요약:
본 논문은 모델의 시간에 따른 학습 정도(TOD)를 이용하여 uncertainty를 측정하는 Active Learning 방법론이다. Image Classification과 Segmentation task에서 SRAAL보다 높은 성능을 보인다.
1. Introduction & Relate work
기존 딥러닝의 성능향상은 라벨링을 진행한 labeled data에 의존도가 컸다. 최근에는 labeled data에 대한 의존도를 줄이기 위해 Semi-supervised, Active Learning 등이 연구되고 있다. 그 중 Active Learning이란 수집 된 Unlabeled data 중 어느 모델의 학습에 도움이 될 데이터를 선정하여 라벨링을 진행하기 위한 테스크이다. 이를 통해 라벨링 할 데이터를 효율적으로 선별하여 데이터셋의 구축 비용을 줄일 수 있다. labeled data에 대한 의존도를 최소화 하더라도, 라벨링은 필수적으로 필요할 것이므로 Active Learning 기술의 발전은 중요하다.
Active Learning은 크게 diversity-aware approach와 uncertainty-aware approach로 나뉜다. 먼저 diversity-aware approach는 unlabeled 데이터셋의 분포를 대표할 수 있는 데이터를 선별하여 labeled data에 포함시키는 방법으로 주로 unlabeled 데이터셋의 분포가 복잡하지 않거나 작을 때 유용하다. unlabeled data에서 선별한 데이터를 labeled data에 포함시키는 과정에서 labeled data의 분포를 unlabeled data의 분포와 유사하게 만드는 목적을 갖는다는 점에서 domain adaptation(DA) 분야와 엮이기도 한다. 다음으로 uncertainty-aware approach란 모델이 unlabeled data에 대한 불확실성을 측정함으로써 모델이 학습이 충분히 되지 못하여 예측에 어려움을 겪는 데이터를 정보량이 많은 데이터라고 판단하여 선별하는 접근법이다. 해당 방식의 단점은 모델에 의존적이기 때문에 주로 task에 의존적인 설계가 필요하다.
최근 loss를 이용해 uncertainty를 측정하는 연구들을 통해 task-agnostic 한 접근이 가능해졌는데, 이때 주로 loss예측을 위한 추가 모델이 필요하였다. 지금부터 소개하는 본 논문은 이러한 추가적인 모델 없이 Temporal output discrepancy(TOD)의 수치를 이용하여 uncertainty를 측정할 수 있음을 이론적으로 보였다. 그리고 TOD를 확장한 COD와 TOD를 적용한 semi-supervised learning 방식을 Active learning 과정에 적용하여 최종적으로 Active Learning 분야에서 state-of-the-art 성능을 보였다. 본 논문을 소개하기 위해 우선 TOD 기반의 uncertainty 측정의 가능성을 소개하고, 다음으로 TOD를 활용한 논문의 Active Learning 방식을 소개한다.
2. TOD 기반의 uncertainty 측정
TOD 기반의 uncertainty 측정은 단순하다. unlabeled data인 x의 uncertainty를 측정하기 위해 (T)번째 학습 모델의 예측값과 (T+1)번째 학습 모델의 예측값을 비교하는 것이다. x 데이터에 대한 예측값의 변화량이 크다는것은, x 데이터의 loss가 크다는 것을 의미하며(loss가 크기 때문에 해당 데이터가 오차전역법을 통해 모델을 많이 변화시켰으므로), 이는 x 데이터의 uncertainty가 크다는것을 의미한다는 점에서 이는 합리적이다. 따라서 TOD 계산식은 [수식 1]과 같이 정의된다.
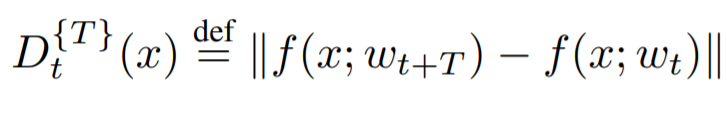
3. TOD기반의 Active Learning
논문에서 제안하는 Active Learning 역시 기존의 논문과 같이 다음의 순서를 거친다.
(a) an unlabeled data sampling strategy
(b) the learning of a task model
이때, A의 과정에서는 TOD 기반의 데이터 uncertainty 측정법인 Cyclic Output Discrepany(COD)를 이용하고, 기존에 확장된 데이터로 supervised learning을 진행하던 (b)의 모델학습 과정에는 TOD 방식을 적용한 semi-supervised 방식으로 모델 업데이트를 진행한다는 것이 본 논문의 특이점이다. 각 모듈에 대해 설명하면 아래와 같다.
3.1. Unlabeled data에서 annotation 요청 데이터셋 선별

COD 기반의 데이터 선별은 [그림1]과 같이 진행되는데, 기존은 모델 업데이트에 따른 시간차 기반의 모델 학습 정도를 비교하였다면, COD는 labeled pool update 시점인 cycle 증가에 따른 모델의 변화를 이용한다. 서로 다른 cycle의 두 모델에서 예측값의 차이가 큰 top-b개의 unlabeled data의 라벨링을 요청하여 labeled pool을 증가시킨다. 이때 데이터 x의 uncertainty 식은 수식2와 같다.
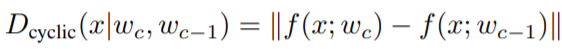
3.2. labeled pool 을 통한 모델 업데이트
기존의 Active Learning에서는 대부분 해당 과정은 task 모델에 대한 학습을 진행하는 형태로 확정된 labeled data를 통해 모델을 학습하여 정확도를 높였다. 하지만 본 논문에서는 제안하는 TOD를 활용하여 unlabeled data 를 학습에 활용하는 Semi-supervised Learning을 진행하였다. 모델의 목적함수는 기존 연구들과 같은 labeled data에 대한 task loss(supervised learning을 위한 loss)와 제안하는 semi-supervised loss를 결합하여 구성하였다. 전체 목적함수는 [수식3]과 같으며 L_s는 모델의 task loss이다. 제안하는 L_u는 [수식4]와 같으며 이는 unlabeled data에 대하여 업데이트 전 모델인 w~와 현재 학습모델인 w간의 차이가 적도록 하는 함수이다. 이는 unlabeled data를 활용하여 unlabeled data에 대한 분포가 급격히 변화하지 않도록 하여 학습 정도를 조절하기 위한 식으로. TOD 방식에서 이용하는 x데이터에 대한 모델의 예측 변화도에 따라 모델이 급격하게 학습하지 않도록 한다.
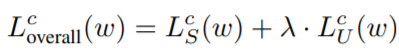
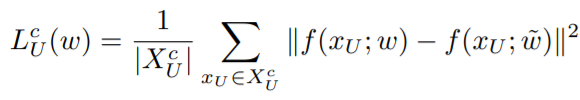
4. Experiments
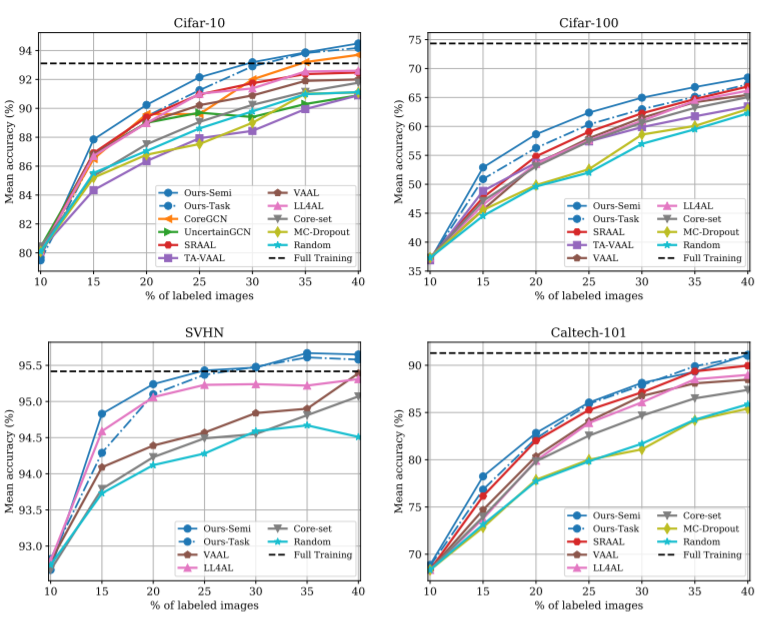
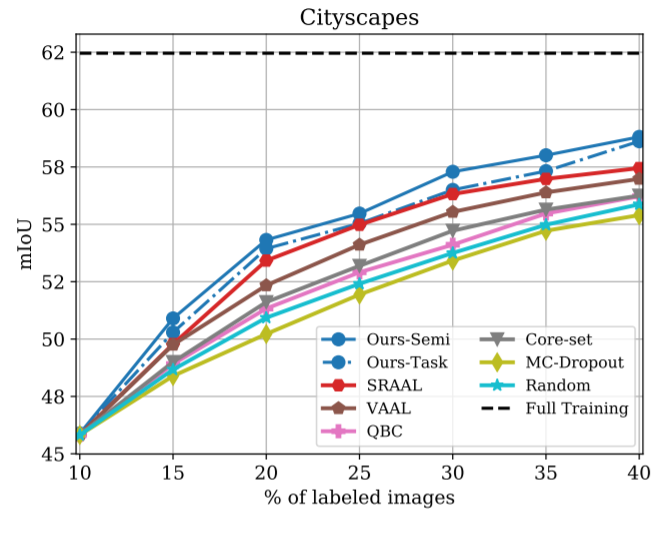
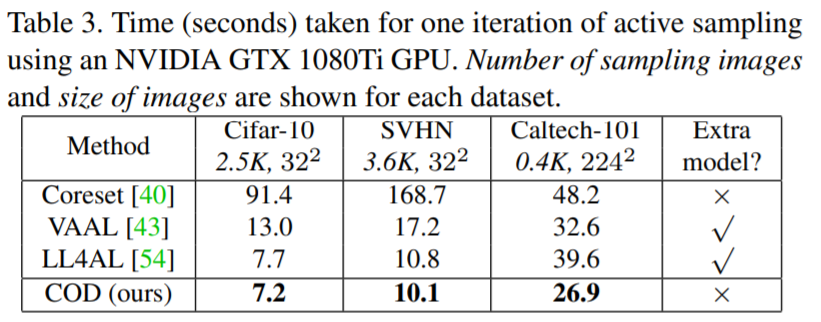
논문은 Image Classification과 Image Segmentation에 대하여 STOA의 성능을 달성하였다. 그 결과는 아래 [그림2,3]과 같다. 이때 비교 성능 중 Ours-Semi는 3.2의 방식을 이용한 것이고, Ours-Task는 기존의 Active Learning 방법론처럼 task loss만을 통해 모델을 업데이트한 경우이다. 또한 [표1]에서 확인할 수 있듯이 분포기반 방법론과 uncertainty 방법론에 비해 빠른 처리속도를 보임을 확인할 수 있다.
제가 오늘 리뷰한 논문과의 비교실험에는 더 좋은 성능을 보이는 것 같습니다. 혹시 ImageNet 에 대한 리포팅은 없나요? 그
혹시 SVHN 에서 labeled image 의 % 가 늘었는데 accuracy 가 왜 줄었는지에 대한 언급이 있는지 궁금합니다. 다른 데이터셋들은 점차 늘어나는데, 왜 이 친구만 40%에서 다른 경향을 보이는 걸까요…?