

Action Recognition 분야에서는 scene bias되지 않고 motion에만 초점을 맞출 수 있도록 여러 방법론들이 제안되어 오고 있습니다. 이는 주로 Action Recognition 분야에서 활용하는 데이터 셋 내 비디오의 scene 비중이 높아서, 모델이 특정 scene에 집중해서 학습하다보면 같은 motion이지만 scene이 바뀌었을 때 강인하게 동작하지 못하기 때문입니다. 특히, Action Recognition 데이터 셋의 scene bias 정도를 한 연구 [링크] 에서는 식 (1) 같이 나타내었습니다.
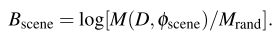
식 (1)에서 M(D, \phi_{scene}) 는 데이터 셋 D에서 scene representation \phi_{scene}에 대한 action classification accuracy을 나타내고, M_{rand}은 랜덤 action classification accuracy (즉, 1/class수)를 나타냅니다. 이러한 두 term을 연산하여 나온 B_{scene}은 데이터 셋 D에 대한 scene bias를 의미합니다.
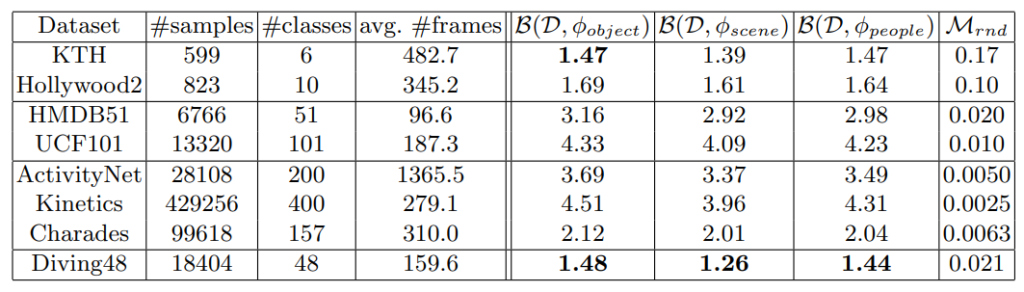
식 (1)을 활용해 scene bias를 측정하였을 때, Table 1에서 각 데이터 셋 별 scene bias된 정도를 확인하실 수 있습니다. 만약, 이상적인 상황에서 특정 데이터 셋에 scene bias가 없다면, scene representation이 accuracy의 영향을 미치지 못하여 random accuracy랑 동일해야하기 때문에 log(1.0/1.0)=0이 되어야합니다. 그러나, 가장 유명한 데이터 셋 UCF101과 Kinetics는 각각 4.09, 3.96으로 꽤 높은 수치를 나타내며, scene bias 되어 있음을 알 수 있습니다. 따라서, 많은 관련 연구들에서는 이 같은 scene bias를 제거하기 위한 시도들을 하고 있으며, 오늘 소개하고자 하는 방법론은 adversarial loss를 통해 동일한 목적을 달성하고자 합니다.
1. Method
본 논문이 제안한 방식을 소개하기 전에 기존 Action Recognition 방법론들의 supervised 방식 방식을 간단히 짚고 넘어가고자 합니다. 비디오 데이터 셋 X과 N class의 label 셋 Y에서 선택된 한 비디오와 그에 해당하는 label을 (x,y)라고 했을 때, 기존 방법론들은 식 (2)와 같이 cross-entropy를 통해 모델 G_{\theta_f}의 파라미터 \theta_{f}와 classifier f_{\theta_A}의 파라미터 \theta_A를 학습시킵니다.
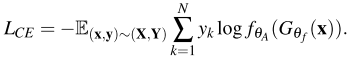
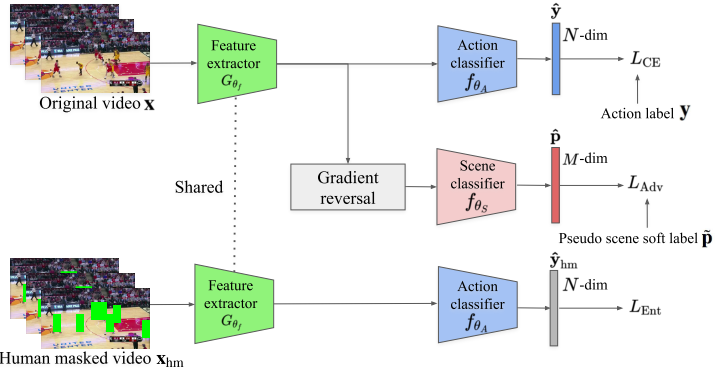
본 논문에서 scene bias를 없애기 위해 제안된 debias 방식은 식 (2)로 학습되는 Action Recognition 방법론에 적용가능한 model-agnostic한 방식이며 두가지의 loss로 구성됩니다. 이는 각각 scene adversarial loss와 human mask confusion loss 입니다.
1.1 Scene adversarial loss

Scene adversarial loss는 모델이 scene label을 맞춘 경우 페널티를 주어 scene-invariant representation을 학습시키고자 합니다. 구체적으로 Fig 3의 “singing” action을 나타내는 왼쪽 비디오가 입력으로 들어왔을 때, 기존 모델은 프레임 내의 가장 많은 비중을 차지 하고 있는 야구장에 bias되어 “playing baseball”라고 예측합니다. 이러한 경우를 방지하고자 식(3)과 같이 설계된 scene adversarial loss가 총 loss에서 마이너스되어, 모델이 scene을 예측한 경우 optimize하지 못하게 합니다.
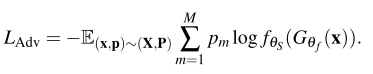
식 (3)에서 f_{\theta_S}는 scene classifier, \theta_S는 scene classifier의 파라미터를 의미하며 p는 M개의 scene label set P에 속한 label을 의미합니다. 여기서 대부분 Action Recognition 데이터 셋은 scene label을 제공하지 않기 때문에, 이미지 데이터 셋 Places365 학습된 ResNet-50으로 pseudo scene label을 생성해 사용합니다.
1.2 Human mask confusion loss
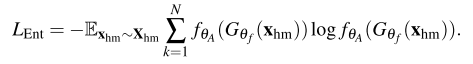
Human mask confusion loss는 Fig 3의 오른쪽(“swimming”)과 같이 사람을 가렸을 때, 모델이 “swimming”을 예측하지 못하도록 식 (4)로 설계되었습니다. 여기서 X_{hm}은 human-masked-out 비디오 셋으로 Fig 2에서 형태를 확인하실 수 있습니다. 이 때, human mask는 학습 이전 Mask R-CNN을 통해 offline으로 계산됩니다.
1.3 Optimization
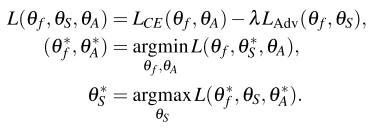
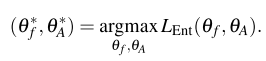
Optimization은 앞서 소개한 각 loss term에 각각 적용합니다. 우선, scene adversarial loss의 경우 식 (5)의 첫번째 줄과 같이 cross-entropy loss와 scene adversarial loss의 차 형태로 optimization되며, human mask confusion loss는 식 (6)에서와 같이 optimize됩니다. 이 때, 식 (5)의 아래 두줄과 식 (6)의 optimize 방향이 다른 것을 알 수 있으실텐데, 이는 gradient reversal layer를 사용한 adversarial training 기법이라고 합니다. 해당 방법은 Domain adaptation을 위한 DANN이라는 방법론에서 나온 방식이라고 하는데, 어떤 방식인지는 이 논문을 읽어보고 추후에 설명하도록 하겠습니다.
2. Experiments
2.1 Does the proposed debiasing method mitigate scene representation bias?
Kinetics 400 데이터 셋의 4분의 1정도인 서브셋 Mini-Kinetics 200 데이터 셋에서, 제안된 방식의 scene classifier를 통한 scene accuracy를 측정하였습니다. Debias가 적용되지않았을 때(cross-entropy만 사용)는 29.7% 였던 scene accuracy가 Debias가 적용되었을 때(제안된 두 loss 사용)는 scene accuracy가 2.9% 감소하였다고 합니다. 이를 통해 상대적으로 scene bias가 완화된 것을 알 수 있습니다.
2.2 Can debiasing improve generalization to other tasks?
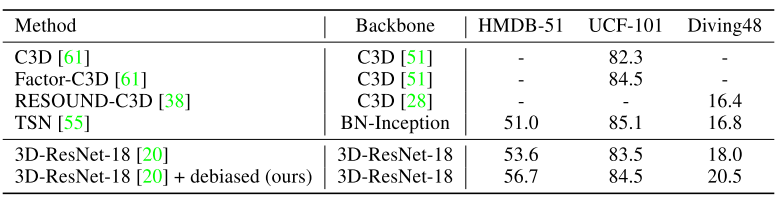
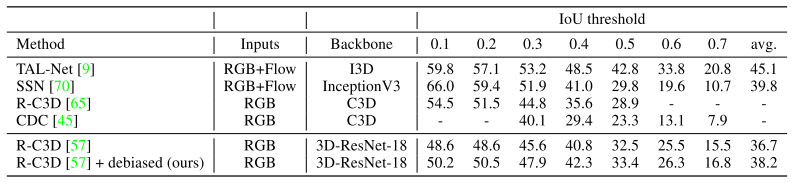

Table 2, 3, 4는 Mini-Kinetics 200에서 학습된 모델을 각각 HMDB51, UCF101, Diving48로 혹은 THUMOS-14로 transfer learning하였을 때의 action recognition과 action localization & detection 성능입니다. 다양한 task에 대해 transfer learning을 하였을 때 기존 대비 제안된 두 가지 loss를 활용할 경우, 일정 수준의 성능향상을 보였으며 이를 통해 제안된 debias 방식이 현존하는 scene bias 데이터 셋에서 효과적임을 알 수 있습니다.
2.3 Ablation study
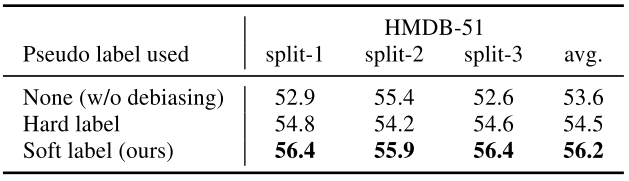
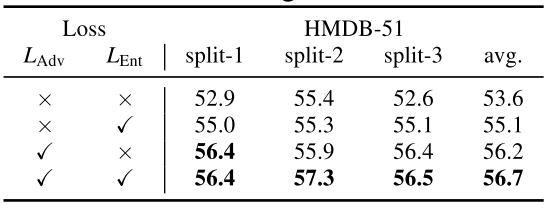
Table 5는 pseudo scene label을 만들 때 하나의 class만 가지도록 hard label을 주었을 때와 여러 class를 가지도록 soft label을 주었을 때의 ablation study 입니다. pseudo label을 생성하기 위해 학습한 Place365 데이터 셋과 semantic하게 유사한 scene 후보를 모두 사용한 것이 이러한 성능 향상을 기인하였다고합니다. 또한 Table 6은 두 loss에 따른 ablation 입니다. 상대적으로 adversarial loss의 영향이 human mask loss에 비해 좀더 크나, 두 loss 모두 성능 향상에 일정 수준 기여하고 있음을 알 수 있습니다.
2.4 Class activation map visualization

마지막으로 Fig 4는 debias 시킨 모델의 CAM을 나타냅니다. 빨간색 text는 잘못 예측한 것을, 파란색 text는 옳게 예측한 것을 나타내며, Baseline 대비 제안된 방식이 좀더 motion에 초점을 두고 있음을 알 수 있습니다.
3. Reference
[1] https://proceedings.neurips.cc/paper/2019/file/ab817c9349cf9c4f6877e1894a1faa00-Paper.pdf
Scene과 Motion의 관계가 생각보다 복합적이네요. Loss 설명을 보면 생각보다 복잡하구요. 그나저나 pseudo scene label을 만들어내는데 정확도는 얼마나 되나요? 이것도 성능에 영향을 미칠 것 같은데요.
video 데이터 셋에는 scene label이 없어 어느정도 정확한지 알 수 없으나, Places365에서의 성능을 찾아보신다면 대략적으로 아실 수 있으실 겁니다.
안녕하세요 좋은 리뷰 감사합니다
질문이 하나있는데 Scene adversarial loss에서 모델이 scene에 해당하는 레이블을 맞출 경우 틀리게 설계되었다고 하는데 그렇다면 1. 배경과 action에 대한 라벨이 따로 필요한 데이터셋이 필요하고, 2. 배경과 action 정보가 서로 다른 영상을 다수 포함하는 데이터가 있어야 할 듯 합니다. 이러한 데이터셋이 혹시 많이 있나요? 감사합니다
1번의 경우 비디오 데이터 셋에서는 부합하는 것이 없기 때문에 pseudo scene label을 사용하였습니다. 그리고 2번의 경우, 이를 scene bias 지표 판단한 논문이 있는데, 그 논문(아래 논문)에 따르면 Diving48 데이터 셋이 가장 많이 그 케이스를 포함하는 비디오 데이터 셋이 아닐까 싶습니다.
[ECCV2018] RESOUND Towards Action Recognition without Representation Bias