Self-supervised learning 에 대한 논문을 다시 가져왔습니다. 저번 튜토리얼 발표에서도 언급하였지만, self-learning은 contrastive learning 기반의 방법론으로 성능이 큰 폭으로 향상되었는데요. 이번에도 Contrastive learning을 사용한 연구에 대해 리뷰해보도록 하겠습니다.
리뷰를 시작하기 전에 본 논문을 한 줄로 요약하자면… Clustering 을 함께 결합하여 Self-supervised learning을 수행하였다! 라고 할 수 있습니다.

Introduction
contrastive learning에서는 각각의 이미지를 instance로 보고 분류 문제를 푸는 instance discrimination task 문제를 수행하여, 비슷한 특징을 지닌 instance들을 negative로 정의하여 서로 밀어내도록 학습을 진행하였습니다. 즉, low-level semantics를 포착하여 discriminative task를 수행했습니다.
그러나 이런 Intstance discrimination task에는 문제점이 있다면, 바로 데이터의 semantic한 정보는 고려하지 않는다는 것입니다. 즉, representation은 데이터의 semantic structure를 고려하지 않아 semantic 유사성이 높더라도 서로 멀리 위치하도록 학습이 된다는 것이죠.
따라서 본 논문에서는 이 문제를 해결하기 위해 비슷한 특징을 공유하는 instance를 prototype(=clustering)으로 묶어 instance 단위가 아닌 prototype 단위로 contrastive learning을 수행합니다. 이를 위해 semantic structure of data를 encode 할 수 있고 high level semantics을 포착합니다.
(여기서 prototype은 본 논문에서 정의하는 단어로 “semantic 하게 유사한 instance 그룹에 대한 대표적인 임베딩” 이라고 이해하면 좋을 것 같습니다. )
다시 말해, 기존의 contrastive learning은 instance 별로 비교하며 positive feature 끼리는 가까이 위치시키고 , negative feature끼리는 멀게 위치시키는 것이었다면, 본 논문에서 제안하는 prototype contrastive learning은 feature끼리 비교하는 것이 아닌, prototype과 비교하여 당기고, 밀어내는 방식입니다.
자세한 과정에 대해서는 방법론 파트에서 설명을 드리도록 하고, 본 논문의 contribution을 정리하면 다음과 같습니다.
- contrastive learning과 clustering을 연결하는 PCL 이라는 새로운 프레임워크를 제안하였다
- 대표적인 contrastive loss인 InfoNCE를 개선한 ProtoNCE Loss를 새롭게 제안하였다.
Method
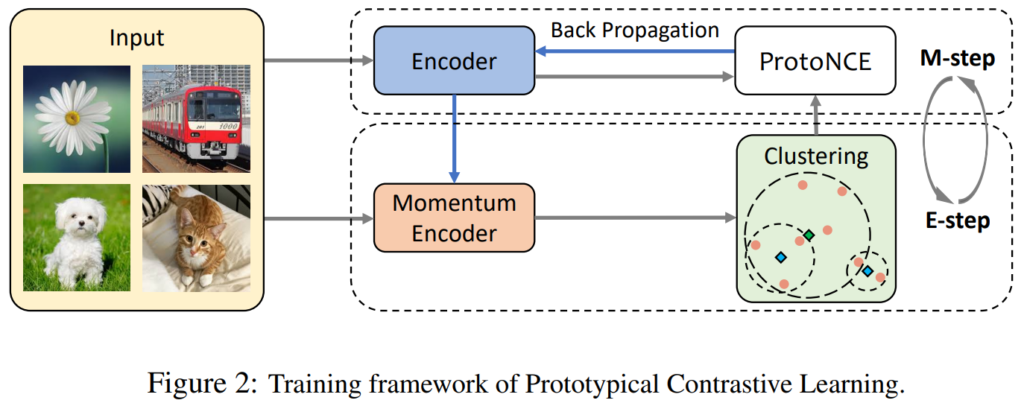
본 논문이 제안하는 모델의 구조입니다. 구조 자체는 MoCo와 흡사한데, clustering을 한 단계 거친 후 Loss를 비교한다는 차이가 있습니다.
이 때, EM(Expectation Maximization) 기법을 통한 학습 방법을 제안하였습니다.
1. E-step (Expectation) : Clustering
이번 단계에서는 clustering을 통해 전체 train feature를 k개의 cluster로 구분합니다. 본 논문에서는 이 과정 덕분에 semantic 한 Instance끼리 묶여서 prototype이 생성된다고 주장하는 것이죠. 이 때 Clustering 방법으로는 일반적인 k-means clustering을 사용하였다고 합니다.
2. M-step (Maximization) : ProtoNCE loss learning
다음으로 수행되는 Maximization 단계에서는 ProtoNCE loss로 학습을 진행합니다. ProtoNCE loss 는 기존 MoCo에서 사용한 NCE Loss를 개선하여 본 논문에서 제안하는 Loss 입니다.
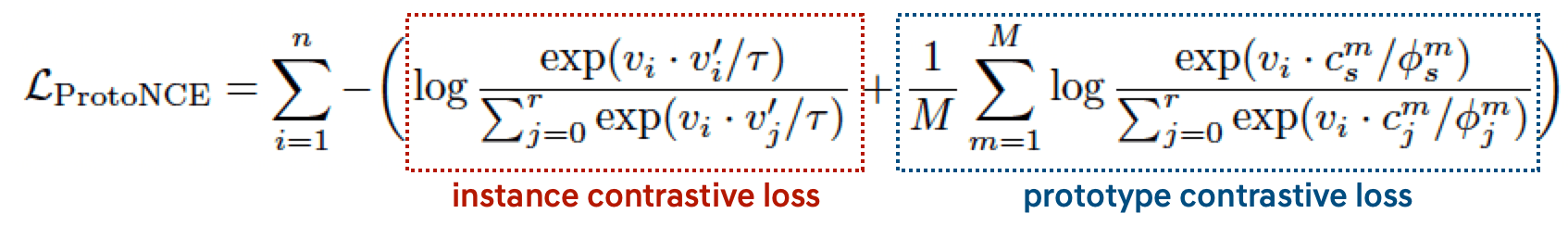
빨간색으로 표기한 첫번째 항은 일반적인 constrastive loss인 instance contrastive loss 항을 의미합니다.
그리고 파란색으로 표기한 두번째가 바로 prototype을 고려한 본 논문에서 제안하는 loss 입니다. 각 변수가 의미하는 것은 다음과 같습니다.
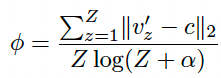
- c : 각 cluster의 centroid
- ? : cluster concentration (오른쪽 수식 참고)
- c : cluster centroid
- Z : 해당 cluster에 속하는 feature의 개수
학습은 prototype contrastive loss를 최소화하도록 진행되게 됩니다. 즉, v*c는 최대화시키면서, ?는 최소화시키도록 학습이 됩니다. (수식을 설명하자면 v * c 를 최대화시킴으로써 cluster의 중심으로 모이도록, ?를 최소화시킴으로써 더 많은 feature 를 cluster에 속하도록 학습이 진행되는 것입니다)
그렇다면 저 ? 항은 무엇이냐? 이 값이 존재함으로써 하나의 cluster에 모든 feature가 모여버리는 trivial solution을 방지할 수 있게 됩니다.
MUTUAL INFORMATION ANALYSIS
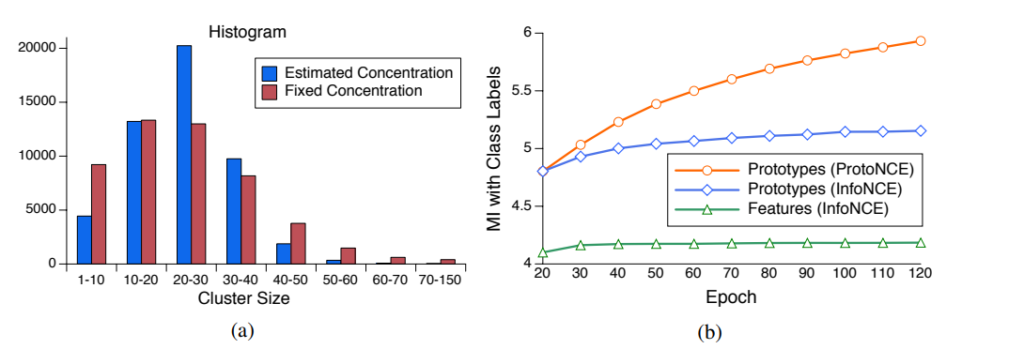
본 논문에서는 앞서 제안한 ?를 적용했을 때와 안했을 때의 차이를 볼 수 있는 실험을 또 진행하였는데요. 상단 그림 중 (a)가 바로 그 차이를 보이는 그래프입니다. ?를 적용한 것은 파란색, 적용하지 않은 것은 빨간색이며, cluster 사이즈에 따른 그 차이를 나타냅니다. ?를 적용하면 더 작은 사이즈의 cluster가 더 많이 생성되는 결과를 보였습니다. 이를 통해 더 좋은 representation을 학습할 수 있다는 것을 확인하였다고 합니다.
오른쪽에 있는 그래프 (b)는 학습에 따른 MI(mutual info)그래프입니다. Feature로 학습할 때 보다 prototype으로 학습할 때가, InfoNCE로 학습할 때 보다 ProtoNCE로 학습할 때가 더 큰 MI를 보인다는 결과를 보였다는 것을 토대로, 제안하는 protoNCE가 좋은 성능과 prototype으로 학습할 때의 효과를 보여주었습니다.

PCL에서 제안하는 방법론을 정리한 수도코드입니다.
Experiment
1) Low-shot classification
self-learning에서 항상 진행하는 고정 표현에 대한 성능 측정입니다.
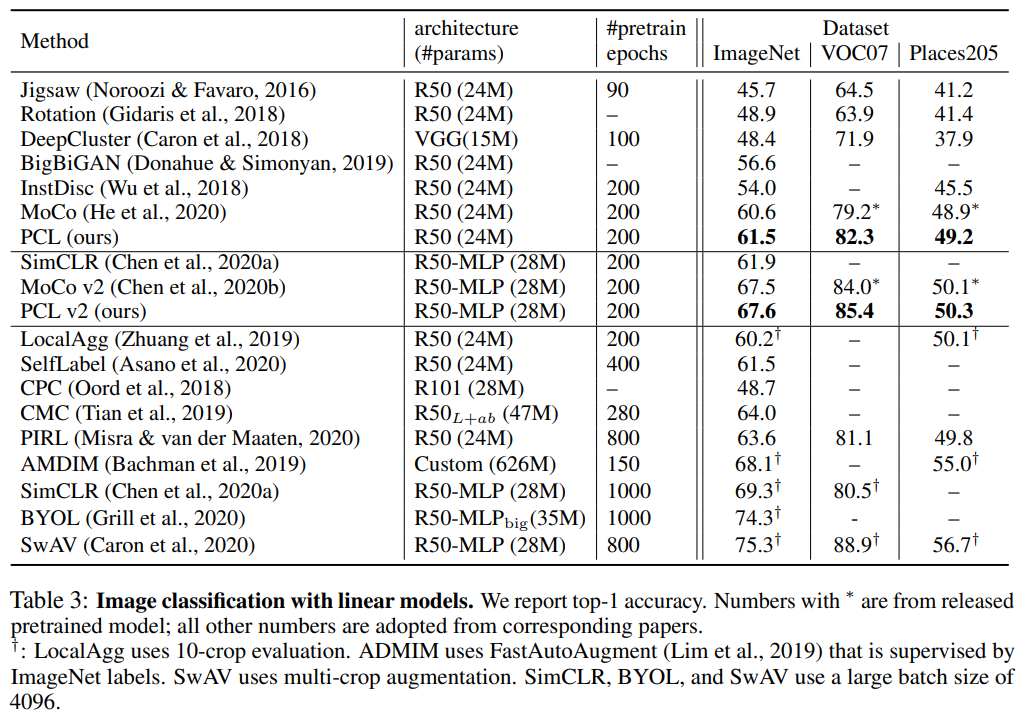
fixed representations에 대해 학습된 linear-SVM을 사용하여 VOC07 과 Places205 데이터셋 모두에서 low-shot classification을 진행한 결과입니다. class 당 샘플 수 k개로 바꿔가며 실험을 진행한 결과입니다. MoCo와 SimCLR를 모두 뛰어넘은 성능을 가질 수 있었습니다. Jigsaw는 대표적인 pretext task기반의 .self-learning입니다.
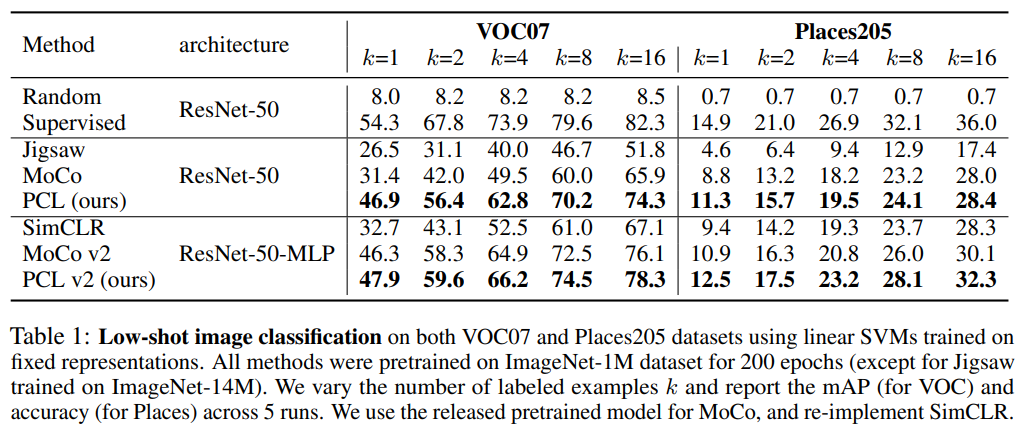
Semi-supervised image classification 한 결과도 리포팅하였습니다.
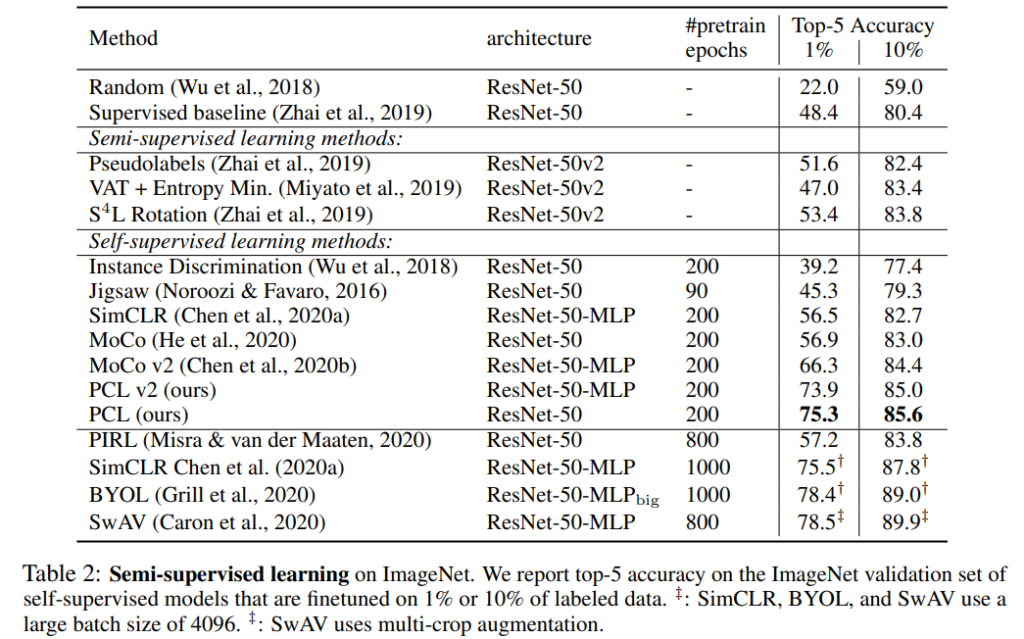
Linear classifiers 라벨이 지정된 전체 학습 데이터를 사용하여 fixed representation 대한 선형 분류기를 학습한 결과입니다. 여기서는 세 가지 데이터셋인 ImageNet, VOC07, Places205 에서 성능을 평가합니다.
T-sne에 의한 시각화 결과입니다. MoCo와 비교하여 구분이 잘 된 것을 알 수 있었습니다.

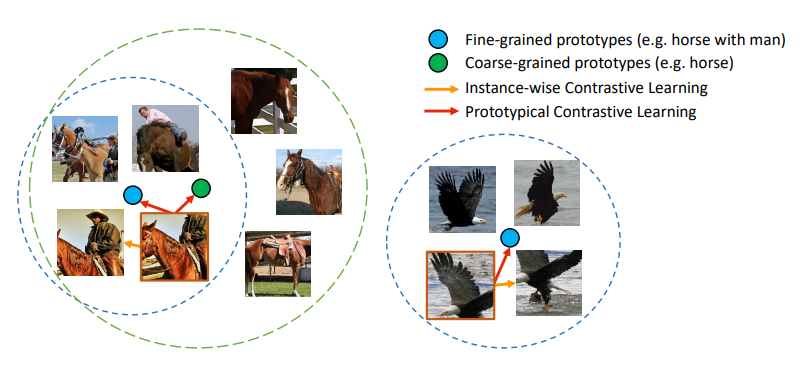
마지막으로 랜덤하게 cluster를 선택하여 시각화한 결과입니다. 초록색은 fine-grained prototypes과 가장 가까운 5개의 이미지를 의미하며, 주황색은 동일한 녹색 class를 커버하는 클러스터(K = 50k)에서 무작위로 선택한 이미지를 의미합니다. 이를 통해 PCL은 데이터 내에서 계층적 의미 구조를 학습할 수 있었다 라고 합니다. (ex: 말과 사람이 포함된 이미지는 coarse-grained의 말 클러스터 내에서 fine-grained 클러스터를 형성한다).

제가 생각했던 것보다 계층적인 구조를 직접 확인할 수 있었다는 점이 인상깊었습니다. 접근 방식 역시 색다르고 이를 해결해나가는 논리와 해결력도 나름 신선했습니다. 이러한 접근법으로 기존 문제점을 찾는 방식을 시도해봐야겠습니다.
질문이 하나 있는데, 맨 처음 Intro에서 contrastive learning을 설명하시는 부분이 있는데 해당 내용 중 “비슷한 특징을 지닌 instance들을 negative로 정의하여 서로 밀어내도록 학습을 진행하였습니다”가 이해가 좀 안가네요?
Contrastive Learning은 positive끼리는 가까이, negative 끼리는 멀어지도록 하는 것인데, 제가 알기로 비슷한 특징을 지닌 instance들은 보통 positive로 보지 않나요? 왜 비슷한 특징들을 가진 instance 끼리 멀어지도록 정의해서 학습을 진행하죠?
좋은 댓글 감사합니다.
contrastive learning을 사용한 self-learning에서는 동일한 이미지 A에서 augmentation 된 두 개의 이미지( A’ ^& A” )만을 positive 라고 두고, 동일 배치에 있는 나머지 이미지는 모두 negative 라고 설정합니다. 이 때 A와 분명 semantic 하게 비슷한 이미지임에도 불구하고 negative 로 처리되는 경우에 대해 이야기 한 것이었습니다. 따라서 비슷한 instance임에도 negative 로 처리된 경우에 대해 본 논문에서는 문제삼았던 것이고, 이를 “비슷한 특징을 지닌 instance들을 negative로 정의하여 서로 밀어내도록 학습을 진행하였습니다” 이와 같이 표현하였던 것입니다.
안녕하세요 좋은 리뷰 감사합니다.
기존의 sematic 정보를 무시하는 contrastive learning의 단점을 보안하기 위해 clustering을 이용하는 논문을 소개해주신것으로 이해했는데, 그럼 cluster의 갯수 k는 class의 갯수보다 적나요? 보통 어떤 식으로 설정하게 되나요? 실험적인 값은 두가지 데이터셋에 대해 제공된 것같은데 혹시 데이터에 치중된 정보가 아닌 일반적인 최적 k에 대한 정보도 있을까요?
좋은 댓글 감사합니다.
instance discrimination 의 클래스는 데이터셋 크기와 같고 여기서의 class 개수라면 네 적습니다. 본 논문에서는 (25,000 50,000 100,000) 일 때 비교 실ㅍ험을 진행하였으며 25,000에서 제일 좋은 성능을 보였다고 합니다. 그러나 안타깝게도 일반적인 최적 K 값에 대한 정보는 없었습니다.