한줄 소개: Self supervised learning에 적용하기 위한 최고의 Data Mixing 기술
본 논문은 self-supervised setting에 적용하여 데이터 증폭을 통해 학습의 효율성을 높일 수 있는 새로운 Data Mixing 방법에 대한 논문이다. 본 논문이 제안하는 Data mixing 방법은 Simple Data Mixing Prior(SDMP)로 다양한 self supervised frameworks(예를 들어 MoCo)가 잘 작동하도록 도우며, 특히 Self supervised setting의 Vision Transformer에 적용하였을 때 성능을 저해하지 않고 향상 시키는 최초의 data mixing 방법론이다. 코드 또한 공개되어있다 https://github.com/OliverRensu/SDMP.
제안하는 연구의 방법론: How to work SDMP?

First. Where the method idea is come from?

인기를 끌었던 data mixing 방법론을 살펴보면, 그 과정을 통해 하나의 mixed sample은 3개의 related sample을 갖게된다. 즉, 두 개의 source image와 다른 방식으로 합쳐진 mixed sample이 생성된다. 논문에서 제안하는 SDMP는 기존 방법론과 다르게 source 이미지와 mixed sample간의 관계 뿐만 아니라, 같은 source로 부터 생성된 mixed samples 간의 관계까지 고려하도록 설계되었다.
Second, The data mixing method that the paper use.
데이터를 직접 Mixing하는 방법론 보다는 mixed sample간의 관계를 어떻게 학습과정중에서 반영하는지 제안한 논문으로 기존의 검증받은 유명 방법론을 data mixing에 사용하였다. data mixing을 위해서 element-wise data mixing method인 Mixup, CutMix, ResizeMix가 이용되었다.
Third, making label method.
self-supervised 방법론은 데이터의 real label을 사용할 수 없다. 또한 해당 labeling 작업은 데이터간의 연관성에 대한 정보를 학습중인 모델에게 주기위한 중요한 정보이므로 본 논문의 주된 제안일 것이다. 본 논문은 기존의 대표적인 두가지 self-supervised 방법론인 contrastive learning과 knowledge distillation을 위한 the virtual label assignments 방법을 고안하였다.
- Case 1: for contrastive learning.
contrastive learnig이란 self-supervised learning을 instance classification으로 보는 시각이다. 해당 방법론에서 동일한 source(A, B)로 생성된 두 이미지(AB, BA)에 연관성에 대한 정보를 주기 위하여 두 mixed image도 positive pair로 지정하였다. - Case2: knowledge distillation
본 논문에서는 특히 DINO로 알려진 knowledge distillation frameworks를 기반으로 한다. DINO는 student model의 output이 teacher model과 match되도록 설계된 학습 방법론이다. 제안하는 방법론에서는 students가 배워야 할 teacher가 2개인데, source teacher와 mix teacher다.
실험: Proving the value of proposed
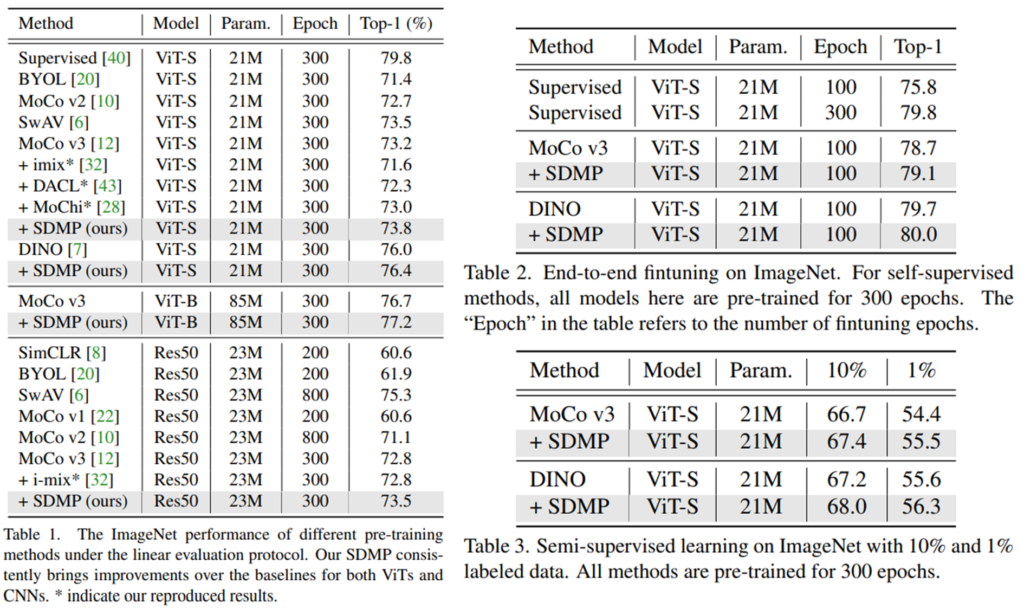
본 논문은 제안하는 SDMP의 검증을 위해 standard benchmarks인 imagenet, cifar-10/100에 대해 성능을 보였다. 실험을 통해 기존 방법론이 Self-supervised ViT에 적용하기 어려웠던 것을 해결하였음을 보였다.
Linear evaluation[Table1]: 각 방법론을 통해 학습한 backbone parameters를 모두 freezing 하고 linear classifier를 얹어 해당 레이어만 지도학습하는 실험으로 backbone의 표현력을 확인할 수 있다.
End-to-end finetuning[Table2]: 제안하는 self-supervised 방법론을 통해 사전학습한 후 supervised setting으로 finetuning한 결과를 리포팅하였다.