이번 X-Review 역시 Active Learning 에 대해 가져왔습니다. 다크데이터 정례회의를 준비하며 읽어본 논문인데요, 다크데이터 과제에서는 다양한 모델을 지원합니다. Classification, Segmentation, Object Detection, Image Captioning 등이 있습니다. 그 중 Segmentation 에 붙어 다크데이터에서 유의미한 데이터를 찾아 모델을 업데이트할 수 있는 방법에 대하여 알아보가기 위해 해당 논문을 읽어보았습니다.
본 논문은 불확실성 기반의 Active Learning + Semantic Segmentation 에 대해 다룬 논문입니다. 그럼 바로 리뷰해보도록 하겠습니다.
ViewAL: Active Learning With Viewpoint Entropy for Semantic Segmentation
Introduction
기존 Segmentation 기반의 AL에서는 대개 단일 이미지에서만 작동하기 때문에, 새로운 뷰에 대해서 같은 라벨이라고 예측하지 못하는 경우가 있습니다.

그 예시가 아래 이미지와 같은데요, 1행 속 빨간색 바운딩 박스에 있는 물체는 같은 물체입니다. 단순히 다른 View에서 찍힌 것입니다. 그러나 모델은 이 둘을 furniture, 그리고 chair라고 서로 다르게 예측합니다.
저자가 말하길 기존 연구들은 서로 다른 뷰에 대해서 일관된 예측값을 발생시키지 못한다고 합니다.
따라서 본 논문에서는 실세계에 존재하는 기하학적 제약 조건을 고려하여 “새로운 뷰에 대해서도 일관된 불확실성 측정” 을 제안합니다.
즉, AL 태스크를 통해 동일한 object 에 대해 다른 뷰에서 서로 다른 예측값을 내는 영역에 대해 어노테이터에게 라벨링을 요청하는 방식을 제안합니다. 그렇다면 다른 뷰에서 다른 예측값을 내는 것을 어떻게 잡아냈는지는 다음 리뷰에서 설명하겠습니다.
Method
Active Learning이란 태스크는 고정된 라벨링 비용일 때, 모델 성능을 가장 향상시킬 수 있는 데이터를 선별하는 방법에 대해 연구하는 태스크인데요.
Active Learning 방법론의 순서에 따른 제안하는 방법론의 순서는 아래 그림과 설명에서 확인하실 수 있습니다.
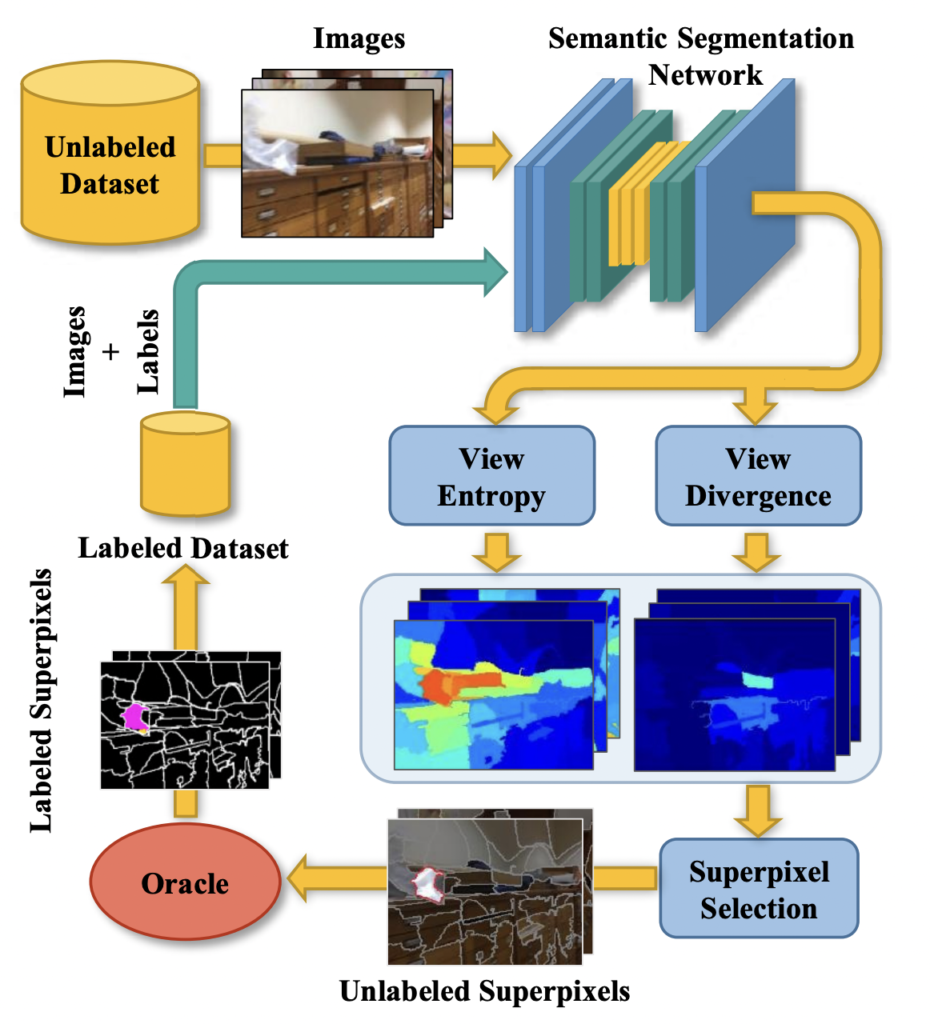
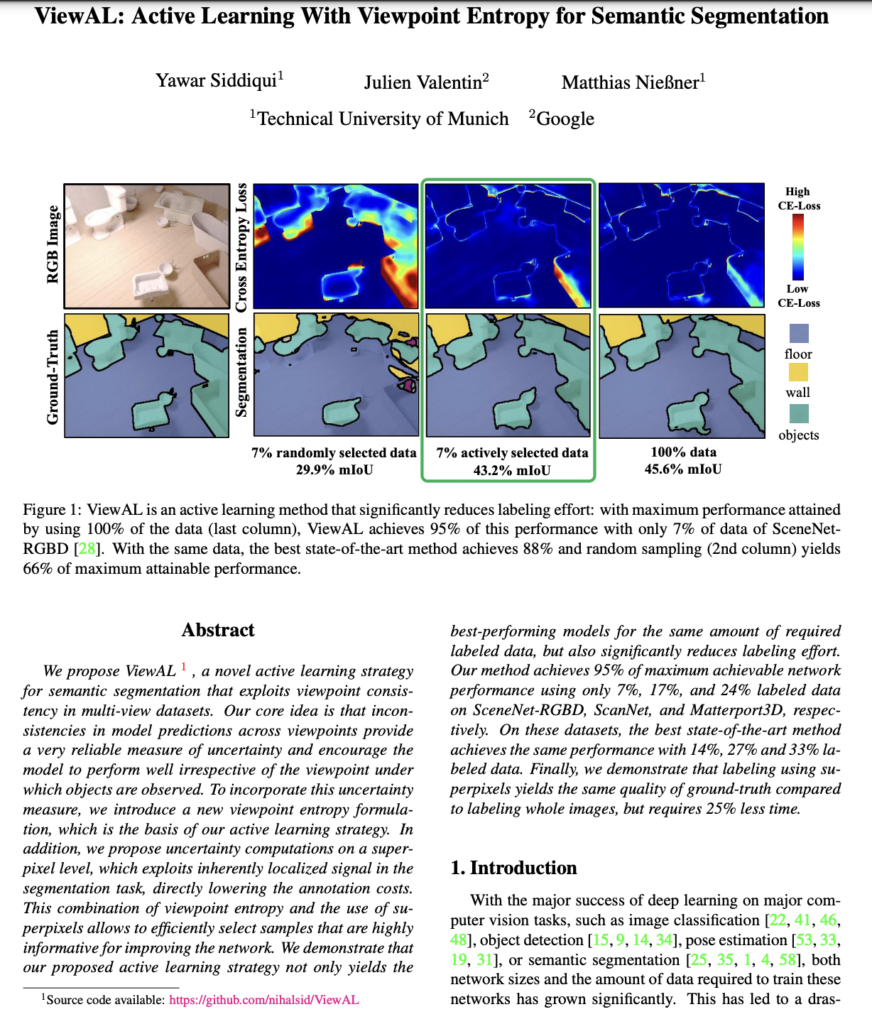
View AL Framework: **(1)** 초기 라벨이 있는 데이터로 모델 학습 **(2)**Unlabeled 데이터에서 Uncertainty 추정 **(3)** Uncertainty 기반으로 레이블링 요청할 Superpixel 선택 **(4)**오라클(어노테이터)로부터 라벨 획득
따라서 주어진 개체에 대한 예측이 뷰마다 다른 것에 정보량이 높다고 판단하여 Uncertainty를 높게 부여하는 것이 본 연구의 핵심입니다.
이를 위해, 본 연구에서는 View Entropy Score와 View Divergence Score를 사용하여 서로 다른 뷰를 고려합니다.
(1) Network Training
기본적으로 해당 연구가 Segmentation 인만큼, 해당 분야에서 가장 많이 활용되는 네트워크를 그대로 가져다 사용하였습니다. Semantic Segmentation 네트워크로 DeepLabv3+ 와 MobileNetv2를 선택하였다고 합니다. DeepLabv3+는 당시 SOTA 였고, MobileNetv2와 조합하니 빠른 학습 및 적은 메모리 소비가 가능했기 때문이라고 서술하였습니다. 그리고 사전학습된 모델을 사용하였다고 하네요.
해당 네트워크에 대해서는 본 리뷰에서는 다루지 않겠습니다. AL에 어떻게 적용했는지가 해당 연구의 핵심이니까요.
(2) Uncertainty Scoring
저자는 동일한 객체가 다른 예측값을 내는 영역에 높은 Uncertainty를 부여하여, 어노테이터에게 새로운 라벨링을 요청하기 위한 Scoring 방식을 제안합니다. 즉, 저자는 새로운 뷰에서도 일관된 예측을 위한 뷰 기반의 Uncertainty 를 제안하였습니다.
그렇다면 그것은 어떻게 제안하였을까요? 바로 View Entropy 와 View Divergence 를 고려하여서 Uncertainty를 설계하였습니다. View Entropy 를 통해 특정 객체가 뷰마다 지속적으로 동일하게 예측되는 지를 판단하고자 하였고, View Divergence를 통해서는 다른 뷰에서 보인 특정 3D 지점에 대한 예측이 현재 이미지의 예측과 어떻게 다른지를 확인하고자 하였습니다.
(2)-1. View Entropy Score
View Entropy를 추정하기 위해서는 이미지 별로 앞서 설정한 세그멘테이션 네트워크에 태워서 픽셀 단위의 클래스 맵을 구합니다.
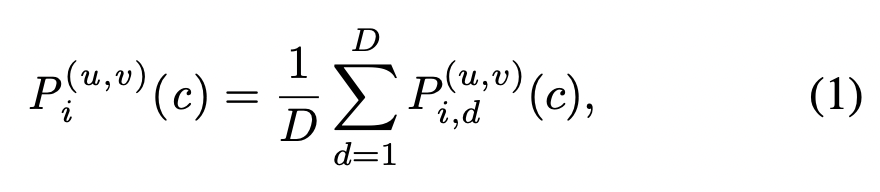
그리고 다음으로, pose와 depth 정보를 사용하여 데이터셋의 모든 픽셀과 관려된 확률 분포를 3D로 back-projceted 됩니다.
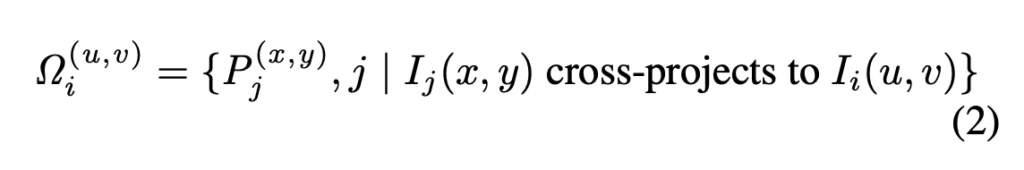
mean cross-projected 분포 Q는 아래와 같이 계산을 하게 되며, 마치 예측확률을 viewpoints 관점에서 marginalizing 하는 것처럼 볼 수 있다고도 합니다.
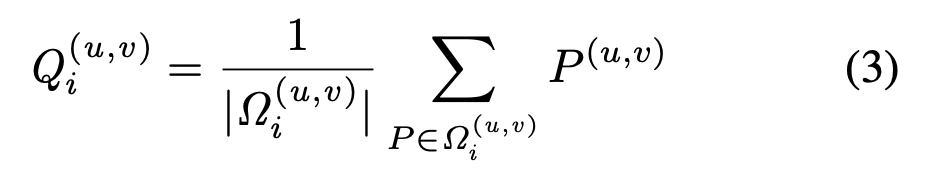
따라서 이것을 이미지에 대한 뷰 엔트로피 스코어를 계산한 식이 바로 아래와 같습니다. (쉽게 말해 3D 지점에서의 확률값에 대하여 엔트로피 스코어를 구한 것이라고 이해하시면 좋을 것 같습니다)
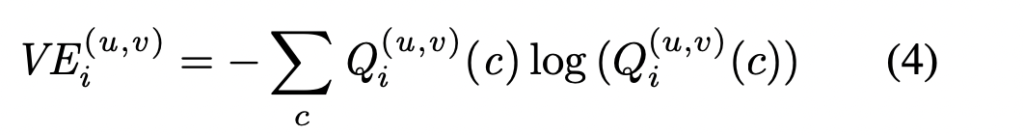
(2)-2. View Divergence Score
앞서 구한 View Entropy는 각 픽셀별로 예측이 여러 view 에 얼마나 일관성이 없는지를 나타내게 됩니다. 그러나 모델을 개선하기 위해서는 어떤 View가 가장 많은 양의 정보를 포합하고 있는지는 알 수 없습니다.
따라서 각 픽셀에 대한 View Divergence Score를 계산하여 모델이 예측한 값과 실제 정답값이 얼마나 다른지를 구하게 됩니다. 즉, 어떻게 다른지를 스코어로 구하게 되는 것이죠. VD score는 아래와 같이 계산되었습니다. 아래 수식에서 KL은 Distrbution P_i 와 P_j 사이의 KL Divergence를 의미합니다. 값이 높을수록 서로 비슷하다는 것을 의미합니다.
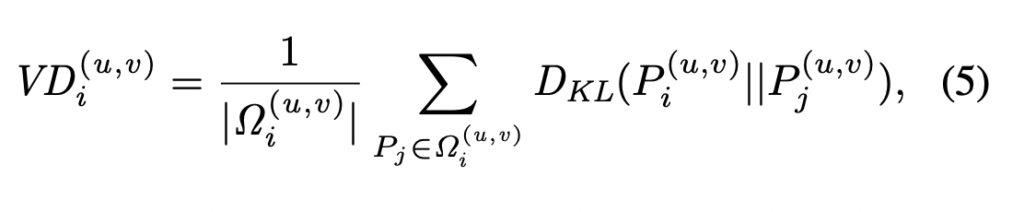
아래 그림은 View Entropy 와 View Divergence Score를 시각화한 것입니다. 모든 score-map에서 파란값은 낮은 값을, 빨간값은 높은 값을 나타냅니다. 그리고 대응하는 픽셀은 동일한 View Entropy score를 가지게됩니다. 이후 View Divergence를 사용하여 가장 반대되는 뷰를 정의하고 어노테이터에게 라벨링을 요청하는 방식이죠.

Region Selection
본 논문에서는 전체 이미지 단위가 아닌 영역 단위로 라벨링을 요청해야한다고 주장합니다. 특히, superpixel을 사용하는 것이 라벨링을 하는 어노테이터 관점에서 효율적이라고 주장하며 이를 사용합니다. superpixel을 구하기 위해 SEEDS 알고리즘을 사용하였다고합니다. superpixel은 이미지의 에지를 기준으로 특정한 영역별로 분할한 픽셀이라고 생각하시면 좋을 것 같습니다. (포토샵에 익숙하신 분들이라면 올가미툴을 사용했을 때의 픽셀이라고나 할까요 ..?) 아래 이미지가 그 예시입니다.

따라서 앞서 불확실성 스코어는 해당 슈퍼픽셀 기반으로 계산되며, 라벨링을 하도록 요청하게됩니다,.
Result
SceneNet-RGBD, ScanNet, Matterport3D이라는 데이터셋을 사용하였습니다. 앞서 뎁스 정보와 포즈 정보를 사용한다고 하였기 때문에, 해당 데이터는 모두 RGBD 로 구성되어있습니다. 그리고 비교실험은 기존 9가지 방법론들과 진행합니다.
아래 추세선 그래프에서 x축은 라벨링된 데이터의 비율을 나타냅니다. 라벨링 데이터가 추가함에따라 성능이 향상되는 것은 대부분인데요. 저자가 제안하는 ViewAL은 모든 데이터셋에서 랜덤샘플링과 다른 방법론들에 비해 우수한 성능을 가집니다. 게다가 ScanNET에서는 라벨링 데이터 17%로 27.7%의 mIoU를 얻었습니다. 또한 전체 데이터셋을 사용하여 학습한 것에 95% 가량의 성능입니다. 이 외에도
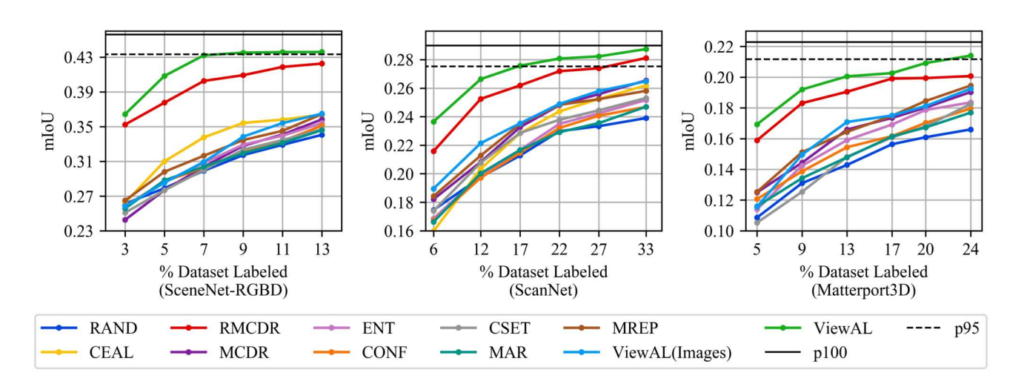
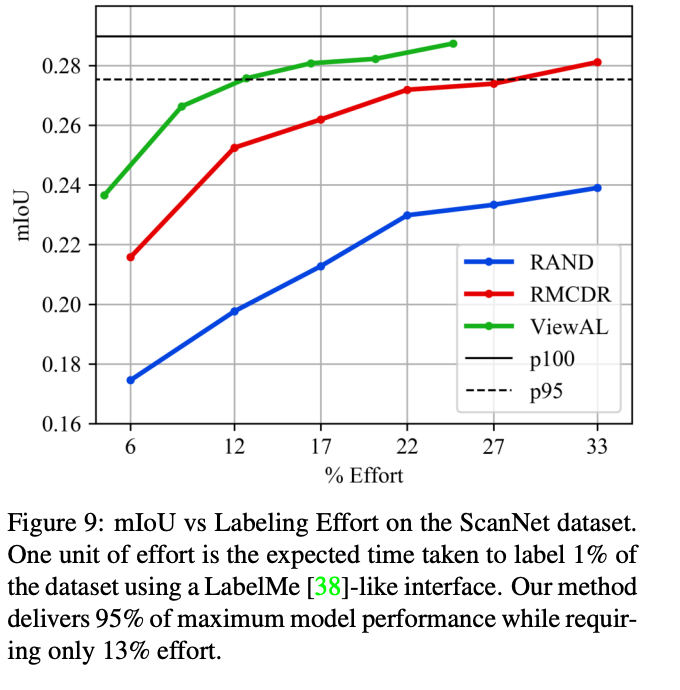
이 외에도 라벨미와 같은 동일한 인터페이스를 사용하여 라벨링을 요청했을 때의 소요 시간을 계산한 결과는 아래 그래프로 ㄹ데이터셋의 1%를 레이블링하는데 필요한 시간을 나타냅니다. 제안하는 방법이 최대 모델 성능의 95%를 달성하는 동시에 13%의 cost만 필요하였습니다.
Conclusion
제안하는 방법론의 contribution을 정리하면 다음과 같습니다.
- ????????? ??????? 라는 서로 다른 뷰 사이의 불일치를 기반으로 ??????????? 계산
- 기준으로 예측 확률에 대한 KL divergence 기반의 가장 정보량이 많은 ???? 기준
- 품질을 유지하면서 레이블링 작업을 줄이는 superpixel 기반의 스코어링 및 레이블링
다만 일반 데이터셋에는 적용하기 어렵고, superpixel이라는 upper가 정해져있다는 단점이 명확한 논문이었습니다. 그래도 AL에 Segmentation을 적용하였다는 것으로 CVPR… 새로운 차별점만 찾는다면…..! 이라는 새로운 관점을 얻은 것 같습니다.
다만 저희 다크데이터의 방향성이 바뀌며 해당 연구의 방법론을 사용하는 것이 다소 어려워졌다는 아쉬움이 조금 남네요. 이상 리뷰 마치겠습니다.
리뷰 감사합니다. 몇가지 질문 드리도록 하겠습니다.
1. Unlabeled data 상황인데 동일한 객체라는 것은 어떻게 찾을 수 있나요? 정확히 동일한 객체를 다룰 때 Unlabel + Unlabel 끼리 비교하는 것인지, Unlabel + label 이렇게 비교하는 것인지 궁금합니다.
2. View Entropy Score에서 갑자기 depth와 pose가 등장하였는데 이는 annotation으로 제공되는 것인가요?