이번 논문은 2021 sensors에 나온 Fully Automated DCNN-Based Thermal Images Annotation Using Neural Network Pretrained on RGB Data라는 논문 입니다. 해당 논문을 리뷰하게된 이유는 카이스트 데이터셋을 인용한 논문을 서베이하는 도중에 abstract를 읽고 흥미가 생겼기 때문입니다. 비교적 최신논문이고, Sensors 라는 좋은 저널에 accepted된 논문이기도 하고요.
Fully Automated DCNN-Based Thermal Images Annotation
Using Neural Network Pretrained on RGB Data
해당 논문에서 다루고자 하는 내용은 bad weather condition, low light condition 등 다양한 변수를 포함하고, 모델을 학습시키기에 충분한 양의 라벨정보를 가지고 있는 thermal 데이터셋이 많이 없는 문제를 해결하는 것 입니다.
아무래도 Thermal가 RGB에 비해서는 많이 대중화되지 않았으며, 그렇다고 새로운 Thermal 데이터셋을 취득하는것은 labeling cost가 많이 발생하기 때문에 비효율적입니다. 해당 논문에서는 이러한 labeling cost없이 기존 RGB 데이터셋에서 pre-trained된 모델을 활용하여 자동으로 thermal을 labeling을 하는 방법을 사용합니다.
뭔가… abstract를 읽었을때는 굉장히 거창해 보였는데 막상 다 읽고나니 생각보다 큰 contribution이 있는 논문이라는 생각은 안듭니다. 그 이유는 thermal 데이터가 부족한 근본적인 문제를 온전히 해결했다고 보기엔 어렵기 때문입니다. 논문에서도 이러한 부분에 대해서 솔직하게 완벽하게 해결 할 수는 없지만, 사람이 annotation을 하는 경우에도 그러한 문제는 발생한다고 적어두었네요. 그래도 전체적으로 보면 내용이 광범위하고 고생스러운 작업들을 한 흔적들이 보이며, 이러한 부분들 때문에 sensors에 게재 허가 되지 않았을까 합니다.

해당 논문에서는 위의 그림처럼 RGB와 Thermal 카메라와 더불어 LiDAR 센서로 취득한 point cloud데이터를 이용합니다. 기존에 RGB에서 pre-trained된 detector를 이용하여 새로 취득한 RGB영상에 annotation을 하고, 이를 thermal 영상에 투영하는 방식으로 thermal 데이터에 annotation을 합니다. 그리고 해당 투영하는 과정에서 point cloud 데이터를 통해 얻은 sparse 한 depth map 정보를 사용합니다. point cloud 데이터가 투영하는 과정에 왜 필요한지는 뒤에서 설명드리겠습니다.

결국 해당 논문에서는 RGB, Thermal영상과 포인트클라우드 데이터가 필요하기 때문에 위와같이 센서팩을 구성하였습니다. 그 밖에도 GNSS / IMU 센서등을 이용해서 point cloud 데이터의 정확도를 높였습니다.
해당 논문에서 kaist 데이터셋과 같이 beam 스플리터를 이용하는 방식은 special한 hardware가 필요하므로 자기들이 구성한 방식이 좀 더 universal하다고 주장하는데… 글쎄요 위의 센서팩을 보면 그렇게 simple 해보이지는 않지만 어떤 의도로 적은 말인지 이해는 갑니다.
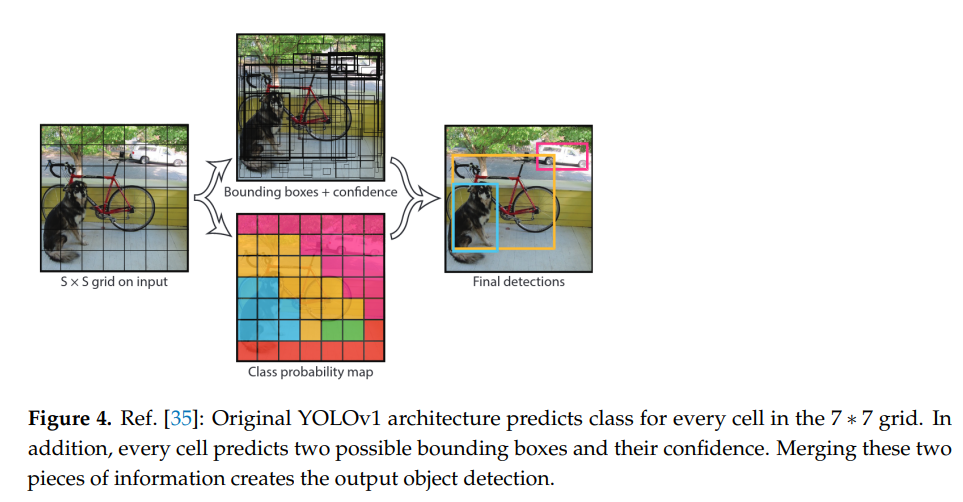
RGB 영상에서 pseudo label을 만드는 목적으로 YOLOv5를 사용합니다 (light weight이면서 efficient하여 사용하였다고 합니다.). 해당 논문에서 YOLOv5에 대해서 자세히 설명을 해놓았네요 참고하시면 YOLOv5 이해하시는데 도움이 될거 같습니다. 그치만, 1년전 논문이라서 그런지 YOLOv5가 단순히 YOLOv3를 Pytorch로 포팅해둔거라고 설명을 해두었는데 해당 부분은 틀린 정보로 실제로 YOLOv5에서는 YOLOv3에 추가적으로 v4에서 사용하는 augmentation과 다양한 최신 테크닉들(SPP/CSP등)이 사용됩니다.
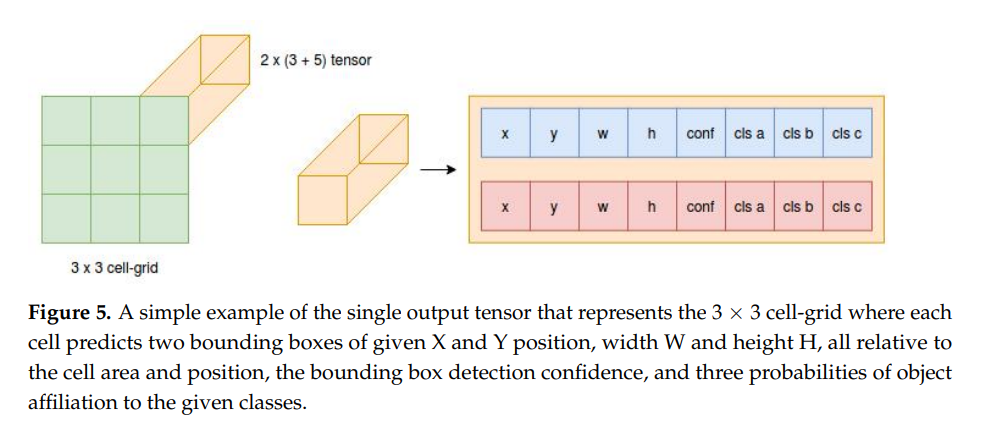
해당 논문에서 그린 그림같은데 figure 5를 통해 YOLOv5에서 grid map이 어떻게 구성되는지 설명합니다. 제가 이전에 했던 YOLO 리뷰를 참고하시면 해당 내용이 있으며, 본 리뷰에서 YOLOv5는 메인이 아니기때문에 생략하겠습니다.
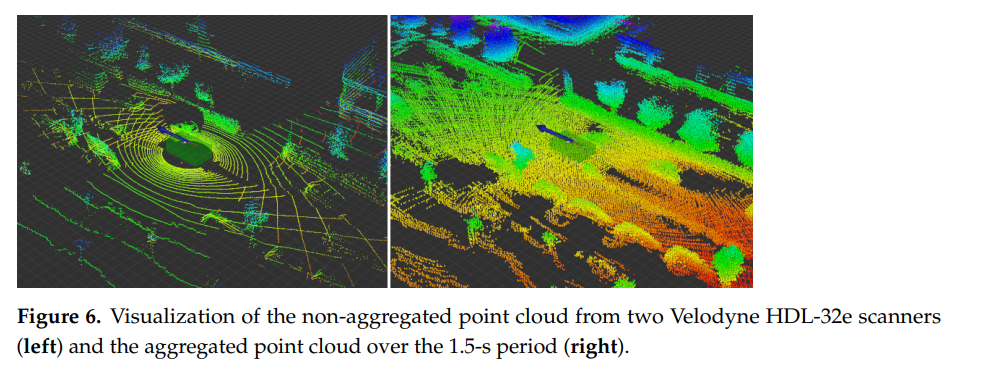
라이다센서로는 32채널을 사용하였으며, 한바퀴 돌때 약 2000개의 포인트가 취득됩니다. 그러나 이는 거리에 따라 상이하며, 약 30미터정도 떨어져있는 자동차의 경우 한바퀴 회전할때 약 10개 정도의 포인트만이 얻어집니다. 그렇기 때문에 그러한 경우 위의 그림과 같이 약 10바퀴(1초정도) 회전하여 얻은 정보를 누적 하였다고 합니다. 사실상… 당연한 부분이지만 페이퍼가 저널이고 23페이지나 되서 그런지 사소한거까지 TMI이다 싶을 정도로 디테일하게 적혀있네요.

RGB영상과 thermal 영상에 투영한 depth map의 모습입니다.

raw point cloud 데이터는 위와 같은 수식을 통해 homogeneous transformations(TF) 과정을 거치며 최종적인 P_world 포인트로 얻어집니다. 수식을 보면 해당 부분은 제가 정확히 이해한 것은 아니지만, Sensing된 sensor value가 1차적으로 imu 센서쪽으로 TF하고, 이후 car쪽으로 TF한다음에 world좌표계로 TF하는거 같습니다.
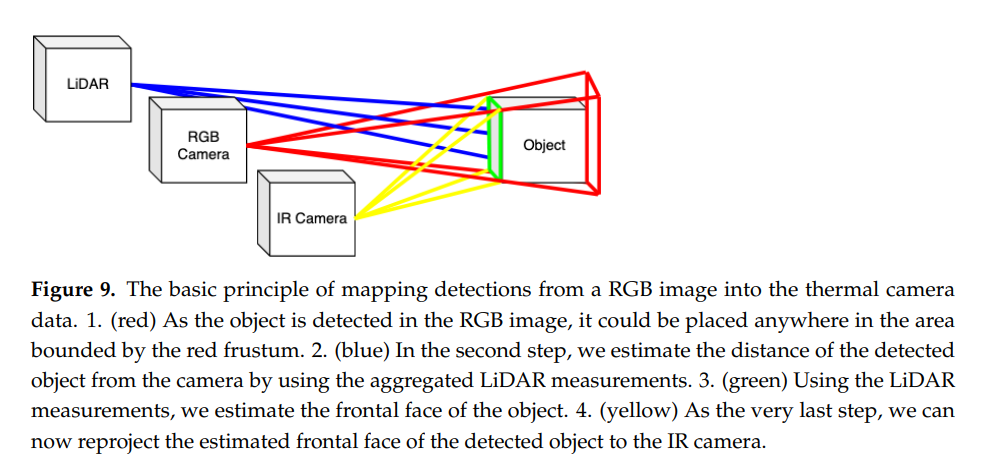
위의 그림을 보면 현재까지 진행한 과정들이 좀 더 직관적으로 보입니다. 결국에 해당 논문에서 하고자 하는 것은 coco 데이터셋 처럼 large-scale의 데이터셋에서 pre-trained된 detector를 이용하여 RGB영상에 pseudo label을 부여하고, 해당 pseudo label을 thermal영상에 투영하여 사용하는 것 입니다. 그 과정에서 포인트 클라우드 데이터를 사용하였으며, 그 이유는 위의그림처럼 포인트클라우드로 부터 얻은 Depth정보를 매개로하면 RGB와 Thermal간에 좌표변환이 용이하기 때문입니다. 그림에서 보면 object의 앞부분에서는 라이다센서, RGB센서, IR센서가 만나는 것을 볼 수 있습니다. 그렇게 만나는 부분을 매개로하여 RGB bbox정보를 Thermal로 변환하여 사용합니다.
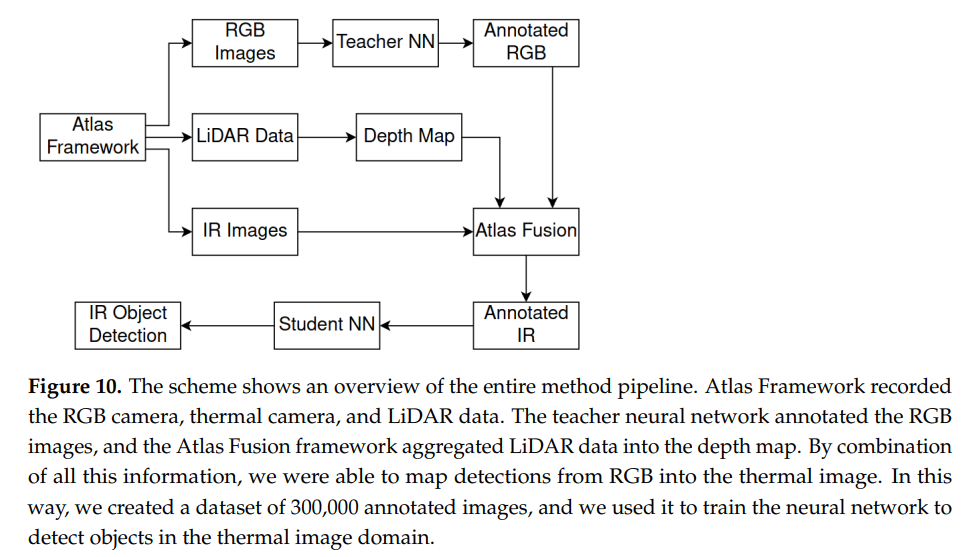
전체적인 프레임 워크는 위와 같으며, 해당 그림에서 Student NN은 Thermal에 투영한 Pseudo label을 가지고 학습한 모델을 의미합니다.
평가
평가에서는 FLIR과 BUDIR라고 명명한 자체취득한 데이터셋을 비교하였습니다. 즉 모델을 학습하는데 FLIR만 썻을때와 BUDIR 데이터셋을 이용하여 추가적인 학습을 하였을 때 성능 개선이 있었는지를 위주로 평가하였습니다.
또한, 해당 논문에서는 새로운데이터셋 Thermal 영상에 pseudo label을 부여하여 학습한 후 성능개선이 있는지 확인을 하는 목적으로 평가 데이터셋을 사용했기 때문에, FLIR데이터셋에 존재하는 RGB이미지는 사용하지 않았습니다.

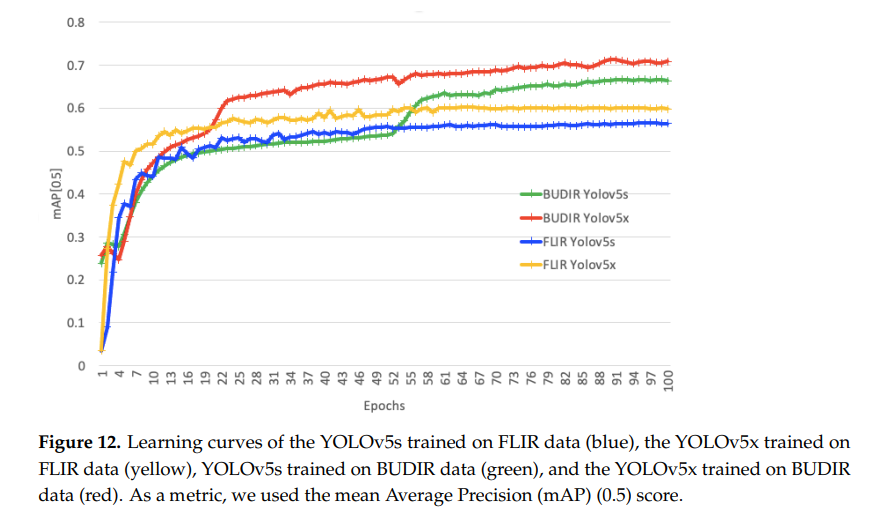
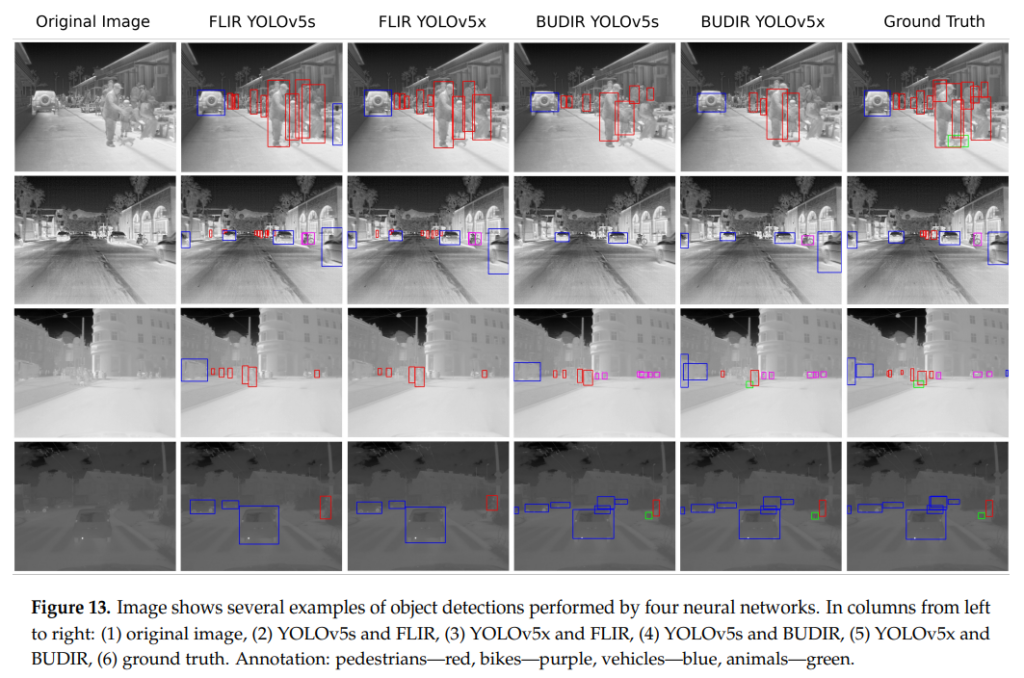
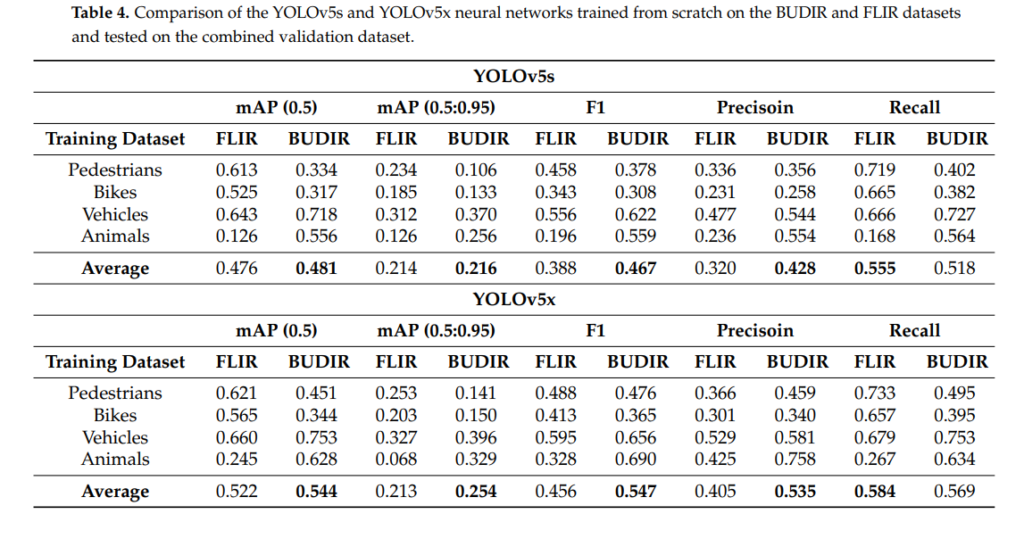
그 결과 BUDIR로 Large-scale Thermal dataset을 pseudo label로 annotation한 synthetic dataset으로 모델을 추가학습 하였을 때, 위와같이 성능개선이 있었습니다.
결론: 해당 논문에서는 사용한 방법론은 기존에 존재하는 방법론이며, contribution이 novel 하다고 보긴 힘들지만, 센서팩 구성, 다양한 실험, TMI급의 디테일한 설명 등 고생스러운 일을 많이 한 논문이었습니다.
RGB이미지랑 THERMAL이미지의 align을 맞추는 방법이랑 비교하면 뭐가 더 효율적인 방법일까요? Align만 맞추면, RGB 이미지 기반으로 pseudo label을 하는 부분은 동일할테니 큰 차이가 없으려나요?
align을 맞추는 방법이 빔스플리터를 말씀하시는거라면 빔스플리터로 맞추는 방법은 전체적인 이미지 밝기값을 저하시킨다고 알고 있습니다. 그밖에도 align을 stereo matching기반으로 depth맵을 구해서 맞추는 방법은 아무래도 lidar를 이용한 depth map보다 정확하지 않겠죠. 각 방법론마다 장단점이 있다고 생각합니다.
과거에 ‘Brno Urban Dataset’ 을 테크공유에 올린적 있는데, 해당 데이터를 이용한 후속연구 인거 같네요(저자가 겹치네요) 근데 중요한건 마지막 표에서 Person이나 Bike는 오히려 성능 드랍이 일어나는데, 이부분에 대해서 논문에 언급은 없나요?
제 기억에 직접적으론 없었고 간접적으로는… flir 데이터셋에 animal 클래스에 대한 imbalance 문제가 있었고, 해당부분을 그대로 재현하여 데이터셋을 구성했다라는 얘기를 합니다. 이러한 이유로 validation set을 나누지않고 test set을 val로 사용하기도 하였는데요. 아마 그러한 부분때문에 animal에서 성능향상이 컸고, 일부 클래스에 성능드랍이 있었어도 전체적인 average도 성능이 향상되지 않았나 싶습니다.
데이터 셋의 특성을 이용하여 다른 도메인간의 self-training을 제안한 측면에서는 의미있는 논문인 것 같습니다.
근데… 아쉬운 점이 제약 조건이 많아 실용성이 떨어지는 기술인 것 같습니다.
한가지 궁금한 점은 추가 학습을 진행하였을 때, 밤 낮에서의 성능 평가는 따로 없었는지 궁금합니다. 밤에서도 성능 향상이 있었고, 이를 어필 했다면 더 좋은 논문이 되었을 거란 생각이 드네요.
제약조건이 많다는 말에 동의합니다. 아쉽게도 낮과 밤에 대한 구분은 따로하지 않습니다.