Before Review
이번 논문은 Action Recognition 진영에서 가장 흔하게 사용되는 Backbone Network를 준비했습니다.
본 논문에서 제안된 I3D라는 Backbone Network는 Temporal Action Localization 진영에서도 가장 많이 사용되는 Backbone Network로 이번 기회에 다시 한번 제대로 공부해보고자 읽게 되었습니다.
Temporal Action Localization에 관한 다양한 실험을 돌리기 위해서는 I3D feature부터 제대로 뽑아야 하는데 이 Network에 대한 이해 없이 Code만 무작정 돌리기는 아닌 것 같아 이번에 리뷰하게 되었습니다.
리뷰 시작하도록 하겠습니다.
Introduction
Fei Fei Li 교수님 연구진들이 구축한 대용량 이미지 데이터셋인 ImageNet은 컴퓨터비전 연구의 큰 획을 그었다고 해도 무방할 정도의 파급력을 가지고 있습니다. 딥러닝이 등장할 수 있었던 것도 이러한 대용량의 데이터셋이 없었다면 붐을 일으키기 힘들었겠죠. 본 논문이 제안된 17년 이전까지의 많은 컴퓨터 비전관련 딥러닝 연구들은 모두 이 ImageNet으로 사전학습된 Network를 이용하여 classification이나 detection , segementation 등과 같은 문제를 해결하였습니다.
즉, ImageNet으로의 사전학습은 다양한 down stream task에 대해서 좋은 성능을 보여준다는 것은 아마 모두가 안다고 생각합니다.
따라서 저자는 Video domain에서의 대용량 데이터셋이 있다면 동일하게 사전학습을 통해 performance boosting을 얻을 수 있지 않을까라는 고민에서 본 연구를 진행하게 됩니다.
따라서 구글의 딥마인드 연구진은 Kinetics-400 이라는 데이터셋을 세상에 공개하게 됩니다. 이 Kinetics-400이라는 데이터셋은 현재 Action Recognition 진영에서 ImageNet과 같은 역할을 하고 있다 생각하면 됩니다. 대용량의 Action Recognition 데이터를 제공하며 현재는 이 데이터셋으로 사전학습된 weight들이 다양한 비디오 down stream task에 사용이 되고 있습니다.
다시 본론으로 돌아오면 본 논문에서는 새로운 대용량 데이터셋을 제공함과 동시에 이 pretrain의 효과를 극대화할 수 있는 새로운 구조를 제안하는 데요 그것이 바로 Infalted 3D Convnets(I3D)라고 하는 구조 입니다. 이 모델을 제안하면서 알아야 하는 중요한 Contribution은 ImageNet으로 학습된 2D Convolution weight들을 3D이 사용할 수 있는 구조를 제안하였다는 점 입니다.
본 논문에서 제안된 I3D에 대해서 얘기하기 전에 Action Recognition 진영에서 사용됐던 구조들을 먼저 알아보고 I3D에 대해서 알아보도록 하겠습니다.
Action Classification Architectures
ConvNet + LSTM
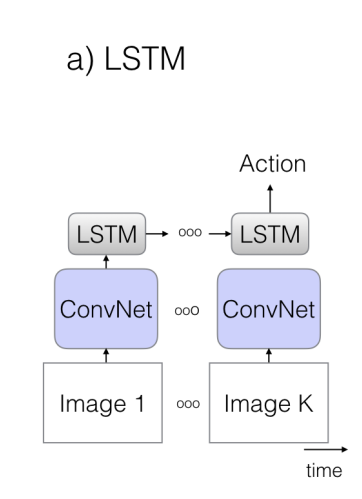
2D Convolution + LSTM을 결합한 구조 입니다. 2D Convolution을 사용하면 뭐가 좋을 까요? 우선 ImageNet Pretrain을 사용할 수 있다는 장점이 있습니다. 또한 Filter의 Parameter도 temporal dimension에 대해서는 존재하지 않으니 모델이 조금 더 가볍겠지요.
하지만 2D의 한계점은 바로 Temporal Structure를 고려할 수 없다는 점이 비디오 연구에서는 한계로 작용하게 됩니다. 그래서 이러한 점을 보완하기 위해 LSTM을 같이 사용해주는 것이라 보면 됩니다. LSTM은 가변적인 길이의 입력에 대해 state를 encode하고 temporal ordering을 할 수 있으며 Long range dependecies를 해결할 수 있습니다.
3D ConvNets
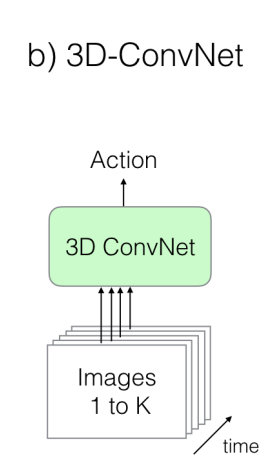
3D Convolution 입니다. 3D Convolution이 뭔지 모르시는 분들은 저의 이전 리뷰를 참고 하시면 됩니다. 핵심만 설명한다면 3D Convolution은 temporal 축에 대해서도 filtering이 진행되기 때문에 temporal한 변화에 대한 특징을 capture할 수 있기에 비디오 데이터에 적합하다고 볼 수 있습니다. 하지만 이 3D Convolution도 몇가지 한계점이 있습니다.
일단 파라미터가 많아진다는 단점이 있습니다. temporal dimension이 추가 됐으니 이건 바로 받아들일 수 있습니다. 하지만 무엇보다 critical 한 점은 ImageNet으로 사전 학습된 weight를 사용하지 못한다는 점이 있습니다. 사전 학습된 weight를 사용하지 못하다 보니, 모델을 scracth로 부터 학습을 진행해야하고 대용량 데이터셋이 아니기 때문에 모델을 깊게 쌓을 수 없었다는 점이 3D Convolution 구조의 약점으로 작용했습니다.
Two-Stream Networks
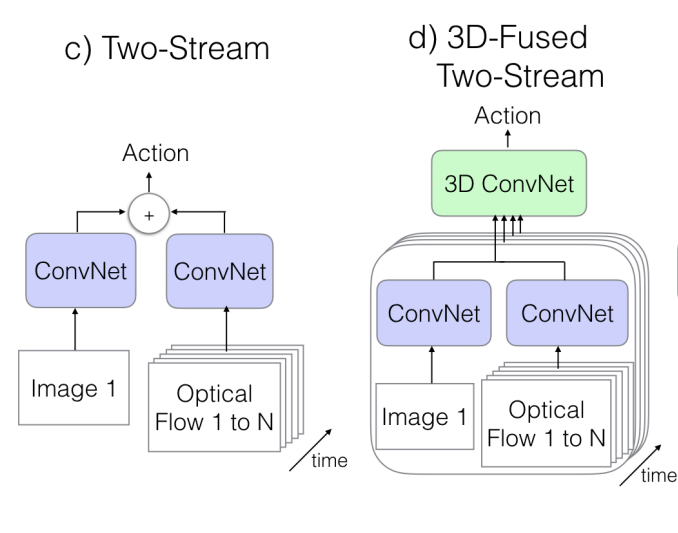
가장 처음에 알아봤던 2D Conv + LSTM 구조의 한계는 무엇이 있을 까요? LSTM은 high level의 information을 capture하는 것은 적합할 수 있어도 low level의 정보인 motion 정보를 이해하기에는 어렵다는 한계가 있습니다. 비디오에서 그 중 특히 Action Recognition을 하는 데 있어 motion 정보를 이해하지 못하면 critical한 한계점이 있다고 볼 수 있습니다.
이러한 점을 극복하기 위한 새로운 접근은 바로 Optical Flow를 이용하는 것 입니다. 제가 Optical Flow에 대해서 제대로 공부를 한 것은 아니라 자세히는 모르지만 비디오 진영에서는 Motion 정보를 넣어주기 위해 보통은 사용됩니다.
그래서 Two-Stream Network라고 해서 네트워크 구조가 동일하면서도 독립적인 두개의 Convolution Network를 이용해주게 됩니다. 제가 궁금한 부분은 Optical Flow는 2채널인 것으로 알고 있는데 ImageNet Pretrained weight를 어떤식으로 사용하는 지는 아직 잘 모르겠습니다.
아무튼 이렇게 독립적으로 forwarding을 진행 후 각 prediction을 평균내서 inference를 한다고 하네요.
Two-Stream 구조에 3D Convolution을 적용한 구조는 마지막에 단순히 평균내서 inference하는 것이 아니라 새롭게 3D Convolution과 3D pooling을 진행해서 prediction을 수행하는 구조 입니다. 두 구조의 성능은 비슷하다고 합니다.
The New : Two-Stream Inflated 3D ConvNets
드디어 저자가 새롭게 제안하는 구조 입니다. 핵심은 어떻게 해야 ImageNet으로 사전학습된 2D weight를 가져다가 사용할 수 있을지에 대한 고민이라 볼 수 있습니다. 거창한게 아니라 그냥 2D filter 동일하게 N번 중첩시켜서 사용한다고 합니다. 대신에 N번 중첩시키면서 전체 연산 결과에 대해서 N으로 나누게 된다면 기존 2D Filtering과 동일한 결과를 가지게 돼서 이렇게 해준다고 합니다.
Pooling 연산을 진행할 때는 temporal axis에 대해서는 대칭적인 구조를 꼭 사용하지는 않는다고 합니다. 이는 Frame rate와 관계가 있는 부분이기 때문에 이렇게 설계하였다고 합니다. 사실 정확히 와닿지는 않네요..ㅎㅎ
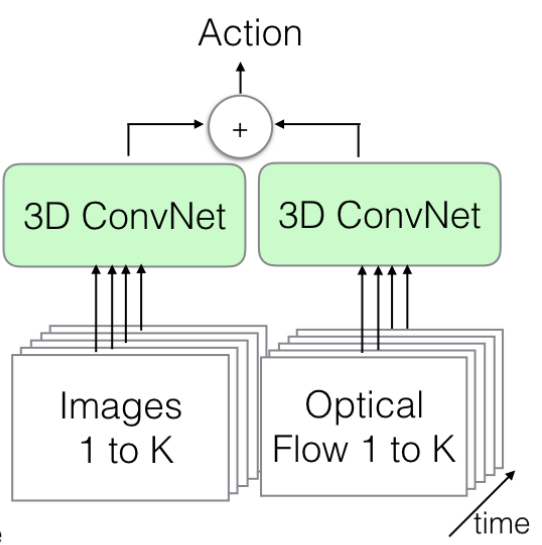
저기 보이는 이 3D ConvNet은 Inception-v1의 Filter들을 3D로 변경한 구조라고 보면 됩니다.
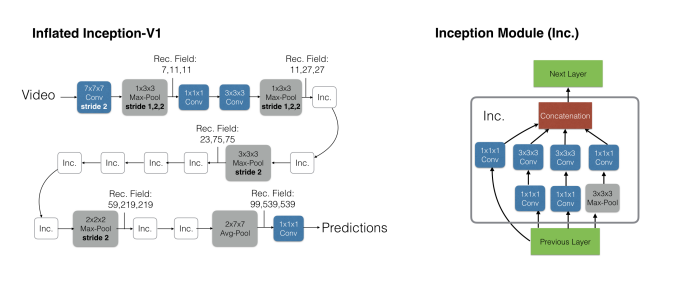
정말 2D Filter를 3D Filter로 변경시킨 것이 다라고 생각하면 됩니다.
Experiments
Experimental Comparison of Architectures
우선 위에서 살펴본 5가지의 구조에 대한 비교 실험 입니다. 데이터셋은 UCF-101, HMDB-51, Kinetics를 가지고 실험을 진행했습니다. (b) 3D-ConvNet을 제외하고는 모두 Inception-v1을 가지고 ImageNet Pretrain에 기반으로 학습이 진행되었습니다.
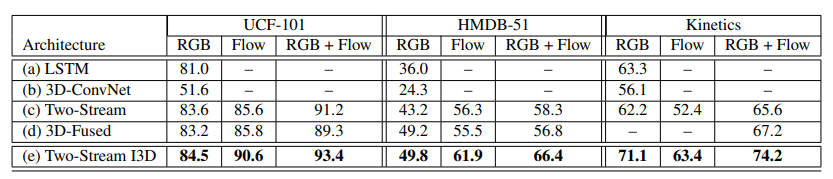
우선 흥미로운 점은 본 논문에서 제안된 Two-Stream I3D가 모든 경우 대해서 가장 성능이 높다는 점 입니다. 이를 통해 3D Convolution이라 할지라도 ImageNet pretrain의 도움을 충분히 받을 수 있다는 것을 보여준 것 같습니다. 또한 제안된 Kinetics가 UCF-101 보다 더 어려운 데이터셋임을 보여주고 있습니다. UCF-101에서는 정확도가 상대적으로 높은 반면 Kinetics에서는 정확도가 낮게 나오는 것을 확인할 수 있습니다. 그럼 HMDB-51은 뭐냐? 물어볼 수 있지만 HMDB는 데이터셋 자체가 적어서 낮게 나오는 거라고 하네요.
또 한가지 봐야할 부분은 Kinetics에서는 RGB의 성능이 오히려 더 좋게 나오고 있습니다. Kinetics 데이터셋이 camera motion이 많아서 action 자체의 motion을 capture하기가 어렵다고 합니다. 그래서 Flow의 성능이 안나오고 RGB의 성능이 더 높게 나온다고 하네요.
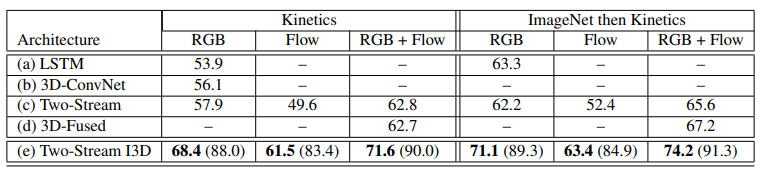
다음으로 확인해볼 실험은 Kinetics로만 사전학습 하는 것이 좋냐 아니면 ImageNet으로 사전학습 후 Kinetics로 학습 하는 것이 더 좋냐에 대한 실험입니다. 결론적으로는 ImageNet으로 사전학습 하고 Kinetics로 학습한 것이 더 높은 성능을 보여주고 있습니다. ImageNet pretrain은 비디오에서도 효과적이다라는 것을 보여주고 있습니다.
Experimental Evaluation of Features
여기서는 Kinetics로 학습된 network의 generality를 보여주기 위한 실험을 진행을 했다고 합니다. 세가지의 Case를 가지고 실험이 진행이 되었는데
- Original : Pretrain 없이 해당 데이터셋으로 finetuning
- Fixed : Kinetics로 Pretrain 후 weight를 고정시켜서 feature를 뽑은 다음 FC layer만을 학습
- Full-FT : Kinetics로 Pretrain 후 해당 데이터셋으로 finetuning
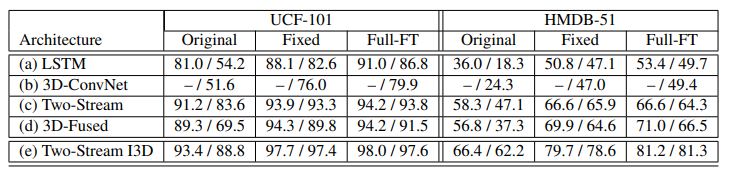
보면 알겠지만 성능이 Original < Fixed < Full-FT 순으로 높습니다. 흥미로운 것은 Fixed가 Original 보다 높다는 점입니다. 즉, Kinetics로 Pretrain한 weight만을 가지고 Feature를 추출하는 것이 좋은 Generality를 가지기 때문에 나온 결과라고 보면 됩니다. 그래서 확실히 Kinetics로 사전학습을 하는 것이 효과적이다 라는 것을 보여주는 것 같습니다.
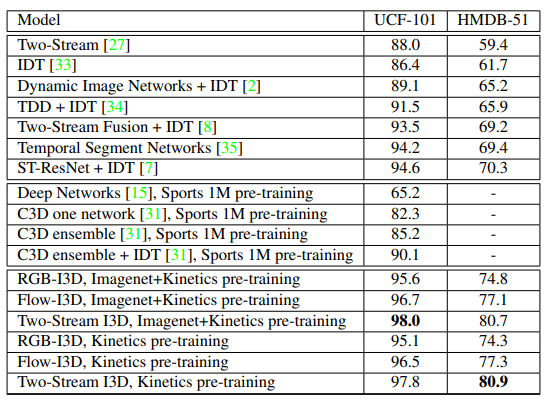
기존의 방법론들과의 비교 테이블 입니다. I3D가 Kinetics 나 ImaegNet 사전학습을 이용하면 SOTA의 성능을 달성하는 것을 보여주고 있습니다. 다만, 다른 방법론들은 Kinetics 사전학습이 아니기 때문에 완벽한 비교는 어렵다고 볼 수 있습니다.
Conclusion
사실 I3D는 이전에 코드만 가지고 몇 번 사용했던 경험은 있지만, 논문에 대한 이해 없이 사용하려다 보니, 찝찝한 구석이 있었습니다. 본 논문에서 언급된 Kinetics 데이터셋은 이 I3D 논문 말고도 다른 paper에 좀 더 자세히 다루긴 하지만 딥 마인드가 공개한 Kinetics 덕분에 비디오 연구에도 큰 동력이 생기지 않았나 싶습니다.
Action Recognition Paper도 종종 읽어서 Backbone에 대한 감을 잃지 않도록 해야겠습니다.
리뷰 읽어주셔서 감사합니다.
좋은 리뷰 감사합니다.
Experiments 부분에서 여러 모델의 다양한 실험 결과를 보여주셨는데,
비디오에서 사용되는 데이터셋들은 프레임 단위로 annotation이 되어있으며 모델도 프레임 단위로 어떤 행동인지 예측하는 것인가요?
첨부해주신 accuracy들이 어떤 식으로 계산되는지 궁금합니다.