합성 데이터를 이용하여 학습한 모델을 real 데이터에 적용할 때 어떤 방식을 활용하여 도메인간의 차이를 줄이는 지 알아보기 위해 읽게 된 논문입니다.
CNN방식은 어노테이션 된 라벨링에 크게 의존한다. 따라서 픽셀 단위의 정답 마스크를 생성해야 하는 segmentation의 경우 데이터가 부족하다는 문제가 있다. 이를 해결하기위해 합성 데이터를 생성하여 모델을 학습하는 방식을 이용했으나, 이는 합성 데이터를 이용하여 학습한 모델을 real 데이터에 적용하는 데 어려움이 있었다. 따라서 이러한 문제를 해결하기 위해 기존의 연구들은 target과 source 데이터간의 도메인 차이( inter-domain gap)를 줄이려는 연구를 수행하였다. 그러나 real world데이터인 target 데이터는 다양한 요인에 의해 다양한 scene distribution을 갖는다. 따라서 해당 연구는 기존 연구는 고려하지 않았던 target 데이터 자체에 있는 intra-domian gap또한 줄이기 위한 연구이다.
Approach
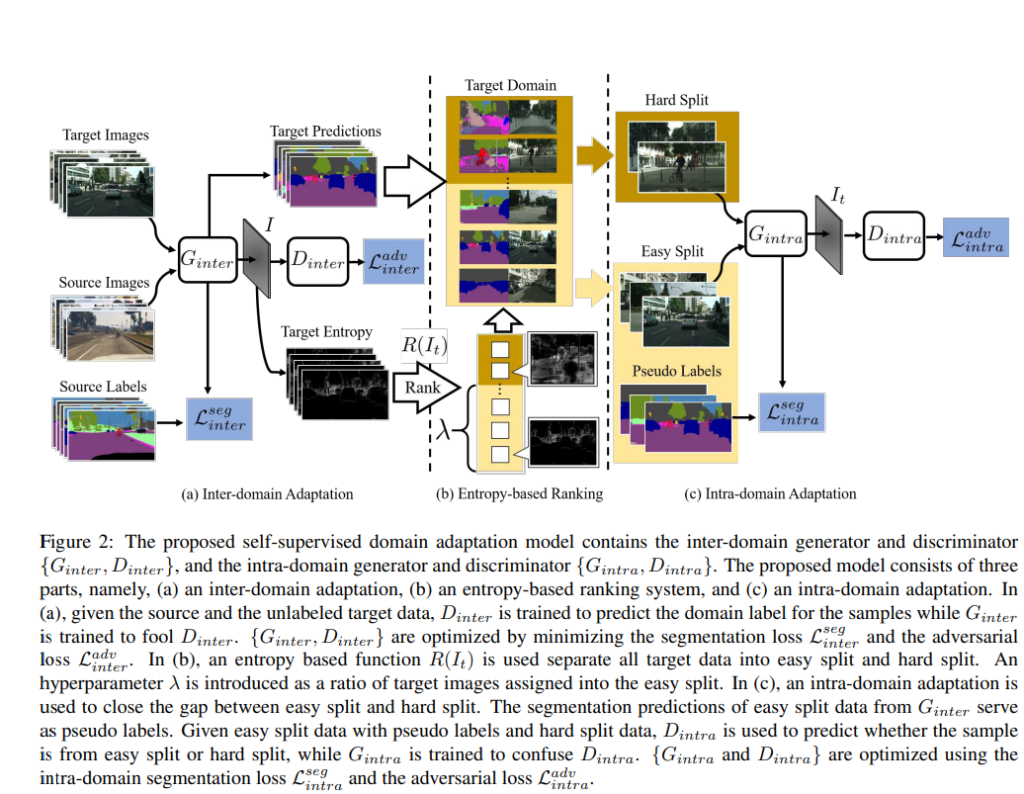
2-step self-supervised domain adaptation 방식으로, 첫번째 단계는 일반적인 Unsupervised Domain Adaptation을 이용하여 inter-domin adaptation을 수행한다. 이후 entropy-based ranking 시스템을 이용해 target 데이터를 easy와 hard로 나눈다. 두번째 단계는 hard분할에 pseudo label을 이용하여 easy 분할과 align되도록 하는 intra-domain adaptation이다.
구조는 그림2에서 확인할 수 있듯이, inter-domain generator →discriminator(inter) → intra-domain generator → discriminator(intra)로 구성되어있다. 순서대로 설명이 되어있다.
1. Inter-domain Adaptation
source domain의 샘플 X_{s}에 대해 라벨 정보를 포함하는 Y_{s}이 있다. G_{inter}는 X_{s}를 입력으로 하고 soft-segmentation map, P_{s}를 생성하는 네트워크이다. G_{inter}를 학습하기 위해 다음식으로 loss를 계산한다.
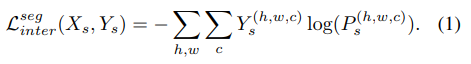
source와 target 도메인간의 차이를 줄이기 위해 Advent 방식으로 feature 의 분포 align을 맞춰준다. Advent 방식은 학습에 사용한 target 도메인과 유사한 이미지에 low entropy를 갖고, source 도메인과 유사한 경우 high entropy를 갖는다는 추정이 있다.
** Advent: Adversarial entropy minimization for domain adaptation in semantic segmentation
target 이미지, X_{t}가 입력으로 들어갔을 때 G_{inter}의 출력은 segmentation map P_{t}가 되고, entropy map I_{t}는 다음식으로 정의할 수 있다.
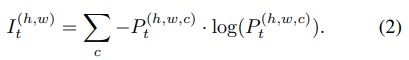
inter-domain gap을 줄이기 위해, D_{inter}는 I_{t}의 라벨을 예측하도록 학습되며, G_{inter}는 D_{inter}를 속이도록 학습된다. 이때, 두 네트워크는 다음 식으로 최적화된다.
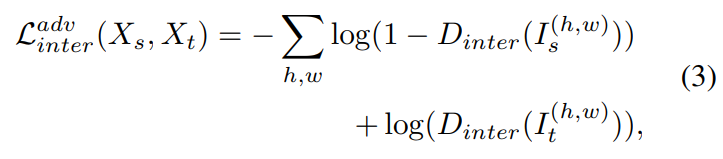
** I_{s}는 X_{s}의 entropy map
\mathcal{L}^{seg}{inter}와\mathcal{L}^{adv}{inter}는 source와 doamin의 차이를 줄이기 위해 학습된다.
2. Entropy-based Ranking
real world에서 수집된 target 이미지들은 다양한 분포를 가지고 있다. target 이미지는 clean하거나 noisy한 predict map을 만들 수 있으며, 이는 intra-domain gop이 존재하기 때문이다. 이를 해결하기 위해, target 도메인을 하위 도메인으로 나눈다. 그러나, target 라벨이 부족하기 때문에 entropy map을 통해 target의 예측 신뢰도를 결정하여 하위 도메인으로 분할한다. target 이미지에 대한 entropy map I_{t}의 평균을 구해 순위를 매긴다. λ 는 (easy 도메인으로 분할된 이미지 수)/(전체 target 이미지셋의 개수)로 정의된 하이퍼파라미터이다.
3. Intra-domain Adaptation
G_{inter}에서 예측한 결과를 pseudo label로 하여, easy 분할과 hard 분할의 alignment를 맞춘다. easy split으로부터 이미지 X_{te}를 G_{inter}에 넣어 예측 맵인 soft-segmentation map, P_{te}를 얻는다. 이후 one-hot-vector로 바꿔\mathcal{P}{te}로 변환한다. G{intra}는 pseudo label을 이용하여 다음의 cross-entropy loss 이용해 최적화 한다.
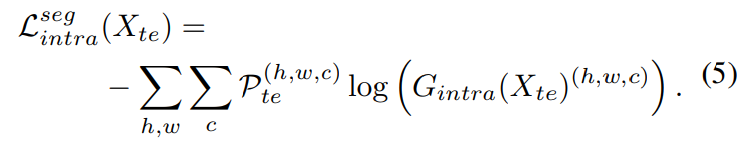
easy split과 hard split의 domain gap을 줄이기 위해 entropy map의 align을 맞춰준다. intra-domain discriminator D_{intra}는 두 splint의 label을 예측하기 위해 학습된다. 또한 G_{intra}는 D_{intra}를 속이도록 학습된다.
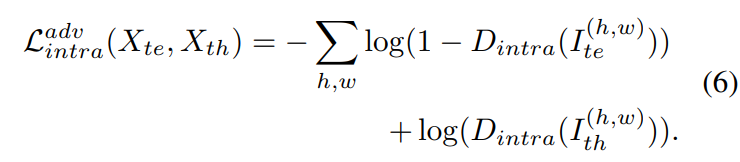
loss 함수는 다음 식으로 구할 수 있다.
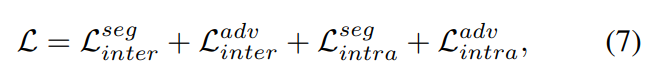
이때, \mathcal{L}를 최소화 하기 위해 G_{inter}와 D_{inter}를 최적화 하고, G_{inter}를 이용하여 pseudo label을 만들고 entropy map의 평균을 이용해 target 도메인의 순위를 매긴다. 마지막으로 G_{intra}와 D_{intra}의 최적화를 한다.
Experiments
Dataset
- 합성 데이터인 GTA5, SYNTIA, Synscapes를 source 도메인으로, real 데이터인 Cityscapes를 target 도메인으로 이용
- GTA5: 비디오 게임으로부터 수집한 LA 도시 urban 환경 데이터셋. 19카테고리 이용
- SYNTHIA(SYNTHIA-RAND-CITYSCAPES) : 16카테고리 이용
- Synscapes: photorealistic 합성 데이터셋. 19 카테고리 이용
- Cityscapes: real-world에서 촬영된 데이터셋
- IoU(= TP/(TP+FP+FN))를 성능지표로 사용
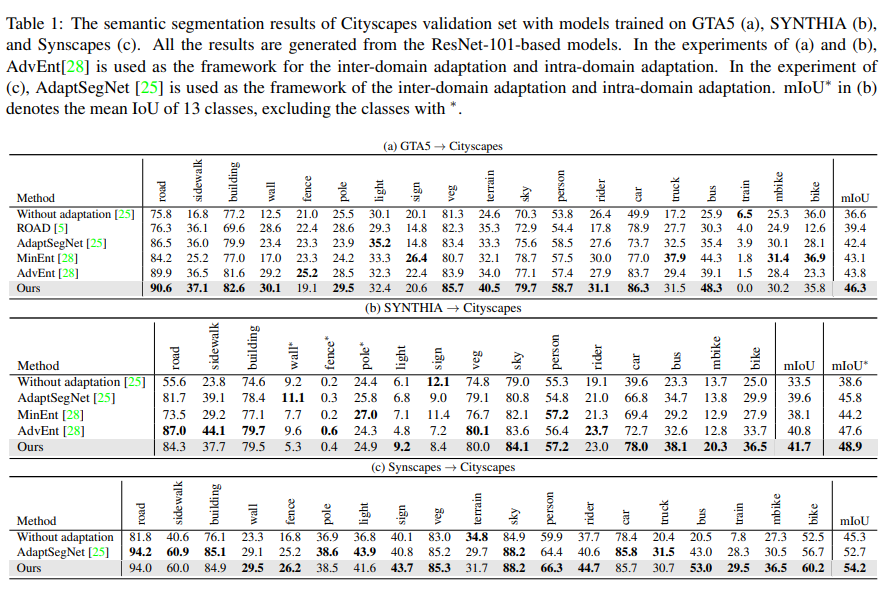
합성 데이터 -> Real 데이터 실험 결과
최적의 λ값 찾는 실험
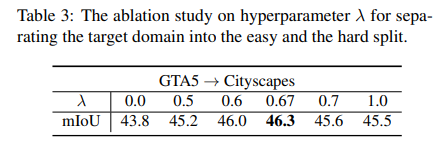
GTA5->Cityscapes의 경우 easy 도메인과 hard 도메인을 나눌 때 λ=0.67에서 가장 좋은 성능을 보였다.
intra-domain adpatation의 효과 확인

pseudo label + self-training을 적용한 경우 성능은 tabel1에서 확인할 수 있듯이 46.3%로, self-training방식만을 활용했을 때 보다 좋은 성능을 나타낸다.
source와 target 도메인의 gap 뿐만 아니라, target 도메인 내의 gap도 줄여 합성데이터로 학습한 모델을 real 데이터에 대한 segmentation을 하기 위해 domain adaptation을 수행한다.

intra-domain adaptation을 적용했을 때와 적용하지 않았을 때의 정성적 결과 비교.

hard split에 해당하는 이미지들의 entropy map과 intra-domain adaptation의 적용 유무에 따른 정성적 결과.
hard split의 경우 기존 방식을 적용했을 때, noisy map을 생성하는 것을 확인할 수 있다.
이 경우 다른 이미지들의 GT가 어떻게 되는 지 확인하기 어려워 본 논문의 방식이 정말로 잘 찾은 것이지, 확인하기 어렵다. noisy한 결과는 첫번째 행을 제외하고 나머지 정성적 결과는 여전히 noisy해보인다..
해당 논문에서 엔트로피 랭킹의 신뢰도가 굉장히 중요해보이네요.
아마 저자도 이를 인지하고 신뢰도를 입증하기 위해서 정성/정량적 실험을 진행했을 거라고 추측됩니다.
혹시 있다면 추가 설명 부탁드립니다.
없다면 이를 입증하기 위한 부연 설명이 있을텐데 이에 대한 설명 부탁드립니다.
해당 방법론에서 엔트로피 랭킹의 신뢰도를 입증하기 위한 정성적/정량적 실험보다도,
엔트로피 랭킹을 통해 intra-domain adaptation을 수행하는 것이 중요하다는 점을 강조하기 위해, intra-domain adaptation의 유무에 다른 정량적, 정성적 실험이 수행되었습니다. 이에 대한 표와 그림을 제가 누락하여 다시 첨부하였습니다. tabel 2와 figure 3,4를 통해 intra-domain adaptation의 효과를 확인하실 수 있습니다.
리뷰 잘 읽었습니다. 궁금한점이 있어 질문 남깁니다.
2. 부분에서, entropy map 을 이용하여 어떻게 순위가 정해지나요? 또한 신뢰도 점수를 기준으로 하위도메인을 어떻게 결정한다는 것인지도 궁금합니다.
entropy map의 평균값(모든 픽셀값을 다 더한다음 픽셀 수만큼 나눕니다.)으로 score를 구한 다음 큰 값 부터 정렬합니다. 이렇게 정렬한 다음, λ(이 값은 실험적으로 결정됩니다)비율만큼 나눠 hard split과 easy split으로 나눕니다.