오늘 제가 리뷰할 논문은 2018년도 CVPR에 게재된 “Weakly Supervised Action Localization by Sparse Temporal Pooling Network”라는 논문입니다.
Temporal Action Localization(TAL)은 action과 background가 공존하는 긴 비디오에서 어떤 action이 어디서부터 어디까지 일어나는지 예측하는 task입니다. 지금까지는 video 분야에서 TAL을 수행하기 위해 fully supervised 방식으로 문제를 해결하는 논문들만 읽어왔는데, 이 때는 ground truth action의 구간 정보와 구간의 class label을 모두 가지고 학습을 진행합니다.
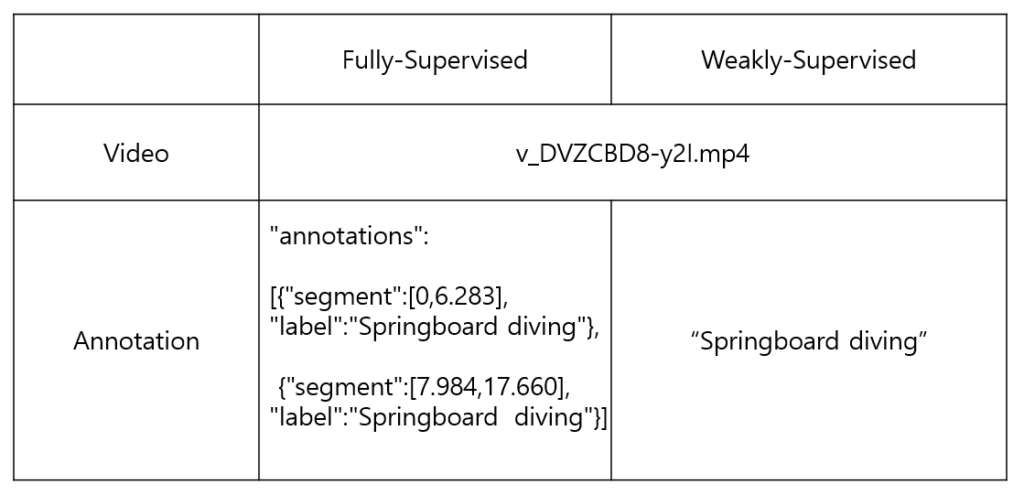
하지만 오늘 소개해드릴 논문은 weakly supervised 기반 방법론으로, video-level label만을 이용해 같은 task를 수행합니다. video-level label은 단순히 그 비디오가 포함하고 있는 action을 의미하는데, 아래 예시 표를 보시면 서로 다른 두 방식을 쉽게 이해하실 수 있으실 겁니다.
본격적으로 논문에 대해 소개해드리겠습니다.
1. Introduction
Introduction은 18년도쯤에 나온 다른 TAL 논문들과 다르지 않았습니다.
- trimmed video에 대한 연구가 활발하지만, 좀 더 실생활에 적용할 수 있는 untrimmed video에 대한 이해와 연구도 필요하다.
- 하드웨어적인 한계에 부딪히기도 하고, video의 temporal 정보를 CNN을 활용해 제대로 modeling 하는 것에 어려움을 겪어 hand-crafted feature를 사용하는 방법론들도 많다.
이를 통해 그 당시의 연구 방향이 어땠는지 알 수 있었는데, 기존과의 차이점이 드러나는 문장도 살펴볼 수 있었습니다.
“큰 cost를 유발하는 fully-supervised 방법론을 기반으로 계속해서 task를 수행하는 것은 미래를 생각했을 때 실용적이지 못하다. 따라서 학습 시 사용하는 temporal annotation을 최소화하여 task를 수행할 수 있는 방법론에 대해 연구하는 것이 훨씬 실용적일 것이다.” 라는 문장이었는데, 그 당시 논문에서 소개한 Weakly-supervised 기반 TAL 방법론(WTAL)은 2가지밖에 존재하지 않았습니다. 따라서 해당 논문은 WTAL의 초창기 방법론이라고 볼 수 있겠습니다.
Contributions
- WTAL 방법론, ‘action은 network가 찾아낸 segment의 sparse subset에서 나타난다’는 점을 잘 파고드는 STPNet 소개
- Action Localization을 위한 Temporal-Class Activation Maps(T-CAMs)와 class-agnostic attentions 활용
2. Proposed Algorithm
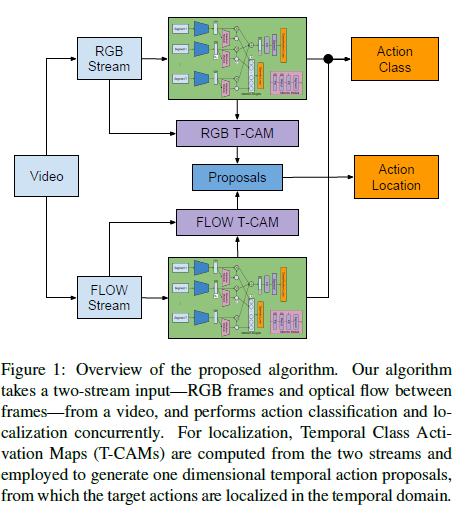
STPNet의 전체 알고리즘은 위 이미지와 같습니다. segment로 분할된 raw video로부터 RGB frame과 Optical flow를 추출한 후, 각각 동일하게 구성된 독립적인 네트워크를 거쳐 classification과 localization을 동시에 수행합니다. 똑같은 구조를 갖는 네트워크 2개를 RGB, Flow에 적용하여 action을 분류하고, RGB와 Flow T-CAM을 추출하여 target action에 대해 시간 축으로 localization을 진행합니다.
2.1 Action Classification
전체 알고리즘 속 네트워크에 대해 자세히 살펴보겠습니다.
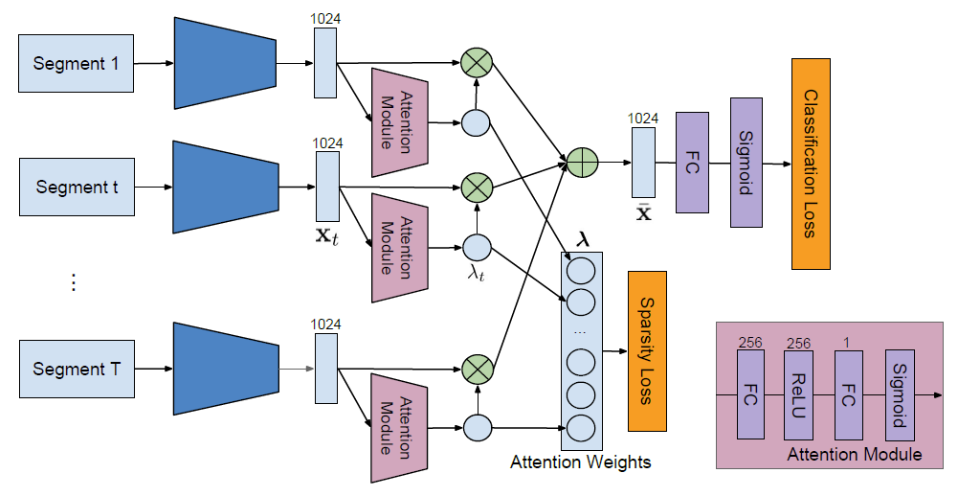
video에서 action을 찾고 분류해내기 위해 논문 저자가 세운 전략은 바로 ‘중요한 action component를 담고 있는 key segment를 구별해내자’입니다. 그런 맥락 속에서, 저자는 모델이 각 segment의 중요도를 판단하여 자동으로 의미 있는 segment들로 이루어진 sparse subset을 선별해내도록 학습하는 방향으로 설계하였다고 합니다. 이렇게 선별해낸 sparse subset of key segments가 video-level label을 예측하게 됩니다.
총 T개의 segment로 분할된 video는 맨 처음 Kinetics pretrained I3D를 거쳐 RGB, Flow stream으로 변환됩니다. 입력으로 각 segment의 RGB 또는 Flow frame을 받고 encoder에 태워 feature x_t를 만들어줍니다.
이렇게 생성된 x_t는 attention module을 거쳐 attention weight \lambda_t를 만들어냅니다.
각 segment에서의 feature x_t와 그로부터 얻은 attention weight \lambda_t를 곱하고 모두 더하여 video-level representation \bar{X}를 얻습니다.
이를 수식으로 나타내면 다음과 같습니다.
\bar{X} = \Sigma{\lambda_tx_t}
t는 1부터 T까지 각각의 segment를 의미합니다.
attention module은 video-level class를 예측하기 위해 앞에서 넘어온 t번째 segment의 feature x_t의 어떤 부분을 집중적으로 봐야하는지에 대한 0~1 사이의 가중치 값을 내도록 학습됩니다. 앞서 저자는 segment 중에서도 video-level action classification을 위해 중요한 segment를 색출해낼 수 있도록 모델을 설계하였다고 하는데, attention module의 output인 attention weight가 바로 이 역할을 해줍니다.
x_t에서 분류를 위해 집중해서 봐야 하는 부분에 1에 가까운 가중치를 곱하고, 영향을 주지 못하는 부분은 0에 가까운 값을 곱해줌으로써 중요한 segment는 더 살려주고, 그렇지 않은 segment는 학습에서의 영향력을 낮춰주는 일종의 feature selection 과정으로 이해할 수 있습니다.
현재는 video의 어떤 부분이 action인지는 모르지만 위의 과정을 거쳐 얻은 video-level representation \bar{X}의 action label은 알고 있기 때문에 CE Loss로 action label에 대해 학습하게 됩니다. attention module는 더욱 sparse한 key segment subset을 생성해내야 하는 attention weight의 목적에 맞게 L1 loss로 학습됩니다.
2.2 Temporal Class Activation Mapping
WTAL에서는 video-level label만 존재하기 때문에 action의 시간 구간에 대해서는 학습할 수 없습니다. 그래서 train과 inference 과정에서는 2.1의 방식으로 action classification을 수행합니다. 여기서부터는 inference 시 어떻게 localization이 수행되는지 정리해보겠습니다.
2.1에서의 과정을 거치면 action class를 알 수 있게 되고, 그 action이 찾아내야 하는 시간 구간의 target action이 됩니다. 이를 위해 저자는 Temporal Class Activation Maps(T-CAMs)를 제안합니다.
T-CAMs에 대해 살펴보기 전, CAM이 무엇인지 보겠습니다.
CAM은 이미지 데이터에서 어떤 부분이 classification 결과에 큰 영향을 주었는지 알아보는 방법입니다.
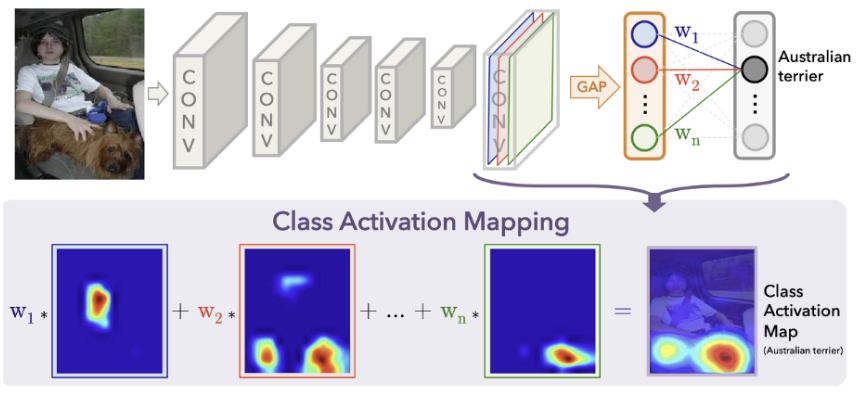
위 사진은 분류 과정 중 가장 주목한 부분을 빨간색, 분석 결과에 영향을 주지 못한 부분을 파란색으로 시각화 한 것입니다. “Austrailian terrier” class를 분류하는 과정 중 이미지 하단 붉은 부분의 영역의 영향을 많이 받았다는 것을 알 수 있습니다.
모델의 forward 과정에서 convolution layer를 거친 output 값들이 마지막에 FC Layer의 파라미터들과 곱해지는데, 잘 학습된 FC Layer의 파라미터들은 분류에 중요한 역할을 하는 부분을 키워주고, 그렇지 않은 부분은 값을 줄이는 역할을 수행합니다. 이러한 특성을 이용해, 학습이 끝난 후 각 convolution layer 층에서 얻을 수 있는 feature map을 가져와 각 클래스 별로 사용한 FC Layer의 파라미터(“Austrailian terrier”와 연결된 파라미터)들을 곱해 후처리 이후 모두 더하면 위와 같이 특정 class를 분류할 때 어떤 부분에 집중했는가를 알 수 있게 됩니다.
이러한 아이디어로부터 저자는 Temporal CAM을 제안한 것입니다. 우리가 localize 해야 하는 target class를 알고 있다면, 그 target class를 맞추는 과정에서 어떤 segment가 큰 역할을 수행했는지 sparse하게 솎아내어 proposal을 만들어 내자는 것입니다. 위 사진에서 예를 들자면 CAM에 빨갛게 나타나는 부분에 bounding box를 치면 target class instance를 찾아낼 수 있듯 시간 축에서 봤을 때 중요한 segment를 잘 처리하여 action의 경계를 만들어내겠다는 것입니다.
어떻게 생각해보면 classification 과정에서 학습된 attention module로부터 attention weight를 뽑아 이용하면 저자의 의도대로 segment 별 중요도를 파악할 수 있지 않나 할 수 있지만, 만약 video-level label이 2개 이상인 경우 attention은 여러 개의 class 중 특정 class에 비중을 둔 weight를 뽑아낸다기보단 그 segment의 class가 무엇인지 모르는 채로 중요한 segment를 weighting 하는 방향으로만 학습되기 때문에 각 class에 특화된 T-CAM을 추가로 생성해줘야 하는 것입니다.
그러면 본격적으로 T-CAMs는 어떻게 만들어내는지 살펴보겠습니다.
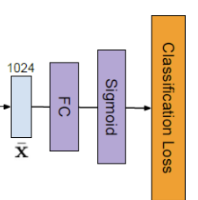
CAM과 마찬가지로 sigmoid에 들어가기 전 마지막 FC Layer의 parameter를 이용합니다. 편의상 해당 FC Layer를 fc3이라고 칭하겠습니다. 클래스 c에 대해 fc3을 거쳐 sigmoid에 들어가는 input을 s^c라고 한다면,
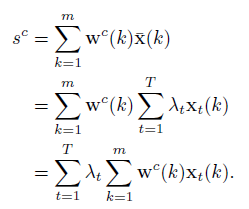
이 때 w^c(k)는 fc3의 k번째 파라미터를 의미하고, \bar{x}(k)는 앞서 segment feature들을 모아 만들어낸 k번째 video-level representation입니다.
class의 전체 개수를 C라 했을 때, t번째 segment에 대한 T-CAM의 원소 a_t는 아래와 같이 표현할 수 있습니다.
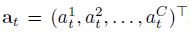
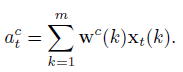
이미지의 CAM에서 convolution layer의 feature map을 fc의 파라미터와 곱해줬다면, 저자는 각 segment의 feature를 fc의 파라미터와 곱해주었습니다.
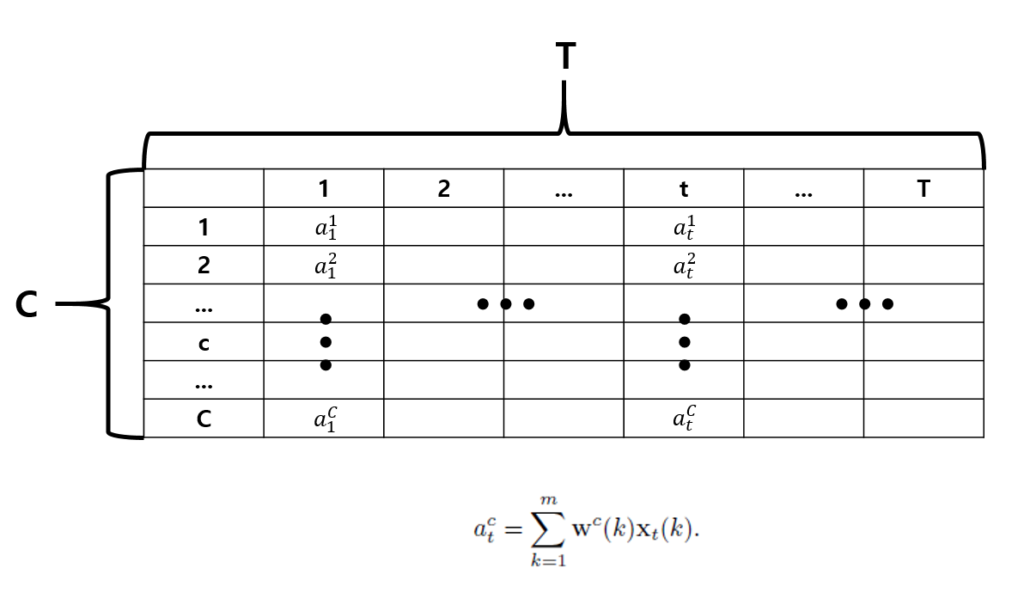
이렇게 하나의 video에 대해서 전체 T개의 segment, C개의 class에 대해 T-CAM을 나타낼 수 있습니다. 이를 통해 t번째 segment가 각 class에 얼마나 relevant한지 알 수 있습니다. 그러면 이렇게 생성한 T-CAM으로부터 어떻게 proposal을 만들어내는지도 확인해보겠습니다.
2.3 Temporal Activation Localization
앞서 얻은 T-CAMs으로부터 여러 정보를 얻어 proposal을 생성합니다. 지금까지의 상황을 정리해보면, inference 시 video가 들어왔을 때 먼저 2.1에서 설명 드린 과정을 거쳐 video의 target action을 설정합니다. 그러면 설정한 target action이 video의 어느 위치에 있는지 찾는 일만 남았는데, 저자는 이를 일차원 시간 구간(1, … , T)에서 각 클래스(1, … , C)에 대해 confidence score가 얼마인지 구하여 proposal을 만들어낸다고 합니다. 사실 상 2.2에서 구한 T-CAM에 일련의 과정을 거쳐주면 됩니다.
하나의 video에 대해 RGB frame과 optical flow 각각의 T-CAM을 생성합니다. 그리고 각각의 T-CAM에 sigmoid를 적용한 뒤 attention weight를 곱해줍니다. a_t는 단순히 fc3의 파라미터와 t일 때의 segment feature를 곱해준 것이므로 segment의 중요도에 따른 attention weight가 곱해지지 않은 상태입니다. 마찬가지로 T-CAM 값에 대한 일종의 feature selection 과정으로 이해할 수 있습니다. (soft selection of the values from the following sigmoid function)

이렇게 얻은 결과는 attention weight를 곱해주어 만들어진 것이므로 weighted T-CAM이라고 하겠습니다. 이후 weighted T-CAM에 thresholding 과정을 거쳐줍니다. 아래 그림처럼 여기서 살아남은 segment들을 proposal로 사용하는 것으로 생각됩니다.
이후 생성된 모든 proposal에 대해 아래의 수식으로 각 class 별 score를 계산하고, score를 기준으로 temporal-NMS를 적용해줍니다.
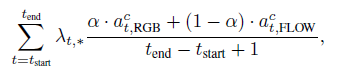
최종 proposal을 그림으로 나타내보면 대략적으로 아래와 같을 것입니다.
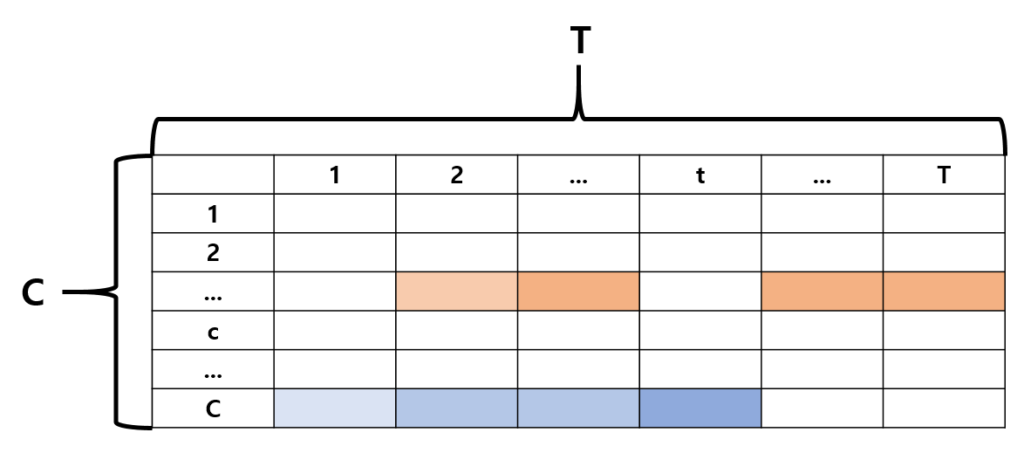
논문에 기타 세부 사항들이 많이 나와 있으니 궁금하신 분은 참고하시면 좋겠습니다.
3. Experiments
다음은 실험 결과입니다.
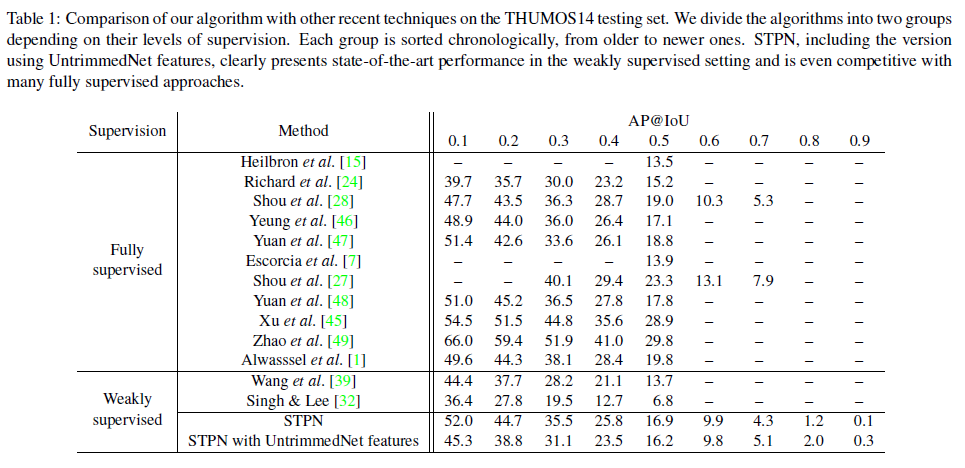
THUMOS 데이터셋에 대한 TAL/WTAL 성능입니다. 보시다시피 그 당시 성능이 측정된 WTAL 방법론은 STPN을 포함해 3가지 밖에 없었습니다. STPN이 기존의 WTAL 방법론들에 비해 큰 성능 향상을 보여준 것은 물론 일부 fully supervised 방법론들 보다도 더 높은 성능을 보인 것을 확인할 수 있습니다. fully supervised 방법론 중 STPN과 성능이 거의 비슷한 [47]은 2016년에 나온 방법론인데, fully와 weakly supervision 사이의 약 2년 정도의 간극이 존재하는 것으로 보입니다. 하지만 STPN을 기점으로 WTAL 연구가 활발히 이루어졌다고 하니, 이후 논문들에서는 fully와 weakly supervision의 성능 차이가 얼마일지도 궁금하네요.
그리고 [39]는 2017년 CVPR에 게재된 UntrimmedNet이라는 방법론인데, T-CAM을 추가로 생성한 것이 아닌 attention만을 이용해 proposal, localization을 진행했다고 합니다. 당연히 각 class 별 score를 뽑아내는 T-CAM 방식보다 성능이 낮을 수 밖에 없었을 것입니다.
정성적 결과입니다.
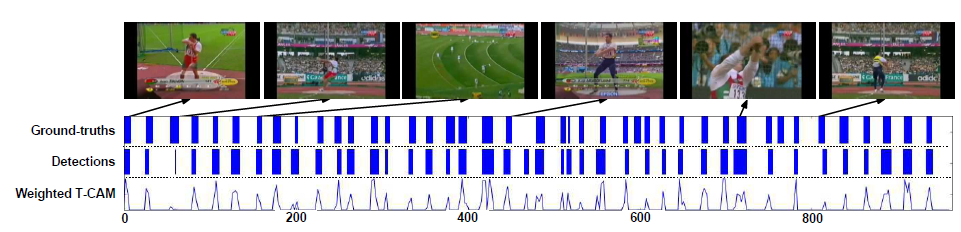
HammerThrow action에 대한 결과라고 합니다. 하나의 video 내 굉장히 많은 action instance가 존재함에도 불구하고 저자는 STPN이 꽤 좋은 예측을 하고 있다고 주장합니다.
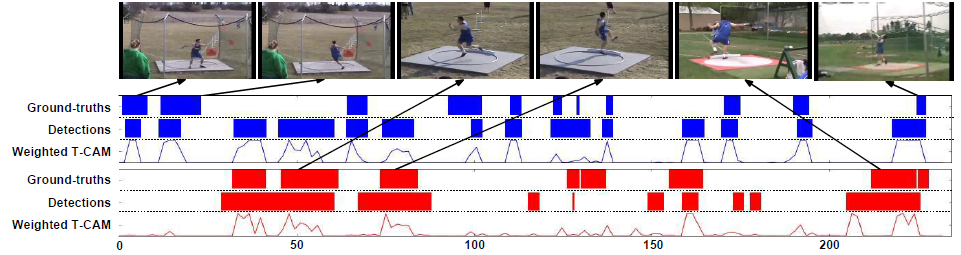
하나의 video 내에 두 가지 action class가 존재하는 예시입니다. 파란색이 ThrowDiscus action이고, 빨간색이 Shotput action입니다. 두 class는 시각적으로 서로 비슷한 action이라는데, 저자는 일부 false positive가 존재하지만 성공적으로 두 class를 잘 구별해냈다고 하네요.
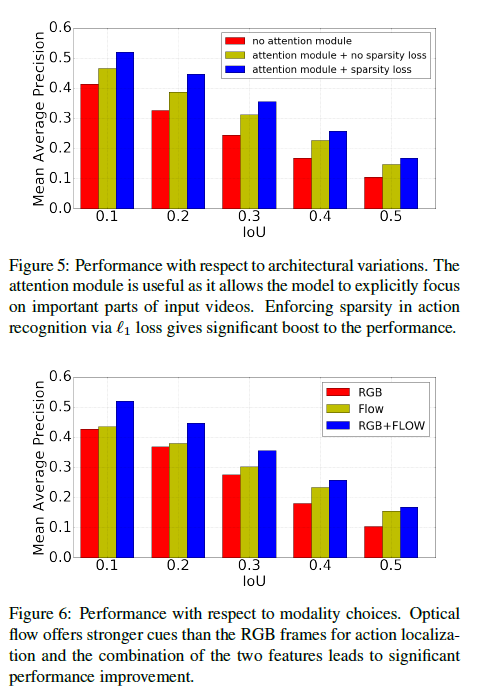
마지막으로 ablation study입니다. Figure 5에서는 attention module과 sparsity loss의 유무에 따른 성능 비교인데, l1 loss를 적용해 sparse한 영역에서 action을 찾을 수 있도록 해준 것이 성능 향상에 도움이 되었다고 합니다. 맨 처음 저자가 주장한 전체 video 중 중요한 segment의 sparse subset을 만들어 action을 찾아야한다는 것이 꽤 큰 성능 차이를 만들었음을 알 수 있습니다. 수치적으로 정확히 얼마가 향상되었는지는 알 수 없었습니다.
Figure 6에서는 다른 논문들과 같이 video로부터 RGB frame과 optical flow를 모두 추출하여 사용하는 것이 가장 좋은 성능을 낸다는 것을 보여줍니다.
처음으로 읽은 WTAL 논문이었습니다. 나온지 오랜 시간이 지난 초기의 방법론임에도 불구하고 처음 접하는 개념이 등장하니 이곳저곳에서 이해하는데 시간이 많이 들었습니다.
temporal annotation 없이 어떻게 localization을 진행하는지 처음에는 감이 전혀 오지 않았어서, 아이디어를 봤을때도 이게 왜 되는건가.. 싶었지만 계속해서 보다보니 굉장히 신기하고 참신하다는 생각이 들었습니다.
저자는 텐서플로우 코드를 공개했지만 파이토치로 구현된 코드도 있어 살펴보았는데, 확실히 코드와 같이 보니 전반적인 흐름을 이해하는데 많은 도움이 되었습니다.
이후에 나온 WTAL 방법론들에 대한 논문들도 시간 순으로 읽어나가며 계속 리뷰 작성하겠습니다. 글 마치겠습니다.