

Action Recognition을 위해, person과 object 간의 interaction과 관련된 논문을 찾아보던 중, Human-Object Interaction (HOI)라는 분야를 알게되어 관련 논문을 리뷰하고자합니다. Action Recognition 분야에서는 현재 scene bias한 데이터 셋들 내에서 모델이 motion에만 초점을 맞출 수 있도록 설계된 방법론들이 한 축을 이루고 있습니다.
한 연구[1]는 프레임 내 local한 영역마다 서로 다른 변환을 주지만 프레임 간의 변환은 동일하게 적용시켜 scene 내의 연관관계는 줄이되 motion 정보는 유지시키는 방식을 도입하였습니다. 또 다른 연구[2]는 optical flow를 통해 motion map을 계산한 뒤, 입력단에서와 feature map으로부터 계산된 gradient map에서 motion map으로 attention을 줌으로써 모델이 motion에만 집중하도록 설계하였습니다.
분명히, 모델에게 motion 정보에만 초점을 두게하는 것은 상당히 효과적이었습니다. 이처럼 모델이 motion에만 집중하는 것에는 성공하였으나, 이 같은 모델로 실험해본 결과 모델이 너무 motion 정보에만 치우쳐저 false positive를 발생시킨다는 단점을 보였습니다.
예를 들어, 한 선수가 제자리에서 돌다가 해머를 던지는 “해머 던지기” 라는 action class를 가지고 있는 비디오의 경우, 모델이 회전하는 선수에만 bias되어 “원반 던지기” 라는 action class로 잘못 예측하였습니다. 또 다른 예시로, “양치하기” 라는 action class의 비디오는 입 주변에서 손이 움직이는 motion으로 인해 “립스틱 바르기”라는 class로 잘못 예측되었습니다.
이와 같은 motion bias한 상황을 대처하기 위해 고민을 해본 결과, 모델에게 motion 뿐만 아니라 인접한 object와의 연관 관계도 알려주어야 한다는 결론을 내리게 되었고, 최종적으로는 HOI task에 도달하게 되었습니다. 그리고, HOI task에서 많이 쓰이는 데이터 셋 HICO-DET의 현재 SOTA인 방법론 QAHOI라는 방법론을 읽게 되었고 리뷰하고자 합니다.
1. Method
1.1 Overview
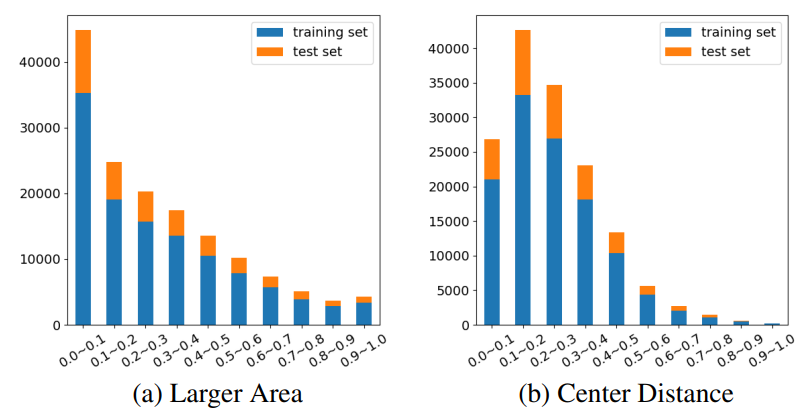
HICO-DET dataset
HOI task는 각 이미지마다 object 간의 연관 관계를 classification하고 이미지 상의 그 위치를 localization 하는 task로, 방법론의 구조에 따라 Two-stage와 One-stage로 나뉩니다.
그 중 먼저 연구된 Two-stage 방법론은 주로 Faster-RCNN을 통해 이미지 내의 object를 찾은 뒤 object 별 feature를 기술하여 연관관계를 탐색하게 됩니다. 하지만, 이 방식은 두 단계를 거치기 때문에 꽤나 시간이 걸리며, object 에 해당하는 bounding box에서만 feature를 기술하기 때문에 서로 멀리 떨어져 있는 object들 간의 contextual한 정보가 부족하다는 단점이 존재합니다.
Two-stage 방법론의 이러한 단점을 해결하기 위해, object를 찾고 object들 간의 연관관계 인식을 동시에 하는 One-stage 기반 방법론들이 등장하였습니다. 이를 통해, Two-stage에서 발생하는 시간 문제에 대해서는 어느정도 해결하였으나, 여전히 멀리 떨어져 있는 object들 간의 연관 관계를 기술한 semantic feature는 모호했고, multi-scale을 고려한 모델이 없어서 object scale에 강인하지 못하였습니다.
실제로 Fig 2의 (a)는 HOI task에서 자주 쓰이는 데이터 셋 HICO-DET내에 존재하는 object의 크기를 나타냅니다. 전체 이미지 크기의 10퍼센트 미만인 object 비율이 높은 경향을 보이며 이러한 이유로 multi-scale을 고려한 모델 설계가 필요해집니다. 뿐만 아니라, Fig 2의 (b)는 같은 데이터 셋에서 object 간의 거리를 나타낸 것이며, 대부분은 이미지 전체 크기 대비 30% 미만의 거리로 근접하게 위치하여 있으나, 거리가 30% 초과인 경우도 꽤나 많습니다. 이때문에 이미지 내 local한 영역 뿐만 아니라 global한 영역으로의 연산도 필요해집니다.
본 논문에 저자는 이와 같은 두가지 문제를 Object Detection 분야에서 제안된 deformable transformer 구조인 Deformable DETR을 통해 해결하고자 하였습니다.
1.2 Multi-Scale Feature Extractor
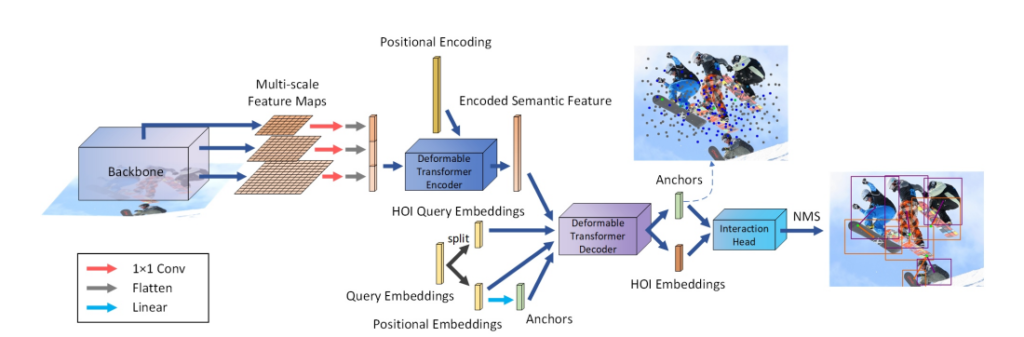
기존 One-stage 방법론들은 transformer구조를 활용한다고 하더라도, 입력으로 들어오는 이미지를 CNN을 통해 feature로 변환 시키는 과정을 거의 고정적으로 가지고 있었습니다. 그러나, CNN의 경우 locality한 속성을 가지고 있기 때문에, non-local한 연관관계를 잘 표현하지 못합니다. 또한, receptive field가 큰 low-resolution의 feature만을 사용하기 때문에, 작은 크기의 object를 무시하기 쉽다는 특징도 가지고 있습니다. 이를 해결하고자 backbone network에서 multi-scale feature를 추출하고 Deformable DETR의 transformer encoder를 활용하였습니다.
먼저, 이미지를 backbone network 입력으로 두고, 마지막 세 stage에서 각각 feature map x_1, x_2, x_3를 추출합니다. 그리고 세 feature map에 1×1 convolution을 적용해 C_d 차원으로 projection한 뒤, flatten 및 concat하여 N_s \times C_d 크기로 만들고 이를 deformable transformer encoder의 입력으로 사용합니다. 이때, N_s는 세 feature map의 모든 픽셀 수를 의미합니다. 이와 같은 입력을 feature의 scale level에 대한 positional encoding과 함께 encoder로 넣어 semantic feature S를 추출하고, 이를 통해 HOI instance를 알아내기 위해 deformable transform decoder의 입력으로 주게 됩니다.
1.3 Predicting HOI with Query-Based Anchors
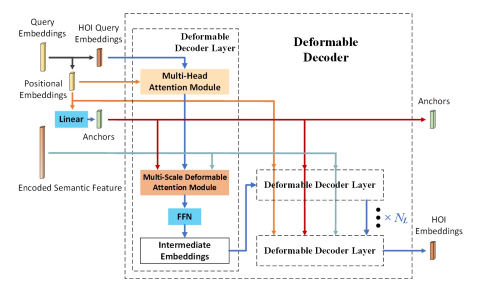
decoder.
앞서 encoder를 통해 얻은 semantic feature S를 deformabale DETR과 같은 방식으로 decode합니다. Fig 4의 과정처럼, query embedding을 각각 HOI query embedding과 positional embedding으로 나누고, Linear layer를 통해 후자를 anchor로 변환합니다. 또한, HOI query embedding은 Multi-Head Attention 과정을 거치고 anchor 및 semantic feature S와 함께 Multi-Scale Deformable Attention Module을 거칩니다. 여기서 나온 output은 linear layer로 구성된 Feed-forward Network를 거친 뒤, 다른 feature 들과 함께 Stacked Deformable Decoder Layer를 거치고 최종적인 HOI embedding 생성합니다.
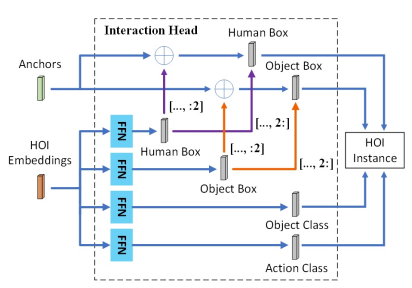
이렇게 생성된 HOI embedding과 이전 생성된 anchor를 각각 입력으로 두고 Fig 5와 같은 interaction head 과정을 수행합니다. 이는 이전 HOI 분야의 One-stage 방법론 QPIC과 유사하며, 각 HOI embeding마다 한 anchor를 쓰는 차이만 존재합니다. Interaction head에서는 human과 object에 대한 bounding box, Object에 대한 class 그리고 human과 object 사이에서 발생한 action class를 예측하며 이 값을 종합하여 HOI instance를 예측합니다. 추가적으로 QPIC과 유사한 방법론은 사용한만큼, 같은 방식의 loss로 학습됩니다.
2. Experiments
2.1 Comparison with State-of-the-Arts
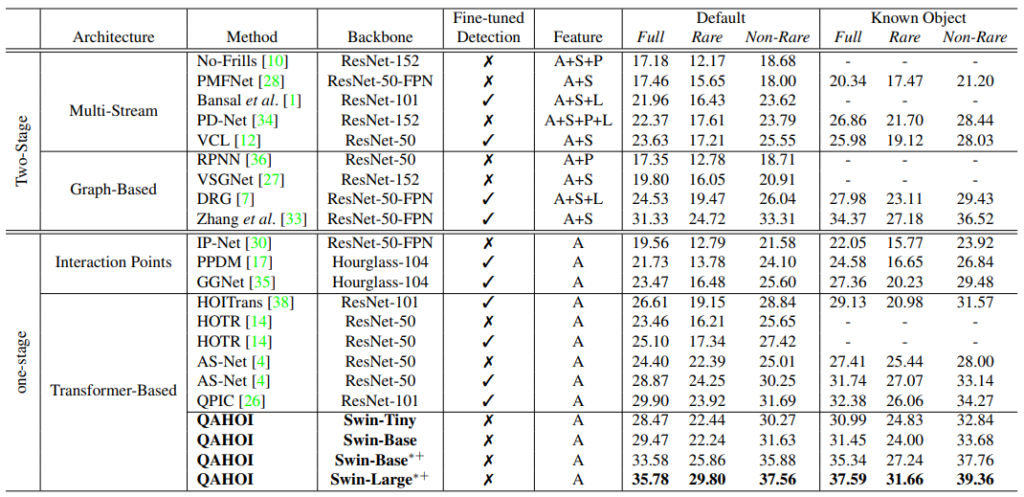
Table 1은 제안된 QAHOI의 benchmark를 나타냅니다. Feature column에서 A는 이미지를 통해 얻은 feature인 appearance feature를 나타내고, S는 사람의 골격 정보를 입력으로 얻은 spatial feature를 의미합니다. 그리고 P는 human pose로부터 얻은 human pose feature를 나타내며, L은 language feature를 의미합니다. 평가지표는 object detection과 같은 mAP를 활용하며, human-object 간의 class를 맞추고 (ex: talk on phone) 그 class에 속하는 human과 object를 IoU 0.5이상으로 예측할 때 TP로 판단합니다. 또한 Full, Rare, Non-Rare와 Known Object는 HICO-DET 데이터 셋에서 object에 따라 나눈 기준입니다. 이러한 지표하에 제안된 방식이 SOTA를 달성하긴하였으나, Backbone network인 Swin transformer의 버전에 따라 성능차이가 많이 나는 특이점을 보입니다. 이는 task가 유사하기에 classification task에서 보였던 성능과 상관관계가 있기 때문이라고 합니다.
2.2 Qualitative Analysis
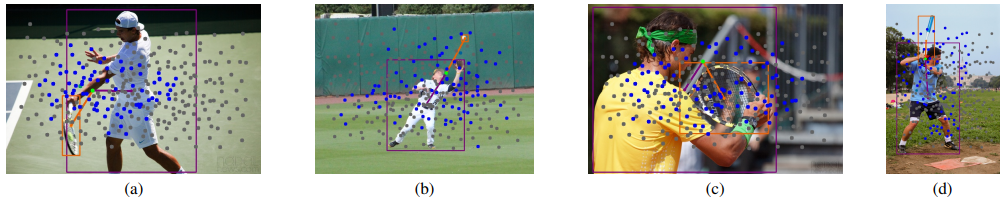
Fig 6은 QAHOI의 정성적 결과 입니다. 여기서 파란색 점은 Deformable DETR에서와 같이 이미지 내에서 object score가 높은 top 100개의 anchor를 나타내며 회색점은 선택되지 않은 anchor를 나타냅니다. 또한 초록색 점은 HOI instance를 예측할 때, 가장 높은 action score를 나타낸 anchor를 의미합니다. 실제로 각 object를 잘 detect하는 것 뿐만 아니라, 두 object간의 interaction으로 action이 발생하는 위치를 어느정도 잘 맞추는 것을 알 수 있습니다.
3. Reference
[1] https://arxiv.org/pdf/2112.08647v1.pdf
한국컴퓨터비전학회 교육때 들었던 Human-Object Interaction Detection이 이렇게 연결되는걸 보니 신기하네요. 제가 알기로는 이 분야가 사람-행동-물체 순으로 연결되어 있는데, Action분야는 맨몸으로 하는 행동들이 꽤 있어서 오히려 이런 분야에서 모호함이 생겨서 성능에 문제가 생기지 않을까요? 혹시 이런 부분도 고민해보셨는지 의견이 궁금합니다.
현재 생각하고 있는 방식으로는 detection을 한 뒤 non-person object와 person간의 interaction하는 것이 있습니다. 맨몸운동의 경우 object가 없거나 혹은 person과 꽤 거리가 있는 위치에 존재하기 때문에, person-object 거리에 따른 가중치로 interaction을 준다면 어느정도 해결되지 않을까 싶습니다. 물론 이미지 상에서는 가까워 보이지만 depth가 달라 실제 3D 상에서는 멀리 떨어져 있는 person-object 간의 interaction은 따로 고민해봐야겠지만요
안녕하세요 좋은 리뷰 감사드립니다.
질문이 하나 있습니다
예시에서 설명해주신 원반 던지기와 헤머 던지기를 분류할 때 object의 관계 뿐만 아니리 배경과 같은 정보도 이용할 수 있을 것 같습니다. 혹시 해당 예시에서 예측 오류를 발생한 이유가 원반 던지기에 주로 해당하는 배경에서 해머 던지기를 진행하여 발생한 문제인가요?
해머와 원빈이라는 object를 인식하지 않아서 발생한 문제인지 궁금합니다.
action 인식 중에 context 정보에 치중되지 않고 action 정보만을 파악하기 위한 연구도 소개해주셨었는데, object 정보를 이용하는것은 context 정보에 오히려 치중되게 하는 결과를 가져올 수도 있지 않을까 궁금합니다.
장면 정보의 경우 motion과 관련된 장면도 있지만 관련이 없는 장면(ex: 골프장에서 푸쉬업)도 있기 때문에 요즘 action recognition 분야에서는 scene bias되지 않게 모델을 설계해야한다는 추세 입니다. 이러한 추세로 어느정도 motion에 대한 모델링이 되어가고 있는데, motion에만 집중한 나머지 fine-grained한 motion을 못찾는 것을 확인하였습니다. (원반 던지기 vs 해머던지기)
때문에 person-object 간의 interaction을 활용해야하지 않을까 싶어 읽게된 논문입니다.
그리고 object 중 person unrelated object는 context 정보에 치중되게 하는 distractor로 작용할 수 있으나 person related object의 경우 fine-grained한 motion을 판단하는데에 도움을 준다고 생각합니다. 물론 이를 구별하는 것도 하나의 연구이슈가 되겠습니다.