
지난 리뷰에 말씀드렸던 것처럼 오늘 리뷰에서는 HNIP에 대해 다루고자합니다. 사실 NIP의 개선 버전이라 생각되어 HNIP의 디테일을 다루고자 하였는데, 알고보니 거의 동일한 방법론이었습니다. 그나마 차이라고 보여지는 것이 어떤 것이 있는지 아래서 설명 드리겠습니다.
1. Nested Invariance Pooling
이 논문 이전(약 2017년도 이전)에는 주로 handcrafted feature들이 많이 활용되던 시절이였고, SIFT와 같은 방법론과 같이 feature가 여러가지의 invariance한 특징을 지니고 있었습니다. 이후, 딥러닝이 발전하면서 CNN을 활용한 딥러닝 기반의 방법론들이 일반적인 상황에서 좋은 성능을 보여왔고 handcrafted feature을 대체하기 시작하였습니다. 그러나 설계 자체가 invariance 를 목적으로 진행된 handcrafted feature와는 달리, 초기 CNN의 feature는 invariance를 목적으로 두지 않아 강인하지 못했습니다.
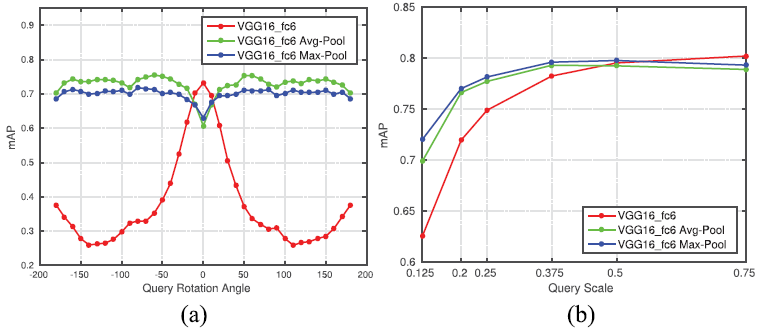
이는 Fig 2를 통한 실험에서도 나타납니다. 먼저 Fig 2는 Holidays라는 데이터 셋에서 image retrieval을 한 성능입니다. 이를 위해 당시 유명하던 VGG16을 backbone으로 활용하였습니다. 우선 (a)는 query를 -180도부터 180도까지 회전(rotation)시켰을 때 성능을 나타냅니다. (a)의 빨간 선을 보신다면, rotation이 0일 때와 0이 아닐 때 성능차이가 큰 것을 확인할 수 있습니다. 그리고 (b)는 query의 해상도를 default에서 0.125배부터 0.75배까지 변경시켰을 때의 성능을 나타냅니다. 이때도 빨간 선만을 보신다면, 해상도가 낮아질 수록 성능 차이가 큰것을 알 수 있습니다. 이러한 결과들을 통해 CNN에서 직접적으로 얻어진 feature에는 rotation과 scale에 대한 invariance가 부족한 것을 알 수 있습니다.
이와 같은 CNN의 invariance가 부족한 문제를 해결하기 위해, 해당 논문의 저자는 Invariance theory를 활용하였다고 합니다. Invariance theory에서는 이미지 x가 있고 transformation group g가 있고 transformation에 강인한 함수 f가 있을 때, f(x) = f(g*x)여야 한다고 주장합니다. 또한, transformation에는 translation, scale, rotation이 존재하며, 특정 statistical moment (mean, max, standard deviation)가 앞선 transformation에 invariance하다고 수학적으로 입증하였다고합니다.
이러한 Invariance theory에 영감을 받아 본 논문의 저자는 CNN feature에 statistical moment를 적용하여 invariance를 취득하고자 하였습니다. 사실 이는 CNN feature에 세 번의 pooling을 적용함으로써 invariance를 취득하고자 하였습니다. 예상외로 나이브해보일 수 있지만, statistical moment의 mean, max, standard deviation은 곧 average pooling, max pooling, square-root pooling으로 나타날 수 있기에 이 같은 방식을 활용하게 된 것 같습니다. 뿐만 아니라 앞서 설명드렸던 Fig 2의 (a), (b) 모두 VGG16 feature에 아무것도 적용하지 않은 빨간 선 대비 특정 pooling을 적용한 초록 선과 파란선의 성능이 균일했던 점도 이 방식이 나이브하지만 유의미하다는 것을 의미합니다.
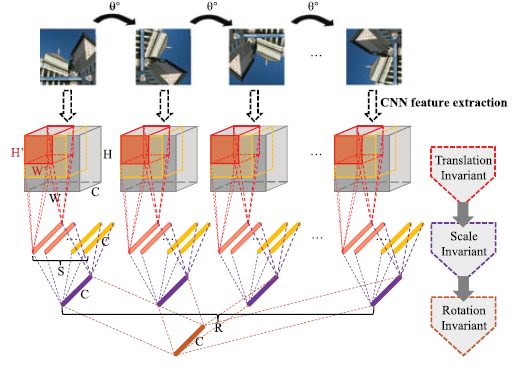
그래서 결국, 본 저자는 CNN feature에 invariance한 성질을 추가하기 위해 세번의 pooling을 적용하였습니다. 세번 pooling의 목적은 순서대로 translation, scale, rotation이며 Fig 3과 같습니다. 먼저 translation invariant를 위해 feature map의 크기 (HxWxC)보다 작은 크기 (H’xW’)의 region을 두고 G_t pooling 연산을 하였습니다. 이때 scale invariant를 위해 적용되는 region 크기 (H’xW’)의 종류를 S개로 다양하게 두어 여러 scale에 대해 연산하게 하였고, 이를 각각 G_t pooling 연산한 뒤 서로 다른 scale에 대해 강인하도록 G_s pooling 연산하였습니다. 마지막으로 rotation invariant를 위해 이 과정을 인풋 이미지를 N번 회전시켜 각각 적용하였으며, G_t, G_s pooling이 적용된 N개의 feature에 G_r pooling을 적용시켜 세 변환에 invariant한 하나의 NIP feature를 생성하였습니다.
여기까지가 NIP였고, 앞서 소개드린 NIP의 세가지 pooling 방식을 모두 동일한 pooling으로 사용하지 않을 때 Hybrid NIP라고 합니다. 예를 들어, G_t, G_s, G_r pooling을 각각 max, max, max pooling으로 사용하였다면 NIP이긴 하지만 HNIP는 아닌것이고, square-root, average, mean pooling으로 사용하였다면 NIP이기도 하고 HNIP이기도 한 것입니다. 조금 의문이 생기실 수도 있으나, 저도 처음에는 당황스러웠고 NIP를 다룬 여러 논문을 참고하면서 내린 결론입니다. NIP를 다룬 논문들에 대해 아래서 간단히 소개드리겠습니다.
- [ICMR 2017] Nested Invariance Pooling and RBM Hashing for Image Instance Retrieval
- NIP를 처음 다룬 논문 입니다. 위에서 설명드린 것처럼 Invariance theory에 영감을 받아 NIP를 제안하였고, G_t, G_s, G_r pooling을 각각 average, square-root, max pooling으로 사용하였습니다.
- [TMM 2017] HNIP: Compact Deep Invariant Representations for Video Matching, Localization and Retrieval
- 오늘 리뷰 드린 논문입니다. 해당 논문에서도 NIP를 제안하였다고 언급되어 있으며, HNIP도 제안하였다고 합니다. G_t, G_s, G_r pooling을 하나의 동일한 pooling으로 사용하지 않는 것을 HNIP로 구분하였습니다.
- [Data Compression Conference 2017] Compact Deep Invariant Descriptors for Video Retrieval
- 이 논문도 NIP를 제안하였다고 소개한 논문입니다. HNIP를 다룬 위 논문과 마찬가지로 동일한 pooling 전략을 가져가고 있지만, 해당 논문에서는 HNIP라는 단어를 찾아볼 수 없습니다.
- [IEEE MM 2017] Compact Descriptor for Video Analysis: the Emerging MPEG Standard
- CDVA framework를 다룬 논문이며, 그 중 NIP를 활용하였다고 언급되어 있습니다. 다만 어떤 pooling을 사용하였는지 나타나있지 않습니다.
이처럼 NIP라는 방법에 대해서 서로 다른 4가지 저널에 투고가 되었으며 각 저널 별로 NIP를 제안하였다고 소개되어 있습니다. 네 논문의 저자가 모두 상당 수 겹치는 것으로 보아, 우연히 서로 다른 기관에서 낸 것 같지도 않아보입니다. 이들을 다 읽어보며 NIP와 HNIP에 대한 구별점을 말씀드리긴 했으나 사실 그 차이가 크지는 않습니다. 또한 같은 전략을 언급한 논문들도 같은 데이터 셋에서 리포팅한 성능이 서로 다릅니다. 여러가지 생각이 들지만, 여기서 리뷰를 마치도록 하겠습니다. 성능은 평가는 HNIP 논문에서 리포팅한 MPEG-CDVA 데이터 셋에서의 성능을 마지막으로 남겨두겠습니다.

2. Referenece
[1] https://vijaychan.github.io/publications.html