Before Review
이번 리뷰는 조원 연구원이 이전에 작성한적이 있지만, 저도 자세한 이해를 해보고 싶어 읽게된 논문입니다.
Video Representation Learning 논문을 읽은 이유는 지금 관심있는 연구분야인 Weakly-Supervised Temporal Localization에서 Class Activation Sequence를 잘 Embedding 하기 위해서는 Self-Supervised 기반의 표현력이 좋은 Feature Representation을 얻어야 합니다.
Video Rerpesentation Learning은 많은 논문들이 나와있지만 Untrimmed Video를 target으로 한 논문은 많지 않습니다. 하지만 본 논문은 Untrimmed Video를 대상으로 제가 고민하고 있는 부분과 비슷한 관점으로 연구를 하여 이번에 리뷰를 하게 되었습니다.
리뷰 시작하도록 하겠습니다.
Preliminaries
Contrastive Learning에 대해서 간략하게 알아보고 본 리뷰 시작하도록 하겠습니다.
Contrastive Learning
간단하게 얘기하면 Instance 기반의 Representation을 얻는 방법이라 보면 됩니다.
예를 들면 강아지 사진이 하나 있다고 가정을 하면 강아지 사진에 두가지 Random Crop을 가해줘도 이는 같은 강아지 사진으로부터 나온것이기 때문에 Feature Representation이 같아야 합니다. 즉, Positive Sample이라는 것이죠.
Unlabeled 상황에서는 어떤 사진이 어떤 Category인지 모르기 때문에 그냥 모든 data를 하나의 Instance라 가정합니다. 그리고 같은 data로부터 변형되어 나온 sample들은 Positive sample로 둘의 feature representation이 같아지게 만들어줍니다. 또한 서로 다른 data들은 negative sample로 둘의 feature representation이 멀어지는 방식으로 학습을 진행합니다.
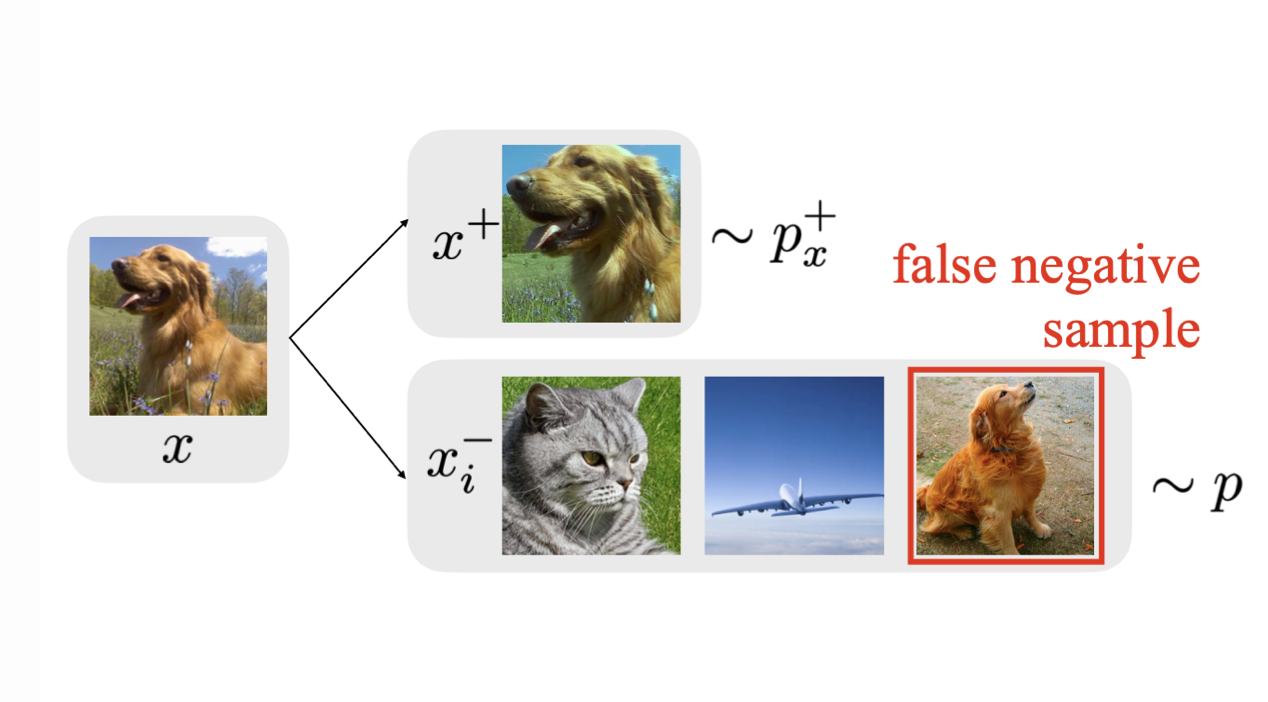
결국 Pretext 기반으로 하든, Contrastive Learning 기반으로 하든 데이터 자체에 대한 이해를 높이기 위한 방법론이라 생각하면 됩니다.
SimCLR
Google Research가 발표한 Contrastive Learning 기반의 framework인 SimCLR에 대해서 간단하게 알아보도록 하겠습니다. SimCLR는 동일한 data로부터 data augmentation을 거친 두 sample은 Positive Pair라 가정하고 다른 data로부터 data augmentation을 거친 두 sample은 Negative Pair로 가정을 하고 Batch 단위로 Sampling을 하고 NT-Xent Loss를 통해 Feature Representation Learning을 수행합니다. 아래의 그림을 보면 어느정도 감이 올 수 있습니다.
제가 얘기하고 싶은 부분은 SimCLR의 framework보다는 NT-Xent Loss를 설명하려고 합니다. 우선 Loss formulation 먼저 보도록 하겠습니다.
- l(i,j)=-log\frac{exp(s_{i,j}/\tau )}{\sum\nolimits^{2N}_{n=1_{n!=i}} exp\left( s_{i,n}/\tau \right)}
우리의 목적 자체는 Positive Pair 끼리의 Feature Representation은 가까워지고, Negative Pair 끼리의 Feature Representation은 멀어지는 것이었습니다. 그렇다면 저 Loss를 최적화 시키는 방향이 우리의 목적과 맞는지 확인을 해봐야겠죠.
수식으로만 보면 조금 어려운 감이 있어 잘 정리한 블로그로부터 사진을 가져왔습니다.
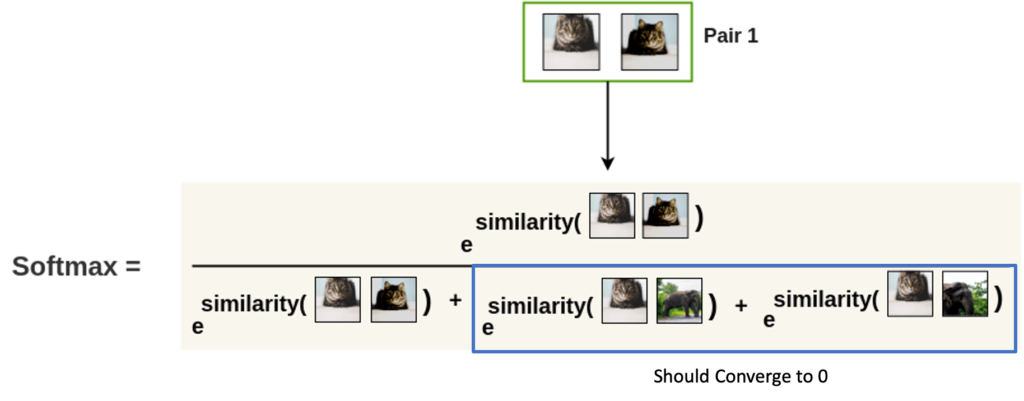
우리의 NT-Xent Loss는 결국 -log(softmax)의 형태를 가지고 있습니다.
결국 저 softmax value가 1에 가까워져야 Loss는 작아지고 모델이 최적화된다고 볼 수 있습니다.
그렇다면 softmax value가 1에 가까워진다는 것은 먼저 Negative Sample에 대한 유사도 항이 0에 수렴을 해야 Loss가 작아집니다. 혹은 Positive Sample에 대한 유사도항이 다른 항에 비해 매우 큰 유사도 값을 가지면 역시 Loss가 작아집니다.
딱 우리의 상황과 동일합니다. NT-Xent Loss의 의미에 대해서 간단하게 설명을 드렸고 이제 본 논문 리뷰에 들어가도록 하겠습니다.
Introduction
Unsupervised 기반의 Video Representation Learning은 요즘 많은 관심을 받고 있는 연구 분야 입니다. 대용량의 Unlabeld Video Data로부터 의미있는 Feature의 Representation을 학습할 수 있다면 다양한 Down Stream Task에 더욱 좋은 성능을 낼 수 있다는 장점이 있기에 많은 주목을 받고 있습니다.
Video 분야에서의 Representation은 같은 Video에서 나온 Clip들은 Positive Sample로써 representation이 가까워지도록 학습을 하고, 다른 Video에서 나온 Clip들은 Negative Sample로써 representation이 멀어지도록 학습이 진행됩니다.
하지만 여기서 한 가지 가정이 필요한데, 그것은 바로 Video Data가 Trimmed Video라는 가정이 필요하다는 것 입니다. 자 그럼 Trimmed Video가 무엇인지 모를 수 있으니 간략하게 설명하자면 비교적 길이가 길지 않고, 하나의 컨텐츠만을 담고 있는 짧은 영상이라 생각하면 됩니다.
그런데 우리가 일상생활속 접하게 되는 비디오들은 대부분 Untrimmed Video의 형태라 볼 수 있습니다. 즉, 여러개의 컨텐츠를 담고 있고 일반적으로 길이가 긴 상황이죠.
자 Trimmed Video라면 하나의 컨텐츠만을 담고 있기 때문에 영상 전반적인 Visual Consistency가 상당히 유사합니다. 비디오속 어느 클립을 따도 다 비슷하게 생겼다는 말입니다.
그런데 Untrimmed Video라면 여러개의 컨텐츠를 담고 있기 때문에 영상 전체가 Visual적으로 유사하지 않을 수 있습니다. 아래의 그림을 한번 보도록 하겠습니다.

자 스모 레슬링에 대한 비디오입니다. 초반부에는 스모 선수가 인터뷰를 하고 있고 영상 중반부에는 스모 경기가 이루어지고 있습니다. 마지막에는 경기장속 관중들이 나타나고 있습니다.
중간에 스모를 경기하는 부분은 Visual Consistency가 높다고 볼 수 있습니다. 하지만 다른 부분들과 Visual Consistency가 높다고는 얘기할 수 없습니다. Visual Consistency를 가지고 Representation Learning을 하는 것은 이전 연구에서도 많이 다뤄진 부분들입니다.
하지만 Untrimmed Video는 다양한 컨텐츠를 포함하고 있기 때문에 Visual Consistency만 고려해서는 부족할 수 있습니다. 따라서 본 논문에서는 Topical Consistency를 제안합니다. 결국 스모 선수를 인터뷰하고 있는 부분과 스모 경기를 하고 있는 부분과 스모 경기장에서 관중들이 나와있는 모습은 모두 스모라는 주제와 연관이 되어 있습니다.
따라서 본 논문에서는 처음으로 Untrimmed Video에 대해서 Representation Learning을 할 때 고려되지 않았던 Topical Consistency 다루는 framework를 제안합니다. 여기서 핵심은 Contrastive Learning 입니다.
무튼 본 논문의 컨셉에 대해서 알아보았고 이제 방법론에 대해서 알아보도록 하겠습니다.
Method
Consistency Learning

학습의 전반적인 방향은 Contrastive Learning이 담당하게 됩니다. 그리고 본 논문에서 Contrastive Learning을 할때 사용하는 Framework는 SimCLR의 방식을 사용한다고 합니다.
N개의 비디오로부터 3개의 sample을 추출합니다.
v_{i},v_{j} : 같은 비디오 내에서 Temporal Distance가 일정 Threshold 미만인 클립들을 의미합니다. 여기서 본 논문의 가정이 들어갑니다. Temporal Distance가 짧다면 Visual Consistency가 일반적으로 높을 것이다 라는 가정입니다.
\mid c_{i}-c_{j}\mid <\delta_{max} 여기서 c_{i}와 c_{j}는 클립의 central frame의 시간대(time stamp)을 의미합니다.
v_{k} : 같은 비디오 내에서 Temporal Distance가 일정 Threshold 이상인 클립들을 의미합니다. 여기서 본 논문의 가정이 들어갑니다. Temporal Distance가 길면 Visual Consistency를 보장할 수 없고 때문에 Topcial Consistency만을 가지게 된다라는 것이죠.
우선 Positive Sample은 단 두 개 밖에 없습니다. 같은 비디오내에서 추출되었고, Temporal Distance가 짧은 클립인 v_{i},v_{j} 뿐 입니다. 나머지는 다 Negative Sample인 셈이죠.
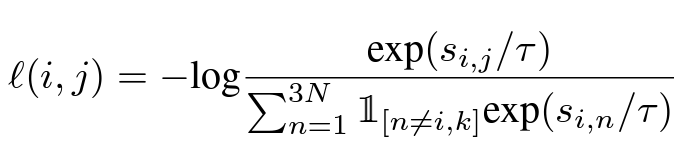
그래서 우리의 Loss항은 저렇게 설계가 됩니다. N개의 비디오에서 3개의 clip을 sampling 했으니 3N개의 Clip이 분모항에 들어가게 됩니다. 3개인 이유는 v_{i},v_{j}(visual consistency) 그리고 v_{k}(topical consistency) 이기 때문이죠.
그리고 Topical Consistency를 이용한 Classification Task를 하나 정의할 수 있습니다. 자 3N개의 Clip으로부터 Feature를 임베딩 시킬 수 있겠죠.
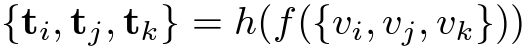
그래서 3N개의 Feature를 얻을 수 있습니다. 그리고 다음과 같이 Feature set을 얻을 수 있습니다.
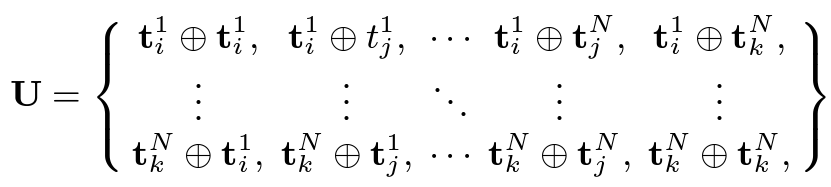
이 feature set은 그냥 3N개의 embedding feature들을 모두 하나씩 pair를 만들어 concat 시켰다고 보면됩니다.
그렇다면 저 U\in R^{3N\times 3N\times 2T_{C}}를 가지고 무엇을 하냐면 일단 Classifier를 통과시킵니다. T_{C}는 원래 임베딩 차원이라 했을 때 두 pair를 가지고 concat을 했기 때문에 2T_{C}의 차원을 가진다고 보면 됩니다.
그리고 임베딩 축에 대해서만 Classifier를 통과시키면 M=\phi (U)\in R^{3N\times 3N}와 같은 confidence map을 얻을 수 있습니다.
그리고 두 임베딩 feature가 같은 비디오로부터 왔다면 topical consistency 관계에 있기 때문에 1(True) 다른 비디오로 부터 왔다면 topical consistency 관계가 없기 때문에 0(False) 이렇게 Label을 할당해서 Binary Classification을 수행할 수 있습니다. 그런데 여기서 일반적으로 Batch Size(N)이 크다면 True 케이스보다는 False 케이스가 훨씬 많기 때문에 Class Imbalance에 효과적인 Focal Loss를 사용했다고 합니다.
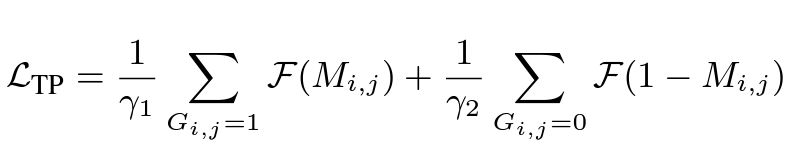
그래서 최종 Loss는 L = L_{CL} + L_{TP} 이렇게 정리할 수 있겠네요.
Gradual Sampling
Visual Consistecny를 가지기 위해 샘플링 되는 두 Clip의 Temporal Distance에는 Threshold가 존재했습니다.
- \mid c_{i}-c_{j}\mid <\delta_{max}
근데 저 Threshold를 그냥 고정된 상수로 하는 것보다 training epoch \alpha에 따라 변하는 값으로 조절하는 것이 더 효과적이라고 합니다. 사실 이에 대한 이론적인 증명도 Appendix에 나와있지만 다루지는 않겠습니다. (사실 어려워서 못 읽겠더라구요…)
- \delta_{max}(\alpha ) = \frac{\alpha }{\alpha _{max}}\Delta
자 일단 \alpha _{max}는 학습 최대 epoch 입니다. 그렇다면 결국 \frac{\alpha }{\alpha _{max}} 값은 ][0,1] 사이의 값을 가지게 됩니다. 그렇기 때문에 \alpha _{max}(\alpha)의 값은 [0,\Delta ] 사이의 값을 가지게 됩니다.
여기서 \Delta는 Temporal Distance의 Upper bound로 고정된 상수 입니다.
핵심은 초반에는 Distance를 짧게 가져가서 확실히 Visual Consistency를 보장할 수 있도록 하다가, 점점 거리를 늘려서 다양한 representation을 얻을 수 있게끔 설계했다고 보면 됩니다. 이론적으로 궁금하신분은 논문을 직접 찾아보시면 될 것 같고, 저는 실험을 통해서만 이 방법론의 효과에 대해 얘기하겠습니다.
Experiments
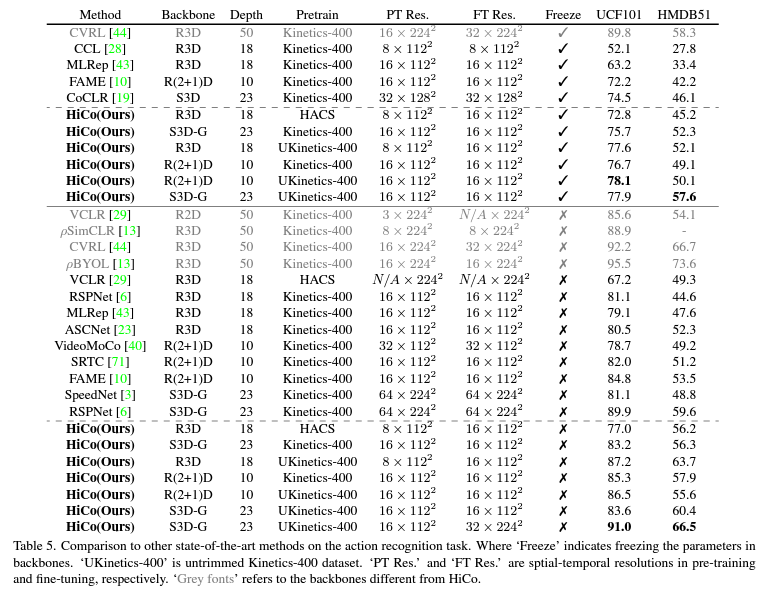
일단 PT는 Pretraining을 한 dataset을 의미하고 FT는 Fully fine tuning , LFT는 Linear fine tuning을 의미합니다. Linear fine tuning이 무엇지는 잘 모르겠네요.
우선 Action Recognition에서의 벤치마크입니다. 대체로 본 논문에서 제안된 방법론인 HiCo가 좋은 성능을 보여주고 있지만 CVRL이라는 방법론보다는 조금 낮은 성능을 보여주고 있습니다. CVRL이 더 높은 해상도와 깊은 네트워크를 사용해서 성능이 높은것이라고 하네요.
핵심은 Pretrain을 Trimmed set인 Kinetics가 아니라 Untrimmed Kinetics로 하였을 때 빛을 발휘한다는 점 입니다.
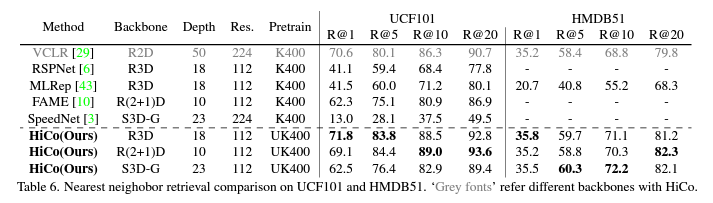
다음은 Video Retrieval에서의 성능입니다. 랭킹 스코어는 단순히 코사인 유사도를 사용했다고 합니다. UCF101이나 HMDB51같은 소규모의 데이터셋이 아닌 좀 더 대용량의 데이터셋을 가지고 벤치마킹을 해줬으면 좋았을텐데 조금 아쉬움이 남네요. 아무튼 Retrieval에서도 좋은 성능을 보여준다는 것은 그만큼 Feature representation이 구별력이 생겼다고 볼 수 있겠네요.
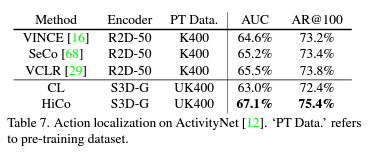
마지막으로 제가 관심있는 Action Localization에서의 성능입니다. 확실히 ActivityNet 과 같은 복잡한 Untrimmed Video를 이해하는 데 효과적으로 작동하는 것 같습니다.
Conclusion
이번 논문을 읽으면서 사실 본 논문에서 제안된 방법론은 가정이 너무 강하게 깔려 있는 것 같다는 생각이 들긴 했습니다.
바로 (1) Short Temporal Distance -> Visual Similarity (2) Long Temporal Distance -> Topical Similarity 라는 점 입니다.
사실 얼핏 보면 맞는 것도 같지만 대용량 Untrimmed Video에서는 동영상 속 내에서 콘텐츠의 Variance가 너무 크기 때문에 저 가정을 뒷받침하기가 사실 힘들어 보입니다. Visual과 Topcial을 단순히 Temporal Distance가 아닌 다른 장치로 필터링할 수 있다면 더 좋은 성능을 낼 수 있지 않을까라는 생각이 드네요.
물론 이번이 처음으로 Topical Consistency가 고려된 연구이기 때문에 이렇게 간단하게 고려를 한 것 같고 앞으로 더 발전의 여지가 충분히 남아있는 것 같습니다. 코드는 공개했다고 하면서 아직 공개가 안되어있네요. 나중에 공개되면 Contrastive Learning이 어떻게 구현되어있는지 봐야겠습니다.
이상으로 리뷰 마치도록 하겠습니다.