오늘은 이전 리뷰와 세미나에서 다룬 2.5D Votenet의 근간인 VoteNet에 대해 리뷰하고자 합니다. 해당 방법론은 효율적으로 포인트 클라우드만 이용하여 3차원 물체 검출의 SOTA를 달성한 방법론입니다. 포인트 클라우드를 직접 사용함으로써 비교적 높은 연산량과 높은 계산 복잡도를 보인 이전 연구에 비해 높은 성능을 보입니다.
Intro
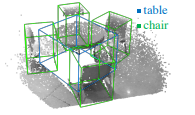
뎁스 센서는 물체의 표면으로부터 3차원 위치 정보를 측정합니다. 3차원 물체 검출에 있어 물체의 기하학적 정보와 구성된 정보로부터 물체의 컨텐츠 정보를 얻을 수 있습니다. 하지만 물체를 구성하는 포인트 클라우드의 희소한 특성으로 인해 위 그림의 테이블과 책상의 다리처럼 얇거나 가려진 경우에는 충분한 3차원 정보를 추출하지 못하는 경우가 있습니다. 또한, 의자와 테이블의 물체의 중심값은 3차원 위치 정보가 없는 빈공간인 경우가 있어 3차원 경계 박스를 예측하는데에 어려움을 줍니다.
반면에 영상인 경우, search sapce의 차원이 줄어든 상황이기에 물체 중심이거나 가까운 픽셀을 검출하는데에 쉬운 경향을 띕니다. 이러한 이유로 해당 논문 이전의 연구들은 2D detector(e.g. front view, BEV based detector)에 의존적인 경향을 띄고 있었습니다.
++ 또는 희소한 포인트 클라우드를 voxelization한 방법론하여 3D conv를 수행하는 방법론
하지만 이러한 경우, 2D detector 수행 후, 추가적인 연산을 수행이 필요하며, 희소한 포인트 클라우드를 재가공하면서 발생하는 정보 손실이 발생합니다.
그렇기에 저자는 raw data인 포인트 클라우드를 직접 사용하길 제안합니다. 하지만 위에서 언급한 바와 같이 포인트 클라우드는 희소한 특성으로 인해 한번에 정확한 3차원 물체 검출을 수행하기가 어렵습니다. 그렇기에 저자는 원리적인 관점에서 hough voting을 이용한 검출기[1]에서 영감을 받아 중심값 정보를 고려한 3차원 정보를 예측하고 이에 대한 물체 검출을 수행할 것을 제안합니다.
[1] Bastian Leibe, Ales Leonardis, and Bernt Schiele. Robust object detection with interleaved categorization and segmentation. International journal of computer vision, 77(1- 3):259–289, 2008. 2, 3
Method
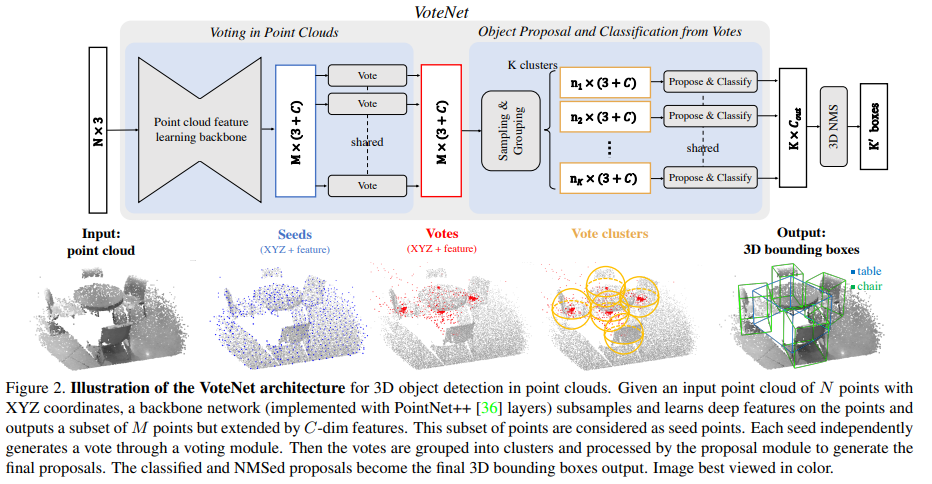
Learning to Vote in Point Clouds
Point cloud feature learning. 가장 먼저 포인트 클라우드 정보 Nx3를 point feature extractor로 성과를 이룬 PointNet++를 backbone으로 적용하여 clustering된 M개의 seed point와 이에 해당하는 3차원 위치 정보 x, y, z와 feature f를 추출합니다.
++ PointNet++는 연속적인 convolution 연산을 적용하여 주변 3차원 정보를 수용하는 특성이 있는 네트워크로 추출된 특징값들은 hand-crafted feature(e.g. sift)와 비슷하게 생각하시면 됩니다.
Hough voting with deep networks. 기존 Hough voting은 사전 계산된 code book을 이용하여 물체 중심값과의 ofttset을 예측합니다. 이런 부분을 end-to-end로 변경하기 위해 저자는 네트워크에 GT(중심값에 대한 offset) ^x*를 직접적으로 loss를 주는 방법을 선택합니다. 해당 네트워크는 간단한 MLP로 구성되며 seed point s_i = [x_i, f_i]를 입력값으로 이용하여 offset ^x를 예측하도록 합니다.
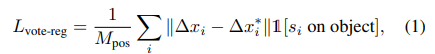
예측 시, seed point 당 하나의 vote point v_i = [y_i, g_i]를 예측하며, yi = xi + ∆xi and gi = fi + ∆f로 보다 중심값에 가까도록 새롭게 생성된 포인트로 구성됩니다. 새로 생성된 vote point v_i는 물체 표면을 중심으로 측정된 희소한 포인트 클라우드을 변환시켜 생성됨으로써 3차원 물체 검출에 도움을 줍니다.
Object Proposal and Classification from Votes
Vote clustering through sampling and grouping. 실제 포인트 클라우드에서는 측정이 불가능한 물체 중심에 생성된 vote points로부터 보다 유의미한 값들을 생성하기 위해 샘플링 및 클러스터링합니다.
++ 논문 내용이 이해하기 어렵고 애매하게 작성되어져 있어 코드 레벨로 살펴본 결과, PointNet++에서 제안된 SAlayer를 사용합니다. 해당 모듈에서는 3D Euclidean space를 기반으로 일정 반경의 주변 값들을 고려하여 seed point를 생성합니다. 이렇게 생성된 seed point를 cluster point로 사용하며, 이를 중심으로 일정 반경의 값들간의 차이 C_k를 특징값으로 사용합니다.
Proposal and classification from vote clusters. 해당 모듈에서 3차원 물체 검출에 필요한 값들을 예측합니다. 해당 모듈에서는 PointNet을 이용합니다. 또한 앞서 예측한 K개의 cluster 정보들은 개별적으로 입력되어져 예측되어집니다. 예측전에 각 포인트들은 노이즈가 될 수 있는 글로벌한 위치 정보를 중심값 기준으로 정규화를 수행하여 로컬한 좌표계로 변환해줍니다. 이후 간단한 구조를 가진 MLP에 태워진 후, max-pooling(channel-wise)을 통해 단일 벡터로 연산되어 집니다.
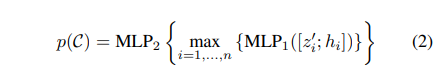
그후, MLP_2를 통해 objectness score, bounding box parameters (center, heading and scale parameterized), semantic classification scores를 예측합니다.
Loss function.
해당 방법론의 Loss는 아래와 같습니다. 수식 1에서 언급한 vote regression loss로 구성되며, object 여부를 측정하는 objectness loss, 물체의 class를 예측하는 semantic classification loss는 cross-entropy로 구성됩니다.
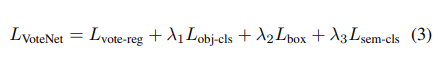
마지막으로 box loss는 수식 4와 같이 예측을 수행하며, L1 loss를 통해 최적화를 수행합니다.
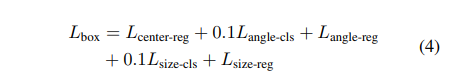
Experiment
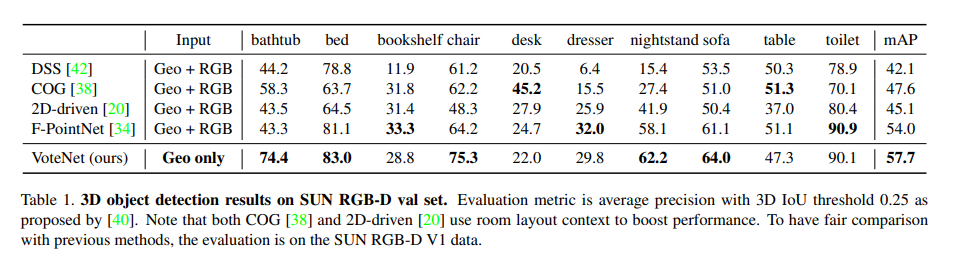
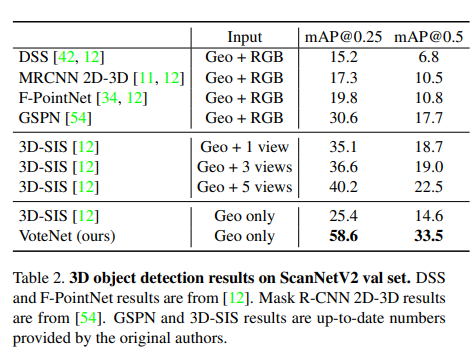
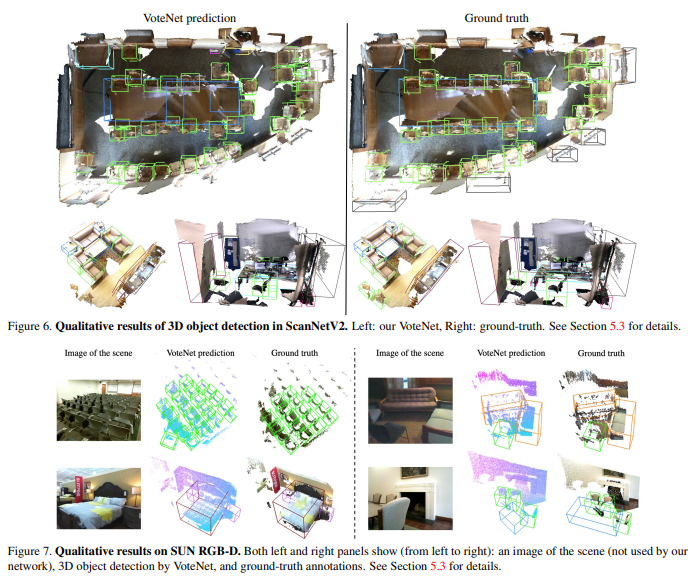
위의 테이블과 그림은 정성/정량적 결과이며, 제안하는 방법론의 성능을 자랑하고 있습니다.
Ablation study
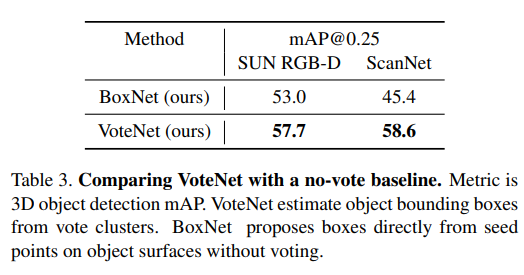
저자는 제안하는 voting 방식이 효과를 증명하기 위해서 동일한 구조를 가진 네트워크에서 vote(i.e offset 연산)을 제거하여 예측을 수행하였습니다. table 3에서와 같이 꽤나 높은 성능 차이를 보여줌으로써 효과를 입증하였습니다. 저자가 주장하길, 이는 표면적만으로 예측하는 것이 성능 저하의 원인이 될 수 있다고 합니다.

또한 이에 대한 정성적인 결과도 보입니다. 파란색 점들은 bbox에 포함되어진 point를 시각화한 그림입니다. 정성적인 결과에서도 boxnet보다 조밀한 오버레이를 보여줌으로써 Proposal module에 입력될 context를 증가시켜 검출기의 성능을 향상 이끈 것을 입증합니다.
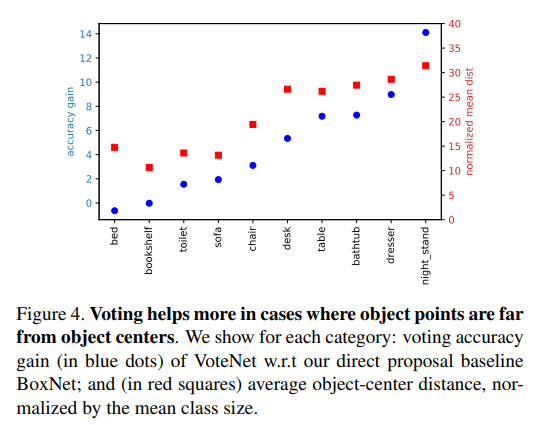
그리고 저자는 데이터 셋 관점에서도 효과를 입증하고자 합니다. fig 4에서 파란색 점은 각 클래스 별 표면적과 중심값의 차이 평균에 해당하며, 빨간색 점은 VoteNet과 BoxNet의 성능 차이입니다. fig 4에서 확실히 볼 수 있는 바와 같이 파란색 점과 빨간색 점의 비례적인 관계를 볼 수 있습니다. 이를 통해 제안하는 방법이 표면적과 중심값의 차이로 발생하는 문제를 개선한다는 것을 입증합니다.

Table 4는 위에서 저자가 주장한 포인트 클라우드을 이용하지 않는 방법론의 문제점으로 지적한 계산 속도와 모델 크기(연산량)에 대한 강인성 평가를 위한 실험입니다. F-PointNet은 2D detector를 기반으로 예측을 수행한 후, 3D detection을 수행하는 방법이며, 3D-SIS는 voxelization 수행 후, 3D convolution을 갖춘 CNN을 이용한 방법론 입니다. F-PointNet 대비 단일 모델을 사용함으로써 4배 이상으로 작은 모델 크기를 보여줍니다. 3D-SIS에서는 모델 크기와 추론 속도 모두 개선된 모습을 보여주고 있습니다.
++ 두 방법론 모두 VoteNet 이하의 성능을 보여줍니다.
============================================================================
해당 방법론은 뎁스 센서의 특성상 물체 표면만을 측정함으로써 발생하는 모호성을 해소하기 위해 포인트 클라우드로부터 물체 중심과의 offset을 예측하도록 학습하였습니다. 예측된 offset 방향으로 생성된 vote points를 생성함으로써 물체 표면이 아닌 물체 중심에 가까운 가상의 포인트 클라우드를 생성하였습니다. 가상의 포인트 클랑우드들은 detection 수행에 있어 높은 퀄리티의 object proposals로 사용되어져 검출기 성능을 향상 시켰습니다.