CVPR 제출논문을 RAL로 변경하고 있는 요즘…. Reference걸어야 될 거 같은 논문을 찾아다니고 있던 중 저의 심기를 건드는 논문이 등장해서 소개드리고자 합니다. 사실 이런 논문은 리뷰를 하지 않지만 .. 소개드리는게 맞나 싶지만…. 제목부터 저의 심기를 매우 건든 논문이며 이렇게 논문은 쓰지 말자는 차원에서 소개드리고자 합니다.
이 논문은 일단 제가 알고 있는 한 Transformer를 Self-supervised monocular depth estimation에 처음 적용한 논문이며 적용을 제대로 못한것 같은데 논문이 된 케이스입니다. 적용할거면 제대로 적용해서 옳은 방향성을 제시하던가… 제대로된 방법을 제시하지 않고… 단순히 적용만해서 “Transformer 처음 적용” 타이틀을 뺏어가니 마음이 살짝 아프네요 ㅠㅠ
그럼 이 논문이 어떤 말도안되는 Contribution을 통해 Transformer를 Self-supervised를 적용했는데 제가 이렇게 짜증내고 화나는지 알아보도록 하겠습니다.
Contribution
먼저 Contribution을 설명하도록 하겠습니다. 사실 이게 Contribution이라하는게 맞는지 모르겠습니다만 설명하자면 다음과 같습니다.
- vision transformer를 Self-supervised monocular depth estimation에 적용하는 방식을 제안한다.
- 제안한 방법론과 기존 CNN 과 성능 비교한다. natural corrutiopn 과 adverarial attack 방법을 이용해서 Transformer network를 평가한다.
- intrinsic parameter 또한 예측하는 네트워크를 제안함
- intrinsic parameter 예측 성능에 따른 depth 성능을 리포팅함
- 네트워크 속도를 평가함
흠… 이 논문에서 괜찮게(?) 본 부분은 Intrinsic parameter를 예측하며 학습하는 방식과 분석 방식이 기존 방식과 더불어 추가된 방법을 썼다는 것 정도인 것 같습니다만 방법론이 너무 간단하고 가져다 써서… 마음에 들지 않지만 뭐 발표된 학회의 수준을 생각하면 봐줄 수도 있는 부분인거 같기도합니다.
Method
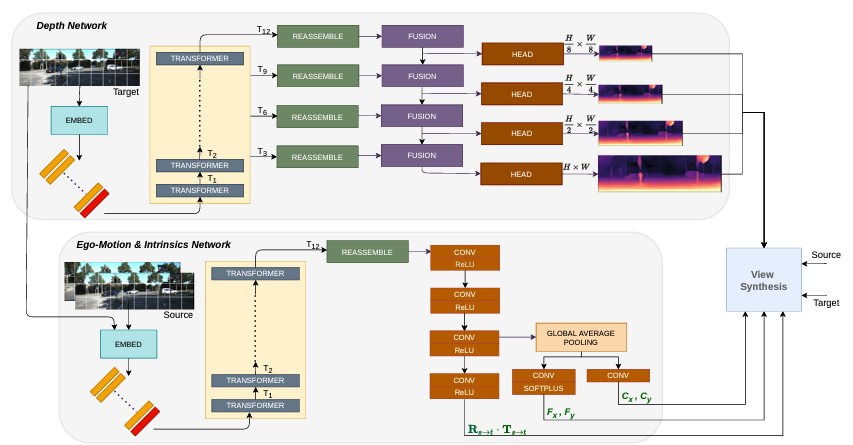
이 논문에서 제안한 아키택쳐는 그림 1과 같습니다. 본 아키택쳐는 Supervised depth estimation 에 Transformer를 적용하는 방법론을 처음제안한 DPT[1]를 그대로 사용하며, 기존 DPT는 Singlescale 로 loss를 계산하지만 이 논문에서는 Self-supervised depth estimation 의 다른 방법론들 처럼 Multi scale로 loss를 계산할 수 있도록 아키택쳐를 설계했습니다. 또한 Posenet도 DPT를 변형해서 그림 1 아래와 같이 구성해서 제안했습니다. 이 PoseNet에서 주목해야할 부분은 intrinsic parameter인 focal length와 principal point를 예측하는 것입니다. Photometric loss를 위해 source image를 target image로 바꾸는 과정에는 각 카메라의 intrinsic parameter가 필요해서 실제 카메라의 intrinsic parameter를 사용하지만 intrinsic parameter를 모르는 상황에서는 depth estimation을 할 수 없고 모델을 할 수도 없다는 단점이 있기 떄문에 이논문에서는 intricparater를 같이 예측할 수 있도록 제안했습니다.
하지만 이렇게 intrinsic parameter를 같이 예측하는 방식은 Depth from video in the wild [2] 에서 먼저 제안되었으며 단순히 transformer에 적용하는 방식을 제안하는것에 contribution이 있다고 보면 됩니다.
method는 이게 끝…입니다. 뭐 따로 추가적으로 제안한게 없으며 이제 분석이 남은 내용이 다 차지 합니다.
Result
이 논문에서는 Deit를 transformer encoder로 사용했으며 그걸 이용한 이유에 대해서는 나와 있지 않습니다.
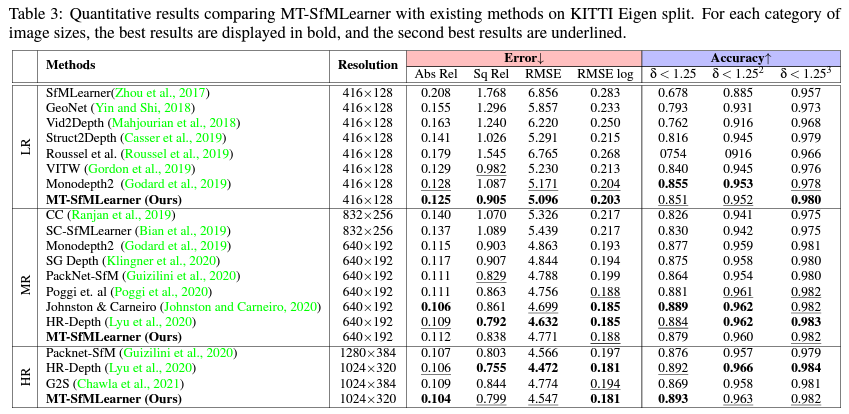
먼저 가장 대중적인 성능평가 데이터 셋인 KITTI 에서의 정량적 평가입니다. 해상도에 따라서 성능을 리포팅했으며 리포팅한 성능이 사실 너무 좋지 않아서 이걸 왜 리포팅했는지 모르겠습니다. LR에서는 다른 논문보단 좋아보지만 비교 방법론이 굉장히 오래된 (?) 것들이라 이 성능을 통해서 이 논문이 제안한 방법론이 좋다!! 라고 볼 수 없습니다. 그리고 Self-supervised depth estimation 방법론들은 MR 에서의 성능을 기본으로 보며 여기서의 성능이 가장 중요하다고 할 수 있습니다만 여기서의 성능이 매우 좋지 않은 것을 볼 수 있습니다. 따라서 …. 이 논문은 어떠한 장점이 있을까… 싶습니다 또한 HR도 리포팅했는데 기존 다른 방법론들은 리포팅하지 않아서 비교를 위해 만들어낸 성능이 아닌가… 싶습니다. 이래서 성능 리포팅할때는 서베이를 제대로해야한다 생각합니다. 아니면 정말 서베이를 제대로했는데 리포팅하면 성능이 SOTA가 아니라서 리포팅하지 않았나…라는 생각도 킹리적갓심인 것 같습니다.
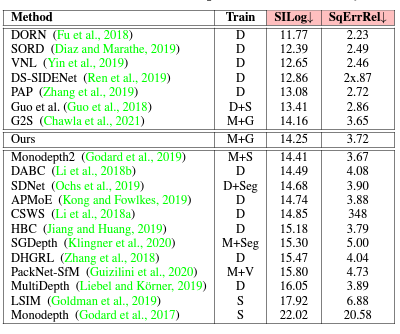
다음으로 KITTI benchmark 성능인데 이것또한 G2S 조차 이기지도 못했는데 왜 리포팅했나 싶습니다. 심지어 이 G2S 의 저자랑 이논문의 저자랑 동일한데 저걸 이기는게 중요하다는 생각을 못한건가 아니면 그냥 학회 수준이 낮아서 그냥 낸건가 궁금한 부분입니다.
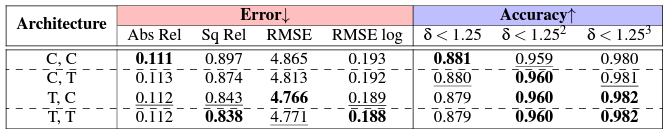
이 ablation study는 궁금했던 부분이라 괜찮았습니다. 이 실험은 (depth estimatimator, posenet) 조합실험이며 C=CNN T=transformer 입니다. 그렇지만 이 조합실험으로 좋은 정보를 얻을 수는 없었습니다. 성능 향상 폭이 너무 minor 해서 정말 Transformer network 가 좋다 할 수 있는지는 확실치 못한 것 같습니다.

정성적 결과를 통해서도 보여주는데 이것 또한 너무 minor한 결과를 보여줘서 좋은 결과라 생각할 수는 없는 것 같습니다.
아래 세개의 성능 평가는 기존에는 하지 않는 평가 방식인데 생각보다 나쁘지 않은 분석 방식인 거 같습니다. 그렇지만 이 논문에서는 단순히 수치만 보여주고 이게 왜 좋은지에 대한 추측조차 없는게 아쉬운 부분인 것 같습니다.
먼저 natural corruptions 에 대한 robustness를 보여줍니다. 이 평가는 아래 사진과 같이 입력 영상에 다양한 augmentation을 적용했을때 성능 drop이 얼마나 되는지에 대한 결과입니다.

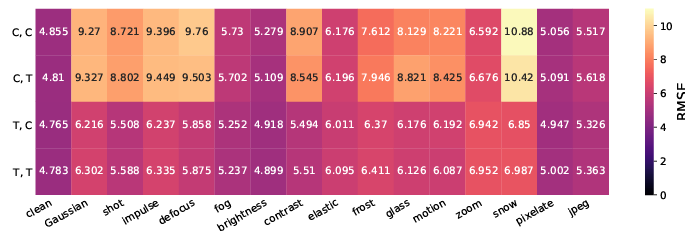
transformer를 사용했을때 입력에 대한 robustness가 생긴다는게 참 신기한 분석인 것 같습니다. 오히려 영상 전체를 보기때문에 입력 영상에 영향을 많이 받을 것 같다고 기존에 전 생각하고 있었는데 그 생각이 깨진 분석인 것 입니다.
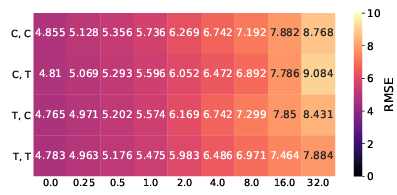
다음은 adverial attack 에 대해서 얼만큼의 성능 drop 이 있는냐에 대한 결과 입니다. 보면 이 결과는 딱히 Transformer의 장점을 볼 수 없는것 같습니다.

아래 평가는 [3]에서 제안된 monocular depth 전용으로 제안된 adverial attack 방법론에 대한 결과입니다.

총 세개의 robustness 결과를 이용해서 transformer를 이용하는게 robustness를 강화한다고 증명했습니다.

다음으로 intrinsic parameter에 대한 결과입니다. intrinsic parameter를 학습하는게 당연히 성능이 떨어지지만 그래도 성능 drop이 그렇게 크지 않거나 오히려 transformer based 에서는 성능 향상이 있는것을 볼 수 있습니다. 이것에 대한 이유는 사실 모르겠습니다. 그리고 Given 성능이 별로라서 이 방법론이 intrinsicparameter를 학습하기 때문에 성능이 안좋은게 아니구나….그냥 안좋은거구나…를 더욱 확신하게 됐습니다.
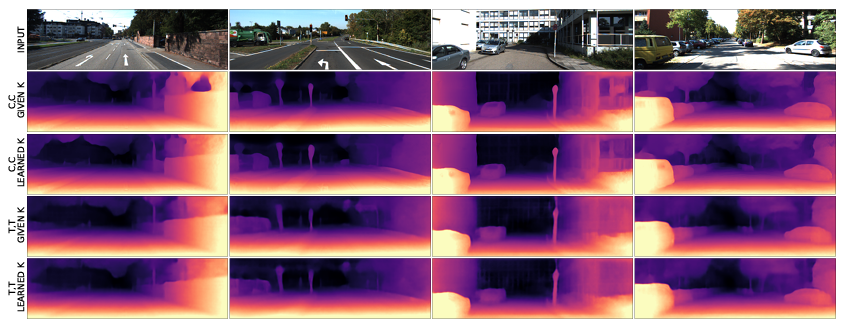
정성적 결과인데 다들 유사한것을 볼 수 있습니다.
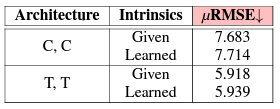
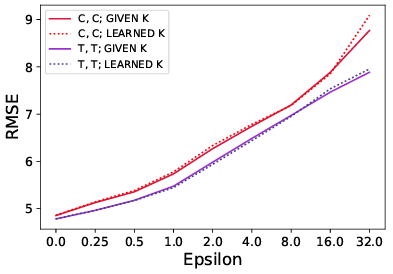
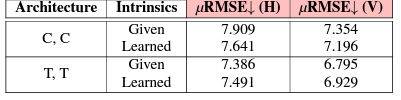
위 세개 평가는 robustness 평가 세개에 대한 결과입니다. 이를 통해서 intrinsic parameter를 학습해도 transformer는 robustness를 가진다는 것을 보여준다는데 이 주장은 동의하지 못할 것 같습니다.
Reference
[1] Vision Transformers for Dense Prediction
[2] Depth from Video in the Wild: Unsupervised Monocular Depth Learning from Unknown Cameras
[3] Targeted Adversarial Perturbations for Monocular Depth Prediction
———————-
흠….. 분석 중에서 [3]은 한번 읽어보고 써볼 수 있나 봐야할 것 같습니다.