예전에 비디오 하이라이트/요약 관련 논문들을 쭉 읽었었는데요. CVPR-2022에서도 하이라이트 논문이 나와서 한번 읽어봤습니다.
Introduction
Task에 대한 설명은 예전 리뷰 1과 예전 리뷰 2의 도입부를 참고해주세요. 본론으로 바로 들어가자면 이전 논문에서의 문제점을 조금 더 해결했습니다.
일단 기존의 연구의 문제점으로 temporal한 정보와 localized 정보를 활용은 하는데, 세그먼트 내의 context를 고려하지 않는 다는 점을 제시하고 있습니다. 그러면서 여러 예시를 통해 이러한 정보들을 고려하는 것이 비디오 하이라이트 감지에서 중요하다는 것을 밝힙니다.

예를 들어서… [그림 1]을 볼 때 기존의 방법론이 비디오에서 세그먼트에 대한 highlight score를 예측해서 그 결과를 바탕으로 예측을 하는 식으로 동작한다면, 이 방법론은 이제 앞뒤 프레임의 연속적인 정보를 이용하여 예측을 수행합니다.
이 정보를 이용하기 위해서 pixel-level distinction estimation 방법론을 이 방법론에 적용합니다. 안그래도 프레임 전부 봐야하는 방법론들도 있는데, 픽셀까지 보면 연산량이 감당이 되나 싶지만… 논문 저자는 이 부분에 대해 context 정보를 볼 수 있다는 점과 설명하기 좋다는 장점 (실제로 어떤 물체 혹은 영역을 보고 하이라이트라고 했는지 설명이 가능) 때문에 장점이 있다고 합니다.
아무튼 contribiution을 정리해보면… 다음과 같습니다.
- Video hightlight detection에 pixel-level distinction estimation 방법론 결합 제안
- temporal한 정보봐 spatial한 정보를 보두 고려하면서도, pixel-level distinction을 수행할 수 있는 3D conv기반의 encoder-decoder network 제안
- SOTA
Approach
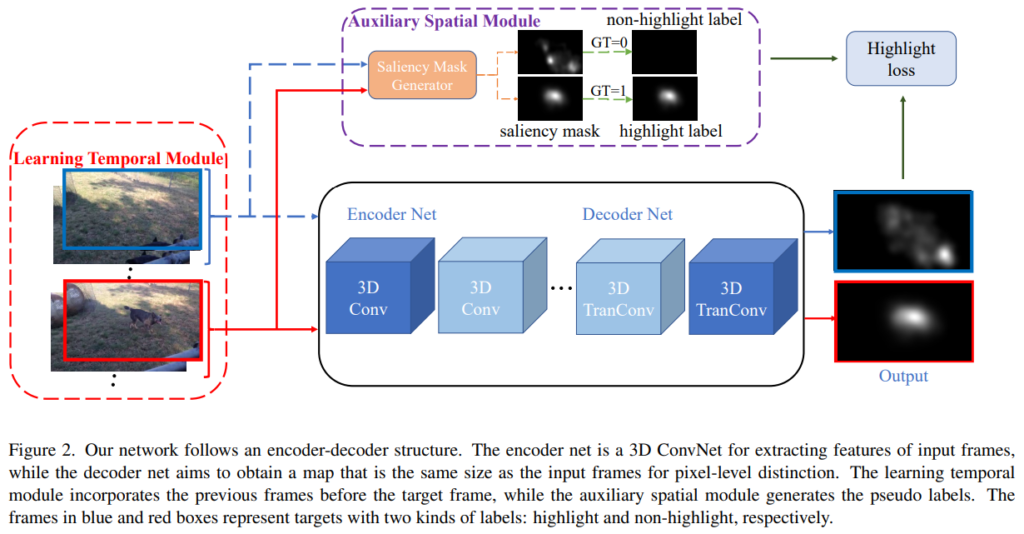
기존 방법론들의 문제점으로 단순히 프레임 혹은 세그먼트에 대한 highlight score를 이용해서 평가를 수행하니 spatial-temporal한 관계를 고려하지 않는다는 점을 지적하며, 비디오 하이라이트에서는 이러한 정보들이 매우 중요함을 강조합니다. 전체적인 프레임워크 [그림 2]를 보시면, Saliency를 이용하는 모듈 하나와 Encoder-Decoder 구조의 네트워크 하나를 가진 것을 볼 수 있습니다.
Modeling Temporal Dependency
먼저 temporal한 정보를 이용하는 모듈을 알아봅시다. 비디오 V에서 비디오의 세그먼트 셋을 S = \{s_1, ... , s_n\}와 같이 정의할 수 있습니다. 그리고 이 세그먼트마다 라벨 y_i이 할당되어 있습니다.
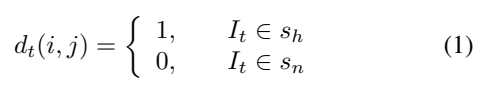
논문에서는 이 정보를 바탕으로 pseudo-distinction label을 먼저 생성해줍니다. [1번 수식]과 같이 pixel-level로 만들어주는데요. 단순하게 세그먼트 라벨이 하이라이트 였을 경우 해당 distinction label을 1로 채우고 아닐 경우는 0으로 채웁니다. (1과 0으로 가득찬 mask를 만들었다고 생각하시면 됩니다.)
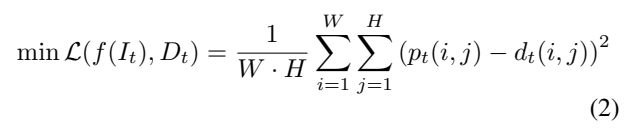
그리고 이 distinction을 추정할 수 있는 함수 f를 정의하고, 그 결과값을 p_t(i,j)라고 해봅시다. 그럼 MSE Loss를 사용하는 [수식 2]와 같이 정의할 수 있습니다. Distinction 추정 함수는 [그림 2]의 encoder-decoder network입니다. 그럼 Temporal한 정보는 어떻게 보느냐에 대해서 설명을 해보자면, 비디오를 C_t = \{I_{t-L+1}, I_{t-L+2}, ... , I_t\}형태의 클립 형태로 분할하고 입력을 클립으로 수정합니다. (백본은 C3D와 같은 것을 사용하면 됩니다.)
Spatial Highlight with Visual Saliency
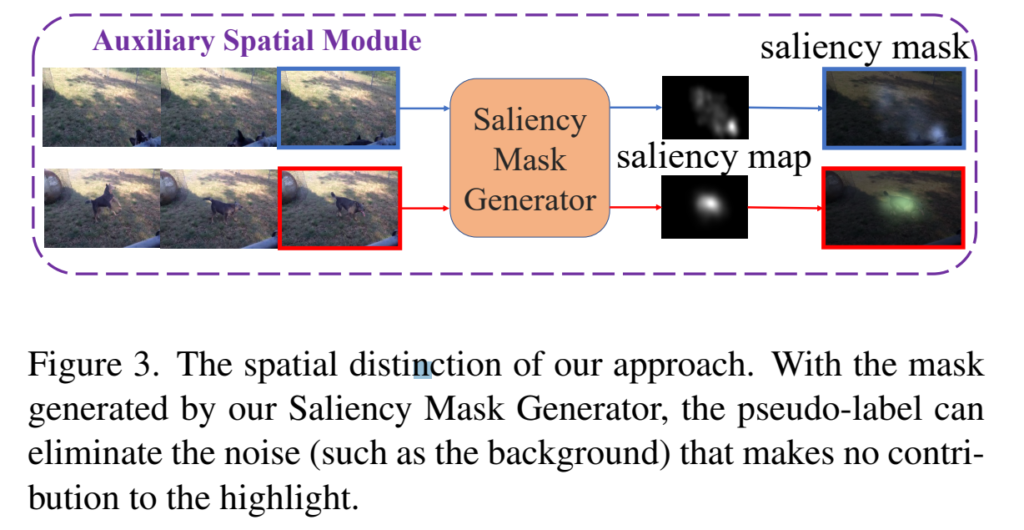
이제 spatial한 정보를 어떻게 살리는지 알아봅시다. [그림 1]의 위쪽 모듈 Auxiliary Sparital Module과 [그림 2]를 함께 보시면 되는데요. 주 목적을 보면 백그라운드로 간주되는 부분들 대신 뭔가 구별되는 물체(?)가 있으면 그 부분을 강조해주는 역할을 수행합니다.
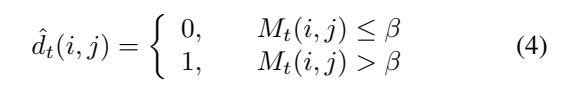
이를 위해서 [수식 1]과 유사한 saliency mask M_t를 가 생성되었을 때, psuedo-label을 생성하는 것을 목적으로 하는 [수식 2]가 위에 있습니다. 그리고 M_t와 특정 하이퍼 파라미터 값인 B에 의해, pixel-level distinctions \hat{d}_t(i,j)가 결정됩니다. 여기까지 읽으시면 어차피 [수식 1]이나 [수식 4]나 목적이 똑같다고 느끼실텐데요.
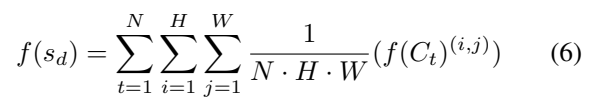
그래서 MSE Loss에서 [수식 6]과 같이 대체해서 표현할 수 있게 됩니다. 사실 이렇게 하면 spatial 정보와 temporal정보를 각각 모듈은 나누어져 있어서 따로 계산하지만, Loss를 한번에 계산하는거라 프레임워크는 한번에 학습을 할 수 있게 됩니다.
Experiments
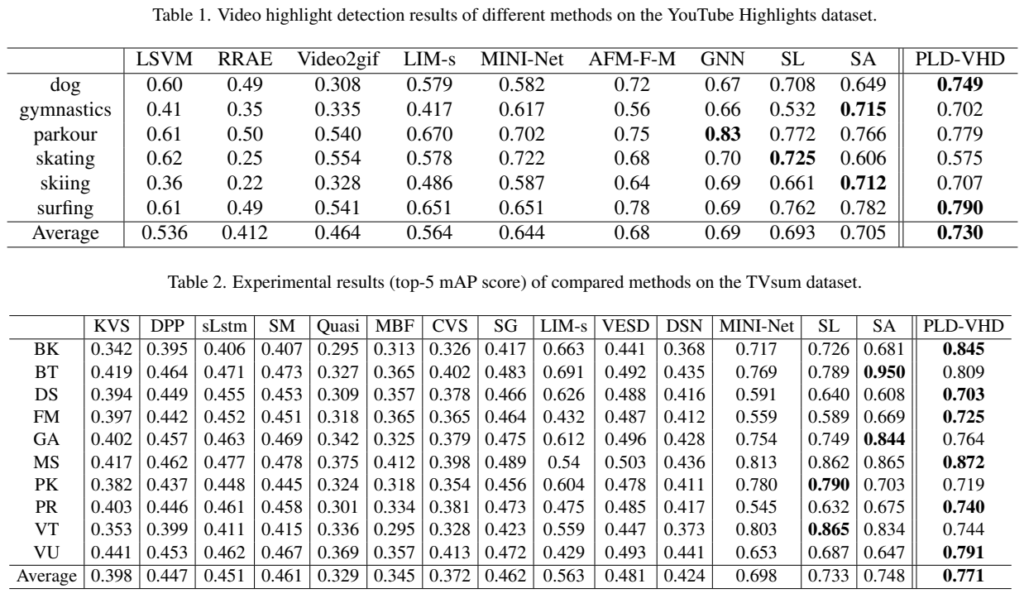
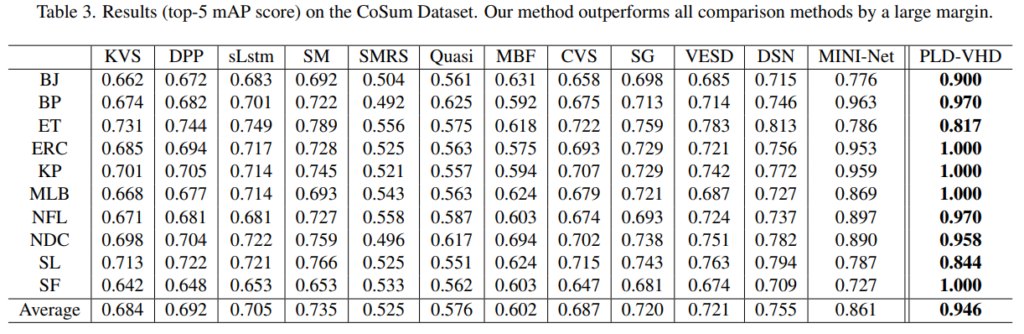
실험 결과를 보게되면 그동안 다루지 않았던 데이터셋으로 CoSum이라는 데이터셋이 추가되었습니다. 저도 처음보기는 하는데 특정 액션을 길게 다루는 데이터셋으로 확인했습니다. 평균 성능이 높긴 하지만, 특정 데이터셋에서는 높은건 한없이 높고 낮은건 한없이 낮은 것을 볼 수 있습니다.

딱히 분석이 없어서 제가 생각을 해봤을 때는, 위와 같이 도심과 같이 복잡한 환경인데 카메라 움직임도 너무 강해서, saliency map 자체가 noisy하게 뽑혀서 성능이 잘 나오지 않은 것으로 생각합니다. 실제로 위의 예시에서 단조로운 배경을 가지는 skiing이나 surfing의 경우에는 꽤 좋은 성능을 보이는 것을 확인할 수 있습니다.
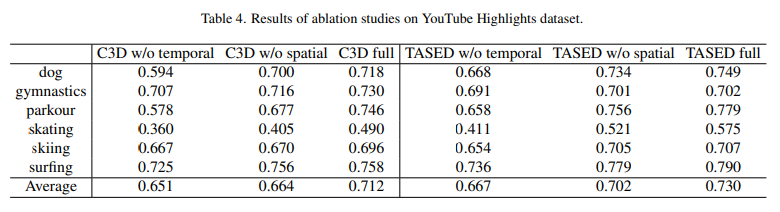
그리고 데이터셋 마다 abalation study가 붙어있어서… 경향성은 똑같으니 하나만 대표적으로 보려고 합니다. Temporal / Spatial 정보를 각각 빼고 실험을 수행했을 때, 모든 경우에서 성능 드랍이 있었습니다. 이를 통해 논문 저자들이 주장하는대로 함께 학습하는 것이 비디오 하이라이트에서 중요함을 확인할 수 있습니다.

[그림 5]는 실제로 모델이 mask를 통해 어떤 부분을 보는지에 대한 예시인데요. 위쪽 예시의 경우에는 조금 모호하긴 하지만 마지막 프레임을 보면 확실히 사람과 개를 보는 것을 확인할 수 있고, 밑의 예시의 경우에는 사람의 움직임에 따라서 마스크가 변하는 것을 볼 수 있습니다.
Conclusion
해당 방법론도 예전부터 해오던 방식이 아니라 다른 task에서 쓰이던 방법론을 결합해서 사용한 건데, 역시 여러 분야를 읽어야… 하겠다는 생각이 들었습니다.
픽셀레벨로 연산을 하며 연산량도 많고 시간도 늘어날 것 같은데 시간에 대한 다른 방법론들과의 비교는 없나요?
또한 해당 task에서 저는 속도보다는 정확도가 더 중요할 것 같다고 생각하는데, 이에 대해 어떻게 생각하시는지도 궁금합니다.
아직 정확도 측면에서도 가야할 길이 먼 연구인데다가. 회사들에서 자체 서비스용으로 알음알음 개발중인 연구분야같아서 비교할 대상이 없어서 비교가 없습니다. 그리고 속도는 당연히 중요한데, 어떤 서비스에 붙이냐에 따라 다를 것 같습니다.
유튜브 하이라이트 데이터셋 실험결과를 보면, 전체적인 에버리지는 쏘타지만, 몇몇개의 클래스에서는 스코어가 꽤 많은 차이로 뒤쳐지는거 같은데, 이런거에 대한 추측되는 이유를 논문 실험파트에서 이야기하지 않나요?
네 저도 왜 없는지에 대한 분석이 있어야할 것 같은데 없더라고요. 근데 아마 제가 해둔 분석이 맞을거라고 추측중입니다. 성능 저하가 날 원인이 그 부분밖에 없습니다.