이번주 리뷰부터는 video retrieval 관련 논문으로 돌아왔습니다. 시작은 간단하게 데이터셋 논문부터 시작합니다. VCDB는 비디오 관련 데이터셋으로 많이 쓰이는 데이터셋입니다. ViSiL도 이 데이터셋으로 학습을 하고 있고. 기본적으로는 논문 제목처럼 partial copy detection용 데이터셋입니다. 특징이라면, 528개의 비교적 적은 core dataset과 10만개의 많은 background dataset이 있다는 점입니다. 그럼 시작하겠습니다.
Introduction
Video copy detection을 하기 위해서는 크기나 조명 변화와 같은 컨텐츠 변형으로 인해 어려운 task라고 합니다. 이 당시에 이런 문제를 해결하기 위해 쓰는 방법이 SIFT와 같은 descriptor를 이용하는 방법이 있었다고 하네요.
이러한 문제는 뒤에 두고, 데이터셋 그 자체의 문제도 있었습니다. 기존의 데이터셋들은 A 비디오와 B 비디오가 존재한다면, A와 B가 서로 유사한지만 알려준다는 문제점이 있었습니다. VCDB에서는 이 문제점을 인식해서 A와 B사이의 어느 부분이 유사한지까지 정보를 알려줍니다. 그럼 어떻게 데이터를 모으고, 라벨링했는지 보겠습니다.
Creating VCDB
Database Collection
Core dataset은 Youtube와 MetaCafe로 부터, background dataset은 youtube로부터 얻었다고 합니다. 주제는 좀 다양한 주제로 28개를 선정했고, 주제당 약 20개의 비디오를 조회수 순으로 다운받았다고 합니다. 이렇게 검색해서 다운받은 영상들은 복사된 비디오 영역들을 공유한다고 합니다.
최종적으로는 528개의 비디오를 선별했다고 합니다. 그럼 background dataset은 왜 있냐고요? 그건 좀 더 현실적인 시나리오에 맞추기 위해 있다고 하는데, baseline에서는 노이즈로 활용했습니다. (좀 더 나중의 ViSiL에서는 triplet loss에서의 negative 쌍으로 활용합니다.)
Annotation
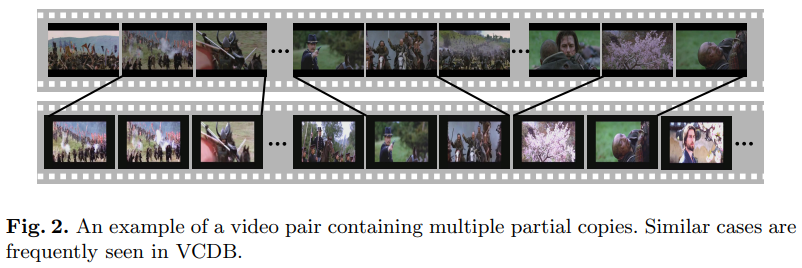
위 그림이 예시인데요. 프레임별로 라벨링을 수행했다고 합니다. 아웃소싱을 맡기기 보다는, 전문 라벨러를 고용해서 수행했다고 하고요. 사실 이 부분이 놀라웠는데요. annotation tool 개발에 꽤 공을 들였다고 합니다. 동일한 세그먼트가 있을 경우에 자동으로 추천해주거나, 두개의 비디오를 개별적으로 볼 수 있거나 하는 방법을 이용해서 라벨링 시간과 정확도를 높일 수 있었다고 합니다.
Statistics

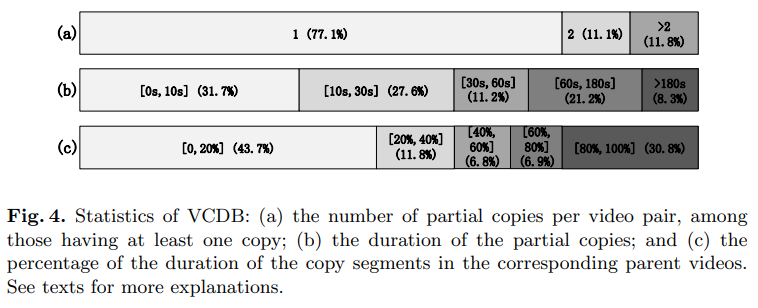
위 그림은 예시 그림과 통계 자료인데요. 통계 자료는 아래와 같습니다.
- A) : 한개 이상의 복사본을 가지고 있는 비디오 복사본의 쌍의 수
- B) : 복사 영역의 시간
- C) : 복사된 영역의 비율
최종적으로는 9236개의 partial copies 쌍이 있었다고 합니다. 위 통계 표와는 다르게 논문 본문에 이 9236개의 쌍을 만드는데, 어떤 변형이 가해졌는지에 대한 설명이 있습니다. 36%는 “insertion of patterns”, 18%는 “camcording”, 27%는 크기 변화, “2%”는 “picture in picture”였다고 하네요.
이러한 양상은 기존의 데이터셋과는 크게 다른 양상이라고 합니다. 실질적으로는 “picture in picture”는 현실에 거의 없는데도 불구하고 기존의 데이터셋에 비중있게 존재했다는 것이고, 현실에는 TV 로고 등으로 인해 “insertion of patterns”이 많다는 것이죠. VCDB가 현실적인 데이터셋임을 잘 보여주는 분석이었습니다.
Baseline System
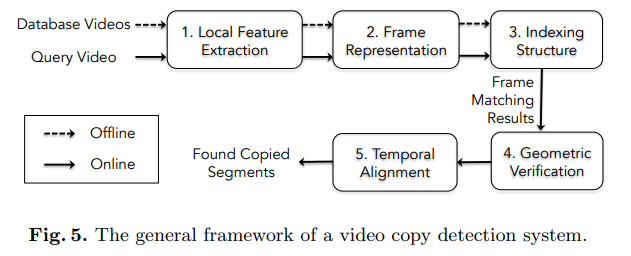
위 그림이 baseline system을 보여주는 그림입니다. (혹시 online과 offline 용어를 어떻게 쓰는지 아시는 분이 있다면 댓글에 남겨주시면 감사하겠습니다… 설명이 없네요.) 각각의 단계별로 어떻게 구성했는지 알아봅시다.
Feature Extraction and Frame Representation
각각의 프레임으로부터 local SIFT descriptor를 뽑은 다음에, BoV를 이용해서 하나의 feature로 만든 것으로 보입니다. 이렇게 되면 이 codebook이 Voronoi cells로 표현된다고 하네요.

참고로 Voronoi cells은 이런겁니다. 저는 몰라서 검색을 해봤던 내용이라, 읽으시는 분들도 참고하셔서 읽으시면 좋을 것 같습니다.
Indexing and Hamming Embedding
online frame matching을 효율적으로 수행하기 위해 Inverted file 구조를 사용합니다. Inverted file은 이제 visual search 발표에서 소개해드렸으니… 넘어가겠습니다. 그리고 BoV에서의 오류 완화를 위해 hamming embedding이 사용되었다고 합니다. 이 hammind embedding의 핵심 아이디어는 위에서 보여드린 voronoi cell을 또 여러 공간으로 분할하는 것인데, 이렇게 되면 결국 각 공간이 binary code로 표현되고 hamming distance에서 쉽게 계산될 수 있다는 것입니다.
Geometric Verification
위의 방법이 항상 옳지 않기 때문에 이제 우리는 geometric한 정보들을 바탕으로 잘못된 match를 지워나가는 방법으로 Geometric Verification을 수행해서 정확도를 높일 수 있다고 합니다. 이 방법을 위해 week geometric consistency(WGC)라는 방법론을 적용했고, 이 방법론은 SIFT descriptor의 angle과 scale parameter를 기반으로 작동한다고 합니다.
Alignment by Temporal Network and Temporal Hough Voting
잘 맞췄으면 구간을 잘 정렬해야겠죠? 이 논문에서는 Temporal Network를 이용하는 방법과 Temporal Hough Voting을 이용하는 방법, 두 가지 방법을 이용하고 비교 실험을 수행했습니다.
Experiments
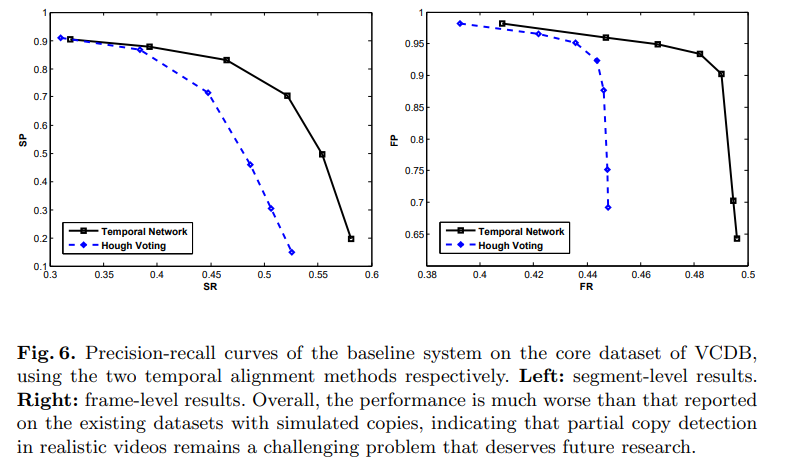
VCDB에서 실험 결과를 보면, Temporal Network기반 방법론의 성능이 더 좋은 것을 볼 수 있습니다. 그리고 해당 실험에서 정답과 단 1프레임이라도 겹친다면, 정답이라고 계산했는데요. copy detection의 목적성을 생각하면 이게 더 적합하기 떄문에 그렇게 했다고 합니다.
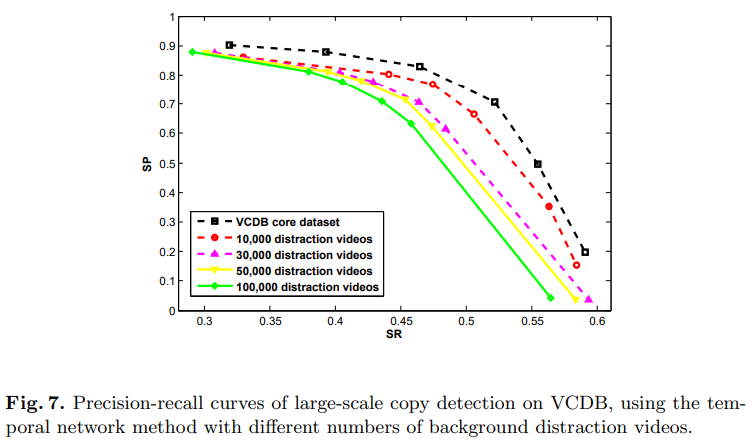
이건 노이즈로 추가된 background dataset의 크기에 따른 성능 비교 표입니다. 성능이 떨어지기는 하지만, 추가된 distaction vidoe의 양을 생각하면, 성능적으로는 괜찮다고는 하는데… 성능 떨어지는 것을 보면 정말 괜찮은지는 모르겠습니다.

위 그림은 잘못 탐지된 예시인데, 저는 오른쪽 위만 copy라고 생각했는데, copy detection의 범주가 제가 생각한 것보다 넓다는 것을 깨닫게 되었습니다.
결론
되게 유명한 데이터셋이라 한번쯤은 읽어봐야겠다고 생각하고 있었는데, 이번 기회에 읽게 되었네요. 비디오 검색 과제에서 사용할 데이터셋에 대한 고민도 하고 있는데, 꽤 도움이 된 것 같습니다.
Voronoi cells 이 의미하는 바는 어떤 것인가요??
논문에서 codebook을 k-means를 이용해서 클러스터링 해두는데요. 그 클러스터링 된 형태를 Voronoi cells이 된다고 논문에 되어있네요. 작성하면서 k-means 내용이 빠지니까 이상해진걸 지금 봤습니다.
혹시 Video Net 구축에 대한 insight를 얻기 위해 VCDB 논문을 읽으신건가요?? 하하
그런건 아니었는데 타이밍이 겹쳤네요 ㅋㅋ… 스터디 때문에 읽었습니다.