오늘은 video summarization 논문입니다. 비디오 요약에서 공개된 코드들이 많이 없어서, 뭘 바탕으로 실험을 해볼까 고르고 고르다가… 이 논문은 누군가가 구현해둔 코드도 있고, 마침 이전에 읽었던 비지도학습 기반의 비디오 요약 논문 “Video Summarization by Learning from Unpaired Data”의 바탕이 되는 논문이라 이 논문을 가져왔습니다.
Introduction
이 논문 저자들은 이 비디오 요약이 많은 비디오 분석 task에 적용될 수 있다고 생각했습니다. 예시로는 action recognition에서 짧은 비디오를 빠르게 분석할 수 있도록 도울 수 있다고 하네요. (제가 지금 실험해보는 것도 이와 비슷한 맥락입니다. 비디오의 키프레임을 이런 흐름을 통해 뽑는거죠.)
또, 중요한 아이디어로 이 비디오 요약에 semantic segmentation 방법론을 가져와서 적용했다는 것입니다. 논문 저자들이 판단했을 때 입력 형태와 출력 형태가 다를 뿐이지, 같은 방법론으로 해결할 수 있다고 생각했다고 합니다. 그래서 이 논문에서는 semantic segmentation에서 사용하는 FCN과 같은 방법론을 가져와서 FCSN이라는 이름으로 바꾸어 비디오 요약에서 사용합니다.
그래서 4가지의 contribution을 가집니다.
- 비디오 요약에 최초로 fully convolutional 모델을 제안함.
- 전혀 관계가 없어보이는 semantic segmentation과 video summarization 사이의 참신한 연결 고리를 만듬.
- 지도 학습 및 비지도 학습 기반의 fully convolutional models 제안
- SOTA
결국은 FCN과 관련된 내용이 결국은 이 논문의 핵심인데… 어떻게 사용했는지 보겠습니다.
Our Approach
이 논문에서는 keyframe / non-keyframe 형태의 binary 형태로 라벨링된 값을 바탕으로 비디오 요약을 학습하는 것에 집중합니다. 특정 프레임이 주어지면, 이 프레임이 키프레임인지 아닌지 구분하려는 것이죠. (비디오 요약에서 프레임이 키프레임인지 알게되면, 해당 프레임이 존재하는 세그먼트를 요약할 세그먼트로 지정하기 때문에 이런 방식이 가능합니다.)
Fully Convolutional Sequence Networks
Semantic segmentation에서 문제를 해결하는 방법들 중 하나에 encode-decoder 구조가 있습니다. 이 논문도 이 방법론을 가져와서 문제를 해결합니다. encoder는 고차원의 semantic feature를 추출하기 위해 프레임을 가공하고, 프레임 간의 long-term structual relationship information를 보존합니다. decoder는 이 정보를 바탕으로 keyframe을 골라주는 0/1 라벨을 생성하고요.
SUM-FCN
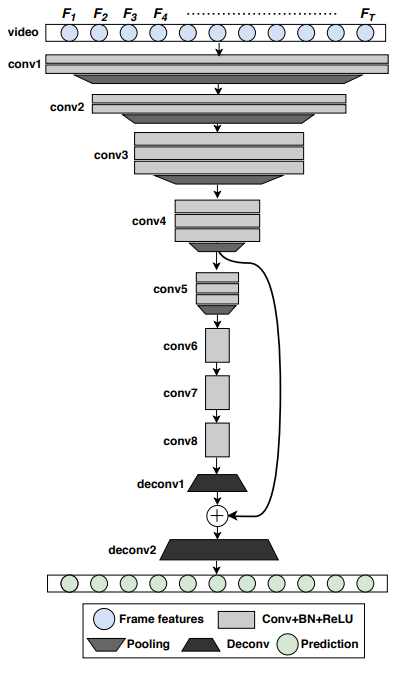
사실 이 FCN이라는 모델 자체가 semantic segmentation에서 널리 사용되고 있어서, 논문 저자는 semantic segmentation에서 RGB 이미지를 입력하는 것을 video summarization 용으로 고치기만 했습니다. 이미지가 m * n * 3의 입력을 가지고 있었다면, 여기서는 1 * T * D의 입력을 넣는거죠. (T는 비디오 프레임의 갯수, D는 feature dimension) 그리고 모든 spatial convoulution을 temporal convolution으로 바꾸었습니다. 이걸 바꾼 이유와 동일하게 spatial maxpooling과 deconvolution layer도 temporal한 연산을 지원하게 바꾸었다고 합니다. 그리고 Conv4의 output을 deconv에서 skip connection 연산을 수행해주는데요. 이는 비디오 요약에서 필요한 temporal information을 복원하는데 도움이 되기 때문에 이렇게 수행했다고 합니다.
하지만 문제가 하나 더 있습니다. 이렇게 keyframe과 non-keyframe을 모델이 예측하도록 학습을 하면, 비디오의 keyframe이 당연히 non-keyframe보다 훨씬 적기 때문에 데이터 불균형 문제가 발생합니다. 이 문제도 pixel level labeling 문제에서는에서는 이 문제를 해결하기 위한 대응법이 이미 있다고 합니다.
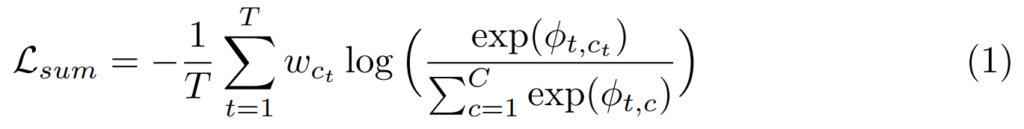
위의 Loss 계산에서 $c_t$가 GT이고, φ, w가 각각 score와 weight라고 하는 Loss를 사용하는데요. 여기서 이 weight가 이 문제를 해결합니다. w_c = median_freq / freq_c를 통해 weight를 만들어서 학습할때 class 예측에 weight 값을 이용하기 때문에 클래스 불균형 문제를 해결할 수 있다고 합니다.
Unsupervised SUM-FCN
비지도학습 방법론은 데이터셋의 한계 때문에 꾸준히 등장하는 것 같습니다. 이 논문의 저자들도 지도학습 방법론의 SUM-FCN을 제안하면서 비지도학습 방법론도 같이 제안했습니다.
비지도학습의 비디오 요약의 목적은 살짝 다릅니다. 기본적으로는 시각적으로 서로다른 키프레임을 뽑아서 비디오 요약을 생성하는 것을 목표로 하고 있습니다. (사실 데이터셋을 실제로 확인해보면 단순히 시각적인 다양성만을 유지한다고 해서 제대로된 요약을 만들 수 없는 비디오가 포함되어 있어서 의문이 드는 부분이긴 합니다. 하지만, 기본적으로 시각적인 다양성을 유지해야한다는 선행연구들에 따르는 것 같습니다.)
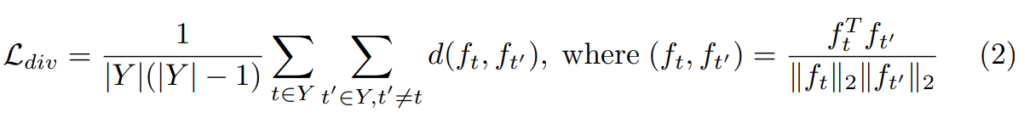
그리고 이러한 다양성을 보장하기 위해서 위와 같은 키프레임의 시각적 다양성을 보전할 수 있는 diversity loss를 사용하는데요… Y가 선택된 keyframe이라는 정도만 알면 모르는 기호는 없을 것 같네요. 근데 이쯤 되면 사실 익숙한 설명이 나오기 시작해서… 잘 보니…
이전에 리뷰했던 “[CVPR 2019] Video Summarization by Learning from Unpaired Data”의 베이스라인이 여기서 출발했더군요… 자세한 내용은 그 논문을 읽어보면 똑같아서 넘어가겠습니다.
Experiments
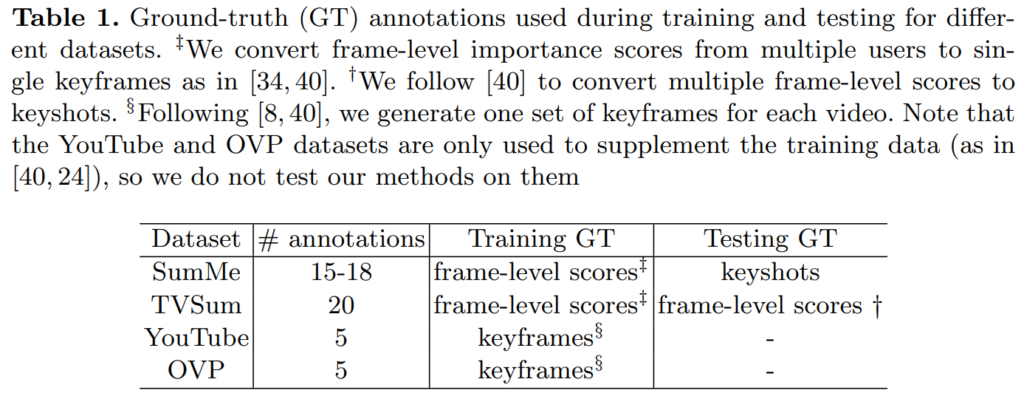
사실 데이터셋에 테스트 GT도 frame-level score로 존재하는지 알았는데, SumMe의 경우에는 shot 단위로 존재하더라고요. 물론 이번 논문에서는 shot단위로 평가를 진행하기 때문에 거꾸로 TVSum의 frame-level scroe를 샷 단위로 변환하는 과정을 거쳐 평가에 이용했습니다.
구현 디테일에서도 약간 세부적인 튜닝이 추가되었습니다. 먼저, 이 논문에서는 초당 2프레임을 뽑아서 video feature를 구성합니다. (백본은 GoogleNet을 사용했습니다.) 그리고 특이한 점은 semantic segmentation에서 crop을 하는 것과 유사하게 학습을 수행할 때, 비디오의 320개 프레임만 보도록 처리합니다. 이런 방식을 통해 길면서도 다양한 길이의 영상에 효율적으로 작동하도록 했다고 합니다.
사실 이 부분이 되게 신기한 부분 중 하나입니다. 초당 2프레임씩 뽑았기 때문에, 최대 160초까지만 모델이 학습한다는 것이 됩니다. 실제로 reimplentation된 코드를 봐도 그렇게 구현되어 있고요. 비디오 요약의 비디오들의 평균 길이(146초, 235초)를 고려하면, 합리적이긴 하지만… 요약할만한 주요 사건은 160초 안쪽에서 발생한다는 분석이 있었기 때문에 이렇게 구현하지 않았을까라는 생각도 듭니다.
실험은 3가지 세팅을 두고 실행되었습니다.
- Standard Supervised Setting : 랜덤으로 선택된 같은 데이터셋 내의 80%의 비디오와 20%의 평가 비디오로 구성함
- Augmented Setting : 위의 세팅과 동일하지만, 학습 데이터를 구성할 때 다른 데이터셋에서도 가져와서 구성함
- Transfer Setting : 학습 데이터셋과 평가 데이터셋을 다르게 구성함
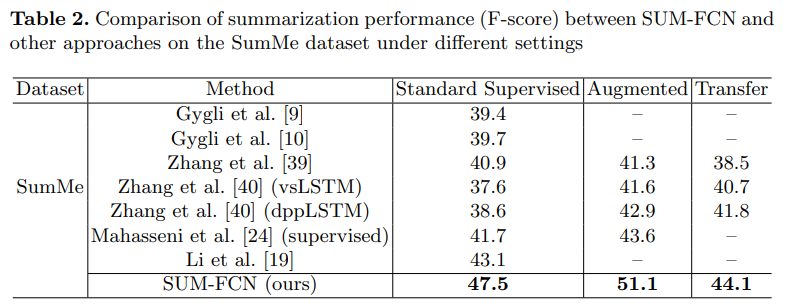
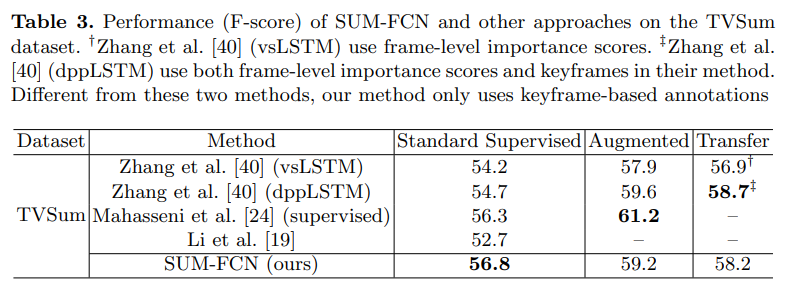
기존의 방법론들에 비하면 성능이 꽤 오른 것을 확인할 수 있습니다. 특히나, SumMe에서 다른 데이터셋이 포함된 평가 방법론으로 실험할때 성능이 많이 올랐습니다. TVSum에서는 기대한만큼 성능이 오르지는 않았는데 이는 TVSum에서는 프레임 단위로 keyframe을 고르도록 학습된게 아니라 샷단위로 학습되었기 때문에 그렇다고 합니다. (TVSum 자체가 샷단위의 GT가 없어서 가공했기 때문)
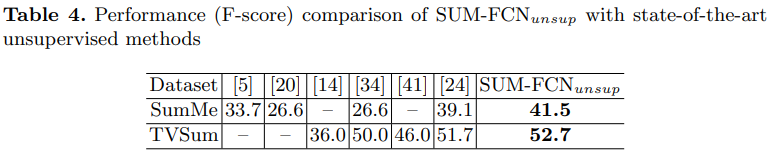
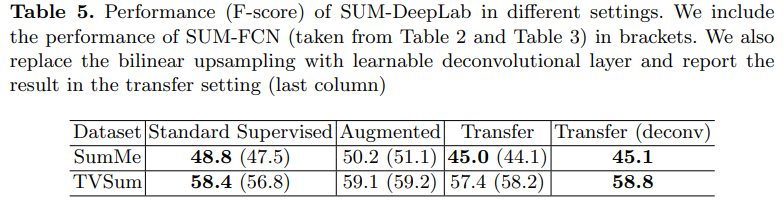
비지도학습 결과도 같이 첨부되어 있는데… 사실 이 부분도 위에서 언급했던 것 처럼 이미 제가 리뷰한 “[CVPR 2019] Video Summarization by Learning from Unpaired Data”에서 확인하는 것이 더 좋을 것 같습니다.
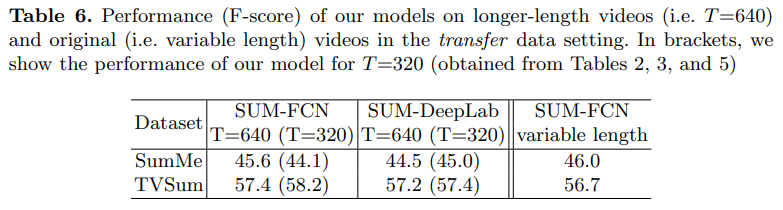
이 실험도 볼만한 실험이었는데요. 입력 비디오의 길이를 160초로 제한함에 따라 발생하는 성능 차이에 대한 실험입니다. 제가 예상한 것과는 다르게 T의 값을 좀 더 길게 바꾸어서 좀 더 비디오를 길게 본다고 해서 무조건 성능이 오르는 것은 아니라는 것을 확인할 수 있었습니다. “variable length”은 이러한 고정길이 입력을 강제하지 않았을 때의 성능인데, SumMe에서는 꽤 좋은 성능을 보이는 것을 볼 수 있습니다.
Conclusion
방법론 자체는 semantic segmentation에서 사용하는 방법론들을 가져와서 그대로 적용한 것으로 보여서 내용이 많이 없더라고요. 비지도 학습 방법론도 뭔가 다른줄 알고 읽었는데 알고보니… CVPR 논문의 preview 같은 느낌이고… 이러한 부분은 좀 아쉬웠지만, 오히려 그런 접근 방식을 통해 앞으로 할 실험을 다시 생각해볼 수 있는 논문이었던 것 같습니다.
2018년 논문이니 2017년에 작성되었을 것이고 저때만해도 각분야 딥러닝으로 갈아타기 바뻤던 시기죠. 지금은 짤 없습니다. ㅎㅎ 최신 논문으로 보시는 걸 추천합니다. 이제 한해한해가 다를겁니다.
넵… 최신 논문부터 거꾸로 읽다보니 순서가 약간 그런 느낌인 것 같습니다. 베이스를 봤으니 다시 최신 논문 보도록 하겠습니다!