2021년 CVPR에서 Oral paper로 선정된 논문입니다.
해당 논문을 리뷰하기에 Generavtive model에 대해서 잘 설명된 자료를 찾아 공유드립니다.

해당 논문은 이러한 Generavtive model을 통해 수행하는 Image Synthesis에서 Transformers의 아이디어를 적용하여 High Resolution의 이미지를 생성하였다고 합니다. 해당 논문에서 사용한 방법은 아래와 같습니다.

Learning an Effective Codebook of Image Constituents for Use in Transformers
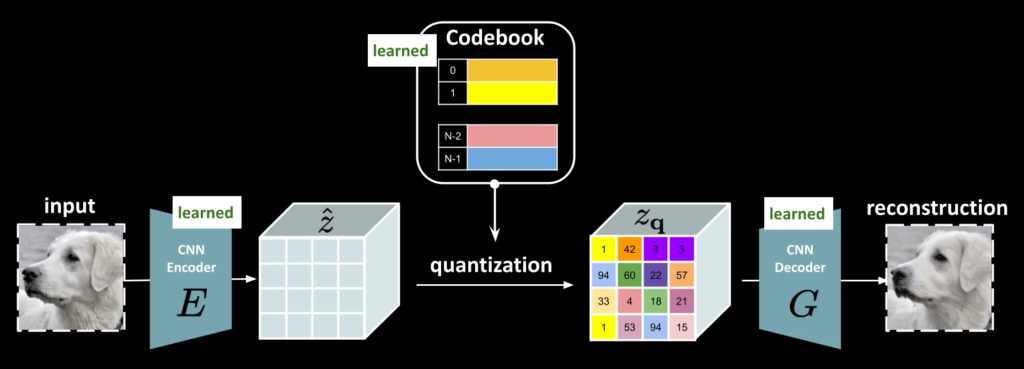
VQ-GAN의 방식은 위의 그림과 같습니다. 이미지를 CNN Encoder를 이용하여 Featuremap을 얻습니다. 그리고 각각 feature vector와 가장 유사한 codebook vector를 찾고, 그 codebook vector로 변경한 후 이를 Decode를 통해 reconstruction image를 계산하게 됩니다.
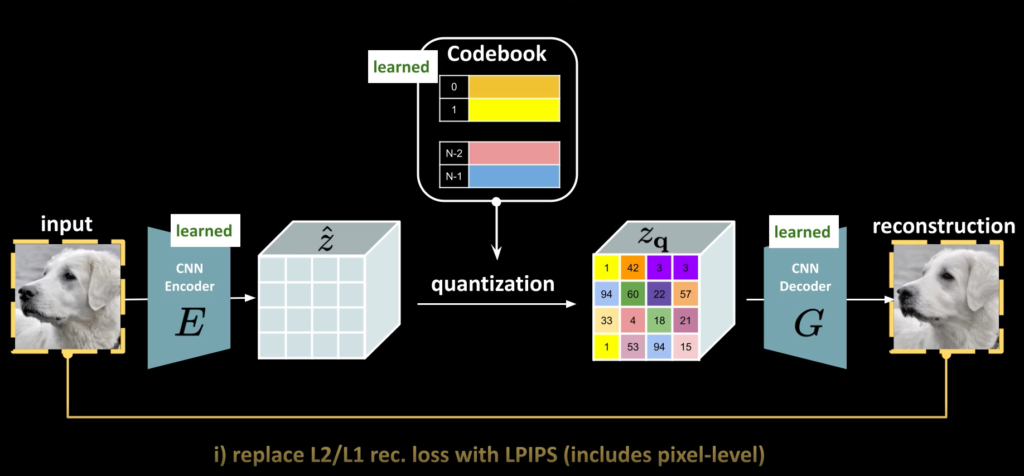
그래서 input 이미지와 reconstruction 이미지에서 Loss를 계산하여 모델을 학습합니다. 자 근데, 중간에 quantization과정이 들어가면 미분불가능 해져 모델이 학습할 수 없습니다. 저자는 이를 해결하기 위해 단순히 디코더의 gradients를 인코더로 복사하였다고 합니다. 이를 수식으로 나타내면 다음과 같습니다.
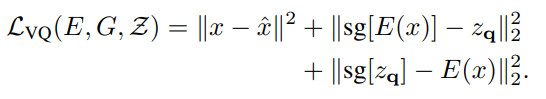
가장 먼저 있는 L2 Loss는 앞서 설명한것처럼 Reconstruction loss를 의미하며 텀은 인코더를 통해서 나온 z와 quantization을 통해 얻은 zq의 차이를 loss로 설계하였으며 sg는 stop gradients(미분이 불가능하므로 끊음)를 의미합니다. 저자는 이를 commitment loss라고 이야기합니다.
Learning a Perceptually Rich Codebook
저자는 Rich codebook을 배우기 위해서 GAN을 적용합니다. 이렇게되면 좀 더 자연스러운 영상이 만들어질 수 있다고 합니다.
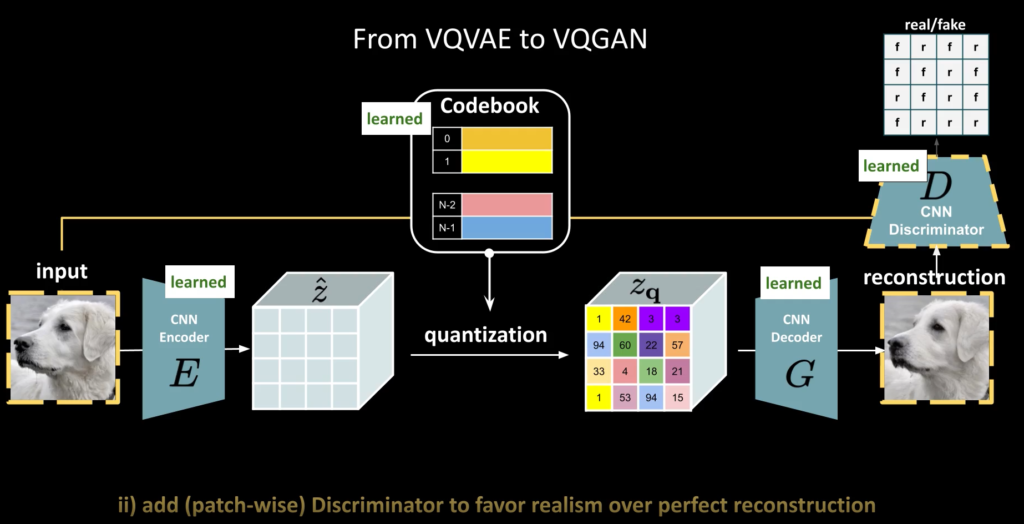
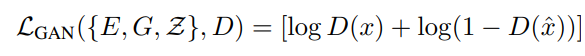
일반적으로 GAN에서 사용하는 Loss이며, 이를 추가하여 최종적으로 Codebook을 학습하기 위한 Loss는 다음과 같습니다.
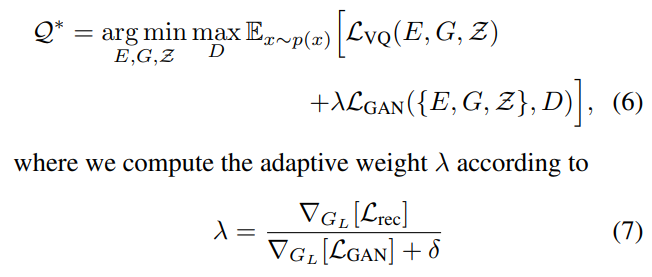
(추가로 GAN Loss는 Adaptbe weight를 적용하였으며 수식은 (7)과 같다고 합니다.)
여기서 1차적으로 중간정리하자면 현재 앞선 방법은 결과적으로 ‘Codebook of Image Consituents’ 을 잘 만들기 위한 과정입니다. 그리고 이러한 Codebook이 있으면 이를 Transfomer에 기존 NLP처럼 적용할 수 있습니다. 아래 예시는 모델이 ‘I am a student’라는 문장을 만든다고 생각하면 ‘I’ 라는 첫번째 입력이 주어지면 연속적으로 뒤에 단어들을 생성하게 됩니다.
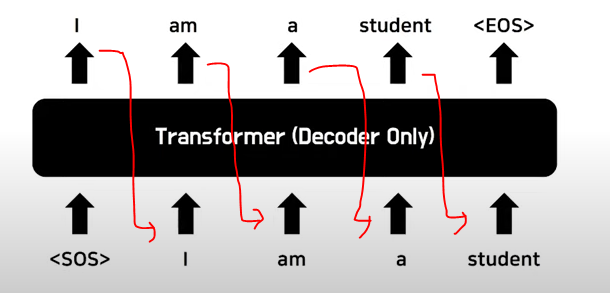
이러한 컨셉과 동일하게 앞서 잘 만들어진 Codebook을 이용하여 ‘I’ 와 같이 초기 입력을 주거나, 혹은 일부 아니면 임이의 입력을 주게되면 Transfomer를 이용하여 이후 들어갈 Code book을 생성하게되며, 이것을 앞서 학습한 VQ-GAN에 입입력하면 새로운 영상이 만들어지게 됩니다.
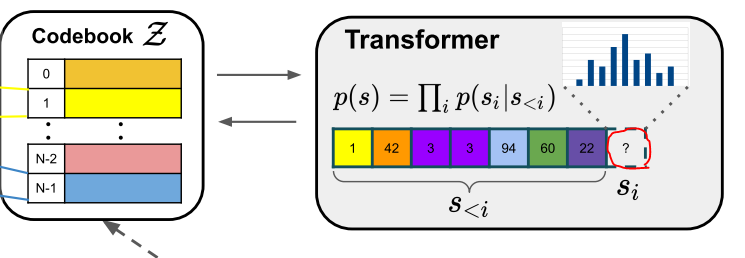
정리하면, 위에 ‘Transformer’를 보시면 ‘1-42-3-3-94-60-22’ 와 같은 흐름이 주어질때 다음번에 등장할 Codebook vector를 Transformer를 통해서 예측하면되고, 이는 실제 NLP에서 마지막에 softmax를 이용하여 Lookup table에서 단어를 선택하는것과 동일하다고 생각하시면 됩니다. 그리고 Image-to-Image translation과 같이 내가 주어진 입력에 맞춰서 이미지를 생성하고 싶으면 아래와 같이 입력 이미지(Condition)을 사용하면 된다고 합니다.
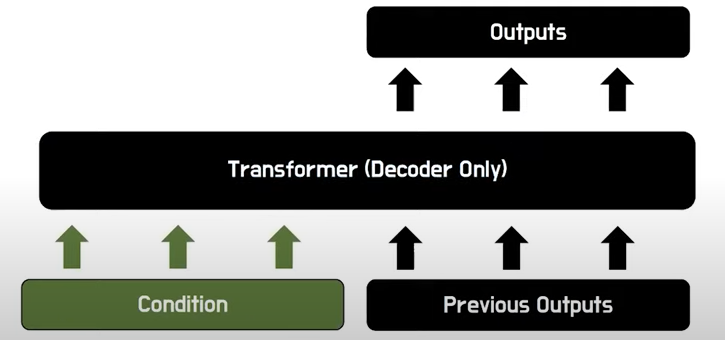
Generating High-Resolution Image
마지막으로 본 논문의 제목과 같이 고해상도의 이미지를 만들기 위한 방법은 다음과 같습니다. 일반적으로 고해상도의 이미지는 sequence voctor들이 너무 많아지게 됩니다. 그러면 많은 연산량이 필요할 수 있는데, 이를 효율적으로 수행하기 위해서 본 논문에서는 Sliding attention window를 제안하고 있으며 아래 그림과 같습니다. 즉, 주위 일부 codebook vector 만을 Transformer의 입력으로 사용하여 다음 자리에 알맞는 codebook vector를 선별하겠다는 내용입니다.
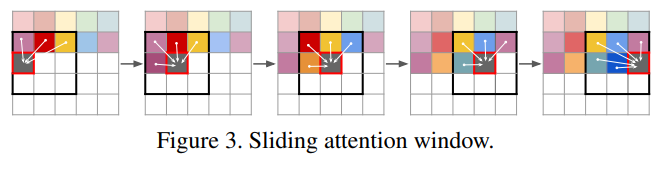
Experiments
이러한 자신들의 방법을 본 논문에서는 다양한 분야에 적용시켜 효과적임을 입증하고 있습니다.
https://compvis.github.io/taming-transformers/?utm_source=catalyzex.com
해당 논문의 프로젝트 페이지에서 영상으로 나타내고 있으니, 관심이 있으신 분들은 확인해봐도 좋을 것 같습니다.
이미지를 생성하기 위한 풍부한 정보가 담겨진 Codebook을 만들고 이러한 Codebook을 실제 NLP에서 사용되는 것처럼 사용하여 이미지를 생성했다는 것이 새롭고 재미있는 아이디어였습니다.
리뷰 잘 읽었습니다.
궁금한 내용들이 몇가지 있는데
먼저 Quantization으로 인해 gradient 계산이 되지않아 디코더의 gradient를 encoder로 전달해준다고 하셨는데 gradient를 어떻게 전달할 수 있는 건가요?? 어떻게 구현되는지 정리가 잘 안되네요.
그리고 두 번째로는 L_{vq} loss 계산하는 부분에서 sg(E(x) – z_{q}도 있고 반대로 sg(z_{q})-E(x)도 있는데 이렇게 둘이 따로따로 적용해주는 이유는 무엇인가요? stop gradient를 각기 따로 적용해서 loss를 계산하면 학습에 어떤 영향을 주는 것인지 잘 모르겠네요.
세 번째 질문으로 코드북은 어떠한 shape을 가지고 있나요? N이 코드북의 총 길이인 것 같은데 1x1xc길이의 벡터들이 N개 있는 형식인가요? 그리고 논문에서는 N값은 몇으로 설정하나요?
네 번째 질문으로는 전체 파이프라인을 나타내는 그림에서는 CNN Encoder와 CNN Decoder라고 존재하는데, 리뷰 내용에는 Transformer 디코더가 나옵니다. 코드북을 생성하기 위해서 Transformer Decoder가 사용되고 그렇게 생성된 코드북으로 영상을 만들때는 CNN Decoder를 사용하게 되는 것인가요?
마지막으로 이 방법론은 속도가 어떻게 되나요? 고해상도의 영상을 빠르게 생성한다고 하셨는데 다른 방법론과 비교한 결과는 없나요?
1. quantization으로 gradient가 계산되지 않기 때문에 본문에 표기한것처럼 디코더의 gradient 값을 복사하여 인코더에서 사용한다고 나타내고 있고 해당방법은 아래 논문을 참고했다고 합니다. 역전파 과정에서 미분이 불가능한 노드(quantization)에서 계산을 중지하고 그 값을 해당 노드를 스킵하여 뒷 노드에 붙여넣고 역전파를 이어서 진행하는게 아닐까요? 자세한 부분은 코드를 보면서 확인이되면 공유드리겠습니다.
Yoshua Bengio, Nicholas L´eonard, and Aaron C. Courville.
Estimating or propagating gradients through stochastic neurons
for conditional computation. CoRR, abs/1308.3432,
2013
2. 해당 논문은 코드북도 학습합니다. 그리고 그 코드북은 결국 CNN인코더를 통해서 나온 벡터들을 이용해 만들게 됩니다. 그래서 인코더를 통해 만든 벡터 E(x)가 z_q와 최대한 비슷해야하며 동시에 z_q(quantization을 통해 나온 벡터 즉 코드북의 벡터)의 값과 인코더를 통해 나온 벡터 E(x)가 가까워지도록 loss를 설계해야 합니다. D(E(x)) 였던 기존 구조를 중간에 z_q가 포함되고 이로 인해 미분이 되지 않기 때문에 이 과정을 위에 stop gradient를 포함하여 loss를 설계하였습니다. 결론은 코드북도 학습하기때문에 해당 loss가 설계됐습니다.
3.코드북의 차원은 임의로 정할 수 있습니다. 논문에서 이에따른 성능차이도 리포팅하고 있습니다. 512,1024,16384의 차원에 따른 결과가 나타나있네요
4. 본문에서의 Transformer 디코더는 시퀀스한 코드북을 구할때 사용하는 디코더를 의미하며 이미지 생성을 위한 디코더는 CNN디코더를 사용합니다. 기존 NLP에서 Transformer를 생각해 보시면 “I am a”라는 입력이 들어가면 Transformer에서는 다음 단어로 “I am a student”, “I am a boy”등 다양하게 완성된 문장을 만들게 됩니다. 이처럼 I, am, a 와 같은 각각의 입력이 코드북의 벡터형태로 들어가면 학습된 Transformer의 디코더는 이전 시퀀스의 벡터들을 보고 NLP의 student, boy와 같이 적절한 다음 벡터를 확률적으로 선택하게 되며, 이렇게 다음 순서의 코드북 벡터의 선택들이 모이면 이를 CNN 디코더로 이미지를 생성하게 됩니다. 따라서 결론은 CNN 디코더, Transformer 디코더 모두 사용되며 그 쓰임이 다릅니다.
마지막으로 빠른 속도를 위해서 앞서 설명한 sliding window 형태로 모든 이전 코드북 벡터들을 보고 다음 벡터를 예측하는게 아니라 3×3 정도의 주변 코드북 벡터들을 보고 다음 코드북 벡터를 선택하기 때문에 빠르면서 고화질의 이미지 생성이 가능하다고 이야기하고 있습니다. 근데 이를 다른 방법론들과 속도적인 측면에서 비교하지 않았습니다. 여러가지 이유가 있겠으나 해당 분야에서는 어떠한 결과가 정해져있는 detection, segmentation와는 다르게 기존 모델들과의 직접적인 속도를 비교하는게 덜 중요하지 않을까요?( 각 모델마다 만들어내는 결과물의 퀄리티를 더 중요하게 생각하고 있어서 그런게 아닐까요 )
아무튼 답변이 도움되시길 바라며, 더 궁금한점은 논문에서..