이번 리뷰 논문은 이전 리뷰와 동일하게 normalizing flow(NF)에 관련된 논문입니다. 이전부터 NF에 대한 논문들을 많이 소개하며 이상치 탐지에 적용하고자 시도를 했습니다. 하지만 어느 정도 진행하면서 성능 향상에 어려움을 겪게 되었고, 이에 대한 통찰을 얻기 위해 다른 논문들을 찾아보게 되었습니다. 찾아보던 와중 해당 논문이 NF가 이상치 데이터 셋인 MVTec-AD에서 두각을 보이도록 해준 논문이라는 것을 알았습니다.
그럼 해당 논문은 어떤 이야기를 담고 있는 걸까요? 이것은 제목에서도 알 수 있듯이, 왜 NF가 Out-of-Distribution(OOD) task에서 좋은 성과를 보여주지 못했는지를 분석합니다. 또한 이에 대한 해결책을 제안하고 있습니다. 자세한 이야기는 아래에서 계속 다루도록 하겠습니다.
Intro
이상 검출, OOD는 크게 정상적인 형태 간의 reconstruction error를 통해 구분을 하거나, 데이터를 유의미한 정보들을 추출하여 특징값 간의 거리를 비교하는 distance error를 기반으로 한 방법, 혹은 두가지 방법을 함께 사용하는 방법으로 구분 할 수 있습니다. 위의 두 가지 방법은 명확한 장단점을 가지고 있습니다.
먼저 특징 값을 이용하는 distance error인 경우, 학습 시 이상 여부에 대한 지도 학습을 통해 명확하게 구분해가며 학습을 진행하며, 고차원의 정보를 저차원으로 추출함으로써, reconstruction errror보다 높은 성능을 가집니다. 하지만 지도 학습의 한계를 그대로 계승한다는 한계가 있습니다. 또한 데이터의 특징 추출로 인해 위치 정보 소실로 어느 위치에서 이상이 발생했는지 명확한 설명이 불가능하다는 단점이 있습니다.
다음 GAN이나 VAE 등의 생성 모델을 이용하는 reconstruction errror인 경우, 정상 분포로 데이터를 복원하여 에러를 측정하기 때문에, 이상 여부만을 검출하는 것이 아니라 어느 부분이 이상치인지 명확하게 알 수 있다는 장점이 있습니다. 또한 학습에는 정상 분포로만 학습하여 이상 여부에 대한 라벨 없이도 학습이 가능하기에 높은 실용성을 가집니다. 반면에 주로 생성 모델을 이용하기 때문에 학습이 잘되는 분포로 치우치는 mode collapse가 발생합니다.
이에 반해, NF는 두 가지 방법의 장점이 결합된 방법으로 볼 수 있습니다. 즉, 데이터에 대한 likelihood를 직접적으로 추정하며 학습하기 때문에, 고차원의 데이터를 저차원에서 비교가 가능합니다. 또한 가역성을 가짐으로써 생성 모델의 한계로 꼽히는 mode collapse 문제를 극복한다는 장점과 가역을 통해 영상을 복원하여 어느 위치에서 이상이 발생했는지 명확한 설명이 가능합니다.
이러한 장점에도 불구하고, NF는 관심을 받지 못하다가 2022년에 와 서야 이상 검출에서 두각을 드러냈습니다. 즉, 그 전까지는 저조한 성능을 가졌다고 볼 수 있습니다.
OOD에서 높은 성능을 보일 것 같은 NF가 저조한 성능을 가진 이유는 무엇 일까요? 저자는 NF의 문제점을 ‘inductive bias’ 라고 지적합니다. 즉, 학습 데이터의 분포와 다른 데이터가 들어가는 순간 저조한 결과를 보여주는 문제입니다. 보지 못한 이상치를 검출 해야 하는 OOD와 이상 검출에서는 매우 치명적인 단점이라고 볼 수 있죠. 사실 ‘inductive bias’는 NF 뿐만이 아니라 대부분의 기계 학습 방법론에서도 해결 해야 하는 문제이기에, 당연한 거 아닌가 라는 의문점이 들 수 있습니다. 하지만 생성 모델로써의 NF와 OOD에서의 NF는 다른 ‘inductive bias’의 성질을 가져야만 합니다.. 이번 리뷰에서는 기존 NF(of OOD)에서의 ‘inductive bias’는 왜 문제이며, 왜 어떤 방향으로 변해야 하는가?에 대해 다루며, 이에 대한 저자의 해결안을 확인할 예정입니다.
++ OOD task에 대해 잘모르시는 분들을 위해 부연 설명을 하자면, OOD는 해석 그대로 다른 분포를 가진 데이터를 구분하는 태스크입니다. 예를 들자면 MNIST로 학습한 모델이 ImageNET 데이터를 out-of-distributuion으로 구분하거나, 학습 클래스 외 클래스를 구분하는 능력 정도를 평가합니다.
Background
위에서 NF는 OOD에서 좋은 성능을 보일 조건을 가지고 있다고 이야기하였습니다. 이에 대해 좀 더 자세하게 설명하자면 NF는 아래의 수식 1을 목적 함수로 학습하기 때문입니다.
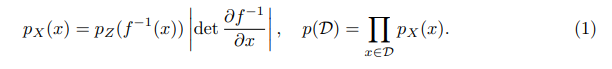
수식 1은 이전 리뷰에서 다룬 바와 같이 학습 데이터 셋 D의 likelihood를 직접적으로 예측하기 위한 데이터 x와 모델 f로부터 변환된 latent feature z의 가능도에 대한 변수 변환 입니다. 그렇기에 모델이 학습 데이터와 유사한 분포를 가진 데이터에서는 높은 가능도를 보여주고 다른 분포를 가진 데이터 셋의 데이터에서는 낮은 가능도를 보이는 것이 당연한 순리로 보입니다.
NF는 affine coupling layers를 이용한 트릭으로 학습 가능한 모델로 구현 가능합니다. affine coupling layers는 수식 2와 같은 구조를 제안함으로써, NF를 적용하기 위한 2가지 조건, (1) 가역성, (2) 자코비안 행렬의 낮은 계산 복잡도를 가능하도록 만들었습니다. (자세한 내용은 이전 세미나 영상을 참고)
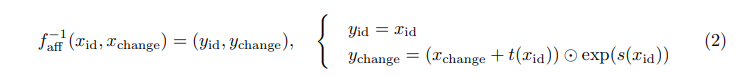
핵심적인 부분만 다시 소개하자면 데이터 x를 x_{id} , x_{change} 를 나눠 수식 2와 같은 간단한 수식으로 y를 y_{id} , y_{change} 로 변환하는 트릭을 통해 손쉽게 가역을 구하며, 자코비안 행렬이 하삼각 행렬 형태를 가짐으로써, 계산 복잡도가 적어지는 트릭을 사용합니다. 추가로 수식 2의 아핀 변환이 일어나는 y_{change} 의 스케일, translation 함수(s, t 함수)를 학습 가능한 layer로 변경함으로써 적응적으로 학습 가능한 모델을 제안했습니다.
또 다른 트릭으로 데이터를 나눌 때, 주변 픽셀의 연관성을 키우기 위해 checkboard mask를 제안하여, 근처 픽셀 뿐만이 아니라 채널과 보다 넓은 픽셀까지 고려 가능하도록 했습니다.
Why flows fail to detect OOD data
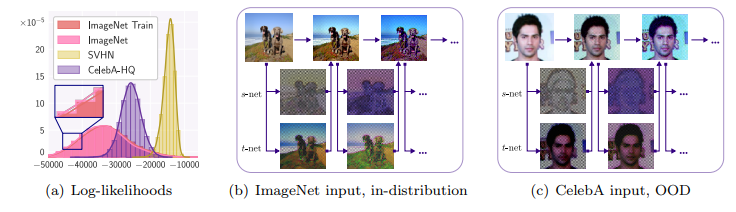
하지만 NF 기대한 바와는 다르게 좋지 못한 성능을 보여줍니다. 이를 증명하기 위해 저자는 NF 모델의 근본으로 불리우는 RealNVP를 베이스 모델로 실험을 진행하였습니다. Fig 1은 ImageNET으로 학습된 RealNVP에서 SVHN, CelebA-HQ를 out-of-distiribution으로 설정한 실험 결과 입니다. Fig 1-(a)를 보면 OOD에서 가장 높은 likelihood를 보여야 할 ImageNet이 아닌 OOD 데이터~SVHN,CelebA-HQ에서 높은 likelihood를 보여주며, 정량적인 결과에서도 문제가 있음을 보입니다. 또한 fig 1-(b,c)를 보면 OOD나 in-distribution에서도 물체의 엣지와 밝기, 색상 등에 관심을 가지는 것을 볼 수 있습니다.
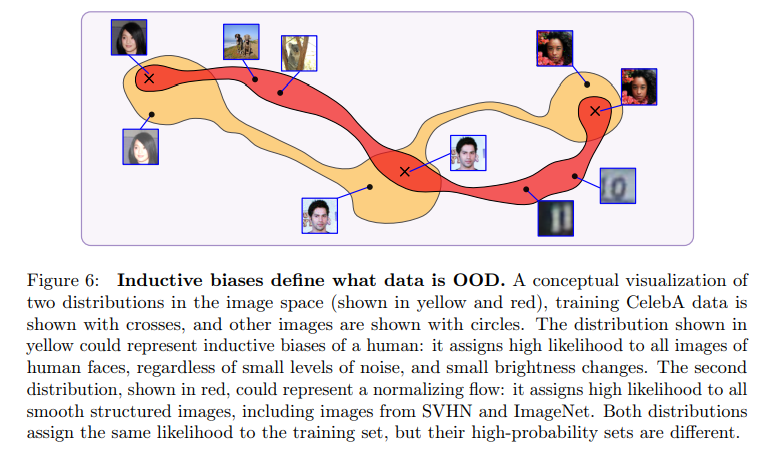
이러한 측면에서 기존의 NF(NICE, RealNVP, GLOW)는 영상의 Sematic structure(high-level feature)를 보는 것이 아닌 graphical feature(low-level feature)에 큰 관심을 가지고 있으며, ‘inductive bias’ 또한 이러한 graphical feature에 대한 방향으로 향하고 있음을 볼 수 있습니다. 이러한 이유는 기존 NF는 생성 모델로써, 영상의 엣지, 밝기, 색상 등의 graphical feature에 대한 latent feature space(fig 6의 red)를 구축하는 것 만으로도 충분합니다.
하지만 OOD에서의 ‘inductive bias’는 fig 6의 yellow 구역의 image space를 가짐으로써, 각 데이터 셋 간 강한 구분력을 가지는 것이 가장 이상적인 결과로 볼 수 있습니다.
즉, 저자는 Fig 6의 red – ‘inductive bias’의 방향을 가지도록 설계된 기존 NF 모델의 구조가 문제이기에, Fig 6의 yellow – ‘inductive bias’를 가지도록 모델 구조를 변경 해야 한다고 주장합니다.
저자는 주장하는 내용이 실제로도 맞는지 확인하기 위한 실험을 진행합니다.
Flow latent spaces

가장 먼저 저자는 NF의 latent feature가 어디를 보는지 확인했습니다. 실험적인 결과, Fig 2와 같이 OOD에서 graphical feature를 보이는 특성이 가지고 있으며, 영상 내의 semantic fetrue에는 관심을 가지지 않는 모습을 보여줍니다. 즉, 위에서 주장한 기존 NF의 ‘inductive bias'(fig 6의 red)를 가지는 것을 증명합니다. 그럼 왜 low-level feature만 보는 이유가 무엇일까요?
Transformations learned by coupling layers
이에 대한 해답은 앞서 이야기한 바와 같이 기존 NF 모델 구조에 있습니다. 크게 coupling layer의 s-Net, t-Net과 Mask 기법에서 원인을 발견할 수 있었다고 저자는 주장합니다.
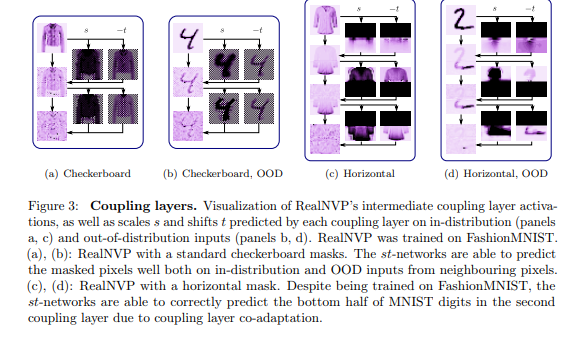
위의 섹션 background에서 설명한 바와 같이 기존 NF는coupling layer의 s-Net, t-Ne와 데이터를 나누기 위한 기법 mask(위에서는 checkboard mask)를 사용한다고 이야기했습니다. 이러한 기존 기법을 이용하여 실험적으로 분석한 결과 fig 3과 같은 결과를 보여줍니다.
Leveraging local pixel correlations
가장 먼저 Fig 3-(a,b)는 주변 픽셀 정보들을 활용한 checkboard mask를 사용합니다. 모델은 FashionMNIST(in-distribution)로 학습된 RealNVP를 이용합니다. s-net에서는 주변 픽셀과 유사한 색상 정보 유사성에 따라 흑백 대조가 극명하도록 학습되는 경향을 보입니다. t-net에서는 이웃 정보가 소실된 checkboard masked 입력 정보를 최대한 복원하도록 학습되는 경향을 보입니다. 이를 통해 Fig 3-(a,b)는 영상 정보의 주변 픽셀 간 상관 관계를 고려하여 학습함으로써, graphical feature에 집중하는 모습을 보여줍니다.
Coupling layer co-adaptation
Coupling layer의 특성을 보다 자세히 들여다 보기 위해 Fig 3-(c,d)에서는 RealNVP에서 기준으로 제안된 horizontal mask를 이용한 분석을 수행했습니다. 실험적인 결과, in-dist, OOD 데이터 셋에서 모두 첫번쨰 레이어에서는 형태를 알아볼 수 없는 값을 추정되지만, 두번째 레이어 이후부터는 점차 형태가 보이는 정확한 예측을 수행합니다. 즉, 이전 레이어에서는 값을 encoding하고, 다음 레이어에서는 이를 decoding하는 co-adaptaion한 과정이 존재한다는 것을 보여줍니다. 고로 OOD에서는 주변 픽셀을 고려하도록 남기는 것보다는 전체를 소실시키는 것이 상대적으로 semantic feature를 볼 가능성이 높아짐으로 보여줍니다.
Changing biases in flows for better OOD detection
이전까지는 기존 NF가 OOD를 위한 ‘inductive bias’가 다른 방향인 것을 입증했습니다. 정리하자면, 기존 NF 모델에서 주로 사용된 checkboard mask 기법은 주변 픽셀 간의 상관 관계를 고려하도록 모델이 설계됨으로써, ‘inductive bias’가 low-level feature를 보는 것에 적합한 형태를 가지고 있습니다. 하지만 OOD에서는 유사한 형태보다는 단순히 구조적인 특징보다는 high-level feature(sematic feature)에서의 차별성이 보다 중요하기 때문에 이를 보는 ‘inductive bias’로 봐야합니다.
이제부터는 OOD를 위한 ‘inductive bias’ 를 가진 NF 모델로 변경하기 위한 저자의 전략을 소개하고자 합니다.
Changing masking strategy
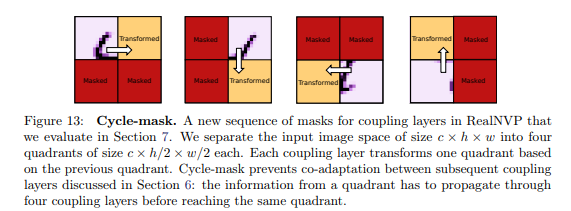
앞서 horizontal mask가 co-adaptation 효과를 보여주는 것을 실험적 결과로 확인했습니다. 저자는 이러한 특성을 더욱 강화하기 위해 cycle-mask 기법을 제안합니다. 기존 horizontal mask 보다 세밀하게 예측하되, 주변 픽셀을 참고 할 수 없도록 설정한 구조를 가지고 있습니다.
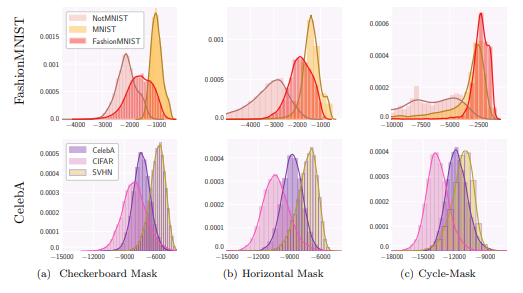
위의 그림은 마스크 변화 별, OOD 성능 변화로 제안하는 방법을 적용한 것 만으로도 in-dist에서 높은 가능도를 보여줍니다.
++ 하지만 CelebA(in-dist)에서는 여전히 SVHN(ood)이 높은 성능을 가진 한계를 보여줍니다.
st-networks with bottleneck
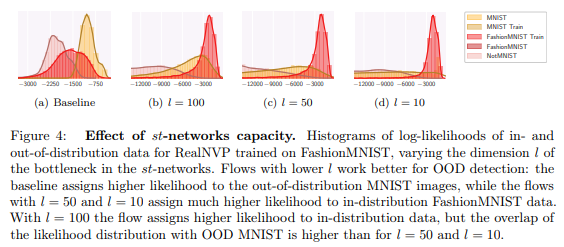
해당 실험에서는 아주 간단하지만 유의미한 전략을 선보입니다. st-networks에 dimension을 축소시키는 bottleneck을 추가하여 실험을 진행했으며, 실험적인 결과로 fig 4와 같이 dimension이 작아질수록 성능이 좋아지는 것을 실험적 결과를 통해 보여줍니다. 이는 semnatic feature가 강하게 추정되어질수록 OOD에서 좋은 성능을 보임을 보여줍니다.
Out-of-distribution detection using image embeddings
저자는 기존 NF은 graphical feature를 고려하는 특성을 가진 것이 문제임으로, OOD에서는 semantic feature를 보도록 하는 것이 중요하다고 주장하고 해결책을 제안했습니다. 여기서 마지막으로 저자는 여러 태스크에서 semantic feature를 사용하는 아주 흔한 기법을 추가합니다. 바로, 영상 그대로가 아닌 backbone으로부터 추출된 embedding feature를 이용하는 방법을 제안합니다.
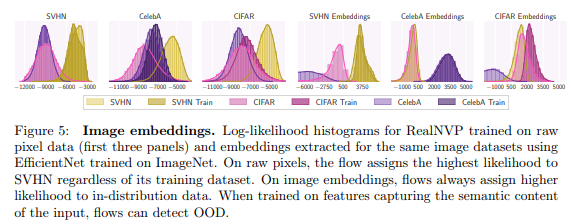
fig 5-4~6 패널은 ImagNet에서 사전학습된 efficientNet을 backbone 모델로 사용한 실험 결과로 놀랍게도 모든 케이스에서 in-dist에서 가장 높은 성능을 보여줍니다.
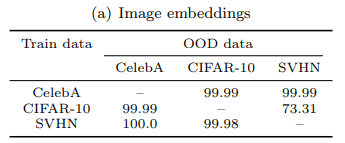
또한 각 케이스별 OOD의 AUCROC을 평가한 결과, 위의 표와 같이 굉장히 높은 성능을 보여줍니다.
==========================================================
해당 논문은 기존 NF이 OOD에서 좋지 못한 성능을 보이는 이유에 대해 모델 관점에서 분석을 진행했습니다. 저자는 이에 대한 원인으로 기존 NF의 ‘inductive bias’는 OOD에 적합하지 못한 모델 구조임을 지적했습니다. OOD에 적합한 NF 구조로 변경하기 위해 graphical feature에 집중하던 구조를 sematic feautre에 집중하는 형태로 디자인할 것을 제안했으며, 이는 실험적인 결과를 통해 입증되었습니다.
지금 진행 중인 논문에서 NF의 성능을 개선하기 위한 방법으로 super-resolution에서 각광 받고 있는 SRFlow를 적용하려고 했었습니다. 해당 논문을 읽지 않았다면 SRFlow를 지금 작성 중인 방법론에 붙이지 못해 아쉬웠을텐데… 헛수고를 하지 않아 다행이라는 생각이 듭니다. 역시 많이 아는 것이 삽질을 덜 하는 길인 것 같습니다.
++ super-resolution은 생성 모델을 이용한 방법론입니다.