Visual Search 3부작의 마지막은 Pinterest입니다. 다음 리뷰부터는… video retrieval로 다시 돌아갈 예정입니다. 마지막으로 소개할 Pinterest는 시기상으로는 ebay → pinterest → Bing 이라 중간이라고 보시면 됩니다.
소개할 논문은 두편을 합친 내용입니다. Discovery → Search 순으로 논문이 작성되었는데, Discovery의 경우 이미지 feature 추출에 관한 내용이 주를 이루고, Search의 경우에는 시스템적인 부분에서의 설명이 주를 이룹니다.
그리고 Pinterest는 이미지 사이트죠? 패션 추천 서비스도 운영중이지만, 사용자가 pin이라고 담은 이미지들을 기반으로 새로운 pin을 추천해주는 서비스도 운영중인 사이트 같습니다. 이런 서비스를 하는 곳이라는 것을 참고하면 좋을 것 같습니다.
리뷰는 Discovery → Search 순서로 합쳐서 정리했습니다.
Introduction
이 시점의 논문들 (17년)들이 다 그렇듯이 GPU와 CNN의 등장으로 인해 이미지 classifiaction 성능과 object detection 성능이 올랐다고 합니다. 게다가 pinterest의 경우 일반적인 search(finding answers)보다는 아니라 browse(finding inspirational or related content)하기 위한 사이트이기 때문에 visual search에 적합한 유저들을 많이 보유하고 있다는 특징이 있습니다.
하지만 문제는 상업적인 visual search platform을 만드려면 역시 돈이 문제죠. 결국은 이게 상업적으로 잘 작동할만큼 거대한 시스템으로 구성할 수 있는지와 실제로 적용을 해서 이용자들을 끌어들일 수 있었는지에 대한 고찰이 있습니다.
그래서 이런 문제들을 풀기 위해 object detection과 localization을 결합한 방법으로 1% 이하의 false positive rate를 가지는 detection rate를 얻어내면서도, 높은 검색 정확도(PT-VGG라고 부르는 살짝 개조한 VGG를 사용합니다.)등을 적용했다고 합니다. 이를 통해 최종적으로는 user engagement의 향상을 보임으로 성공적인 visual search system을 개발했다고 합니다.
Pinterest Image
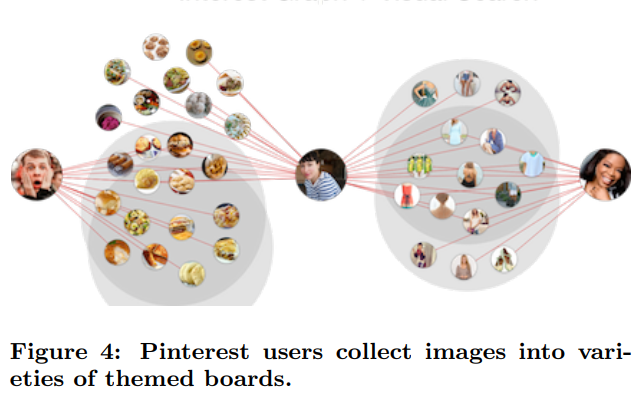
시작하기전에 당연히 입력되는 값들이 어떤 값이 있는지 알아야 하겠죠? 위 이미지는 유저들이 이미지를 다루는 방법에 대한 내용입니다. Pinterest에 입력되는 이미지들은 위와 같이 특정 유저들에게 게시판 형태로 묶이게 됩니다. 이러한 특성 떄문에 이 이미지들은 엄청난 metadata를 보유한 hand-curated-collection으로 만들어져있습니다.
Feature Representation
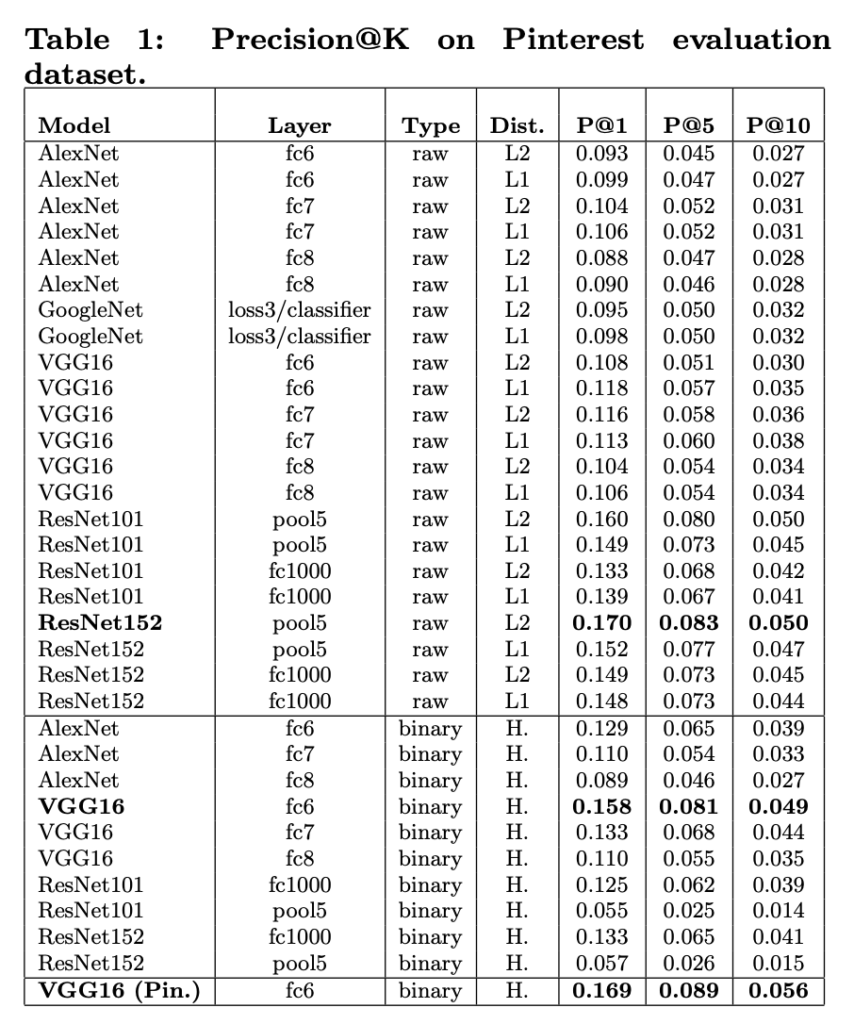
그럼 이 이미지들을 어떻게 분류하고 feature를 뽑는지 확인해봅시다. Pinterest에서는 당시 유명했던 모델들을 모두 사용했습니다. Alexnet, GoogleNet, VGG, ResNet을 사용했습니다. 그리고 Type을 보시면 raw와 binary가 있는데요, 역시 여기서도 binarized representation도 테스트합니다. 그리고 raw feature를 비교할때 L1을 쓸지 L2를 쓸지도 모두 테스트했습니다.
그리고 이 백본들 전부 Imagenet으로 pretrained model을 가지고 있죠? 여기서도 이 pretrained model을 가져와서 사용합니다. 단, 이베이에서 설명드렸던 것과는 다르게 여기서는 오히려 Pinterest에 업로드되는 이미지들이 일반적인 이미지들보다 좋은 퀄리티를 가진 이미지들이라서 이를 위한 fine-tuning을 해줬습니다. 이건 softmax classification layer만 새로 학습하는 방식을 이용했다고 하네요.

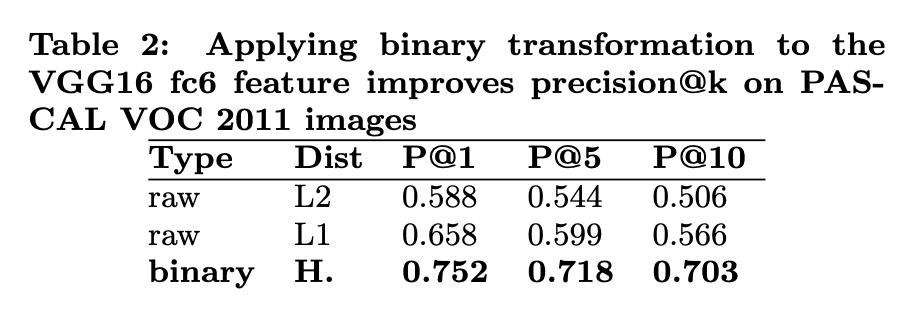
그리고 위 그림은 binarized representation의 효용성을 보이는 그림입니다. PASCAL VOC 2011데이터를 시각화한 데이터인데, 오른쪽(binarized)이 조금 더 잘 분리되는 경향을 보이는 것을 확인할 수 있습니다.
실제로 수치상으로 확인해보면 L2 → L1 → binary 순으로 성능 향상이 있는 것을 확인할 수 있습니다. 이 점은 feature를 생성할 때, binary 표현법이 noise에 조금 더 강인하기 때문에 그렇다고 하네요.
그럼 어떤 백본을 사용하고, binarized representation을 사용할 것 까지는 결정했다면, fine-tuning을 위한 데이터는 어떻게 만들지 설명을 아직 드리지 않았죠? 이 데이터는 수많은 데이터 중에서 100,000개 까지의 텍스트 검색 결과를 바탕으로 20,000개를 임의로 선택하여 여기서 후처리르 거쳐서 18,000개는 학습용 데이터로, 2,000개는 query 이미지로 사용했다고 합니다. 이 결과가 위의 큰 표(Figure 1)에서 확인할 수 있는 결과입니다.
최종적으로는 binarized representation을 곁들인 VGG16을 사용했습니다.
Object detection
Visual search 논문들의 공통점을 보면, detection을 하고 그 결과를 바탕으로 feature를 뽑는다는 공통점이 있는 것 같습니다. Pinterest에서도 역시 똑같이 사용하는데요. 원래 detection 모델을 Pinterest flashlight라는 서비스에서 사용중이었다고 하네요?
그런 이유로 해당 서비스에서의 노하우가 있었을지는 모르겠지만, Faster R-CNN과 SSD를 테스트 했습니다. 학습을 하는데 있어서 많은 내용이 있긴 하지만 결국 정리하면, SSD의 속도에 비해 Faster R-CNN의 성능이 그렇게 우수하지 못했기 때문에 실시간 서비스가 더 중요한 pinterest lens에서는 SSD를 사용하기로 결정했습니다. 나머지 서비스에서는 Faster R-CNN을 사용합니다.
특이한 점으로는 이미지 해상도를 290×290을 사용합니다. 이게 이 논문 저자가 모델을 수정하면서, IoU 수치를 조절하면서 stride를 변경하거나, positive & negative anchor를 고정비율로 선택하는 것 대신에 Online Hard Example Mining (OHEM)을 이용해서 anchor를 적절하게 선택하도록 한다든가 하는 방법을 적용했다고 설명합니다. 문제는 이미지 해상도가 애매하게 10픽셀 낮은거랑 무슨 상관인지는 모르겠습니다.
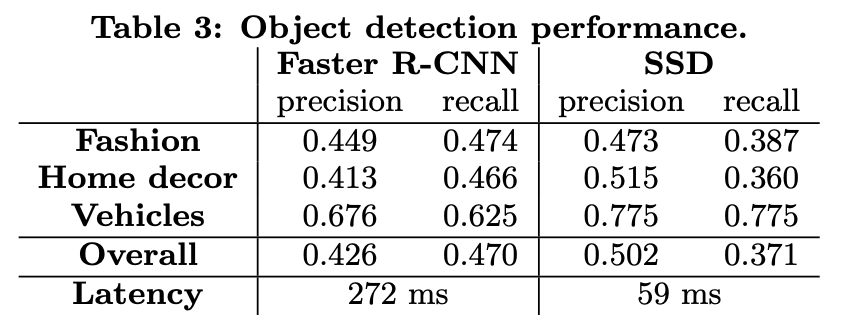
아무튼 이러한 방법론들을 이용해서 최종적으로 나온 성능을 보면 위와 같습니다. 아무래도 속도 차이가 좀 나서 고민해볼 만한 부분이 있었던 것 같습니다.
Adapted to pinterest services
이 부분은 각 서비스들에 어떻게 적용했는지에 대한 내용입니다. Pinterest라고 하나의 검색만 있는게 아니고, 분할된 서비스들을 제공하더라고요. 그래서 각각의 서비스들마다 약간씩 차이점이 있습니다. 각각의 서비스들은 결국 engagement(유저 참여율 정도로 해석되는 것 같습니다.) 높이는 방향으로 학습이 됩니다. 그것 이외에는 딱히… 정리할 만한 내용이 없는 듯 하네요. 앞서 설명한대로 related pins와 flashlight라는 서비스에는 faster R-CNN을 사용하고, lens 서비스에서는 속도가 더 중요해서 SSD를 사용합니다.
Click prediction
사실 이건 서비스는 아닙니다. 이런 것도 학습을 한다는 것이 신기해서 이 부분에 포함했는데요. close-up rate(CUR)과 click-through rate(CTR)을 높이기 위해 모델이 이를 높이기 위해 학습합니다. 사실 engagemet랑 비슷한 개념이 아닐까 싶은데 다른 용어를 쓰는걸 보니 다른 수치같아서 포함했습니다.
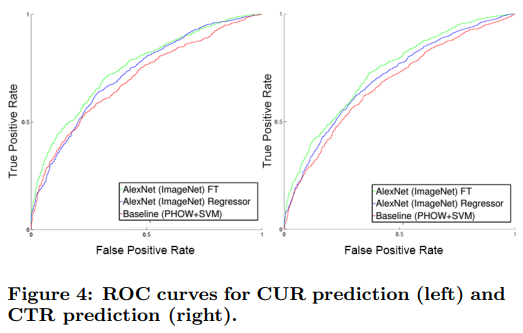
학습은 당연히 Imagenet pretrained model을 사용하고, caltech-101에서 실험 결과가 위와 같습니다. 이러한 방법론이 baseline에 비해 전반적으로 성능이 좋은데요, 이와 비슷한 방법을 pinterest에 적용하면 성능이 꽤 좋다고 합니다. 이러한 방법론은 유해이미지 탐지에도 적용되었다고 하네요.
큰 시스템에 적용하기
이 부분은 과연 Pinterest는 어떻게 이 대용량 시스템을 운영하는지에 대한 이야기입니다. Pinterest는 기존의 뽑아둔 feature들도 갱신될 수 있다는 점을 고려한 것 같습니다. 그래서 새로운 이미지가 들어왔거나, 아니면 내가 모델을 변경해서 feature를 새로 바꿔야할때를 위해 Incremental Fingerprinting Service를 구축했다고 합니다.
위의 그림과 같은 시스템인데요. 이미지에 지문을 부여해서 관리하겠다는 것입니다. fingerprint라고는 하는데, 결국은 날짜와 MD5 해쉬를 기반으로한 이미지 시그니처 입니다. 이미지가 갱신 되지 않은 상태인 것을 전체 이미지의 묶음을 노드로 나눠서 노드별로 처리하는 형식입니다.
결론
급하게 마무리한 느낌이 있는 듯 하지만… 남은 내용들은 hadoop으로 분산처리를 어떻게 했다 등등의 내용들도 많고, 앞선 리뷰에서 대부분 반복되는 내용들 같아서 Pinterest는 이정도로 정리하려고 합니다. 다음 리뷰부터는 video retrieval로 다시 돌아가서 차근차근 익히다가 돌아오려고 합니다.
우리 비디오 검색에 Hadoop 이나 Spark 도입 검토는 불필요한가요?
데이터셋을 어떤 데이터셋을 사용할지에 따라 결정될 것 같습니다. 느린 연산 속도는 visual search system에서도 이미지를 다 feature로 미리 뽑아둔 다음 유사도 계산할 때 미리 뽑아둔 값을 사용하는 것으로 극복해서, FIVR 정도면 Hadoop 없이 충분하다고 생각하고요. 만약 KDX 뉴스 데이터셋(지속적으로 양이 증가할 것으로 예상되는 데이터셋을 포함)을 적용하려면 검토를 해봐야 할 것 같습니다.
binarized representation 방식으로도 여러가지 종류가 있는 것으로 아는데 pinterest에서는 어떤 방식을 사용하나요?
해당 논문에서 어떤 방식을 사용했다고 설명하지는 않고, Analyzing the Performance of Multilayer Neural Networks for Object Recognition(https://arxiv.org/abs/1407.1610)을 저자가 citation으로 달아두었습니다.