이번 리뷰 논문은 오랜만에 KITTI를 타겟으로한 3차원 물체 검출 방법론를 다룹니다. 해당 논문은 처음으로 end-to-end로 진행되는 3차원 물체 검출을 제안한 논문입니다. 해당 방법론의 재밌는 포인트는 깊이 추정 모델과 3차원 물체 검출을 통합하며, end-to-end로 학습을 진행한다는 점이 특징적인 부분입니다.
Intro
3차원 물체 검출은 자율 주행의 인지 능력에 있어서 매우 중요한 역할을 가집니다. 그렇기에 3차원 물체 검출에 있어서 모델의 입력 혹은 모델 자체가 3차원 공간의 정보를 얼마나 잘 효율적이며 효과적으로 이해하는 것이 매우 중요합니다. 이러한 예시로 자율 주행 회사는 3차원 인지를 위한 깊이 센서 Lidar를 사용하지 않는 테슬라 진영과 Lidar를 이용하는 반 테슬라 진영으로 구분 지을 정도로 매우 중요한 부분이라고 볼 수 있습니다.
Lidar를 이용한 3차원 물체 검출은 영상기반의 방법론을 능히 능가할 정도로 높은 성능을 보여주고 있습니다. 하지만 센서의 가격과 물리적인 움직임으로 인해 센서 자체의 내구성이 떨어지기 때문에 실용성이 떨어진다는 문제점이 있습니다. 반면에 카메라를 이용한 영상기반의 3차원 물체 검출은 상대적으로 센서 비용이 적으며, 내구성 이슈도 덜하다는 장점과 다른 기능과 함께 사용이 가능함으로써, 범용적인 쓰임새가 있다는 장점이 있습니다. 하지만 영상 기반의 3차원 물체 검출은 영상 공간에서 3차원 공간을 추론함으로써 발생하는 깊이 정보의 모호성으로 인해 성능 저하를 보여준다는 한계가 있습니다. 이와 같은 이유로 두 방향의 방법론들은 한쪽은 센서의 한계, 다른쪽은 알고리즘의 한계를 가지고 있어 누가 우위를 가진다고 보기 힘듭니다.
오늘 리뷰 논문에서는 영상 기반의 3차원 물체 검출에 대해 다루고자 합니다. 해당 방법론은 스테레오를 이용하여 3차원 물체 검출을 진행합니다. 특히 저자는 영상에서 3차원 정보를 추론함으로써 발생하는 노이즈에 대해 집중하고자 합니다. 해당 논문이 출판된 시기에는 psuedo-lidar가 대세를 이루고 있었습니다. psuedo-lidar는 깊이 추정 모델과 추정된 깊이 정보를 실제 세계 좌표에 해당하는 포인트 클라우드로 변환시켜 라이다 기반의 3차원 물체 검출 기법으로 3차원 검출을 수행하는 방법을 사용합니다. 저자는 사전에 학습된 깊이 추정 모델을 사용하는 방법에 문제가 있다고 지적합니다. 특히 깊이 추정 모델를 이용한 포인트 클라우드에서는 잘못 매칭된 정보로 인해 인공물이 생성된다는 문제점이 있습니다. 두 모듈이 별개로 학습함으로써 모호한 부분에 대한 정보를 알 수 없기에 노이즈로 보아 성능이 떨어진다는 문제점을 지적합니다.
그렇기에 저자는 사전 학습된 깊이 추정 모델을 사용하는 것이 아닌 3차원 물체 검출 모델과 통합하여 3차원 물체 검출에 특화된 표현력을 가지도록 합니다. 추가로 대부분의 스테레오 기반의 깊이 추정 모델들은 대응되는 픽셀로부터 disparity를 구하여 깊이 정보를 구합니다. 즉, 매칭된 픽셀간의 거리를 찾는 것이 곧 깊이 정보를 구하는 방법에 해당합니다. 하지만 영상의 정보들은 픽셀이라는 명확히 구분된 정보들의 구성으로 표현되기 때문에 가까운 거리에 위치한 정보인 경우, 깊이 정보에 대한 구분 능력이 떨어진다는 문제점이 있습니다. 예를 들어 kitti에서는 39-40m(< 0.25px)에 위치한 물체인 경우에는 disparity 차이가 거의 없기 때문에 구분하기 어렵다는 문제점이 있습니다. 이러한 문제점을 해소하기 위한 방법론으로 plane sweeping approach 방법이 있습니다.
+ plan sweep이란 다른 위치에서 촬영된 영상을 겹쳐놓고 점차 이동을 시키면 일정 부분에서는 두 영상이 일치된다는 현상을 이용하여 깊이 정보를 추론하는 방법입니다. 이러한 특징으로 픽셀 수에 의존적인 스테레오 매칭 기법 대비 능동적으로 대응이 가능하다는 장점이 있습니다. ++ 쩝… 해당 부분에 대해서는 정성적인 분석이 없어 아쉽습니다… 해당 방벙론의 베이스 모델인 스테레오 깊이 추정 모델 PSMNet에서 사용하는 퓨전 방법-채널 측면에서 결합을 한번 더 모듈을 태우는 것을 이렇게 의미 부여를 할 수 있구나 싶네요 ㅋㅋㅋ 정성적인 부분이라도 있었으면 ‘오 대단한 발견이다!’할텐데 컨트리뷰션을 만들고자 원래 있던거에 의미 부여한 느낌이 들어 아쉬운 감이 있습니다.
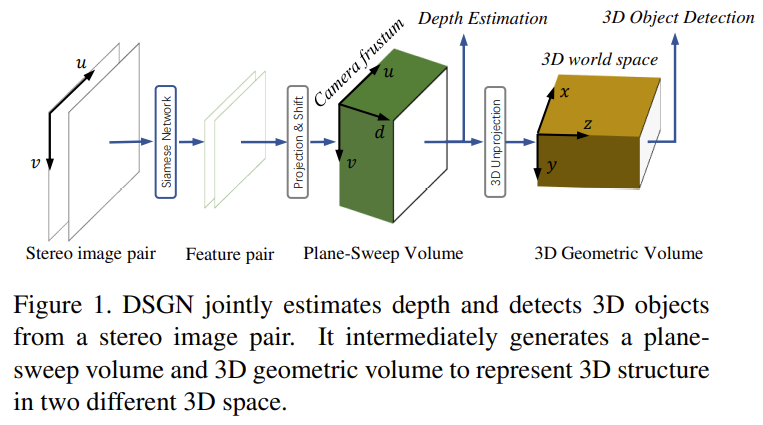
보다 구체적으로 저자가 제안한 파이프라인을 소개드리자면 fig 1과 같습니다. plane sweeping approach 측면에서 깊이 정보를 추론하여 camera frustum(Plane-Sweep Volume)을 구성한 후, 카메라 파라미터를 이용하여 3D world space로 사영된 3D Geometric Volume을 생성하여 3차원 물체 검출를 수행합니다. 해당 파이프 라인은 pseudo-lidar 대비 고품질의 기하학적 구조 정보 뿐만이 아니라 픽셀 수준의 의미론적 정보를 함께 학습이 가능하다는 장점이 있습니다.
좀 더 정리하자면 기존 영상 기반의 방법론들은 영상 속 물체가 거리에 따라 스케일이 달라지는 현상을 이용허여 2d representation을 구해 3차원 물체 검출을 수행하고자 했습니다. 하지만 같은 클래스 속 물체들은 각기 마다 형태나 크기가 매우 상이하기 때문에 깊이 정보와 연관성을 구하기가 매우 어렵습니다. 또한 단축법에 의해 같은 스케일인데도 불구하고 관점에 따라 다른 스케일로 보인다는 문제점이 있습니다. 그렇기에 저자는 기존의 방법과는 다르게 camera frustum(Plane-Sweep Volume)을 우선적으로 구하고 이를 다시 BEV로 사영하여 3차원 물체 검출을 수행하는 방법을 제안합니다. 자세핰 내용은 다음 섹션에서 다루겠습니다.
+ 전반적인 방향성(철학)은 psuedo lidar랑 같은 방향성을 가진다고 보시면 됩니다. 단, 사전 학습된 모듈의 한계를 end-to-end로 가져가면서 얻는 장점이 추가된거라고 보시면 됩니다.
Method
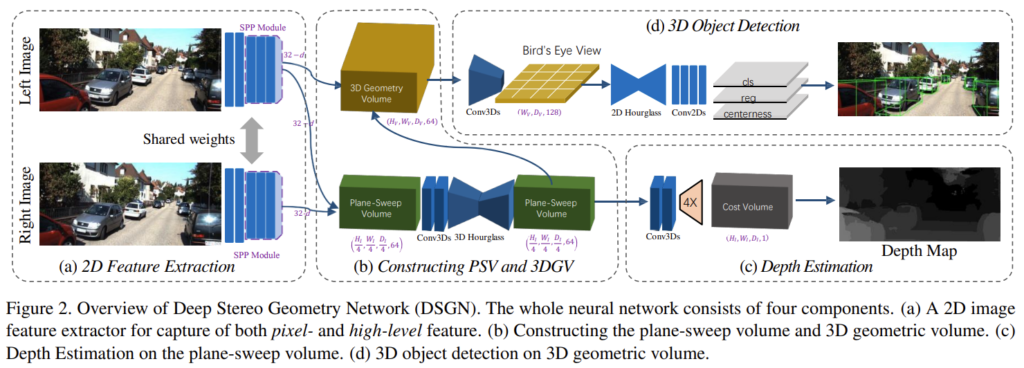
Deep Stereo Geometry Network
DSGNet의 전반적인 파이프라인은 fig 2와 같습니다. 스테레오 입력 쌍 (I_L, I_R)로부터 weight를 공유하는 Siamese network를 통해 feature를 추출하고 plane-sweep volume (PSV)를 구성합니다. 이를 기반으로 pixel-correspondence를 학습합니다. plane-sweep volume를 기반으로 미분 가능한 와핑을 통해 3차원 세계에 투영한 3D geometric volume (3DGV)로 변환한 다음에 3D object detection을 수행합니다.
Image Feature Extraction & Constructing 3D Geometric Volume
저자는 두 영상 속 대응되는 픽셀 대응을 잘 찾기 위해 스테레오 깊이 추정 모델인 PSMNet을 기반으로 모델을 구축합니다. 해당 모델의 backbone을 이용하여 특징을 추출한 다음 두 특징을 차원 측면으로 결합을 진행합니다. 저자는 이를 plane-sweep volume (PSV)라고 명명합니다. PSV는 두개의 3D conv를 거쳐 3D hourgalss를 통해 3차원 깊이 정보를 학습하도록 유도합니다. 해당 모듈에서는 깊이를 그대로 학습하는 것이 아닌 camera frustum 측면에서 깊이 정보를 예측하도록 학습됩니다. 해당 모듈에서 추론된 PSV는 아래의 수식을 통해 실제 세계 좌표로 투영됩니다.
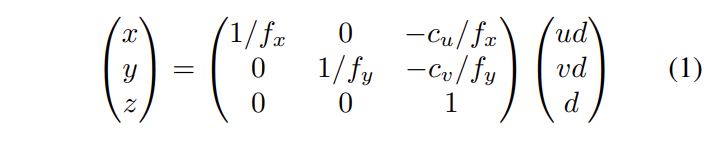
수식 1은 내부 카메라 파라미터로 구성되며, 해당 수식으로 PSV는 3D geometric volume으로 변환됩니다. 또한 해당 수식은 상삼각행렬로 손쉽게 미분이 되기에 통합된 네트워크 구성에 있어 어려움을 주지 않습니다. 변환된 volume은 실제 세계의 정보를 표방합니다. 유사한 알고리즘으로 psuedo lidar를 생각하시면 좋습니다. 변환된 정보는 trilinear interploation을 통해 x4로 업샘플링되어집니다.
Depth Regression on Plane-Sweep Cost Volume
plan-sweep volume으로부터 대응된 픽셀을 학습하기 위해서 fig 2와 같이 깊이 정보를 회귀합니다. 해당 모듈은 PSMNet과 동일한 모델 구조로 이뤄져 있습니다. 단, plane-sweep volume으로부터 깊이 정보에 대한 매칭을 진행하기 위해 아래 수식을 이용하여 변환을 진행합니다.
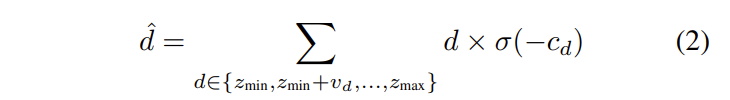
수식 2는 soft-argmin operation으로 사전 정의된 [z_min, z_max]의 에서의 c_d 정보부터 계산되어집니다.
3D Object Detector on 3D Geometric Volume
해당 모듈에서는 변환된 3D geometric volume을 이용하여 3차원 물체 검출을 진행합니다. 해당 모듈은 2차원 물체 검출인 FCOS에서 영감을 얻어 설계되었습니다. 3D geometric volume는 3D conv를 통해 (W, D, 128)로 압축된 featue를 투영하며, 2차원 물체 검출 FCOS와 유사한 모델을 통해 학습을 진행합니다. 해당 모듈에서는 사전 정의된 anchor를 이용하며, 각 픽셀에서는 해당된 anchor의 offset을 예측하는 방향으로 학습되어집니다. Anchor는 x, y, w, h, l, z, theta에 대한 정보를 예측하며, 추가적으로 FCOS의 특징은 centerness를 계산합니다. 저자는 3차원 공간에 맞는 centerness를 다음과 같이 정의합니다.
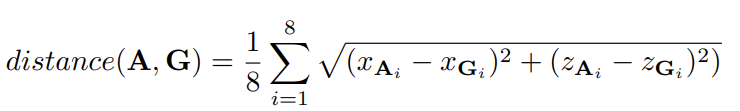
앞서 가정한 대로 BEV로 투영했기 때문에 좌표계에 대한 표현은 x, z로 구성이 가능합니다. 그렇기에 위의 수식과 같이 x, z 측면에서의 3차원 박스 여덞점에 대한 예측값과 GT 정보 간의 거리 값을 예측합니다.
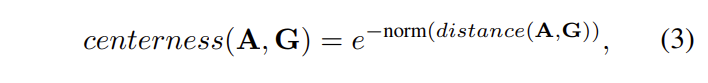
예측된 정보는 수식 3에 의해 centerness의 정도를 예측합니다. + 해당 내용에 대한 자세한 내용은 FCOS를 참고
Multi-task training
저자가 제안한 구성은 깊이 추론과 3차원 물체 검출을 동시에 수행합니다. 이에 대한 수식 4와 같이 구성된 loss를 설명합니다.
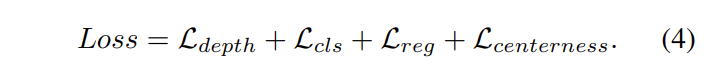
전체 loss는 깊이 추론 모델인 PSMNet의 loss와 3 차원 물체 검출에 맞도록 변경된 FCOS loss를 응용된 loss로 구성됩니다.
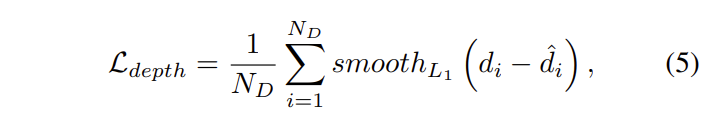
Depth loss는 수식 5와 같이 L1 loss로 구성되며, N_D는 제공된 Lidar 포인트를 의미합니다.
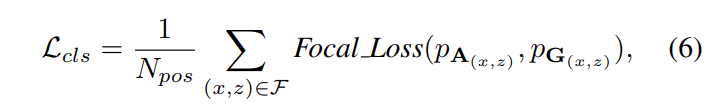
Classification loss는 데이터 불균형을 방지하기 위해서 수식 6과 같이 focal loss로 구성됩니다.
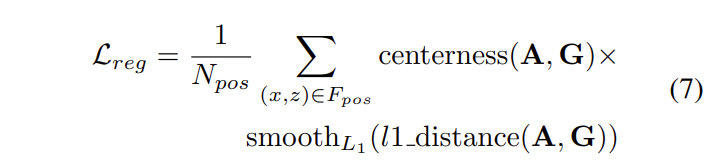
Regression losss는 수식 7과 같이 3차원 bounding box를 구성하는 값에 대한 l1 loss로 학습이 진행되며 FCOS의 특징대로 centerness에 대한 예측도 같이 수행됩니다. 추가적으로 overfitting을 방지하기 위해서 Positivie case에 대해 선별을 진행하여 학습을 진행합니다. Positive sample들은 영상 내 존재하는 물체 수에 비례하여 선별되어집니다.
Experiment
제안한 모델은 LiDAR 기반 방법론의 대표적인 MV3D를 능가하며 특히, Pseudo liadr(PL) 조차 능가하는 결과를 보여줍니다.
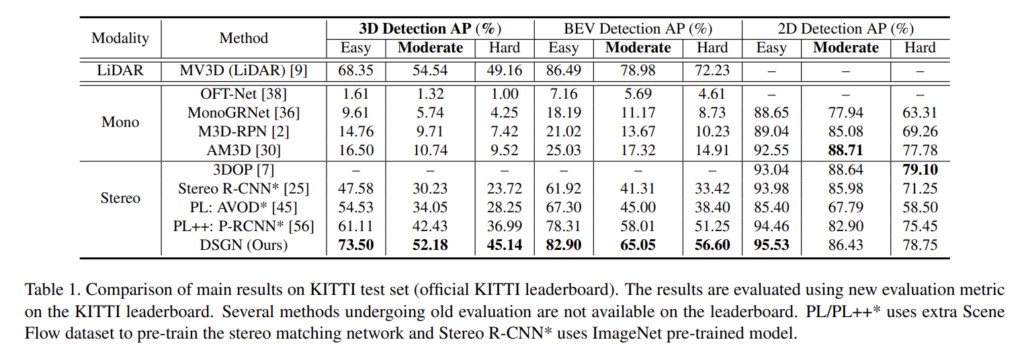
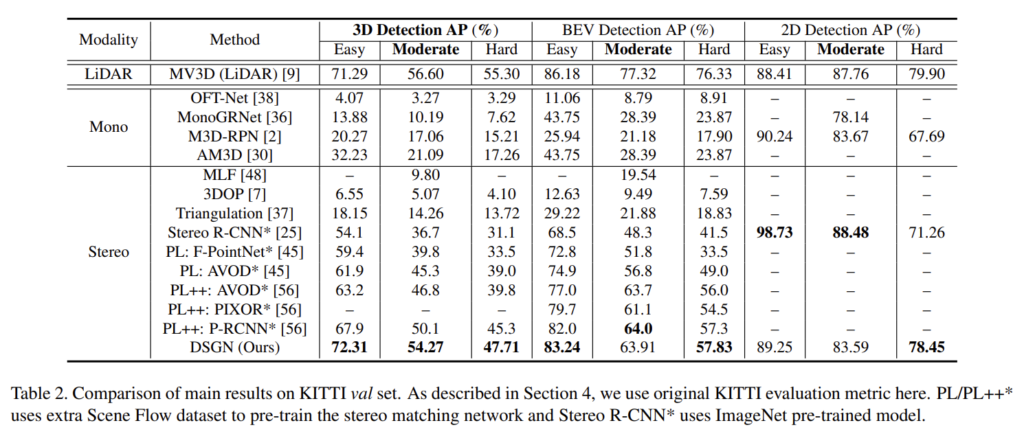
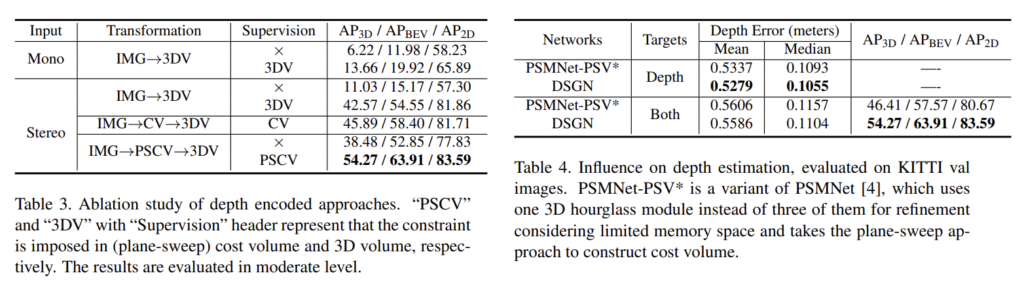
또한 변환 방법에 대한 효과를 증명하기 위한 ablation study를 진행합니다. Tab 3에서 PSV를 이용하지 않고 CV는 직접적으로 깊이 정보를 회귀한 경우에 해당합니다. Supervision은 멀티 태스킹이 아닌 사전 학습된 모듈을 이용한 경우에 해당합니다. 실험 결과 제안한 모듈을 이용할 경우 가장 좋은 성능을 보여줍니다. Tab 4는 제안한 PSV의 효과를 입증합니다. 깊이 추정 모델의 베이스 모델인 PSMNet에 PSV를 추가했을 때, 베이스 라인 대비 성능 향상을 보이며 3차원 물체 검출과 동시에 학습하는 경우에도 성능을 능가하는 결과를 보여줍니다.
좋은 리뷰 감사합니다.
본 논문은 영상 기반의 3차원 물체검출에 대한 논문으로,
가까운 물체의 disparity 차이가 거의 없어 깊이 정보를 구하기 어렵다는 것에 초점을 두고 plane sweeping approach을 통해 문제를 해결하고자 한 것이라고 이해하면 될까요? Plane Sweeping Approach는 통해 거리에 따라 물체의 스케일이 달라지는 것을 이용한 것인가요?
좋은 질문이자 지적이네요.
plane sweeping approach에 대해 다시 설명드리자면 특정 시점 차이를 가진 영상을 겹쳐 보았을때 초점이 맞지 않다가 한 영상을 일정 거리 이동할 경우 시점이 맞는 현상을 보입니다. 이에 대한 예시는 유튜브 영상(https://www.youtube.com/watch?v=EjJq3PunF9A)를 참고하시면 좋을 것 같습니다.
이러한 특징을 이용하여 명시적으로 픽셀 매칭을 이루는 것이 아니라 두 특징 영상을 concat하여 hourglass를 태워 암시적으로 픽셀 대응을 진행하는 방법을 제안한다고 합니다. 사실 해당 모듈이 plane sweeping approach를 이용하는 방법인지는 저도 확신이 들진 않습니다. 실험을 통해 정량적인 향상은 보였지만, 정성적인 결과는 없어 더욱 모호하게 받아들여지긴 합니다.