제가 이번에 리뷰할 논문은 VIO 논문입니다. 여러 VIO 논문들이 DeepVIO 방법론과의 비교를 하고 있어 읽어보게 된 논문입니다.
VIO를 지도학습으로 할 경우 좋은 성능을 얻을 수 있지만, 대량의 GT를 모으는 것에 어려움이 있고 unscene 시퀀스에 대해서는 fine-tuning이 필요했기 때문에 비지도학습 기반의 VIO 방법론들이 제안되었다고 합니다. 하지만 단안 비지도학습 방식의 경우 scale ambiguity 문제가 있고, 다양한 속도에 대한 학습이 되지 않아 pose를 예측할 때 큰 drift를 가진 결과를 얻게 된다는 문제가 있었다고 합니다. 따라서 이 논문의 저자들은 stereo 이미지를 이용하여 얻은 정보를 활용하여 self-supervised 방식으로 학습하고, inference를 할 때는 단일 시퀀스만 사용하여 pose를 예측할 수 있는 방법론을 제안하였습니다.
이 논문의 contribution을 정리하면 다음과 같습니다.
- 최초로 setero로 얻은 정보를 이용하여 self-supervised end-to-end로 학습한 monocular VIO 방식
- 2D optical flow feature(OFF), IMU pose, VIO 궤적에 페널티를 주기 위해 3D geometry 정보를 이용(loss를 구할 때 사용)
- FC-fusion 네트워크로 IMU값을 업데이트
- KITTI 데이터셋과 EuRoC 데이터셋으로 VO/VIO와 비교했을 때 SOTA 달성
Method
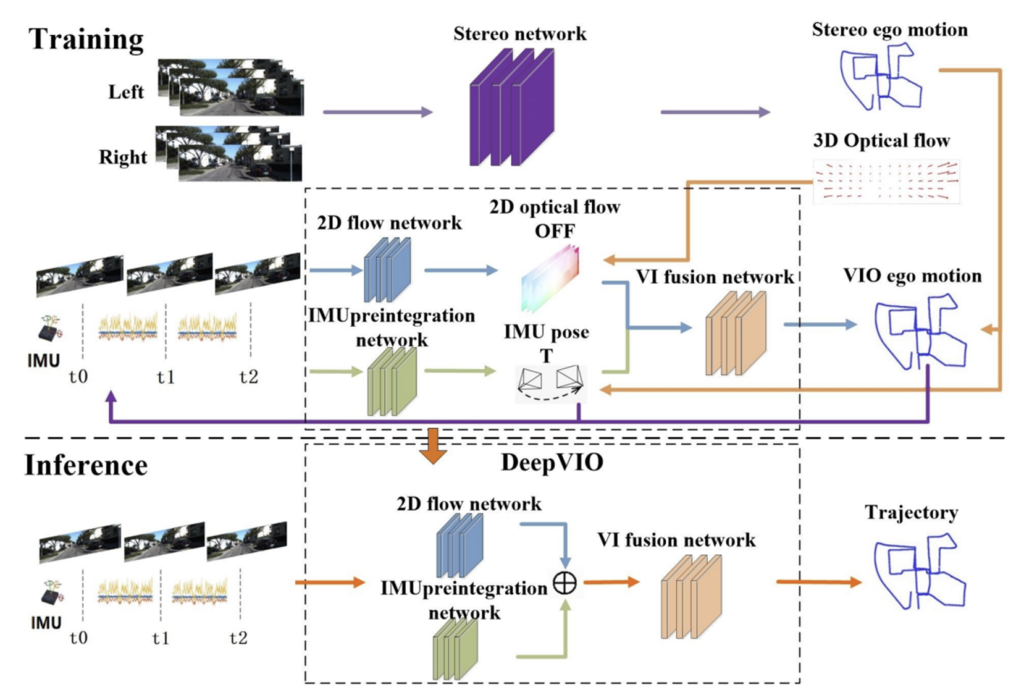
DeepVIO는 CNN-Flow, LSTM-IMU, FC-Fusion network로 구성됩니다.
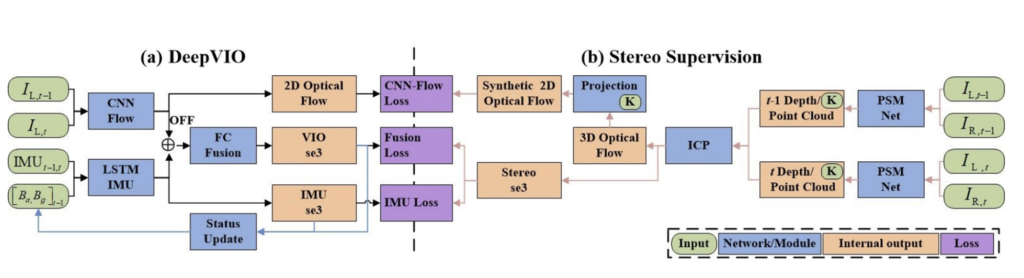
단일 시퀀스 I_{L,t-1}, I_{L,t}를 CNN-Flow를 통과시켜 optical flow feature와 2D optical flow를 계산합니다. IMU 데이터와 현재 상태 정보는 IMU preintegration 네트워크를 통해 relative 6-DoF pose(IMU-se3)를 구합니다. 이렇게 구한 OFF와 IMU-se3를 concat하여 FC-Fusion 네트워크를 통과시켜 궤적을 구합니다. 이때 IMU-se3와 VIO-se3를 이용해 현재 상태정보를 업데이트 합니다.
또한 저자들은 stereo 시퀀스를 활용하여 얻은 정보를 이용하여 학습을 진행하였으며, 이는 그림2의 (b) 부분을 통해 확인할 수 있습니다.
t-1과 t에서의 pair 이미지를 각각 PSMNet이라는 depth 추정 네트워크를 통과시켜 depth 정보를 얻고 depth 정보를 3D point cloud로 변환합니다. 이후 ICP(Iterative Closest Point)라는 두 포인트를 정합시켜주는 알고리즘을 활용하여 3D optical flow를 계산한 뒤, 3D point cloud를 2D로 투영시켜 합성 2D optical flow 정보를 만들어냅니다. 이렇게 얻은 정보들을 이용하여 DeepVIO 네트워크를 학습합니다.
DeepVIO 학습은 다음 loss들을 이용합니다.
- Optical Flow Loss: 합성 2D optical flow와 예측된 2D optical flow 간의 오차 최소화
- IMU Loss: 예측된 IMU-se3와 Stereo-se3 오차 최소화
- Fusion Loss: FC-Fusion 네트워크의 예측값과 Stereo-se3 간의 오차 최소화
1. Stereo Network
PSMNet이라는 당시의 SOTA 방법론을 이용하여 stereo 이미지에 대한 disparity를 구합니다. 이후 depth를 구하는 식을 활용하여 depth d_L을 구합니다.
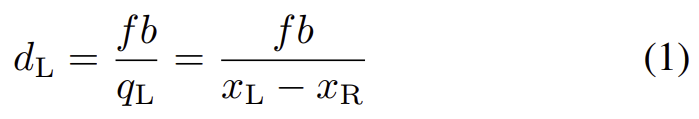
구한 depth를 3D point cloud \mathbf{c}로 변환시킵니다. 이때, 하늘과 같은 영역에서 오차가 너무 커지는 것을 방지하기 위해 일정한 범위의 depth 값에 해당하는 경우만 변환해줍니다. 이렇게 내부 파라미터를 이용하여 point cloud로 변환을 해줌으로써 scale ambiguity 문제를 해결합니다.
이후 t-1, t 프레임으로 부터 얻은 point cloud 값 \mathbf{c}_{t-1}, \mathbf{c}_{t}에 대해 ICP를 적용하여 두 point cloud의 매칭정보 I(\mathbf{c_{t-1}, c_t} ), rotation값 \mathbf{R}, translation값 t을 구합니다. 이렇게 얻은 rotation translation 정보를 이용해 Stereo-se3를 구합니다.
또한 I(\mathbf{c_{t-1}, c_t} )를 이용해 3D optical flow I(\mathbf{v_{3D}} )를 구하고, 아래의 식을 이용하여 2D로 각각 reprojection 시킵니다.
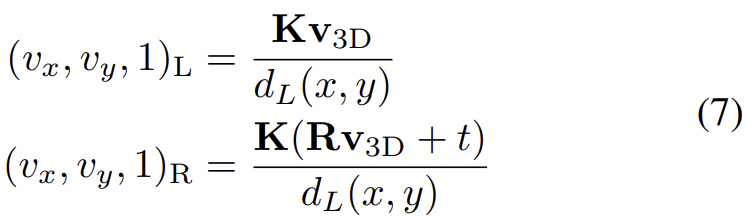
이렇게 3D optical flow를 재투영 시켜 얻은 2D optical flow 정보 \mathbf{v_{2D}}=(v_x,v_y)를 활용하면 LiDAR 센서로 얻은 optical flow 정보보다 dense하고, 모든 픽셀이 대응하는 값을 가지게 됩니다.
*** 2D optical flow와 3D point cloud를 투영시켜 얻은 2D optical flow에 대한 결과

그림3은 3D optical flow로부터 얻은 2D optical flow(c)와 2D optical flow(d)에 대한 결과로, 두 이미지의 박스는 textual less한 상황에 대한 결과로, 둘다 한계가 있음을 알 수 있다고 합니다.
2. CNN-Flow Network
CNN-Flow network는 FlownetC를 이용하여 단안 시퀀스로부터 2D optical flow를 구합니다. 이렇게 구한 값은 1.Stereo Network 섹션에서 구한 합성 2D optical flow 정보를 이용하여 조정됩니다.(학습)
3. LSTM-IMU Network
(1) Preintegrated Network
IMU 데이터와 현재 상태 S를 LSTM 네트워크를 통과시켜 IMU-se3(3개의 rotation과 3개의 translation으로 이루어진 6차원 백터)를 얻고, 1.Stereo Network 섹션에서 구한 Stereo-se3를 이용하여 학습합니다.
(2) Status Update Module
현재 상태S는 FC-Fusion 네트워크와 IMU Preintegrated network의 피드백을 둘 다 이용하여 업데이트가 됩니다.
4. FC-Fusion Network
optical flow feature(OFF)와 IMU-se3는 합쳐져 FC-Fusion network로 들어갑니다. fusion network는 5개의 fully-connected layer로 이루어져 있습니다. FC-Fusion의 output은 VIOI-se3라 하며 마찬가지로 1.Stereo Network 섹션에서 구한 Stereo-se3를 이용하여 학습하게 됩니다.
5. DeepVIO Loss
1. CNN-Flow Loss
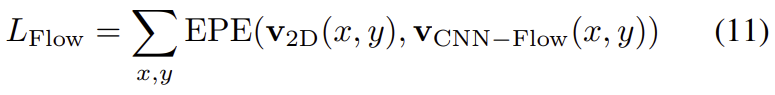
\mathbf{v}_{CNN-Flow}(x,y)는 CNN-Flow에서 구한 2D optical flow값, EPE는 endpoint error(optical flow에서 사용하는 error라고 합니다)를 의미한다고 합니다.
2. IMU Loss
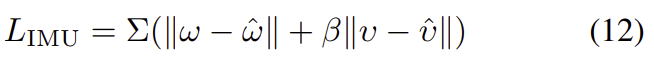
\omega,\upsilon는 카메라 motion의 GT 값(Stereo-se3), \hat{\omega},\hat{\upsilon}는 LSTM-IMU에서 구한 추정값을 의미합니다.
3. Fusion Loss
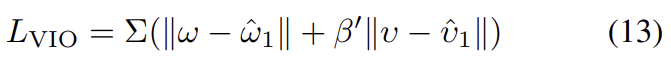
\hat{\omega}_1,\hat{\upsilon}_1는 FC-Fusion 네트워크에서 에서 구한 추정값을 의미합니다.
total loss 는 위의 loss 3개를 합하여 구합니다.
Experimental result
Dataset
- KITTI Dataset
: 389쌍의 stereo 이미지와 optical flow map을 가지며, 카메라의 한 프레임당 IMU는 10개의 변화 값을 가진다. - EuRoC dataset
: 2개의 방과 산업 환경을 초소형 항공기(MAV)로 비행하며 촬영한 영상으로 11개의 sequence를 가진다. IMU 센서는 200Hz, stereo 이미지는 20Hz로 촬영되었다.
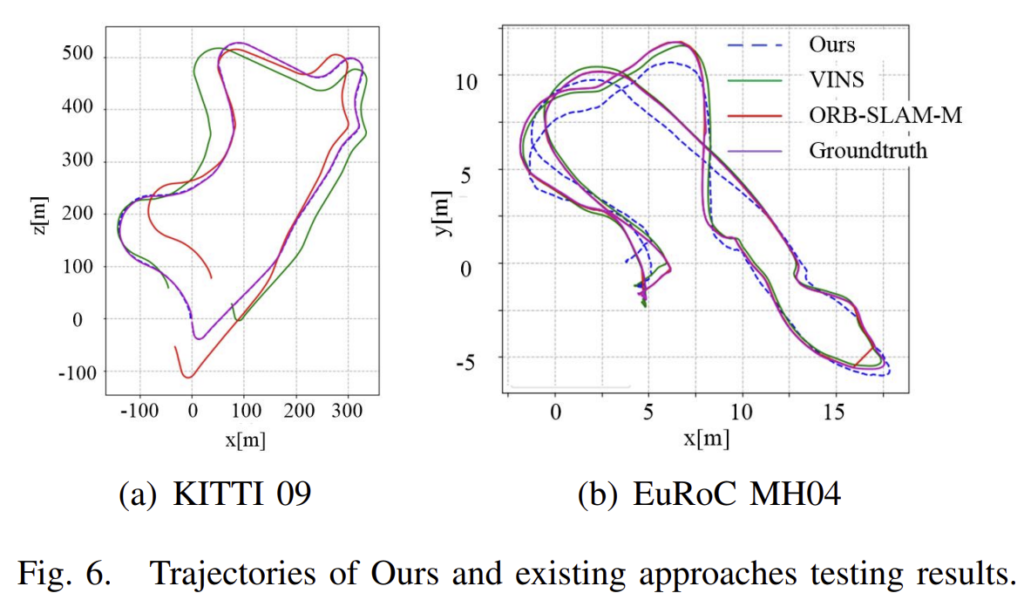
Comparison of the Trajectories
DeepVIO를 학습 기반 방법론의 SOTA(VIOLearner), 전통적인 방법론의 VO(ORB-SLAM-M_withow loop closure) 및 VIO(VINS)비교한 결과입니다.
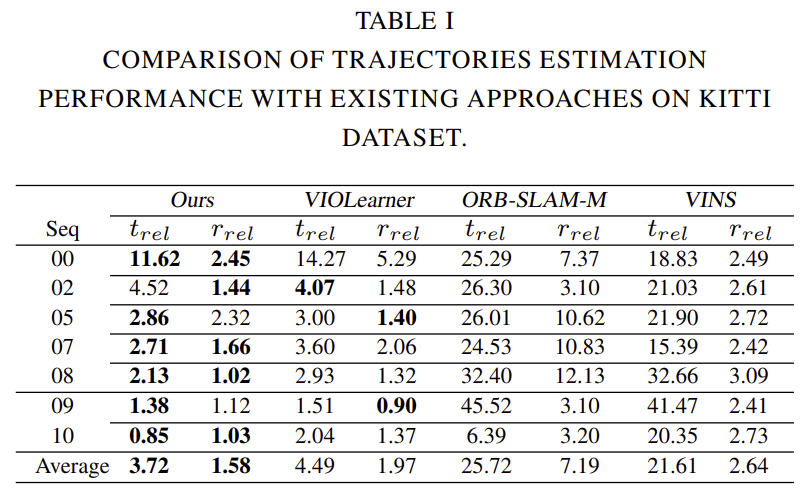
t_{rel}(%)은 100~800m 거리의 평균 translation 오차 백분률, r_{rel}(◦)은 100~800m 거리에 대한 평균 회전 오차를 의미합니다. 평균 오차를 보았을 때 해당 논문이 SOTA를 달성하였고, 대부분의 시퀀스에서 가장 좋은 성능 혹은 경쟁력 있는 성능을 얻은 것을 확인할 수 있습니다. 특히, unseen sequence(09,10)에서 잘 일반화 할 수 있는 것을 알 수 있습니다.
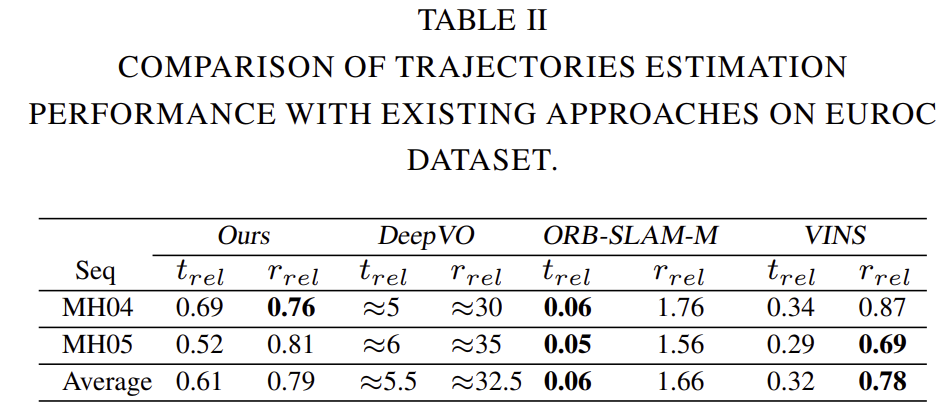
IMU 정보가 포함되므로 DeepVO보다 좋은 성능을 보입니다. 하지만 VINS 방법론보다는 약간 낮은 정확도를 보이지만 이는 좋은 IMU 데이터(동기화가 잘 맞고 높은 주파수를 가진)가 영향을 주었기 때문이라고 합니다. 또한, ORB-SLAM-M에 대한 translation 성능이 약간 떨어지는 것은 local bundle adjustment 최적화가 없기 때문이라고 분석하였습니다.
Optical Flow Error

3D optical flow가 DeepVIO의 GT로 사용될 수 있다는 것을 보여주기 위한 실험입니다. 그림5의 (a)는 left 이미지, (b)는 sparse한 GT, (c)는 합성 2D optical flow, (d)는 Flownet2로 구한 2D optical flow입니다. GT보다 조밀한 값을 가지며, 두 point cloud의 움직임을 계산해 동적인 객체를 제거할 수 있어 학습에 GT로 사용하기 더욱 좋다고 합니다.
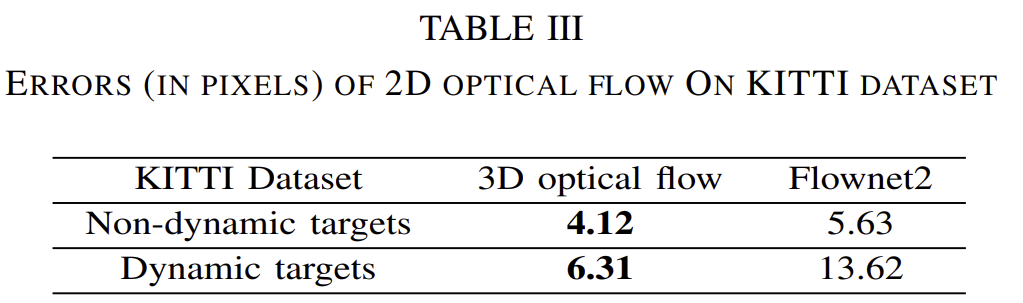
또한 표3에서 확인할 수 있듯이, 단순히 2D optcial flow를 구하는 Flownet2와 비교했을 때 오차가 작은 것을 확인할 수 있습니다.
이 실험을 통해 저자들은 합성 2D optical flow값이 학습시 GT로 사용될 수 있다고 주장합니다.
좋은 리뷰 감사드립니다.
한가지 질문 드리고 싶은 내용이 있습니다.
해당 방법론에서 stereo depth estimation을 이용한 정보로 구축한 optical flow와 se3을 GT를 사용하는 방법라고 이해했습니다.
그럼 Stereo 를 이용한 방법론의 성능은 어느정도 인지 궁금해지네요.