제가 이번에 리뷰할 논문은 VIO와 관련된 논문입니다. 이 논문은 depth 정보도 사용하고 있기에 직접 적용해보기에는 어려움이 있을 것 같지만, visual 정보와 inertial 정보를 융합하는 방식에 중점을 두고 알아보고자 리뷰하게 되었습니다.
Abstract
VIO는 카메라와 IMU 측정값을 융합하여 위치 정보를 알아내는 방식으로, 기존의 방법론들은 서로 다른 도메인의 정보(시각 정보와 관성 정보)를 융합하므로 일관적이지 못한 결과를 낼 수 있다는 문제점이 있었습니다. 또한, 절대 속도를 이용하지 못해 긴 시퀀스로의 확장이 어렵다는 문제점도 있었다 합니다.
이 논문은 시/공간 정보를 서로 다른 branch로 다루어 이미지 쌍과 연속적 이미지에 각각 집중하도록 설계를 하여 센서를 퓨전하는 방식을 제안합니다. 또한 warm start라는 작고 효과적인 모듈을 제안하여 속도와 관련된 정보를 IMU 인코더에 제공하도록 하였다고 합니다.
Introduction
VIO에 사용되는 카메라와 IMU센서는 둘다 저렴하고, 에너지 효율적이라는 장점이 있다고 합니다. 또한, VIO 연구들은 loosely coupled/ tightly coupled 방식으로 나뉘는 전통적 기법과deep network로 영상과 관성 측정값을 결합하는 학습 기반의 기법이 있습니다. 학습 기반의 방식의 경우 센서에 가중치를 주는 방식으로 센서를 퓨전하는 방식으로, 두 센서간의 상관관계를 학습하지 못한다는 문제가 있었고, 이를 해결하기 위해 저자들은 논문은 transformer-like 프레임워크를 가져와 IMU와 이미지를 query와 memory 형식으로 이용하는 방법을 제안하였습니다.
또한, VIO에서 IMU 정보를 이용하기 위해 LSTM을 인코더로 이용할 때, 초기값을 설정하는 것이 중요하지만 이를 완전히 해결하지 못한 상태였고, 이를 해결하기 위해 저자들이 warm start라는 모듈을 제안하였다고 합니다. 이 방식은 이전의 예측 포즈를 추출하여 인코더에 제약으로 이용하는 방식이라고 하며 이후에 더 자세히 다루도록 하겠습니다.
이 논문의 contribution을 정리하면 다음과 같습니다.
- ego-motion을 비지도, end-to-end 방식으로 예측
- 시공간 도메인을 분리하여 attention mechanism 적용
- warm start모듈을 제안하여 예측된 pose와 관성 측정값의 관계를 고려하여 IMU encoder의 초기값 생성
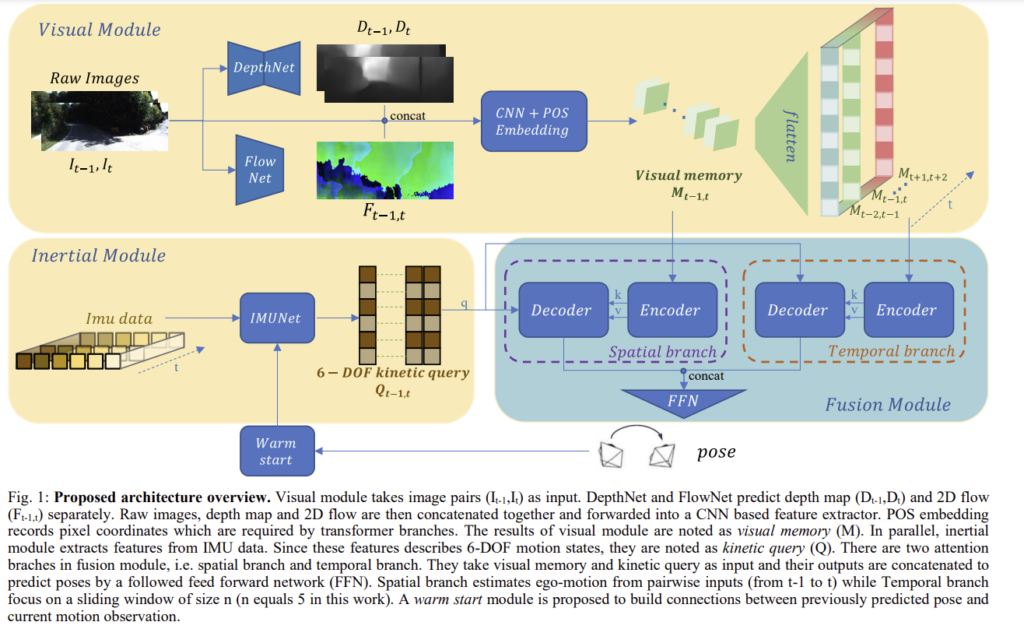
Proposed Method
저자들이 제안한 프레임워크는 visual module, inertial module, fusion module 3가지로 이루어져있습니다. visual 모듈은 이미지와 depth map, 2D optical flow를 통해 고차원 정보를 추출하고(visual memory), intertial module 6-DOF 모션 상태인 kinetic query(Q)를 출력합니다. 이후 2개의 attention branches를 함께 이용하여 ego-motion을 추정합니다. 또한, warm start를 이용하여 fusion과정에 이전 포즈와 현재 모션의 연관성을 만듭니다. 이제 각 모듈에 대해 자세히 알아보겠습니다.
A. Input Encoding
Visual feature encoding
인접한 이미지(I_{t-1},I_t)와 depth map(D_{t-1},D_t), 2D optical flow(F_{t-1,t})를 concat하여 줍니다. 이때 depth 정보는 모델에 주변 3차원 정보와 축적 정보를 제공하고, 2D optical flow는 픽셀의 변화량을 예측하고, 기하학적으로 제약을 주는 역할을 합니다. 또한, depth map과 optical flow는 GT가 아닌 네트워크의 출력(depth map은 DepthNet, optical flow는 MaskFlownet)을 이용합니다. ResNet-18을 feature extractor와 POS 임베딩을 위한 삼각함수로 이용하였고, 이 feature extractor와 POS 임베딩 함수를 F_v라 했을 때 다음과 같이 표현할 수 있습니다.
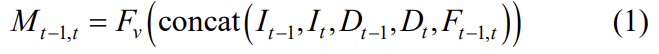
Inertial feature encoding
센서의 샘플링 주파수가 다르기 때문에 두 프레임 이미지 사이에는 N개의 그룹이 존재하며, 각각 3개의 가속도 값과 3개의 속도값이 있으므로 IMUNet의 입력 크기는 6xN이 됩니다. IMUNet은 2-layer LSTM과 fully connected layer로 구성되며 hidden state h에는 LSTM의 마지막 단계의 값과 warm start 모듈의 output이 포함됩니다. 이 과정을 F_i라 할 경우 아래의 식과 같이 정리할 수 있습니다. (warm start 관련 내용은 C에서 자세히 설명)
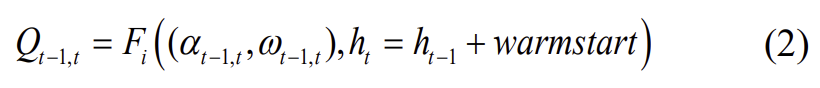
B. Spatial Branch and Data Fusion
attention 작동 방식과 그 활용인 object detection의 DETR에 영감을 받아, 공간적 transformer branch를 설계하여 2개의 센서 정보를 query와 memory로 만들어 융합하였다고 합니다. (이때 DETR은 탐지된 object의 다양한 영역과 크기의 박스에 집중하기 위해 100개의 쿼리 slot을 학습하고, 이에 따라 최대 100개의 객체를 탐지할 수 있다고 합니다.) 이때 관성 측정값과 pose transformation은 동일한 차원을 가지고, 이미지에서는 고차원 feature를 추출하므로 인코딩된 IMU 데이터를 쿼리로 사용하고 이미지에서 추출한 feature는 memory로 사용하였다고 합니다. (이때, memory를 얻을 때, object detection과 odometry가 다른 테스크이기 때문에 pre-trained model을 이용하지는 않았다고 합니다.) POS 임베딩은 visual memory에 픽셀의 위치 정보를 넣어 feature map이 vector로 분해될 경우에도 위치 정보를 가질 수 있도록 한다고 합니다.
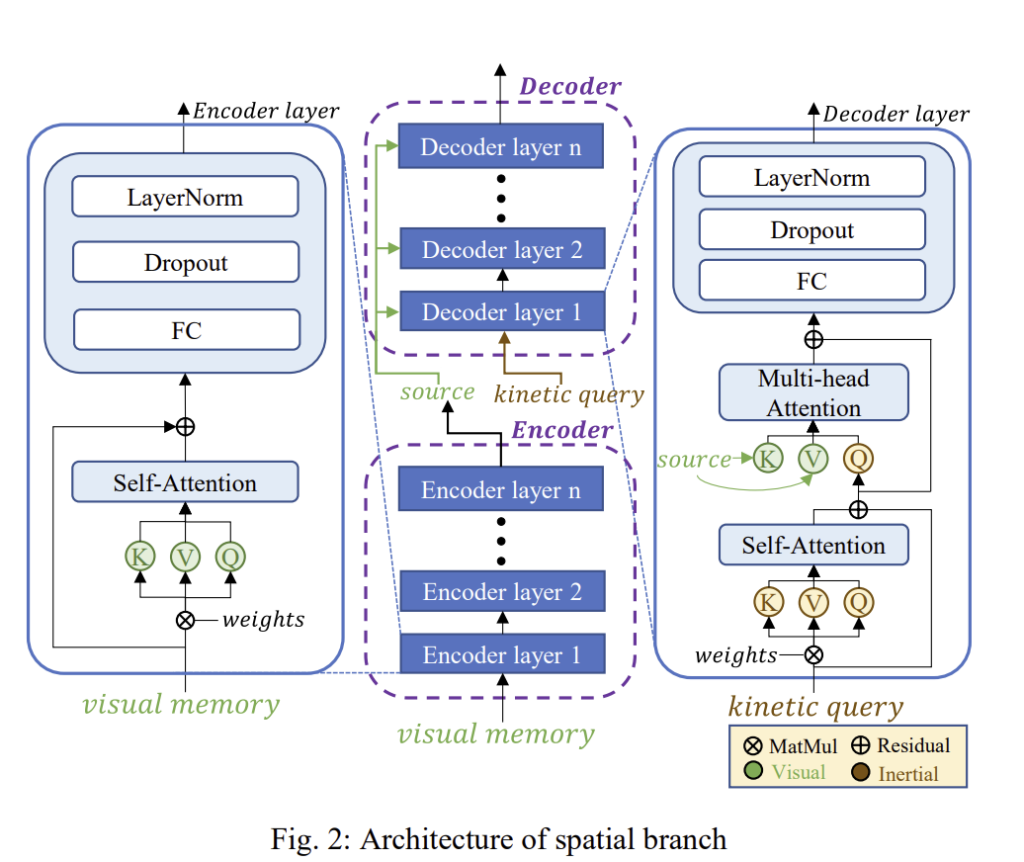
위의 그림2가 인접한 두 프레임의 이미지 사이의 ego-motion 추정에 도움을 주는 공간적 transformer branch를 표현한 그림입니다. visual memory가 self-attention을 만들기 위해 인코더로 들어가고, 인코더는 위와 같은 구조를 갖게 됩니다. 첫번째 레이어는 학습된 가중치와 visual memory를 곱하여 key(K), value(V), query(Q)를 얻습니다. 이후, self-attention은 다음의 식으로 정의합니다.
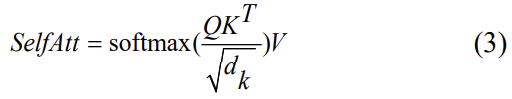
이때 d_k는 key의 차원을 의미합니다.
이후 FC 레이어의 입력으로 들어간 뒤 drop out, layer normalization를 통과하여 encoder layer 2로 전달되며, 레이어들을 통과해 최종적으로 source를 출력합니다.
decoder는 encoder와 유사한 구조로 이루어져 있으나 visual feature와 inertial feature를 융합하기 위해 multi-head attention 모듈이 추가됩니다. 과정은 우선 각 head를 self-attention(식(3)과 동일)을 이용하여 계산합니다. 이때, K와 V는 visual source에서 나오지만, Q는 kinetic query가 됩니다. 즉, 관성 측정값으로 부터 구한 query의 도움을 받아 visual feature와 6-DOF motion이 관련이 있는 부분에 집중을 하게 되는 것입니다. 이후 self-attention 값을 모두 concat하고 가중치\mathbf{W}^O를 곱해 multi-head attention을 얻습니다.
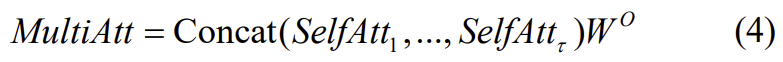
C. Temporal Branch and Sequence Consistency
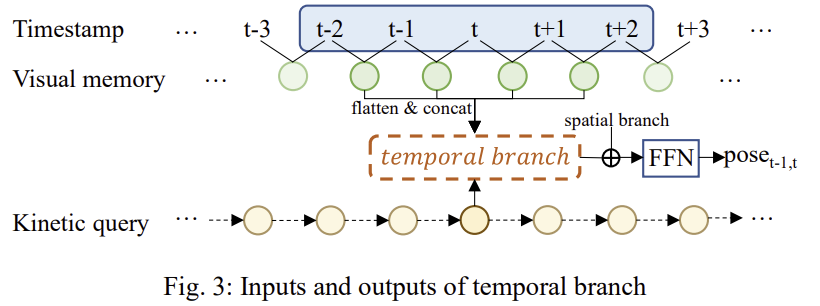
temporal branch는 시퀀스동안 scale의 일관성을 유지하도록 설계되었습니다. 앞서 설명한 spatial branch와 유사하지만 입력값이 다르고, 이미지 쌍을 보는 것이 아닌 이미지 내의 sliding window를 보며, window 크기는 이 논문에서는 5로 설정하였다고 합니다.
t-1→t의 상대 pose를 추정하는 경우라 했을 때,
우선 t-2에서 t+2의 visual memory를 flatten하고 concat하여 새로운 하나의 visual input으로 temporal branch의 인코더에 입력합니다. 이때 POS 임베딩을 통해 공간적 구조를 유지한다고 합니다. t에서의 kinetic query(IMUNet의 결과물)도 유사한 방식으로 decoder에 입력으로 들어가고, 두 branch의 결과를 concat하여 ego-motion을 추정합니다. 두 branch가 합쳐진 후 통과하는 FFN(feed forward network)는 2개의 conv 레이어와 avgpooling레이어로 구성되며, 음수와 양수를 모두 얻기 위해 tanh를 활성화 함수로 이용합니다.
D. Warm Start for IMUNet
속도가 없이 선형의 가속도만 주어질 경우, inertial 모듈은 scale이 모호하다는 문제를 겪게 됩니다. 따라서 예측된 pose로 부터 속도 정보를 추출하고 hidden state에 추가하고자 warm start 모듈을 제안하였다고 합니다. warm start 방식은 handcrafted 방식과 CNN 방식이 적용되었습니다.
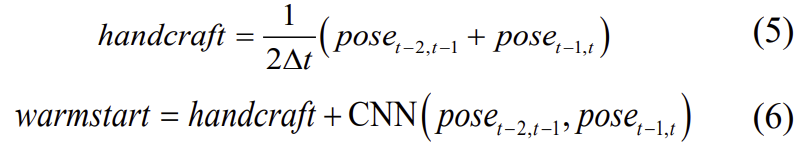
∆t는 두 이미지 간의 일정한 시간 간격을 의미하고, 식(6)의 CNN은 1d conv 레이어를 의미합니다. handcraft는 t-1에서 속도를 계산하고 CNN은 IMUNet의 속도 feature에 상대 pose를 매핑하여 구하며, pose를 사용할 수 없는 초기 단계에서는 warmstart없이 motion을 추정한 뒤 식(2)와 같이warm start를 반복합니다.
E. Loss Functions
image reconstruction을 기반으로 loss를 구하였다고 합니다.
카메라 intrinsic matrix S와 depth map과 이미지 사이의 상대 변환(T_{t-1,t}이 주어지면 아래의 식을 통해 이미지를 합성할 수 있습니다.
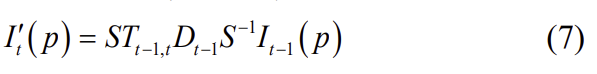
모든 이미지에 대한 I'_t를 생성하고 합성 영상을 원본과 일치시키며 image reconstrution loss는아래의 식으로 공식화할 수 있습니다.
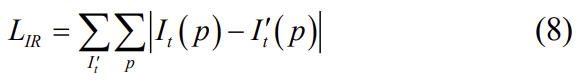
또한 L_D loss는 I_{t-1}을 3D 공간으로 투영시킨 추정된 상대 pose를 이용하여 t에서의 3D point를 구한다. 이후 t시간에서의 3D 포인트 정보를 투영시켜 구한 depth map D_t^c와, 식(7)과 같은 방식으로 합성하여 구한 depth map D_t^s 를 이용하여 loss를 계산한다.
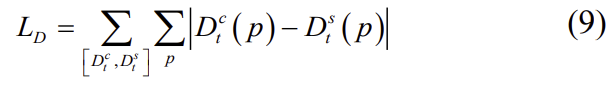
게다가 동일한 랜드마크에서 샘플링된 서로 다른 이미지의 픽셀들은 공간으로 투영되었을 때 동일한 3D 좌표 C(p)가 된다는 점을 이용하여 loss L_C를 계산합니다.
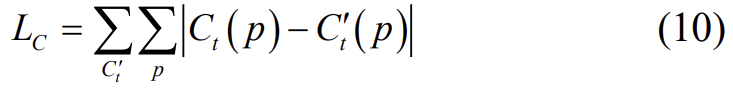
이렇게 하여 total loss는 위의 loss 3가지를 가중 합한 결과가 됩니다.
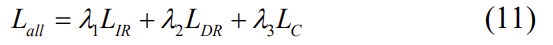
저자들은 실험을 할 때 λ1=0.6, λ2=0.2, λ3=0.2로 설정하였습니다.
Experiments and Evaluation
Dataset
KITTI _GPS로 얻은 GT가 포함된 11개의 시퀀스로 구성되며, 00-08시퀀스(IMU 데이터를 사용할 수 없는 03는 제외)는 학습에 사용하고, 09-10은 test set으로 사용합니다. 이미지는 10Hz, IMU는 100Hz로 기록되므로, 두 프레임 사이의 inertial encoding의 입력 사이즈는 10×6이 됩니다.또한 원본 데이터에서 누락된 IMU 프레임은 선형 보간을 이용하여 처리하였다고 합니다.
Malaga_ outdoor 데이터셋으로 다양한 시나리오에서의 강인성을 평가하는 데 사용되고, 마찬가지로 이미지는 10Hz, IMU는 100Hz로 수집하였고, {01, 02, 04, 05, 06, 07}시퀀스는 학습에 03은 test에 사용하였다고 합니다.
Motion Estimation
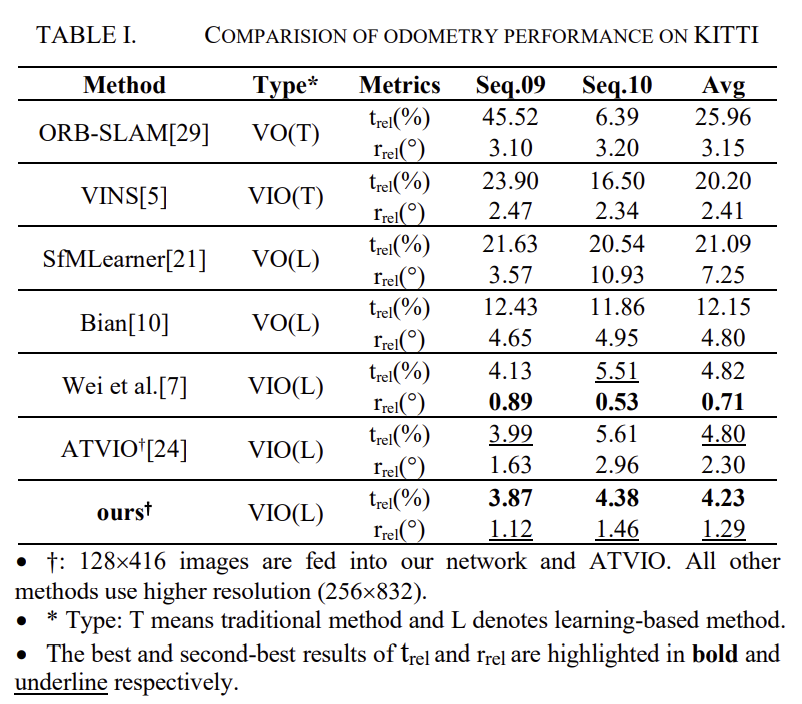
표1은 KITTI 데이터셋에 대한 정량적 결과로, 100~800m 길이의 평균 이동 및 회전 RMSE 차이를 측정하였다. 해당 논문의 성능 비교를 위해 전통적인 VO[29]와 VIO[5], 학습기반 VO[21,10]와 VIO[7, 24]의 결과가 리포팅되어있습니다. 모든 방법론들은 단일 이미지와 IMU를 입력으로 하며, 해당 방법론과 동일한 학습/테스트 세트를 이용하였습니다.
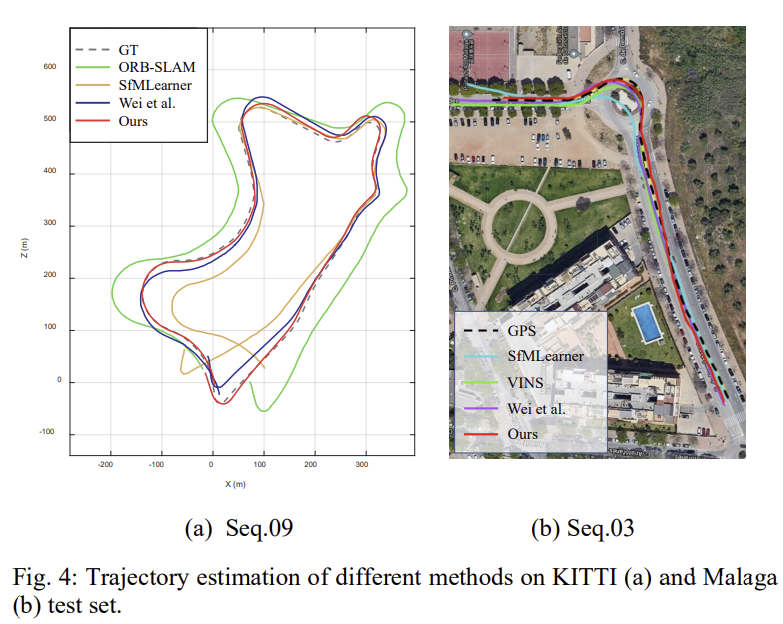
translation에 대해서는 가장 좋은 성능을 달성하고, rotation에서는 2번째로 좋은 결과를 달성하였으며, 다른 방법론들과 비교했을 때 저해상도의 이미지를 이용하였다고 합니다. 정성적 평가를 위해 궤적을 나타낸 결과를 아래의 그림으로 나타내었습니다. (참고로 Malaga는 03 sequence만을 test 데이터로 사용하고 있어서 그런지 논문에 정량적인 결과는 따로 리포팅하지 않고 정성적으로만 보였입니다.)
Ablation Study
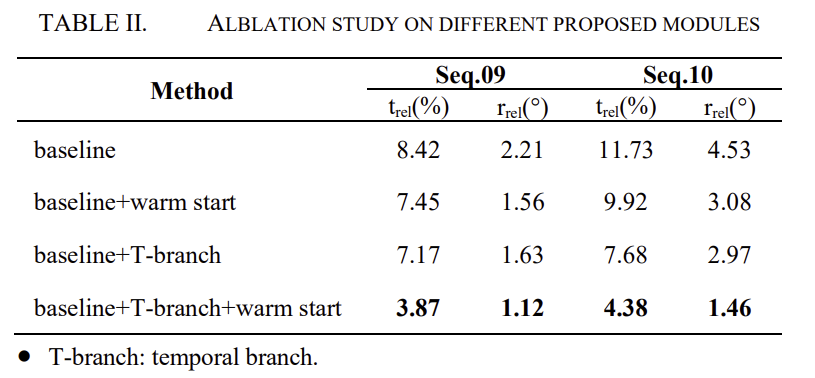
각 요소의 중요성을 확인하기 위해 KITTI 데이터셋으로 ablation study를 진행하였고, 베이스라인은 두개의 인접한 영상과 해당 IMU 데이터를 입력으로 사용하고 fusion에는 spatial branch만 활용하였고 이에 대한 결과를 표2에 리포팅한 것입니다. 정성적인 결과를 통해 warm start와 temporal branch가 추가됨에 따라 성능이 향상되는 것을 확인할 수 있습니다.
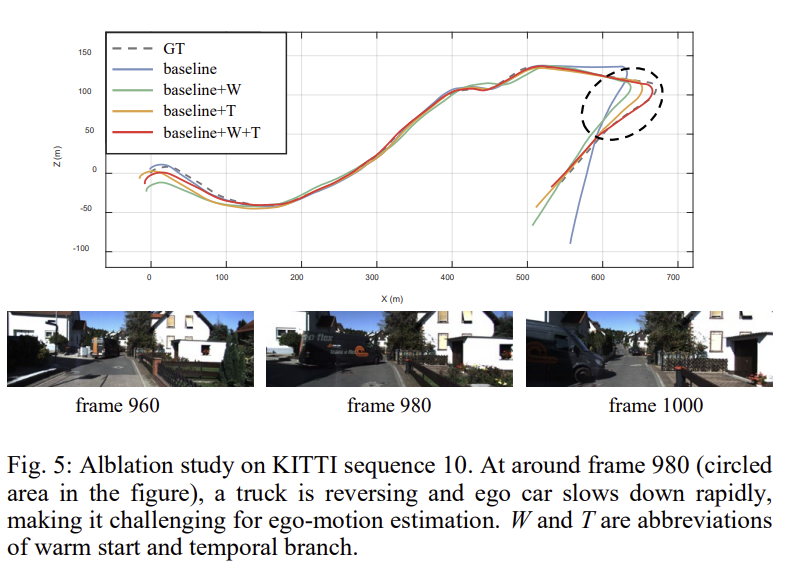
그림 5는 시퀀스 10에 대한 궤적을 나타낸것으로, 트럭이 후진함에 따라 촬영에 사용된 차의 속도가 빠르게 낮아진 상황이 포함되어 있습니다. (검정 점선에 해당하는 부분) 이에 대한 실험 결과를 통해 제안된 temporal branch 및 warm start는 동적 시나리오와 차량 속도의 급격한 변화에 대해 모델의 강인성을 향상시킬 수 있다는 것을 확인할 수 있습니다.
Robustness test
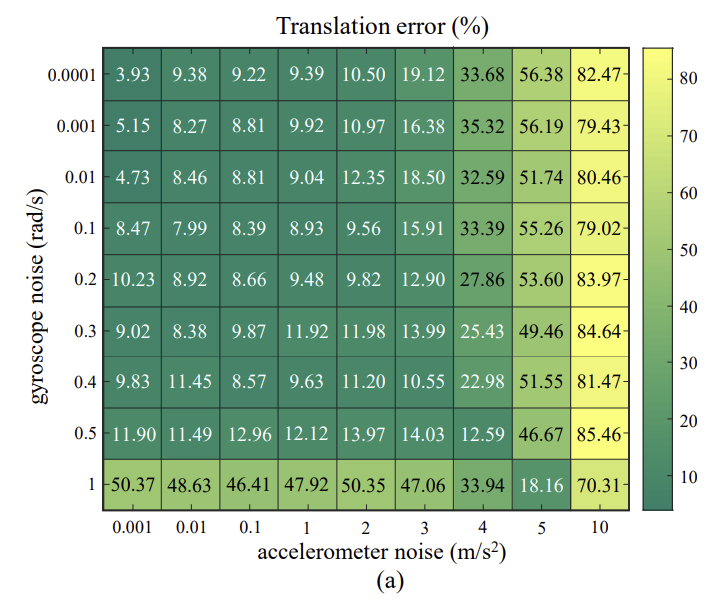
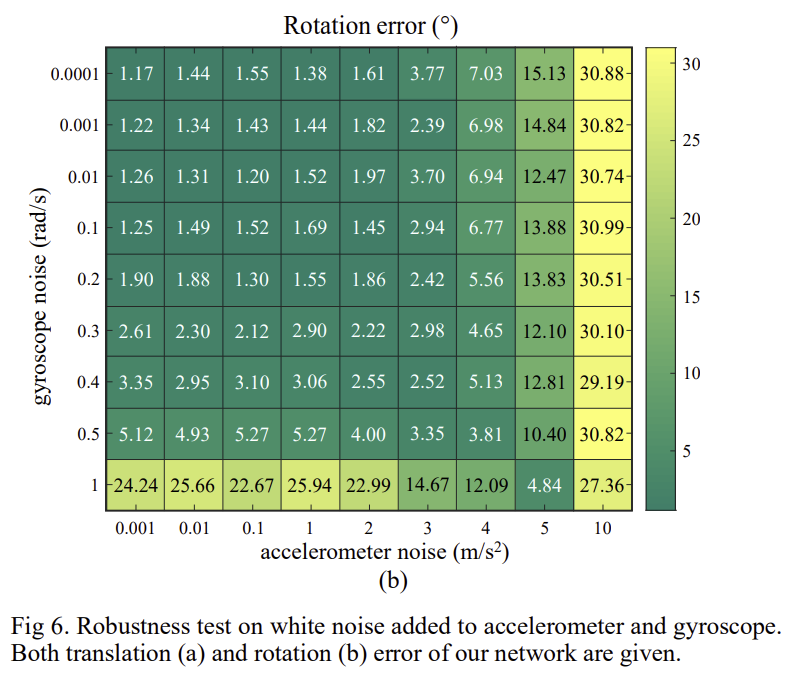
사람과 환경적 요인(차랑의 진동)으로 카메라와 IMU에 노이즈가 생길 수 있으며 두 센서의 시간 동기화가 맞지 않을 수도 있고, 이에 대한 강인성을 확인하기 위해 오염된 데이터(IMU 노에즈, 이미지 블러, 동기화가 맞지 않는 상황)를 이용하여 실험을 하였고 이에 대한 결과를 그림 6에 표현하였다고 합니다. 이를 통해 가속도계 노이즈가 최대 3m/s^2, 자이로스코프 노이즈가 최대 0.5rad/s일 경우까지 경쟁력 있는 성능을 얻을 수 있다는 것을 확인하였다고 합니다.
IMU 센서 데이터와 카메라 데이터를 fusion하는 방식을 적용해 볼 수 있을 것 같고, 특히 마지막에 Robustness test에 해당하는 실험을 잘 적용해보면 좋을 것 같다고 생각하였습니다.
안녕하세요 좋은 리뷰 감사합니다
제가 그동안 해당 분야를 많이 접하지 않았어서 용어가 조금 생소하네요 혹시 VIO의 문자적 의미가 무엇인지, 축약 이전의 단어가 궁금합니다.
둘째로 기존 VIO 방법론의 문제점인 일관성의 하락의 원인이 무엇인가요? 서로 크게 다른 두 도메인을 같이 사용하므로써 발생하는 성능하락이 원인이 되는것인가요?
또한 해당 방법론이 “시/공간 정보를 서로 다른 branch로 다루어 이미지 쌍과 연속적 이미지에 각각 집중하도록 설계” 했다고 하셨는데 혹시 share branch로 진행하는 기존 연구가 있었는지, 있었다면 해당 연구의 어떤 특징때문에 branch를 서로 나누었는지 궁금합니다.
또한 loosely coupled/ tightly coupled 등의 용어도 저에게는 조금 어렵네요 ㅎㅎ
시, 공간을 분리했다고 하셨는데 시간적 정보는 무엇이고 공간적 정보는 무엇인가요? 제가 이해하기는 시간(IMU)/ 시간+공간(video) 으로 이해되서 질문드립니다!
감사합니다
VIO란 visual-inertial odometry로, 카메라의 시각정보와, IMU센서로부터 얻은 관성 정보(속도 가속도)를 이용하여 ego-motion(상대적인 위치 변화)를 측정하는 것입니다.
VIO의 문제점이 일관성 하락이라기보다도, 시각 정보와 inertial 정보가 도메인이 다른데 (차원수도 시각정보는 WxHxC 일때, inertial 정보는 6) 단순히 concat하는 방식으로는 두 도메인의 correlation 학습이 제대로 되지 않을 수 있다는 의미로 보입니다.
visual-inertial odometry(VIO)에서 loosely-coupled방식은 visual 센서의 정보와 inertial 정보를 독립적으로 처리하여 pose를 추정한 후 이를 융합하는 방식입니다. VO 알고리즘을 크게 변경하지 않고 inertial 정보를 통합할수 있다는 장점이 있으며, extreme한 상황에서 견고성을 가질 수 있어 sensor failure 상황을 잘 관리할 수 있다고 합니다.
또한, tightly-coupled 방식은 camera poses, feature positions, IMU 파라미터를 동시에 최적화하는 방식으로, 상관관계가 높아지도록 할 수 있지만 다르 센서와 융합하기 어렵고, 구현이 어렵다는 단점이 있다고 합니다.
share branch로 진행하는 기존 연구가 있었다기보다는, 이 논문이 tightly-coupled 방식이며, 이때 카메라와 관성 정보를 합칠 때 공간적 정보와 시간적 정보를 나누어 잘 볼 수 있도록 branch를 거친 뒤 합치는 방법을 제안했다고 이해하였습니다.
우선 IMU 센서로부터 얻은 정보는 IMUNet을 거쳐 6-DOF 쿼리 값(pose)으로 바뀌어 두 branch에 들어갑니다.
spatial branch는 인접한 두 프레임의 이미지와 그 두 프레임 사이에 해당하는 pose값이 들어갑니다. 즉, 두 프레임(한 쌍의 이미지)을 고려하는 것이고,
temporal branch는 t-2~t+2에 해당하는 이미지들(의 sliding window를 고려한다 함)과 t에 대응되는 pose 값을 입력으로 하기 때문에 시간적 정보를 활용할 수 있다고 합니다.
warm start에 대한 추가적인 설명 부탁드려도 될까요??
우선 IMU센서가 변화량을 측정하다보니, 절대 속도 정보가 없을 경우 scale이 모호하다는 문제가 있고, 이를 해결하기 위해 pose를 예측하는 IMUNet에 속도 정보를 hidden state에 추가하여 scale이 더 명확한 pose를 추정하려 한 것으로 이해를 하였습니다. 이를 위해 주어진 식 (5)를 이용하여 t-1에서의 속도 정보를 구하고 (거리-속도-시간 관계에 의해 handcraft값이 t-1에서의 속도를 의미), CNN( )을 이용하여 (t-2,t-1)과 (t-1,t)의 pose 정보를 융합한 값을 handcraft 값과 합쳐준다는 의미로 이해하였습니다.
이렇게 얻은 값이 warm start라는 값이 되어, 속도정보와 pose 정보를 내재한 정보가 되어 LSTM에서 pose를 측정할 때 활용하겠다는 의미라 이해하시면 될 것 같습니다.