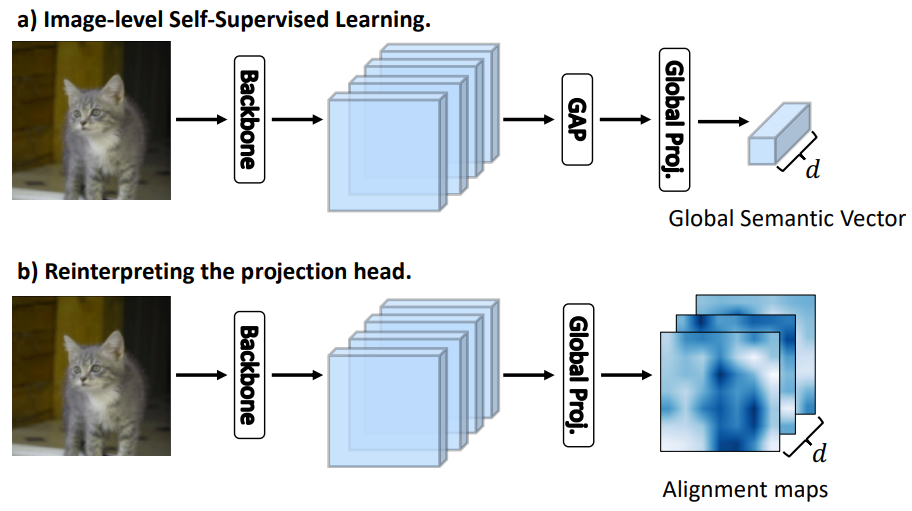
간단 소개:
Self-supervised learning(SSL)은 모델의 학습을 위해 이미지에서 물체의 불변성을 활용한다. 특히 이미지에 서로 다른 augmentations을 적용하여 학습에 사용하는데, 이때 random crop 등으로 object가 손실되거나 misalignment가 발생하는등, 문제가 발생할 수 있다. 논문에서 제안하는 Learning where to Learn(LEWEL)은 feature의 spatial information을 활용하여 배경이 아닌 object(학습 대상)에 집중하게 해, feature learning을 더 잘 하도록 만든다. 본 논문은 학습 시 이미지의 object에 집중하기 위해 semantic segmentation에서 영감을 받아 Self-supervised learning 의 projection head를 per-pixel prediction으로 재해석 하였다. 기존 방법론은 [그림1]의 a)와 같이 Global Average Pooling (GAP)를 통해 클래스를 예측했다면, 제안하는 방법론은 alignment map 이라는 pixel 단위 예측을 학습에 활용하였다.
방법론:
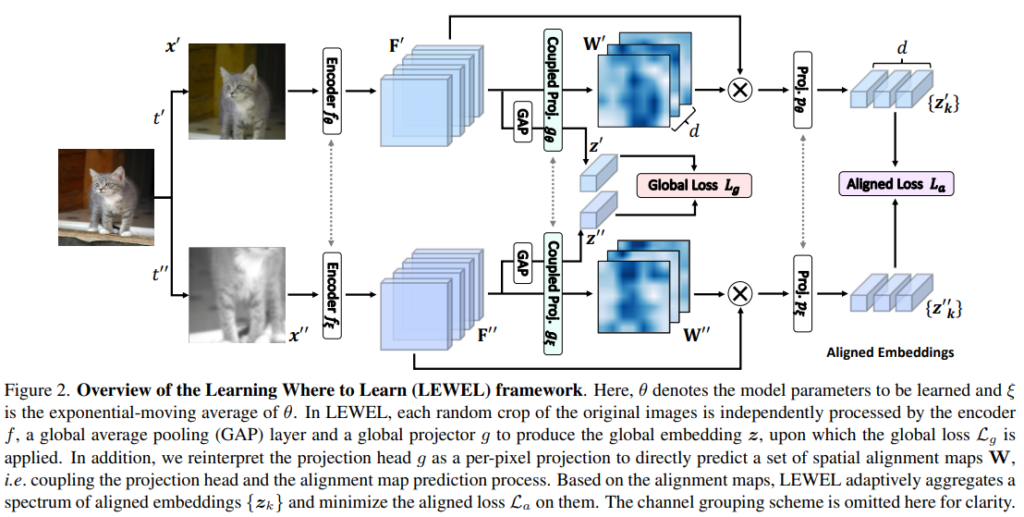
제안하는 방법론은 agmentation을 적용한 두 이미지(이하 서로 다른 view)의 context가 불변한다는 특징을 이용하여 기존 SSL 방법론과 같이 두 view에 대한 예측이 동일해야 한다는 특성을 이용해 학습을 진행하였다. 이때, prediction head를 classification 예측을 위한 layer로 해석하여 각 클래스에 속할 확률값에 대한 일관성을 높이거나, 혹은 가장 강하게 예측한 클래스를 통해 pseudo label을 생성하여 학습하는 기존 방법론에 제안하는 alignment map을 이용하였다. 이를 통해 기존 방법론에서는 대응할 수 없었던 augmentation을 통한 object 손상에 대응할 수 있다. 즉, 물체가 심하게 잘리거나 배경만 포함한 경우에 대응할 수 있다.
논문에서는 prediction head에 대한 두가지 해석(그림1참조)을 통해 두가지 learning process를 제안한다: global contrastive learning, learning where to learn. global contrastive learning은 그림1의 a)를 learning where to learn은 그림1의 b)를 활용한다. 먼저, global contrastive learning은 기존 많이 사용되는 contrastive learning frameworks로 x에 대하여 augmentation된 두 이미지 x’, x”을 학습에 사용한다. 학습을 위해 x’을 encoder f_θ (단, θ는 parameters)를 통해 임베딩하고 [F’=f_θ(x’)] 해당 feature를 GAP를 통해 representation y’을 얻는다[y’=GAP(F’)]. 이후 projection head 인 g_θ를 통해 embedding 표현인 z’를 얻는다[z’=g_θ(F’)]. 다음으로 x”은 momentum encoder인 f_ξ로 임베딩을 한 후[F”=f_ξ(x”)] 같은 과정을 거쳐 z”로 임베딩한다[z”=g_ξ(GAP(F”))]. 이렇게 임베딩된 최종 형태인 z’와 z”는 같은 context 인 x에 대한 예측이므로 같아야 한다. 따라서 global contrastive learning의 loss는 L_g=l(z’, z”)이다.
다음으로 learning where to learn에서는 기존의 global contrastive learning frameworks에서 GAP 과정을 제외하고 생성한 pixel level prediction인 aligment map을 학습에 이용한다. 먼저 앞선 방법과 동일하게 두 view(x’, x”)에 대해 embeding model(f)를 통해 embedded representation F’, F”을 구한다. 이때 각 alignment map예측(W, W”)을 feature값에 곱해 학습할 영역(두 view간에 aline된 영역)만을 활성화 한다. (이때 W’은 F’을 통해, W”은 F”을 통해 생성되며 생성 방법은 뒤에서 소개하겠다.) 예측 맵으로 attention된 feature y’과 y”(y’=W’⊗F’, y”=W”⊗F”)은 projection layer p를 거쳐 최종 형태 z’_k, z”_k으로 임베딩되며, 해당 값이 유사해지도록 학습한다(이때 k는 예측의 output feature의 차원이며, class 갯수와 다르다). 따라서 alignmetn loss는 L_a=l(z’_k, z”_k)이다.
제안하는 두 학습 방식에서 z’과 z”간의 거리를 계산하는 loss함수는 InfoNCE와 Mean Square Error(MSE) loss를 이용했으며 실험에서는 LEWEL_M(InfoNCE), LEWEL_B(MSE)로 리포팅하였다.
Alingment map(W) 생성 방법:
기존 SSL 과정에서 projection head(g)는 global representation(y’)를 분류하는 분류기 역할을 한다. 이를 semantic segmentation 관점으로 확장하여 projection head(g)를 per-pixel projection head로 확장하여 GAP 이전의 representation에 적용하였으며 그것이 alinment map이다[W’ = g_θ(F’)].
실험:
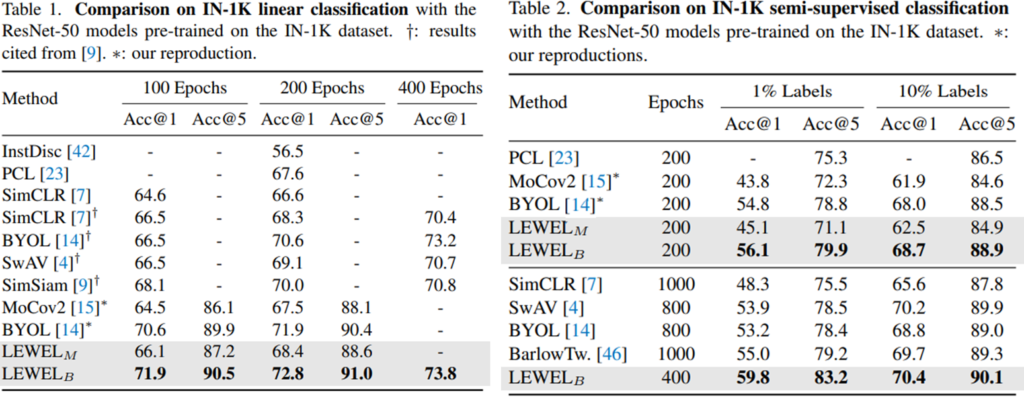
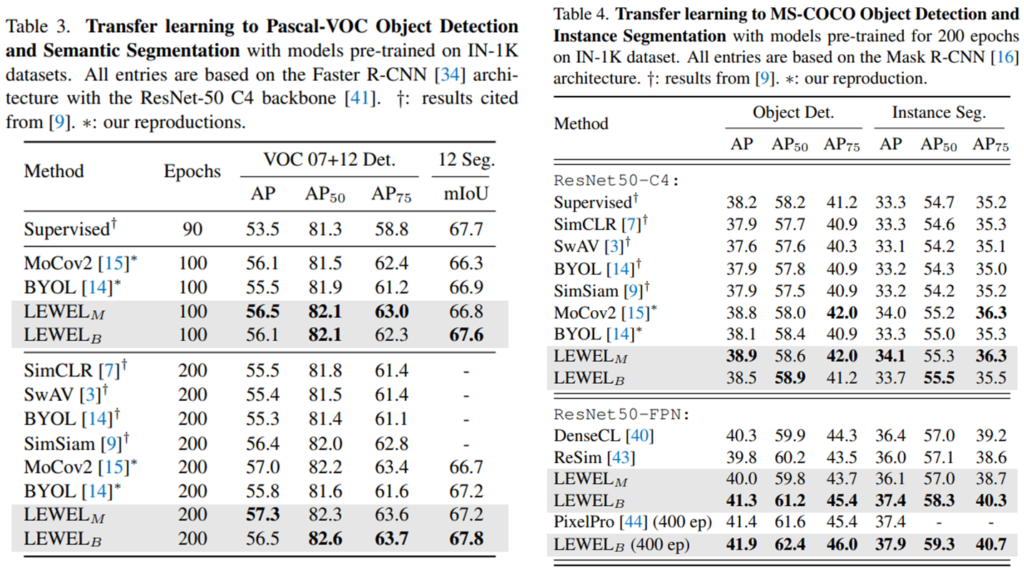
제안하는 방법론은 기존 방법론과 비교하기 위해 imagenet dataset에 대해 linear classification과 semi-supervised learning의 성능 비교를 진행하였으며(table1, table2), table3,4에서 transfer learning을 통해 pretrain method 방법론으로써 우월성을 보였다. 이때 Pascal VOC 데이터셋으로 object detection task를 MS-COCO dataset으로 object detection과 semantic segmentation 성능을 보였다.
좋은 리뷰 감사합니다. 해당 논문은 제가 항상 의구심을 가진 부분을 집중하는 것 같습니다. Random. Crop으로 발생하는 문제는 없는가? 하는 것말이죠. 그것을 실험적으로 보인 논문이라 생각이 되네요.
좋은 리뷰 감사합니다.
SSL 과정에서 augmentation 중 random crop으로 인해 발생하는 문제점에 대응하기 위한 방법론으로 이해하였습니다.
그렇다면 이 논문이 나오기 이전 연구들에서 random crop의 수행 여부에 따른 성능은 어떻게 되나요?
random crop을 쓰는게 안쓰는 것보다 성능이 더 낮아 이러한 연구가 진행된 것인지, 아니면 쓰는게 성능이 높긴 하지만 crop의 문제점을 새롭게 지적한 것인지 궁금합니다.