안녕하세요 이번주에도 비디오 검색 관련 논문 읽기… 세번째 논문으로 PPT를 들고 왔습니다. 방법론 이름이 PPT 입니다. 해당 논문에서는 near-dupliceate video retrieval (NDVR) 과 near-dupliceate video localization (NDVL) 를 위해, 계층적인 filter-and-refine 프레임워크로 a spatiotemporal pattern-based approach 를 사용할 것을 제안했습니다. 이 당시 성능을 평가했을 때 기존의 접근 방식보다 좋은 결과를 달성했다고 합니다.
Introduction
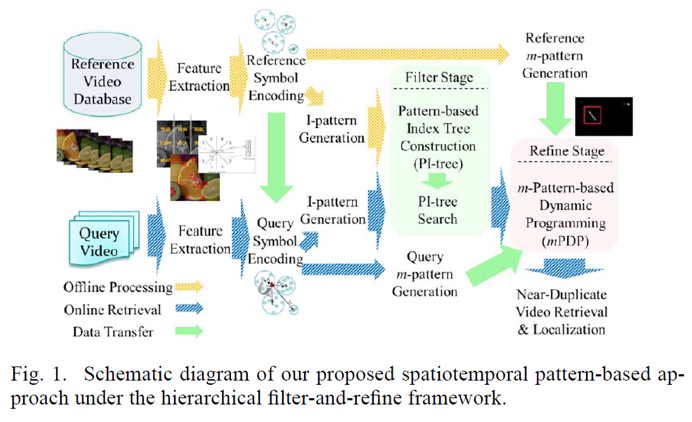
우선 전체적인 프레임워크는 위의 그림과 같습니다. 이를 이용하면 fully NDVR, parital NDVR, 그리고 NDVL 의 결과까지 도출해낼 수 있습니다. 아래는 해당 프레임워크에 대한 순서대로의 설명입니다.
- 하나의 query video 와, 여러 개의 reference videos (database) 가 주어진다.
- video frames 의 low-level features 를 뽑는다.
- (2) 의 features 가 symbolized 된다.
- (3) 의 symbol sequences 를 이용하여, I-pattern 과 m-pattern 을 만든다.
- (4) 의 I-pattern (query + reference)를 이용하여, PI-tree 를 만든다.
- Filter stage : non-near duplicate videos 를 거르기 위한 목적이다.
- (5)의 결과에 mPDP 를 확장한 방법을 적용한다.
- Refine stage : re-rank 와 localize 하기 위한 목적이다.
- 최종적으로 NDVR + NDVL 결과를 얻는다.
Feature Extraction
- 비디오에서 t개의 프레임 간격으로 keyframe 을 선택한다. (uniform sampling)
- (이때, 더 정확한 추출을 위해, 추출 전에 preprocessing 으로 boreder removal 을 한다.)
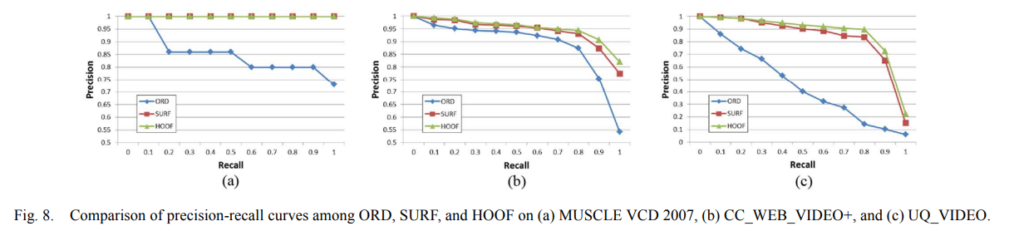
- 비교를 위해 keyframe 마다 3가지 종류의 feature 를 추출한다. (ordinal feature, SURF, HOOF)
Pattern Generation
- K-means clsutering 을 사용하여, 비슷한 feature 의 keyframes 끼리 cluster 를 만들고 해당 cluster를 나타내는 symbol 을 정의한다. (symobl encoding.)
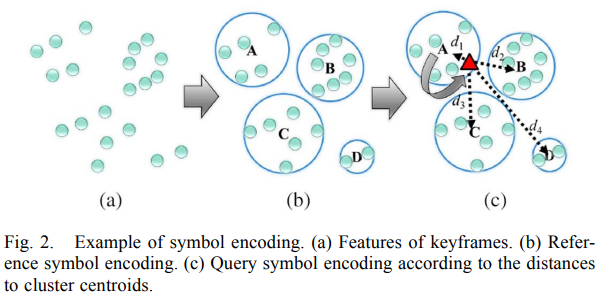
- 비디오의 각 keyframe 마다 배정된 symbols (or candidate symbols) 을 합쳐서, video 마다 a sequence of symbols 를 만든다.
- 단순 symbol sequence 에는 길이 2 짜리 window 를 sliding over 해서 I-pattern 을 만든다.
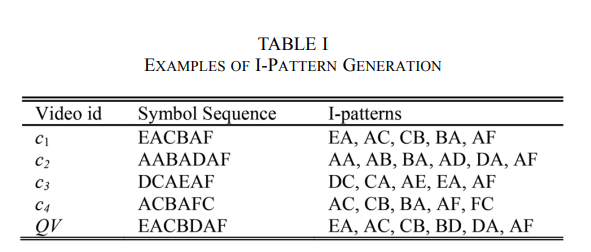
- candidate symbol sequence 에는 길이 m 짜리 window 를 이용해서 m-Pattern 을 만든다.
- 이때, reference video 와 query video 간의 symbol similarity 는 아래 공식을 이용하여 구할 수 있다.
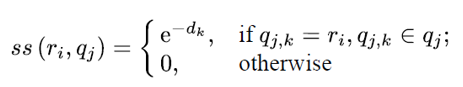
PI-Tree
- 생성된 pattern 을 기반으로 non-near-duplicate videos 를 걸러내기 위해, filter stage 에서 쓰이는 구조 입니다.
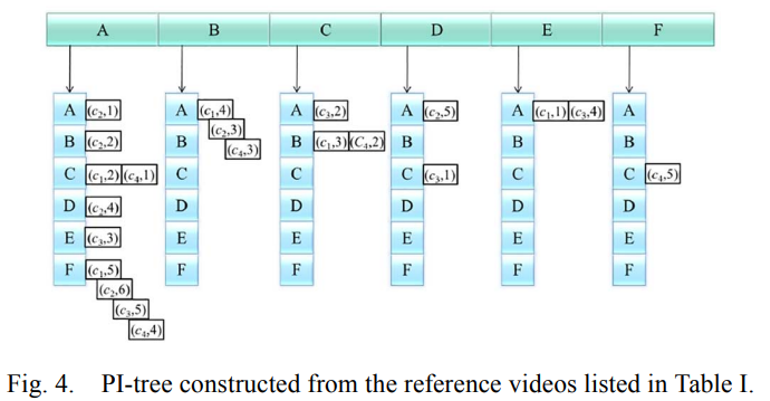
video c1 에 대한 i-pattern 중 첫번째 인덱스에 있는게 EA 라고 할 때, 위 그래프의 col : E, row : A 를 보면 (c1,1)이 들어가 있습니다. 모든 pattern, video 에 대해 이 단계들을 반복해서 PI-tree 를 구성합니다.
PI-Tree Search
같은 I-pattern 을 가진 video 의 수가 많을 수록, 해당 I-pattern 은 흔하다는 의미가 됩니다. 즉, 검색은 비디오들 간의 차이점을 중요시해야하니까, video retrieval 을 할 때 필요하지 않게 된다는 뜻입니다.
아래는 I-Pattern P 의 distinctivness 를 계산하는 식입니다.
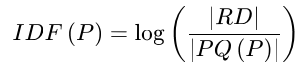
- RD : the number of Reference Database
- PQ(P) : the number of videos in the queue prefixed by the I-Pattern P
이를 이용해서, 어떤 a query video 에서 I-Pattern {P1, P2, … Px} 가 주어졌을 때, 각 P 가 해당하는 queue pool 에 대해 distinctivness 를 구해서, 특정 queue 에 있는 temporal relation 과 consistency socre 를 아래와 같이 정의합니다.
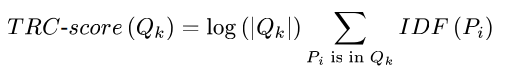
이 이후에, queue pool 을 얻었기 때문에, reference video cj에 대한 near-duplicate score 를 아래와 같이 얻을 수 있게 됩니다.
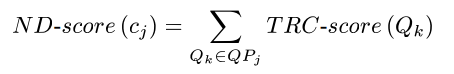
mPDP
- m-Pattern 기반 Dynamic Programming 을 뜻합니다.
- m-pattern 을 dynamic programming 의 basic units 으로 사용합니다.
- 어떤 reference video RV 의 u번째 m-pattern 을 r^u 라고 하고, 어떤 query video QV 의 v번째 m-pattern 을 q^v 라고 했을 때, 이 둘의 video similarity 는 아래와 같습니다.

이때, pattern similarity PS 는 두 가지 방법으로 구할 수 있습니다.
- DPS (Direct m-Pattern Similarity) : naive
- 두 m-pattern 에서 같은 position 에 있는 symbols 간의 유사도를 계산합니다.
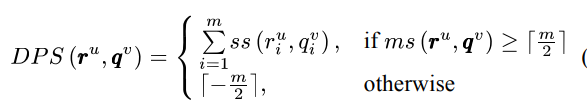
2. TPS (Time-shift m-Pattern Similarity) : enhanced version
- time 이 shift 됐을 경우를 대비하여 optimal matching 을 고려하여 계산합니다.
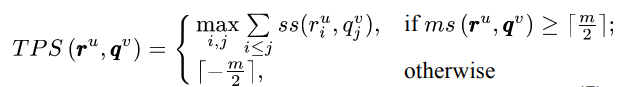
NDVL and Re-Ranking
- mPDP 이후에 얻게 된 tables 를 이용해서, video 가 near-duplicate 인지, 그리고 그렇다면 localize 를 해줍니다.
- 계산한 similarity 가 클 수록 near-duplicate 일 확률 이 높습니다.
- 또한 얻은 backtrakcing 의 대각선 특성을 이용해서, 서로 얼마나 연관되어있는지 알아내고, 이를 통해 NDVL 과 Re-ranking 을 진행합니다.
Experiments
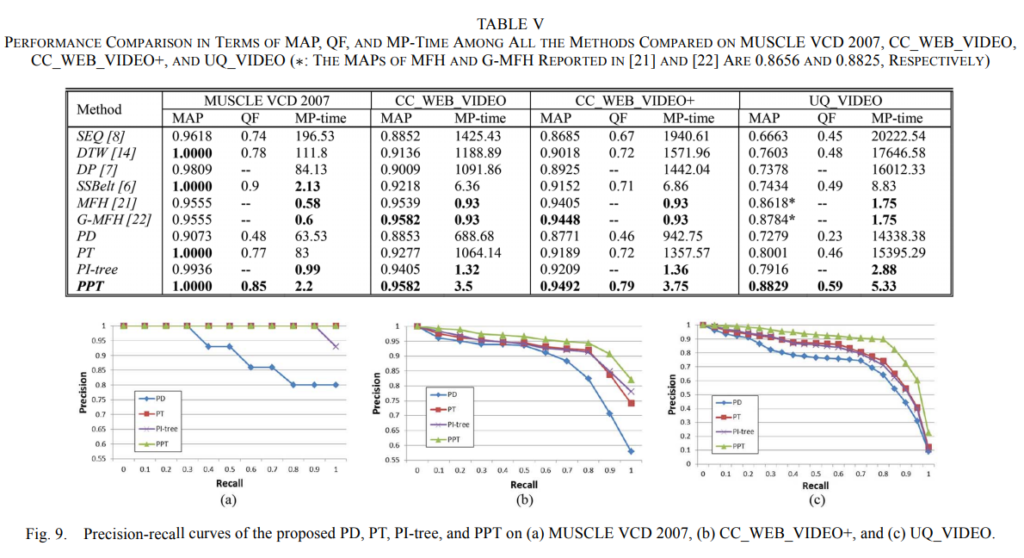
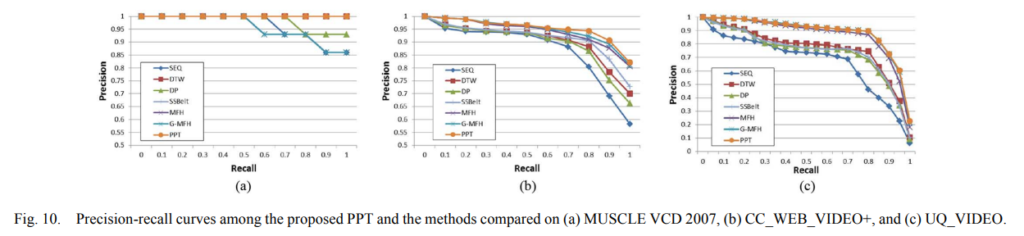
- five datasets : MUSCLE VCD, CC_WEB_VIDEO, CC_WEB_VIDEO+, UQ_VIDEO, TRECVID-CVCD
- compared features : ORD (ordinal feature), SURF, HOOF