Before Review
이번 리뷰는 자연어처리 논문을 읽게 되었습니다. BERT라고 해서 아마 한번쯤을 들어보셨을 법한 논문을 읽게 되었는데요, 이번 캡스톤 주제중 하나인 Text-to Video 논문을 읽을라고 하니, 계속 BERT가 나오는 것 같아 이 논문을 읽고 가야 편할 것 같아 리뷰를 하게 되었습니다.
BERT를 좀 찾아보니, 자연어처리에 있어서 아주 대단한 업적을 쌓은 그런 논문인가 봅니다. BERT는 간단히 얘기해서 텍스트 데이터를 임베딩 시키는 새로운 메커니즘을 제안한 논문이라 보면 됩니다.
이 임베딩이 너무나도 좋아서 11가지 자연어처리 task에서 SOTA를 달성하였다고 하네요. 따라서 BERT 이후로는 Word2Vec이나 Glove와 같은 임베딩을 사용하지 않고 거의다 BERT 인코더를 통해서 나온 embedding을 사용하고 있다고 합니다.
그럼 본격적으로 리뷰 시작하도록 하겠습니다.
Introduction
우리 컴퓨터 비전에서도 ImageNet Pretrain이 중요하게 작용하는 것 처럼, 자연어처리에서도 사전학습의 중요성은 여전히 존재합니다. 자연어 처리에서 사용되는 사전학습의 깊은 역사는 잘 모르지만 논문에 의하면 두가지의 전략이 존재한다고 합니다.
Feature based 방식은 ELMo라는 기법이 대표적이고, Fine-tuning 방식은 GPT(Generative Pre-trained Transformer)가 대표적이라고 하네요. 기존의 이 두가지 접근 방법들은 동일한 방식을 공유합니다. Unidirectional language model을 사전학습 한다는 점 인데요. 저자는 이러한 unidirectional 접근들이 pre-trained representation을 크게 방해한다고 주장합니다.

위의 그림은 BERT와 GPT 그리고 ELMo의 구조적인 차이를 보여주는 그림입니다. 가운데 그림의 GPT는 트랜스포머의 디코더를 이전 단어들로부터 다음 단어를 예측하는 방식으로 단방향 언어 모델을 만들었습니다. 즉, 이전 단어들만 가지고 attention이 진행되기 때문에 unidirectional 이라 부르는 것 입니다. ELMo는 엄밀히 말하면 bi-directional한 구조(정방향 LSTM + 역방향 LSTM)로 학습이 되어서 저자가 주장하는 문제 상황에는 해당되지 않습니다. 하지만 LSTM 구조를 사용하고 있다는 약점이 존재했습니다.
따라서 트랜스포머를 베이스로 하면서도 양쪽 방향을 모두 고려하는 모델을 만들 수는 없을까?에 대한 고민으로 구글 연구진들은 이 BERT라고 하는 것을 제안하게 됩니다.
BERT는 이를 위해 두가지 pretrain 전략을 고려하게 됩니다. Masked Language Modeling(MLM)이라는 하는 것과 Next Sentence Prediction(NSP)라는 것인데요 이게 무엇인지는 뒤에서 더 자세히 설명하도록 하겠습니다.
이렇게 pretrain된 새로운 인코더를 가지고 다양한 자연어처리 task에 적용을 할 수 있는데요, 이 BERT라고 하는 것이 얼마나 대단한지 11가지 task에 대해서 모두 SOTA를 갈아치웠다고 합니다. 워낙 임베딩 능력이 좋아 다양한 자연어처리 task에서 embedding vector를 얻기위해 이 BERT를 사용한다고 합니다.
그렇다면 이 BERT 가 과연 무엇인지 이제 부터 알아보도록 하겠습니다.
BERT
BERT의 기본 구조는 트랜스포머의 인코더를 쌓아올린 구조입니다.즉, 트랜스포머의 인코더만을 사용했다고 생각하시면 됩니다. Base 버전에서는 총 12개를 쌓았으며, Large 버전에서는 총 24개를 쌓았습니다. 여기서 BERT-base는 BERT보다 앞서 등장한 GPT-1과 하이퍼파라미터가 동일한데, 이는 BERT 연구진이 직접적으로 GPT-1과 성능을 비교하기 위해서 GPT-1과 동등한 크기로 BERT-Base를 설계하였기 때문입니다.
Token Embedding
BERT의 임베딩 자체는 Transformer 구조를 그대로 사용하여 하기 때문에 Contextual Embedding을 수행하게 됩니다. 이 Contextual Embedding이 무엇이냐면 문맥을 반영한 임베딩이라고 생각하면 됩니다. 동일한 단어라 할 지라도 그 문장의 문맥에 맞춰서 해석하는 의미가 달라지는 것을 의미합니다. 이는 Transformer의 Multi-Head Self Attention을 통해서 가능한 것이겠죠? Multi-Head Self Attention이 무엇인지 모르겠다면 저의 이전 리뷰를 참고 하시길 바랍니다.
Position Embedding
트랜스포머에서는 포지셔널 인코딩(Positional Encoding)이라는 방법을 통해서 단어의 위치 정보를 표현했습니다. 포지셔널 인코딩은 사인 함수와 코사인 함수를 사용하여 위치에 따라 다른 값을 가지는 행렬을 만들어 이를 단어 벡터들과 더하는 방법입니다. BERT에서도 동일하게 활용하여 위치 정보를 투여해주게 됩니다.
Segment Embedding
저는 자연어 처리 task가 기계 번역같은 것들만 있는 줄 알았는데 그게 아니라 Question and Answering과 같은 두 개의 문장 입력이 필요한 task도 있다는 것을 본 논문을 통해 알았습니다. 여기서 중요한 것은 첫번째 문장과 두번째 문장을 구분해야할 필요가 있겠죠? 따라서 Segment Embedding은 두 개의 문장을 구분하기 위한 임베딩으로 임베딩 벡터의 종류는 문장의 최대 갯수인 2개 입니다.
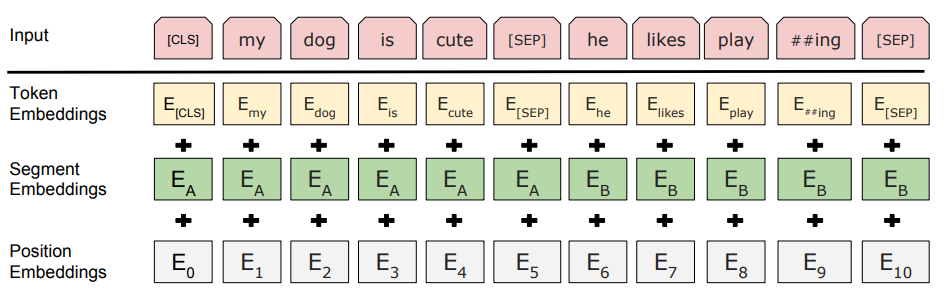
결론적으로 BERT는 총 3개의 임베딩 벡터를 활용하여 자연어 데이터를 처리합니다.
Pre-training BERT
BERT를 사전학습 시키기 위해서 저자는 두가지의 unsupervised task를 사용합니다. 바로 Masked Language Modeling(MLM)이고 다른 하나는 Next Sentence Prediction(NSP)라는 것 입니다. 이 두가지가 무엇인지는 지금부터 알아가보도록 하겠습니다.
Task #1 : Masked LM
Masked 라는 단어를 보면 뭔가 느낌이 오실 수도 있을 것 같습니다. 입력 텍스트의 15%의 단어를 랜덤하게 Masking을 하게 됩니다. 즉 문장 중 일부를 가려놓고 이 없어진 부분에 대해서 문맥을 통해 예측을 하라는 작업이라고 보면 됩니다.
여기서 한가지 더 고려해야할 사항이 있습니다. [MASK]라는 토큰은 사전학습 때는 인위적으로 만들어 주지만 finetuning 단계에서는 발생하지 않는다는 것 입니다. 따라서 pretrain과 finetuning간의 misalignment 문제가 발생할 수 있어 다음과 같은 규칙으로 Masking을 적용하게 됩니다.
- 80%의 단어들은 [MASK]로 변경한다.
Ex) The man went to the store → The man went to the [MASK]
- 10%의 단어들은 랜덤으로 단어가 변경된다.
Ex) The man went to the store → The man went to the dog
- 10%의 단어들은 동일하게 둔다.
Ex) The man went to the store → The man went to the store
그래서 각 masking된 embedding vector를 가지고 classification을 통해 pretrain이 진행된다고 보면 됩니다.
Task #2 : Next Sentence Prediction
또 하나의 Pretrain task는 이진 분류로 진행이 됩니다. 두 개의 문장을 입력으로 받고 이 문장이 이어지는 문장인지 아닌지를 맞추는 방식으로 훈련이 된다고 보면 됩니다. 논문에 나와있는 예시를 좀 가져와서 살펴보도록 하겠습니다.
- [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] : 이어지는 문장
- [CLS] the man went to [MASK] store [SEP] penguin [MASK] are flight ##less birds [SEP] : 이어지지 않은 문장
근데 여기서 특이한 것이 등장을 했습니다. [CLS] 토큰과 [SEP] 토근인데요, [CLS] 토큰은 BERT가 분류 문제를 풀기 위해 추가된 특별한 토큰이라 보면 되고, [SEP] 토큰은 문장을 구분하기 위한 토큰이라 보면 됩니다. 첫번째 문장과 두번째 문장이 끝난 지점에 [SEP] 토큰이 들어가 있다는 것을 보면 알 수 있겠네요.
BERT는 Masked Language modeling을 통해 단일 문장에 대한 문맥을 이해하기 위한 훈련이 진행되며, Next Sentence Prediction을 통해 두 문장의 관계를 이해하는 훈련이 진행이 됩니다. 두 task 모두 자연어처리에서 좋은 임베딩을 가지기 위해서 고려 되어야하는 속성이라 볼 수 있겠네요.
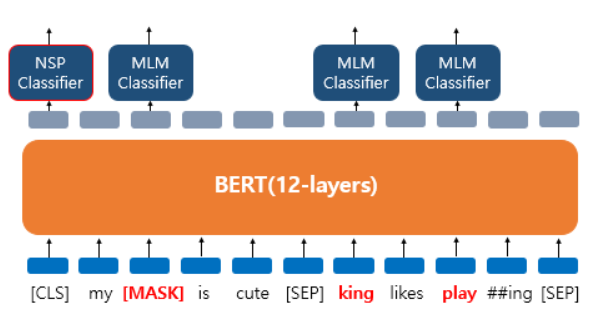
그래서 보면 [CLS] 토큰을 통해 Next Sentence Prediction를 수행합니다. 입력으로 들어온 두 문장이 이어지는 관계인지 아닌지 그와 동시에 Masked embedding vector에 대해서는 각각 Classifier를 달아서 원래 무슨 단어였는지 예측하는 과정을 수행하게 됩니다.
Fine-tuning BERT
BERT는 위에서도 설명한것 처럼 사전학습된 인코더 입니다. 우리는 이제 이 인코더를 가지고 원하는 task에 대해서 finetuning을 진행할 수 있을 것 입니다. finetuning의 과정을 사실 굉장히 간단하다고 합니다. 각각의 task에 맞춰서 마지막에 필요한 Layer만 조금 추가하면 되기 때문입니다. 여기는 크게 비전 분야랑 다르지 않은 것 같습니다. Encoder로 부터 Feature를 뽑고 downstream task에 맞는 몇개의 Layer를 추가해서 Loss를 계산한뒤 전체 네트워크를 finetuning 하는 방식은 비전에서도 많이 하는 방식이기 때문입니다. 논문에 나온 4가지의 예시를 가지고 한번 설명해보도록 하겠습니다.
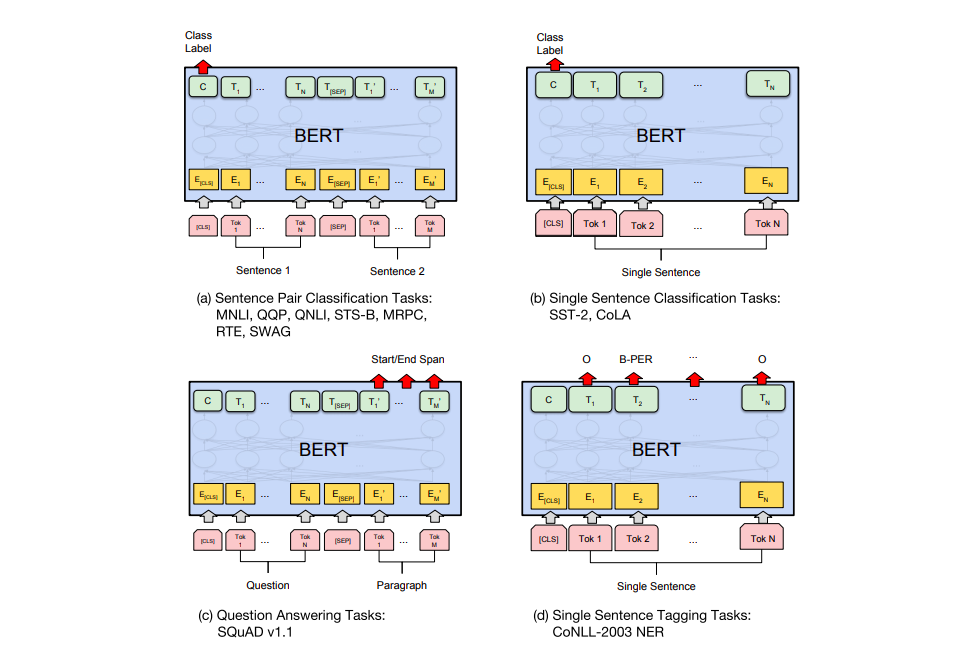
(a)와 (b)는 Sentence level의 task로 비슷하게 동작합니다.
우선 (a) Sentence Pair Classification에 대해서 먼저 알아보면 대표적으로 자연어 추론이 있다고 합니다. 자연어 추론 문제란, 두 문장이 주어졌을 때, 하나의 문장이 다른 문장과 논리적으로 어떤 관계에 있는지를 분류하는 것입니다. 찾아보니 유형으로는 모순(contradiction), 함의(entailment), 중립(neutral) 관계등이 있다고 합니다. 그냥 Classification이라 보면 될 것 같습니다.
(b) Single Sentence Classification Task에 대해서 얘기해보면 스팸 분류 이런것이 대표적이라 볼 수 있겠네요. 즉, 하나의 문서에 대한 텍스트 분류 유형입니다.
여기서 (a), (b) 모두 [CLS] 토큰을 사용하게 됩니다. 앞서 Pretraining 단계 에서 [CLS] 토큰은 BERT가 분류 문제를 풀기위한 특별 토큰이라고 언급한 바 있습니다. 이는 BERT를 실질적으로 사용하는 단계인 fine tuning 단계에서도 마찬가지입니다. 텍스트 분류 문제를 풀기 위해서 [CLS] 토큰의 위치의 추가적인 FC Layer를 달아서 분류를 수행하게 되는 것이지요.
(c)와 (d)는 이제 Token level의 task라 볼 수 있습니다.
(c) 부터 얘기를 해보자면 Question Answering task라고 해서 질문과 본문을 입력받으면, 본문의 일부분을 추출해서 질문에 답변하는 것입니다. 제가 한국말 예시를 찾아봤을 때는 다음과 같은 예시가 있다고 하네요.
“강우가 떨어지도록 영향을 주는 것은 ?” 라는 질문과
“기상학에서 강우는 대기 수증기가 응결되어 중력의 영향을 받고 떨어지는 것을 의미합니다. 강우의 주요 형태는 이슬비, 비, 진눈깨비, 눈, 싸락눈 및 우박이 있습니다”. 라는 본문이 주어졌다고 해보겠습니다.
이 경우 정답은 중력이라고 볼 수 있습니다. 이 처럼 질문에 대한 답을 본문에서 찾아서 예측하는 작업을 Question Answering 이라고 하네요.
(d) 는 Tagging 작업이라고 해서 말 그대로 각 단어별로 태깅을 한다고 보면 됩니다. 각 단어의 품사를 태깅하거나 개체를 태깅하는 작업들이 있다고 하네요. [CLS] 토큰이 아니라 각 embedding token 별로 분류가 진행된다고 보면 됩니다.
Experiments
BERT에서도 실험을 진행할 때는 자연어처리에서 가장 많이 활용되는 GLUE 벤치 마킹을 사용했다고 합니다. 이 GLUE 벤치 마킹을 좀 찾아봤는데 GLUE는 뉴욕대, 워싱턴대, 딥마인드의 자연어처리(NLP) 연구자들이 함께 만든 언어 벤치마크로 언어 능력을 측정하는 9가지 테스트셋을 포함하고 있다고 합니다. 예를 들어, 해당 문장이 문법적으로 맞는지 판단하는 CoLA, 두 문장의 의미가 유사한지 판단하는 STS-B, 두 문장의 논리적 상관관계를 판단하는 MNLI 등이 있습니다.
여기 벤치마킹에 있는 모든 NLP task를 소개해드릴 순 없으니 궁금하신 분들은 GLUE 벤치마킹을 찾아보시길 바랍니다.
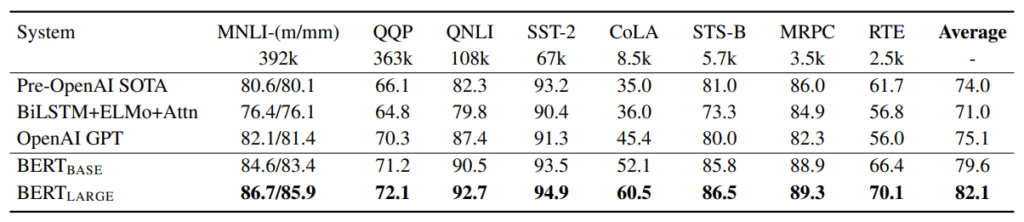
그래서 GLUE 벤치마킹을 통한 실험을 보면 BERT가 모든 task에서 제일 높은 성능을 보여주고 있습니다. BERT base만 하여도 다른 방법론들 대비 좋은 성능을 보여주는 데 BERT Large를 사용하면 base 보다도 훨씬 더 좋은 성능을 보여주고 있네요.
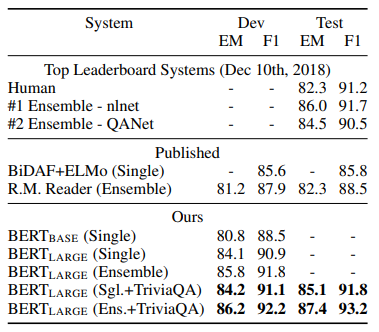
그 다음으로는 SQuAD v1.1이라는 데이터셋에서의 Question Answering 성능입니다. Question Answering task가 무엇인지는 위에서 이미 설명을 하였으니 다시 하지 않겠습니다. 평가 메트리만 조금 설명을 해보도록 하겠습니다.
- EM score (Exact match score) : 간단히 말하면 정확히 맞는 답의 수라고 합니다. 각각의 질문+본문 쌍이 입력으로 왔을 때 모델의 예측이 정확히(start index와 end index를 맞추는) 정답과 동일하면 EM =1 다른 경우는 EM = 0으로 해서 score를 산출하게 됩니다.
- F1 score : F1 score는 Precision과 Recall의 조화평균입니다. F1 score는 데이터 label이 불균형 구조일 때, 모델의 성능을 정확하게 평가할 수 있으며, 성능을 하나의 숫자로 표현할 수 있습니다.
사실 여기서 SQuAD 리더보드에 대한 언급이 논문에서 나왔는데 무슨 소리인가 이해를 하질 못했습니다. 뭐 결론만 받아들이면 SQuAD라는 유명한 Question Answering이라는 task에서도 SOTA를 달성하였습니다.
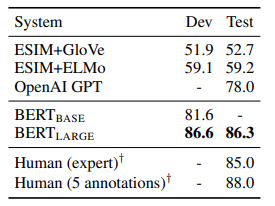
마지막으로 Situations With Adversarial Generations(SWAG)라고 해서 앞 문장이 주어졌을 때, 보기로 주어지는 4 문장중에 가장 잘 이어지는 문장을 찾는 task 입니다. 예를 들면 다음과 같은 문제라 생각하면 됩니다.
A girl is going across a set of monkey bars. She (i) jumps up across the monkey bars. (ii) struggles onto the bars to grab her head. (iii) gets to the end and stands on a wooden plank. (iv) jumps up and does a back flip.
인상 깊은 것은 사람을 능가하는 SOTA를 달성하였네요. BERT 참 대단합니다..
Ablation Studies
앞선 실험들은 사실 다 SOTA라고 하기만 하고 별 다른 분석 내용은 내놓고 있진 않았습니다 .따라서 저는 이 파트가 논문에서 가장 중요하다고 생각합니다. 같이 한번 살펴보도록 하겠습니다.
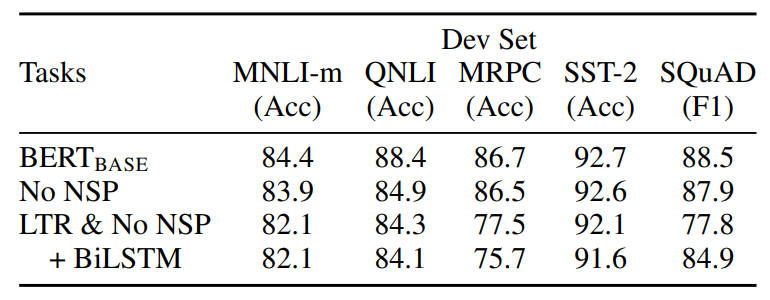
우선 Pretraining task에 두가지 요소에 대한 ablation을 알아보겠습니다. BERT_base와 동일한 hyperparameter로 실험을 진행하지만 ablation한 두가지 다른 모델로 실험을 진행합니다.
- No NSP: MLM은 사용하지만, 다음 문장 예측 (NSP)를 없앤 모델
- LTR & No NSP : MLM 대신 Left-to-Right (LTR) 을 사용하고, NSP도 없앤 모델, 이는 OpenAI GPT모델과 완전히 동일하지만, 더 많은 트레이닝 데이터를 사용하였습니다.
일단 NSP를 제거했을 때 Base 보다 성능이 조금 떨어지는 것을 볼 수 잇습니다. 그래도 성능 하락의 폭이 그렇게 크지는 않아보입니다. 그런데 NLI 계열의 task에서는 성능이 많이 떨어지는 이유가 Natural Language Inference task는 문장간 논리적인 구조 파악이 중요한 task인데 NSP를 사용하지 않으면 이러한 부분이 약해지기 때문에 성능 하락이 크게 발생하였네요.
가장 중요한것은 Masked language modeling을 제거했을 때 성능이 전반적으로 크게 감소하는 것을 볼 수있습니다. 저자가 주장한 bi-directional modeling이 왜 중요한지 보여주는 실험인 것 같습니다. 여기서 BiLSTM을 붙여서 어느정도 bi-directionality를 부여해도 성능이 하락하는 것으로 보아 Masked Language modeling이 bi-directional modeling을 하는데 최적의 방법이라는 것을 알 수 있습니다.
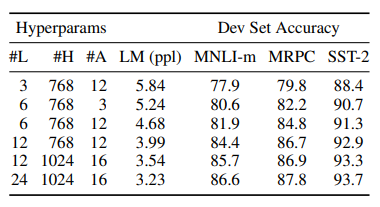
간단하게 말해서, 측정한 데이터셋에서는 모두 모델이 커질수록, 정확도가 상승함을 볼 수 있습니다. 특히 BERT의 경우에는, downstream task를 수행하는 dataset의 크기가 작아도, pre-training덕분에, model의 크기가 클 수록 정확도는 상승함을 볼 수 있습니다.
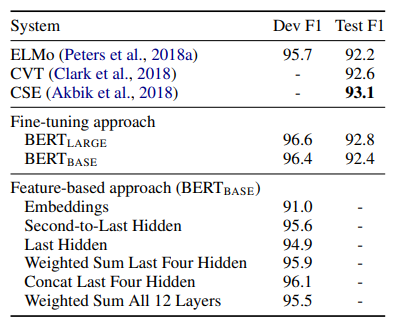
지금까지는 BERT를 사전학습후 downstream task로 finetuning을 할 때 간단한 FC layer만 붙여서 다시 학습 시키는 것만 살펴봤습니다. 하지만 BERT를 feature based approach의 방식으로도 finetuning이 가능합니다. 해당 실험에서는 BERT 마지막 레이어에 Bi-LSTM을 부착시켜 BERT를 freeze 시키고 해당 레이어만 finetuning 하는 식으로 학습을 시켰을 대의 성능입니다. 우리가 Backbone 얼리고 FC Layer 학습 시키는 거랑 비슷하다고 보면 됩니다. 결론적으로는 Finetune All과 단지 0.3 F1 score차이밖에 나지 않습니다.
이를 통해 BERT는 Feature-based approach에서도 효과적이다라는 것을 보여주고 있습니다.
Conclusion
BERT의 뛰어난 자연어 데이터 임베딩을 통해 자연어 처리의 새로운 시대가 열렸다고 해도 과언이 아닐 만큼 BERT는 위대한 연구로 생각이 듭니다. 비디오에서도 VIdeoBERT가 있는 것으로 알고 있는데 나중에 시간이 나면 한번 읽어봐야겠습니다.
지난번 Transformer 리뷰에 이어 이번에 BERT를 읽게 되었는데, 비전이 아닌 논문을 읽는 것은 어려운 것 같지만 그러면서도 뭔가 교양(?)이 쌓이는 듯한 기분이 듭니다. 이참에 GPT까지 읽어볼까 고민도 하였지만 우선 갈길이 머니, 빠르게 Text-to-Video 논문 읽으러 가야겠습니다.
아무튼 리뷰 읽어주셔서 감사합니다.
해당 방법론을 학습하려면 어느정도의 리소스가 필요하고 어느정도의 시간이 걸리나요?
학습 시간을 명시하지는 않았지만 대략 33억개의 단어로 구성된 텍스트 데이터로 사전학습을 진행한다고 하니 아마 구글 같은 대기업이 아니면 실제로 사전학습부터 scratch로 하는 것은 상당히 시간이 많이 들것 같습니다. 다만, 중요한 것은 사전학습된 BERT는 공개가 된 상태이고, 이를 finetuning하는 것은 한시간도 안걸리는 작업이기 때문에 BERT가 좋은 연구라 생각이 듭니다.
좋은 리뷰 감사합니다. BERT에 대해 듣기만 했지 전혀 몰랐는데, 덕분에 조금이나마 알게된 것 같습니다.
그런데 제가 워낙 무지한 분야라 궁금한 게 있어 댓글 남깁니다.
Segment Embedding 의 최대 개수가 2개인 것에 대한 질문인데요, 문장을 구분해주는 토큰으로 이 말은 즉 두 문장이 최대 입력이라는 뜻인가요? 그런데 Fine-tuning BERT의 (c) 는 QA task를 나타내는 것으로 문장과 문단이라고 하는데, 그럼 단순히 문장을 구분해주는 뜻은 아닌 것 같아서.. segment embedding의 역할과 학습에 어떤 영향을 주는 지 궁금합니다.
두번째는 Ablation study 에서 MLM 만을 제거한 성능 평가는 보이지는 않는지요? 몇가지 데이터셋에서 MLM을 안썼을 때 그렇게 성능이 훅 떨어지는 것 같지는 않아서 정말 bi-directional modeling에 최적의 방법인지 궁금해집니다.
감사합니다
1. 두 문장이 최대 입력이라는 뜻인가요? : 이 리뷰를 작성하면서 저도 찾아보니, 명시적으로는 Senetence pair를 고려한다고 나와있지만, 문장과 문단을 고려하는 경우 혹은 문단과 문단을 고려하는 경우도 있다고 합니다. 이때 Segment Embedding은 단순히 Question과 Answer를 명시적으로 구분하기 위한 embedding이라 보면 될 것 같습니다.
2. 보아하니 SST-2라는 Sentiment Analysis (감정 분석)에서는 성능하락이 크지 않지만 다른 task에서는 눈에 띄게 떨어지는 것이 보입니다. 추측하건데 감정 분석에는 bi driectional 접근이 크게 중요하지 않아서 성능하락이 적은 것으로 생각이 듭니다. 논문에서는 이에 대한 분석이 없어 답변은 이정도로 마치겠습니다.
안녕하세요 좋은 리뷰 감사합니다. 덕분에 BERT와 관련된 기본 개념들을 숙지할 수 있었습니다.
이전부터 궁금하던 내용이었는데, [MASK] 토큰은 단순히 차원에 맞는 0벡터가 들어가는 것인가요? [MASK] 토큰에 어떤 것이 들어가는지와, 해당 내용물을 달리 했을 때 표현력 차이에 대한 연구가 존재하는지 궁금합니다.
그리고 Next Sentence Prediction 기법으로 사전학습하기 위해서는 데이터셋 자체에 문장 쌍이 존재해야할 것 같은데, 문장 쌍 정보가 없는 데이터셋으로는 해당 사전학습을 진행할 수 없는 것이 맞나요?
좋은 리뷰 잘 읽었습니다.
저도 이전부터 BERT가 궁금했었는데요 덕분에 자세하게 알고 갑니다!
그리고 읽던 중에 생긴 질문인데요 트랜스포머에서의 Self attention은 bidirectional 한 것과는 조금 다른 건가요?
masked language modeling과 next sequence prediction은 기존의 문장 내 토큰간의 attention을 하던 것과 어떤 부분이 달라서 bidirectional하게 학습이 된다고 할 수 있는 건지 궁금합니다.
아침에 메일이 와서 깜짝 놀랐네요ㅋㅋ
GPT와의 차이를 바탕으로 이해하면 편할 텐데,
GPT의 경우는 next-token prediction 방식으로 사전학습이 진행되는데 이는
A, B, C 라는 sequence가 있는 상태에서 다음으로 D를 예측하는 과정은 uni-directional 하다고 볼 수 있고 (A,B,C-> D)
A, X, C, D에서 B를 채우는 과정은 B를 채우기 위해 A와 C, D를 모두 참조하기 때문에 bi-directional 하다고 볼 수 있습니다. (A -> X <- C,D)