이번 X-Review에서 제가 소개해드릴 논문은 2021년 ICCV에 게재된 ‘Foreground-Action Consistency Network for Weakly Supervised Temporal Action Localization’ 이라는 논문입니다. 편의 상 줄여서 ‘FACNet’이라고 칭하겠습니다.

이 논문을 읽게 된 계기는 2주 간에 걸쳐 저번 주까지 임근택 연구원님께서 리뷰하신 Weakly Supervised Temporal Action Localization via Representative Snippet Knowledge Propagation이라는 논문을 보았는데, FACNet의 일부를 base 분류기로 포함하고 있기 때문입니다.
이번에도 마찬가지로 video-level label만을 사용하여 WTAL task를 수행하는 방법론입니다. 비디오의 Weakly-supervised Temporal Action Localization task에 대하여는 지난 리뷰들에서 여러 번 언급했으므로 자세한 내용은 설명하지 않고 넘어가겠습니다.
그럼 바로 논문을 살펴보겠습니다.
Introduction
이전에 제가 리뷰나 세미나에서 소개해드렸던 WTAL 방법론들, 또는 그 당시 기타 방법론들에는 일반적으로 WTAL task를 수행하는 두 가지 큰 흐름이 존재하였습니다.
- 비디오 전체에서 foreground(action) 또는 background에 대한 attention weight를 만들어 내어 localization 하는 방법론들 (attention mechanism)
- 비디오의 snippet 별 클래스에 속할 확률을 계산하는 ‘Class Activation Sequence'(CAS)를 추출하여 classification과 localization을 수행 (multiple instance learning)
위 두 가지 방식 중 하나만 사용하는 논문도 있고, 둘 다 사용하는 논문도 있습니다.
attention mechanism을 이용하는 기존의 방법론에서 저자는 attention weight의 의미에 대해 지적합니다. 학습 시 temporal annotation이 없기 때문에 video-level label만을 이용하여 attention weight를 학습합니다.
즉, 클래스 c에 대해 특정 snippet t가 큰 attention weight를 갖는다는 것은 비디오가 클래스 c를 갖는 것으로 올바르게 분류되는 과정에서 t가 큰 역할을 했다는 것입니다. 이렇게 분류에 큰 역할을 수행한 snippet t를 discriminative snippet이라고 하는데, 저희가 찾아야 하는 action은 discriminative snippet만으로 이루어져 있는 것이 아닙니다.
물론 discriminative snippet이 중심을 이루지만, 그 주변의 less-discriminative snippet도 action에 포함되기 때문에 이러한 방법만으로는 완전한 action을 찾아내기 힘들다고 볼 수 있습니다.
다음으로 CAS를 추출하여 classification과 localization을 수행하는 방법론은 아래 그림을 참고하여 설명드리겠습니다.
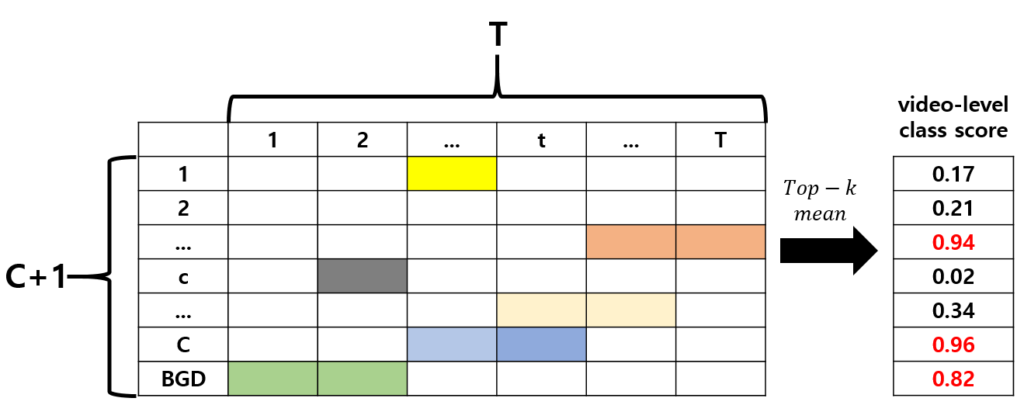
비디오의 feature를 임베딩 하여 모듈에 태우면 위 그림과 같은 CAS를 얻을 수 있습니다. 이후 CAS로부터 classification과 localization을 수행하는 과정을 간단히 설명드리겠습니다.
- CAS에서 각 클래스 별로 상위 k개의 점수를 평균내어 video-level class score를 만들어냅니다.
- 그리고 그 점수를 thresholding 하여 localization 할 클래스를 선별하고, 다시 CAS로 돌아가 선별된 클래스들에 한하여 localization을 수행합니다.
이렇게 기존에 일반적으로 수행되던 과정을 크게 2단계로 나눠 볼 수 있는데요, 저자는 각 단계에서의 문제점을 지적합니다.
첫 번째 단계에서, 상위 k개의 점수를 이용하여 classification을 수행합니다. 하지만 ‘k’는 결국 사람이 직접 정해주는 하이퍼 파라미터이기 때문에 실제로 상위 k개의 snippet이 모두 foreground라는 보장을 할 수 없다고 합니다. 이 부분이 왜 문제가 될 수 있는지 잘 납득되진 않지만 아마도 고정된 k개의 점수만을 사용한다면 action 또는 foreground snippet이 아닌 background snippet의 점수도 고려될 가능성이 있다보니 최적의 성능을 내지 못한다는 의미로 해석하였습니다.
두 번째 단계에서 CAS에 들어가는 점수들은 분류 과정에서 학습된 모듈이 내뱉는 점수이다보니 앞서 말씀드린 attention mechanism과 같은 맥락의 문제가 발생한다고 볼 수 있습니다.
정리하자면 attention mechanism을 이용하는 방법론들은 localization을 수행할 때 snippet이 classification에 기여한 정도를 기준 점수로 삼다보니 classification과 localization 사이의 불일치성 때문에 완전한 localization이 어렵다는 문제를 지적하였고, CAS를 생성하고 classification과 localization을 수행하는 방법론에서는 top-k로 고정된 개수의 snippet을 살펴본다는 점을 지적한 것입니다.
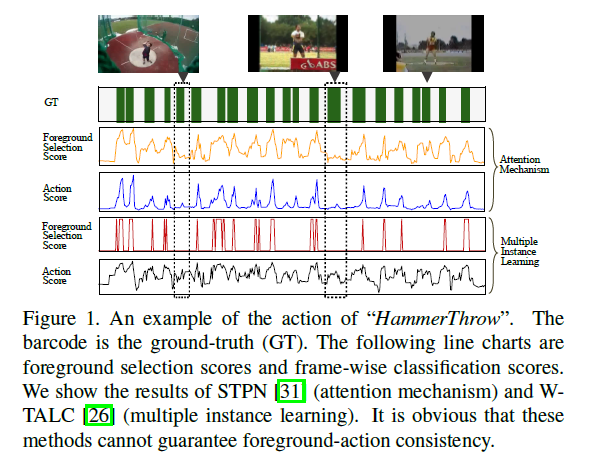
그렇다면 Figure 1을 통해 지적한 것들이 무슨 문제를 야기하는지 보겠습니다. 4개의 line chart 중 1, 2행은 각각 attention mechanism을 사용하는 기존 방법론의 foreground score, action score에 해당하고, 3, 4행은 각각 CAS를 사용하는 방법론의 foreground score, action score에 해당합니다. 1, 2행을 보면 less-discriminative한 부분은 제대로 잡아내지 못하고 있는 것을 볼 수 있습니다. 3, 4행은 foreground score는 낮지만, action score는 높아 foreground-action consistency가 깨진 상황에 해당합니다. 각 용어들이 어떤 의미를 갖는지는 뒤에서 설명드리겠습니다.
이러한 배경 속에서, 저자는 foreground-action consistency를 유지함과 동시에 discriminative + less-discriminative snippet을 모두 action으로 인지할 수 있는 모델인 FACNet을 제안합니다.
Method
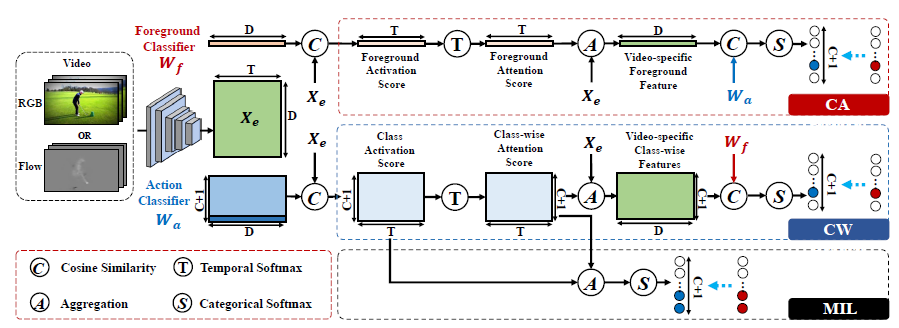
FACNet의 전체 아키텍쳐이고, 크게 3가지 branch와 하나의 module로 나누어져 있습니다.
- CA branch : Class-wise foreground classification branch
- CW branch : Class-agnostic attention pipeline
- MIL branch : Multiple Instance Learning branch
- + Hybrid Attention Module
Relation definition
논문에서 사용되는 핵심 단어에 대해 정리하고 넘어가겠습니다.
- Foreground : 우선 Foreground는 어떤 action class이든 관계 없이 모든 action에 해당하는 것을 의미합니다. 다시 말해 비디오에서 background가 아닌 부분은 모두 foreground로 볼 수 있습니다. Actionness 또는 class-agnostic과 비슷한 맥락이라고 생각하시면 될 것 같습니다.
- Action : Action은 마찬가지로 background가 아닌 부분을 의미해 다른 논문에서는 foreground와 혼용되기도 하지만 이 논문에서는 특정 클래스에 속하는, foreground보다 조금 더 좁은 개념으로 정의하고 있습니다.
- Foreground-to-action relation : foreground는 특정 class의 action에 속한다는 일방적인 관계
- Action-to-foreground relation : action은 무조건 foreground에 속한다는 일방적인 관계
Overview
비디오로부터 feature를 임베딩 하는 과정까지는 기존 방법론들과 똑같습니다. 이후 3가지 branch가 존재하는데 첫 번째 branch인 CW branch는 ‘action-to-foreground relation’을 모델링합니다. 두 번째 branch인 CA branch는 ‘foreground-to-action relation’을 모델링하고, 마지막 MIL branch는 video classification의 성능을 향상시키는 역할을 수행합니다. 각각의 branch의 세부적인 사항을 하나씩 살펴보겠습니다.
CW branch : Class-wise foreground classification branch
Introduction에서 문제를 정의하며 FACNet은 foreground-action consistency를 잡겠다는 목적을 가지고 있습니다. 저자는 이 때 foreground와 action은 양방향적인 관계를 형성하고 있다고 용어 정의에서 설명하였습니다. 하지만, 기존 방법론들은 대부분 foreground-to-action 관계에만 주목하여 정보를 얻어왔는데, 반대로 action-to-foreground 관계에서 얻을 수 있는 정보도 얻을 수 있고, 둘 다 학습에 사용해야 한다고 주장합니다. CW branch는 두 관계 중 action-to-foreground를 고려하는 branch에 해당합니다.
기존 방법론들이 foreground-to-action 관계에만 집중했다는 것은 class와 관계 없이 비디오에서 attention weight를 뽑고, 그것을 이용해 CAS를 만들어 task를 수행했다는 것을 의미합니다. 읽는 내내 말장난 같기도 하고, 혼동되는 부분이 많았는데 실제 branch를 보겠습니다.
먼저 학습되는 파라미터로 Foreground Classifier W_{f}\in\mathbb{R}^{D}와 Action Classifier W_{a}\in\mathbb{R}^{(C+1)\times{D}}가 존재합니다. W_{f}는 클래스에 관계 없이 특정 snippet의 feature가 foreground인지에 대한 점수를 만들어내고, W_{a}는 snippet feature가 어떤 클래스에 속하는지에 대한 점수를 만들어냅니다. 여기서는 background class까지 포함하여 총 C+1개의 클래스를 분류에 사용하고, D는 feature의 차원을 의미합니다.
CW branch에서는 첫 번째로 비디오의 t번째 snippet의 embedded feature X_{e}(t)와 W_{a}(j) 간의 코사인 유사도를 계산해 snippet 별 class activation 점수 S_{a}\in\mathbb{R}^{(T)\times{C+1}}를 만들어냅니다. 여기서 j는 하나의 클래스를 의미합니다.
S_{a}(t, j)=\delta{}\cdot{}cos(X_{e}(t), W_{a}(j))
코사인 유사도를 구하는 두 대상이 각각 D차원의 벡터이므로, 각 클래스마다 하나의 스칼라를 얻을 수 있는 것입니다. 결국 S_{a}는 T개의 snippet 각각이 C+1개의 클래스에 속할 점수를 값으로 갖게됩니다.
A_{a}(t, j)=Softmax(S_a)
이때의 Softmax는 temporal softmax에 해당합니다. 여기까지 하면 각 snippet이 각 클래스에 속할 일종의 class-wise attention weight를 얻었다고 볼 수 있습니다. 이렇게 얻은 A_{a}를 기존 embedded feature에 적용하여 video-specific class-wise feature F_{a}\in\mathbb{R}^{(C+1)\times{D}}를 얻습니다.
F_{a}(j)=\sum{}_{t}A_{a}(t, j)X_{e}(t)
F_{a}는 하나의 비디오를 (C+1)개의 feature로 표현한 것이므로, 하나의 feature가 그 비디오의 클래스를 의미하는 feature를 의미하는 것으로 볼 수 있습니다.
이제 비디오의 클래스 별 feature를 얻었으니 foreground classifier W_{f}를 이용해 각 feature가 foreground인지에 대한 점수를 얻어야 합니다. 점수는 위에서처럼 feature와 분류기 weight의 코사인 유사도 연산을 적용하여 얻습니다. 이에 해당하는 class-wise foreground activation scores는 클래스 별 점수이므로 shape은 당연히 R_{a}\in\mathbb{R}^{(C+1)}일 것입니다.
R_{a}(j)=\delta{}\cdot{}cos(F_{a}(j), W_{f})
이번에는 categorical softmax를 적용하여 최종적으로 비디오의 각 클래스에 대한 점수 P_{a}\in\mathbb{R}^{(C+1)}를 얻어냅니다.
P_{a}와 저희가 알고 있는 video-level label을 normalize 하여 normalized cross-entropy loss \mathcal{L}_{cw}를 계산합니다. background label에 대해서는 foreground feature를 모델링 한 것이므로 0으로 줍니다.
여기까지 CW branch의 과정과 목적에 대해 다시 정리해보겠습니다. 우선 코사인 유사도를 통해 embedded feature의 class-wise attention score를 계산해주고, 선형 결합을 통해 feature에 적용하여 비디오의 클래스 별 feature를 만들어냅니다. 클래스 별 feature를 foreground classifier에 태워 얻은 foreground score를 저희가 알고 있는 video-level label과 비교를 통해 학습하게 됩니다.
저자가 기존 방법론들이 고려하지 않았다고 주장한 ‘action-to-foreground relation’이 위와 같은 아키텍쳐 설계를 통해 학습에 사용되는 것입니다. 당연히 여기까지만 사용하면 다른 방법들과 같이 action과 foreground 사이의 일방적 관계만 고려한 것이므로 반대로 foreground-to-action relation을 고려하는 branch도 필요합니다.
Class-agnostic attention branch
CA branch에서는 CW branch와 반대로 foreground-to-action relation을 고려합니다. 사실 새로운 내용은 없고 CW branch와 대조되는 흐름으로 설계되어있다고 보시면 됩니다. 빠르게 살펴보고 넘어가겠습니다.
앞서와 마찬가지로 Foreground Classifier W_{f}\in\mathbb{R}^{D}와 Action Classifier W_{a}\in\mathbb{R}^{(C+1)\times{D}}를 사용합니다. 먼저 snippet 별 foreground일 점수S_{f}\in\mathbb{R}^{t}를 얻어야 합니다. 특정 클래스의 속할 확률까지 각각 구할 필요 없이 그냥 snippet 별로 foreground일 점수입니다. 이후 마찬가지로 temporal softmax를 거쳐 A_{f}\in\mathbb{R}^{t}까지 구해줍니다.
S_{f}(t)=\delta{}\cdot{}cos(X_{e}(t), W_{f})
A_{f}(t)=Softmax(S_{f}(t))
이후 비디오의 foreground feature F_{f}\in\mathbb{R}^{D}를 구하기 위해 A_{f}(t)와 embedded feature의 선형 결합을 사용합니다.
F_{a}(j)=\sum{}_{t}A_{f}(t)X_{e}(t)
얻은 video-specific foreground feature를 action classifier에 태운 후 categorical softmax를 적용하여 비디오의 각 클래스 별 점수 P_{f}\in\mathbb{R}^{C+1}를 얻습니다. 이렇게 얻은 클래스 별 점수와 저희가 알고 있는 GT label의 normalized cross-entropy loss \mathcal{L}_{ca}를 학습에 사용하고, 마찬가지로 background class의 GT label은 0으로 둡니다. CW branch와 서로 보완적인 관계에 대한 학습을 수행한다고 생각하시면 됩니다.
Multiple Instance Learning branch
MIL branch는 foreground-to-action relation을 좀 더 보완해주기 위해 설계되었습니다. 또한, 기존의 CAS를 사용하던 방법론들이 top-k개의 점수를 사용하는 것에 지적하였었는데, 여기서는 top-k 방식같은 hard-attention 대신 CW branch에서 얻은 snippet 별 class activation 점수 S_{a}\in\mathbb{R}^{(T)\times{C+1}}로 attention을 적용하여 video-level class activation scores R_{m}\in\mathbb{R}^{C+1}을 얻습니다.
다시 CA, CW branch에서의 과정과 마찬가지로 클래스 별 점수 P_{m}\in\mathbb{R}^{C+1}을 계산하고, normalized cross entropy loss \mathcal{L}_{mil}을 계산하여 학습합니다. 모든 비디오에는 background snippet이 존재하므로 GT label의 background class는 1로 두고 학습합니다.
\mathcal{L}_{total} = \lambda{}_cw\mathcal{L}_{cw} + \lambda{}_ca\mathcal{L}_{ca} + \lambda{}_{mil}\mathcal{L}_{mil}
Hybrid attention
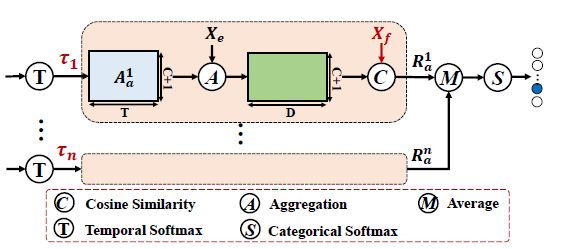
기존에 attention mechanism을 사용하는 방법론들은 discriminative snippet에만 치중하여 localization을 수행하게 되는 경향이 문제점이라고 언급하였었습니다. CA, CW branch에서 attention score A_{a}, A_{f}를 생성하기 위해 softmax를 거치는데, 이 때 큰 temperature \tau{}를 줌으로써 좀 더 discriminative 한 snippet에 높은 attention weight를 줄 수 있다고 합니다.
같은 맥락에서, \tau{}가 2, 5 일 때 굉장히 discriminative한 snippet에 높은 가중치를 주게 됩니다. 이 때 less-discriminative한 snippet에도 주목할 수 있도록 attention을 만들어줘야 하는데, \tau{}=1로 주면 2, 5 일 때보다 less-discriminative 한 snippet들에 주목하게 됩니다.
만약 하나의 \tau{}만 사용하여 attention weight를 뽑아내면 너무 discriminative 한 snippet에만 주목하거나, less-discriminative한 snippet들로 분산되어 안좋은 성능을 내게 되는 단점이 존재합니다. 그래서 저자는 모든 branch에서 1, 2, 5의 \tau{}로 부터 얻은 R_{a}를 평균 내어 사용하는 hybrid attention 방식을 취한다고 합니다.
Experiments
벤치마크 실험은 THUMOS14 dataset, ActivityNet 1.3 dataset에서 수행되었습니다.
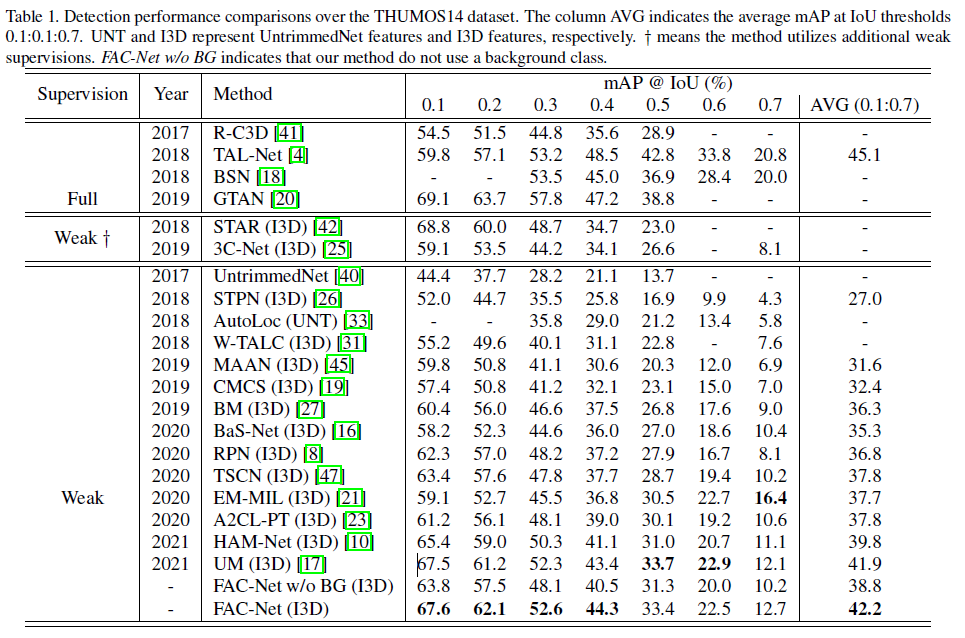
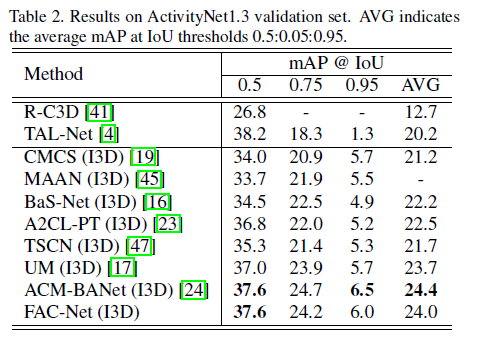
THUMOS14 데이터셋에서는 SOTA 성능을 달성하였습니다. ablation study에 주목할만한 점이 있어 넘어가보도록 하겠습니다.
Ablation Studies
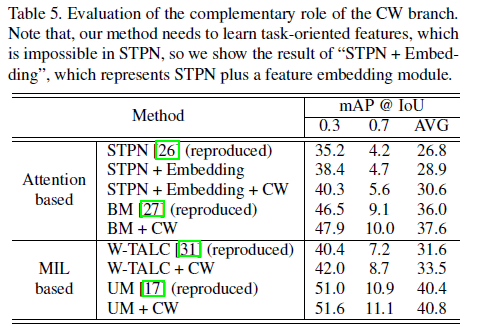
저자는 foreground-to-action 관계와 action-to-foreground 관계를 모두 고려하는 모델을 설계하였습니다. FACNet의 CW branch에서 action-to-foreground 관계를 모델링합니다. 과연 이 아이디어와 CW branch가 유효한지 살펴보기 위해 foreground-to-action 관계만을 고려하던 기존 방법론들에 CW branch를 붙여 측정한 성능입니다.
task 초반의 방법론인 STPN과 W-TALC에 CW branch를 붙여주니 성능이 둘 다 1.5% 이상 크게 오른 것을 볼 수 있습니다. 그 당시 최근의 방법론인 UM에서도 소폭이지만 성능이 향상하는 것을 볼 수 있습니다.
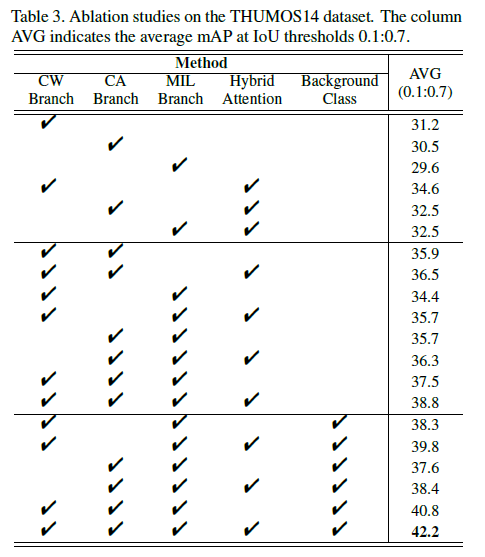
다음은 각 branch나 모듈에 대한 ablation 실험 결과입니다.
CA branch나 CW branch 중 하나만 사용하다가, 두 branch를 모두 사용하는 경우 거의 4~5%의 평균 mAP 향상이 있는 것으로 보아 둘 다의 보완적인 관계를 동시에 고려해주는 것이 중요하다는 것을 볼 수 있습니다. 또한 다른 모듈이나 branch의 유무에 따른 결과도 살펴보실 수 있습니다.
Hybrid attention의 역할이 제가 이해한 바로는 조금 더 완전한 action을 찾아낼 수 있도록 도와주는 것이었습니다. Hybrid attention의 존재가 높은 IoU threshold에서의 성능 향상에 어느 정도 도움이 되는지 궁금하였는데 결과가 평균으로만 나와있어 아쉽습니다.
Qualitative Result
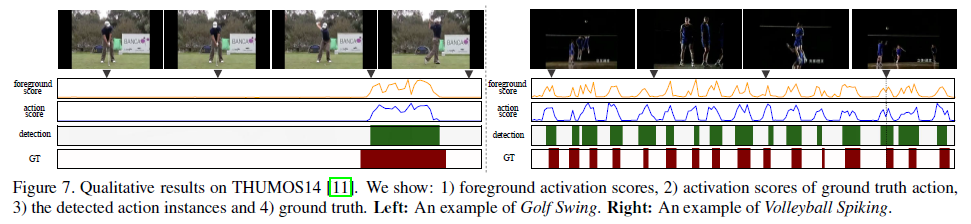
정성적 결과입니다. 저자가 원하던 foreground-action consistency가 잘 유지된 것을 볼 수 있습니다.
이상으로 리뷰 마치겠습니다.
Action과 Foreground의 상호 보완성을 보겠다는 것은 알겠는데 용어 선택이 참 복잡하네요. top-k의 문제점을 대신하기 위해서 MIL branch가 도입되었다고 적혀있고, 대충 어떻게 score를 뽑는지는 알겠는데요. 그림상을 보면 MIL이 CW와 같이 쓰여야 하는 것으로 보입니다. 그럼 ablation에서도 CW 단독 / CW+MIL 성능이 있어야 top-k 보다 좋다는 것을 보일 수 있을 것 같은데. 이 부분에 대한 설명이 혹시 있나요?
좋은 리뷰 감사합니다.
개념이 헷갈리다 보니 이해가 잘 가지 않는 것이 있습니다.
top-k를 정해두는 것과 CAS의 상위 K개 점수에 threshold를 이용하는 것이 문제이며, 이는 background에 해당하는 경우도 action 혹은 forground로 학습 되기 때문이라 하셨는데, 그렇다면 forground로 예측하는 영역이 많아지는 문제가 생겨야하는 것이 아닌가요..??
학습시 각 action 혹은 forground로 구분하는 기준이 모호해진 것으로 이해햐면 되나요??