는 homogeneous MTL 특히 supervised learning 기반의 MTL 방법론에 대해 주로 서베이 하였다고 합니다.
수많은 MTL 방법론의 관계를 정리하기 위해 다음의 세가지 키워드로 각 방법론을 카태고리화 했다고 합니다: when to share, what to share, how to share. when to share의 가장 쉬운 접근법 중 하나는 cross validation을 통한 모든 퓨전 방식을 검토하는 것인데, 이는 당연하게도 큰 연산량을 요구하며 더 많은 데이터셋을 필요로해 MTL의 장점(데이터셋 활용도 증가)을 희석시킵니다. 최근에는 딥러닝 방법론을 통해 traning data가 모델의 Σ 방식을 결정하기도 한다는데 NAS 방법론들을 지칭하는 듯 합니다. 다음으로 what to share issue로는 기존방법론에서 3가지 접근법이 있다고 합니다: feature, instance, parameter.여기서 가장 활발히 연구되는것은 feature based MTL이며 multi-tasks를 해결하기 위한 공통정보를 지닌 common feature를 학습하기 위한 방법론이라고 합니다. instance based MTL은 multi task learning 에 유용한 instaces를 찾아내 task간 지식을 공유하는 방법론이라고 하는데, 소개한 세가지 접근법 중 가장 연구가 활발하지 않은 방법론이라고 합니다. 마지막으로 parameter based MTL은 어떤 태스크의 모델 파라미터를 다른 태스크 모델을 학습하는데 사용하기 위한 방법론이라고 합니다. 본 서베이에는 해당 분류 기준에서 feature-based MLT과 parameter-based MTL에 대한 연구를 소개한다고 합니다. 이때 각 방법론은 how to share를 기준으로 더 세부적으로 나뉘는데요, feature-based MLT은 1) feature learning approach라는 대표적인 방법론으로, parameter-based MTL은 2) low rank approach, 3) cluster approach, 4) task relation learning approach, 5) decomposition approach의 네가지로 나뉜다고 합니다. 본 논문은 이 5가지 접근법에 대해 시대순으로 소개하여 각 방법론간의 관계를 독자들이 이해하기를 바란다고 합니다.
정리하면 MTL은 feature를 공유해 task간의 지식을 공유하려는 feature based MTL과 paraeter를 공유하는 parameter based MTL이 있으며, feature based MTL은 task를 해결할 수 있는 common feature를 배우기 위한 방법론이 주를 이루며, parameter based MTL은 각 방법론의 제목을 통해 유추할 수 있듯이, 각 task간의 관계를 이용합니다. 각 방법론에 대한 조금 더 자세한 소개는 아래와 같으며 parameter based MTL 방법론은 다음 리뷰에 소개하겠습니다.
1) feature learning approach
MTL을 위해서 해당 접근법은 original feature를 common feature로 바꾸기 위한 방법론을 연구합니다. original feature는 multi-task 문제를 해결하기에 적당한 정보량을 갖지 못할 수 있기 때문이죠. 따라서 feature learning이란 original feature를 가공하기 위한 방법론입니다. 본 논문에서는 common feature(논문 표현 learned feature, 이하 learned feature)를 생성하기 위해 original feature에 linear or nonlinear trasformation을 적용하는 feature transformation approach와 단순히 유용한 정보를 선택하는 selects a subset of the original feature approach로 나눕니다. 따라서 두번째 카테고리가 original feature와 더욱 유사한 형태를 가집니다. 각 방법론을 연구한 논문들을 소개합니다.
feature transformation approach
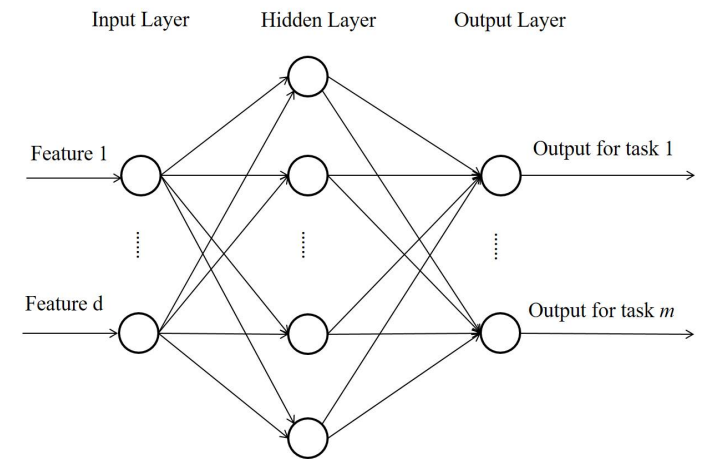
가장 먼저 multi-task learning을 진행한 연구는 1997년 공개된 [1]입니다. 이는 그림2와 같이 multi-layer를 이용해 구현됬는데요 그림2에서 hidden layer의 output이 learned feature입니다. learned feature는 hidden layer에 따라 linear 혹은 nonlinear 형태일 수 있다고 합니다. 결합형 모델인 [1]와 다르게 multi-task feature learning(MTFL)[10]은 수식1과 같은 형태로 일반화 됩니다.
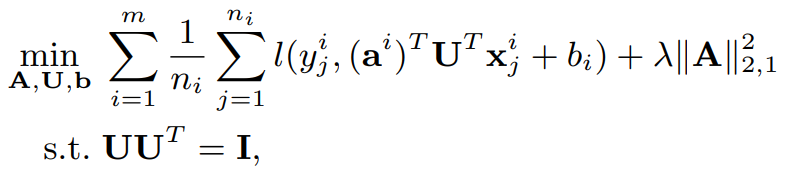
수식1의 first term은 모든 태스크에서 학습데이터에 대한 empirical loss를 의미하며 second term은 변환 후 feature 형태를 조정하기 위한것입니다. 이때 U는 transformation parameter, A는 기존 모델의 parameter이며 x와 y는 학습데이터 입니다. 예를 들어 [10]의 경우는 수식2를 해결하는 것과 같습니다. 수식1의 구체화된 형태이죠.
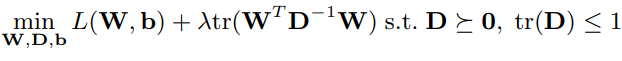
이때 W는 transformed된 모델을 의미하며 w=Ua입니다. (W=(w^1, w^2, w^3, …w^m)). term 2의 목적을 더욱 구체화 해서 알 수 있는데요, 결국 각 모델에 대한 공분산 D를 배우는 과정이라고 합니다. D를 찾으면 task간의 관계를 알 수 있기 때문이라고 하네요. 더 나아가서 최근에 딥러닝 기반의 더 많은 레이어를 이용한 deep multi-task models 연구도 활발하게 이루어지며 다음의 3가지 카태고리로 나뉜다고 합니다: learn a common feature representation by sharing first several layers. use adversarial learning, learn different but related feature representations for different tasks
첫번째 카태고리는 그림 2와 유사한 형태이지만 더 깊은 hidden layer를 사용하며 이때 초기 layer만 share되는 형태를 지닙니다. [15~19의 연구가 이에 속합니다. 두번째는 feature network Nf, classification network Nc, domain network Nd로 구성되며 여기서 domain은 task 를 의미합니다. 수식3의 방법으로 학습을 진행하는데 모든 task에 대한 Nf, Nc를 학습하며 Nd는 해당 데이터가 어떤 task를 위한 데이터인지 판별합니다. 이때 판별을 할 수 없도록, 즉 모든 태스크에서 모든 데이터를 보도록 minimax 문제로 정의됩니다.
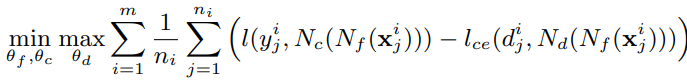
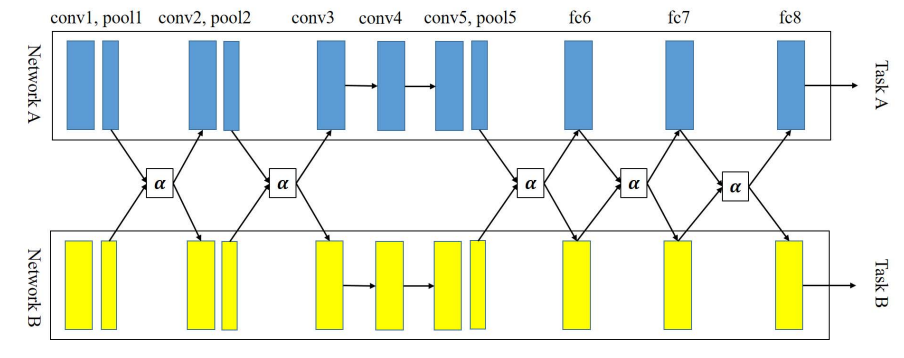
마지막 카테고리는 모델의 중간중간에서 feature의 혼합을 하는 방법론으로 그림 3과같은 구조를 갖습니다. 이때 모델은 수식4와 같이 feature transform 됩니다.
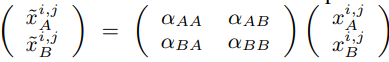
- [1]”Multitask learning,” MLJ, 1997
- [10]“Convex multi-task feature learning,” MLJ, 2008
- [15]“Facial landmark detection by deep multi-task learning,” in ECCV, 2014.
- [16]“Multi-task deep visualsemantic embedding for video thumbnail selection,” in CVPR, 2015
- [17]“Deep model based transfer and multi-task learning for biological image analysis,” in KDD, 2015
- [18]“Multi-domain dialog state tracking using recurrent neural networks,” in ACL, 2015
- [19]“Heterogeneous multi-task learning for human pose estimation with deep convolutional neural network,” IJCV, 2015.
selects a subset of the original feature approach (다음리뷰)
- “Multi-task feature selection,” tech. rep., University of California, Berkeley, 2006
- “Multi-task feature learning via efficient l2,1- norm minimization,” in UAI, 2009
- “Adaptive multi-task lasso: With application to eQTL detection,” in NIPS, 2010
- “Sparse overlapping sets lasso for multitask learning and its application to fMRI analysis,” in NIPS, 2013
- “Efficient multi-task feature learning with calibration,” in KDD, 2014
- “Safe screening for multi-task feature learning with multiple data matrices,” in ICML, 2015
- “Blockwise coordinate descent procedures for the multi-task lasso, with applications to neural semantic basis discovery,” in ICML, 2009
- “Multi-stage multi-task feature learning,” JMLR, 2013
- “Multi-level lasso for sparse multi-task regression,” in ICML, 2012
- “On multiplicative multitask feature learning,” in NIPS, 2014
- “Encoding tree sparsity in multi-task learning: A probabilistic framework,” in AAAI, 2014
- “Multi-task feature and kernel selection for SVMs,” in ICML, 2004
- “Tree-guided group lasso for multi-task regression with structured sparsity,” in ICML, 2010.
- “Exclusive lasso for multi-task feature selection,” in AISTATS, 2010
- “Probabilistic multi-task feature selection,” in NIPS, 2010
- “Learning feature ´ selection dependencies in multi-task learning,” in NIPS, 2013
- “A probabilistic model for dirty multi-task feature selection,” in ICML, 2015.
2) low-rank approach (다음리뷰에)
3) cluster approach (다음리뷰에)
4) task relation learning approach (다음리뷰에)
5) decomposition approach (다음리뷰에)