지난번 Bing에서의 Visual Search 이후 두번째 논문입니다. 사실은 이 논문이 이전에 작성한 논문보다 먼저 나왔었습니다. Visual Search를 하기 위해 다양한 feature를 쓴다고 말씀드렸었는데요. 여기서도 여러가지 feature를 뽑아서 사용하는 aspect라는 개념이 등장합니다. 그럼 시작하겠습니다.
Introduction
Visual search system 자체는 많은 상업적인 시스템이 있지만, 논문으로 작성된 내용도 많이 없고 최적화 단계는 여전히 도전적인 부분이라 ebay에서 이러한 점들을 공유하고자 작성하였다고 합니다.
ebay에서의 visual search는 크게 4가지 문제가 있는데요.
- Volatile Inventory
새로운 상품이 올라오고, 팔리는데 걸리는 시간이 매우 짧아서 올라오는 물품들이 금방 사라지는 문제가 있다고 합니다. (아마 auction system? 때문인 것으로 추정)
- Scale
ebay 정도의 큰 데이터셋에서 작동하기에는 기존의 해결책들이 적합하지 않았고, 세분화된 카테고리를 적절한 시간과 정확도 안에 분류하는 문제가 있다고 합니다.
- Data Quality
ebay에서 판매를 허용하는 셀러가 영세 업자들도 있다 보니, 이미지 퀄리티 자체가 차이가 극과 극으로 나고, 정보들이 없거나 부정확한 경우가 많았다고 합니다.
- Quality of Query Images
ebay ShopBot은 유저들이 올리는 이미지를 받아서 처리한다고 합니다.

이 논문 자료는 아니지만, 교수님이 추천해준 Deview 발표 영상에서 가져온 실제 유저들이 업로드할 Query 이미지 예시를 보면, 정말 다양합니다. 그렇기 때문에 이 논문에서도 그냥 유저들이 올리는게 문제라고만 정의했지만 실제로는 이런 의미가 있다고 생각하면 될 것 같습니다.
ebay에서는 이러한 문제점들을 해결하기 위해 category classification과 binary signature extraction을 통합해서 수행할 수 있는 DNN을 통해 해결했다고 합니다. 여기에 asprect prediction을 곁들여서 정확한 검색을 하는 것을 목표로 했습니다.
Related works
기존의 방법론들은 hash function을 바탕으로 비교를 진행하기 때문에 이를 어떻게 학습 시키냐가 문제였다고 합니다. 크게 loss를 통해 학습하는 방법이 있고, hash function을 직접 학습하는 두가지 방법이 있습니다. 각자 장단점이 있지만, ebay가 보유한 특성에 적합하지 않아, hybrid scalable and resource efficient visual search engine을 제안했다고 합니다. 이 방법은 물체의 정확한 카테고리를 정하고, 시각적인 정보들을 바탕으로 re-ranking을 수행한다고 합니다.
Approach
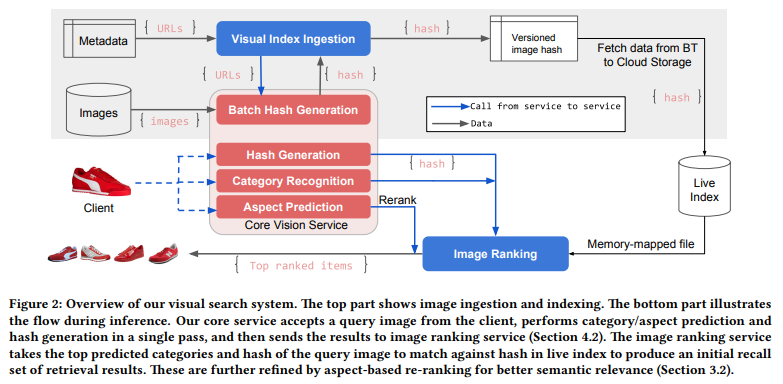
위 그림이 개략적인 시스템 구조입니다.
Category Recognition
이 모듈은 운동화라는 카테고리안에서도 남성용과 여성용을 구분할 수 있을 정도의 세분화된 카테고리(ebay에서 사용하는 카테고리 분류 범주)를 예측하는게 목표입니다. 당시 SOTA 였던 ResNet-50을 백본으로 사용했다고 합니다. 학습에 사용된 augmentation을 보면, resize→center crop+mirror version을 사용했다고 합니다. 여기까지는 기본이고, “on-the-fly data argumentation”을 사용해서 좀 더 강인한 모델을 만들고자 했다고 합니다.
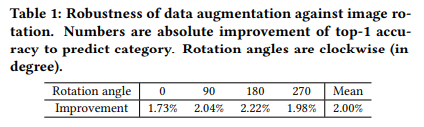
왜 이런 augumentation에 집중했는지 생각해보면, ebay 자체가 같은 물체라 하더라도 사용자들이 매-우 다양한 환경에서 촬영하기 때문에 이런 방법을 사용해서 정확도를 높이고자 한 것으로 생각됩니다.
Aspect Prediction
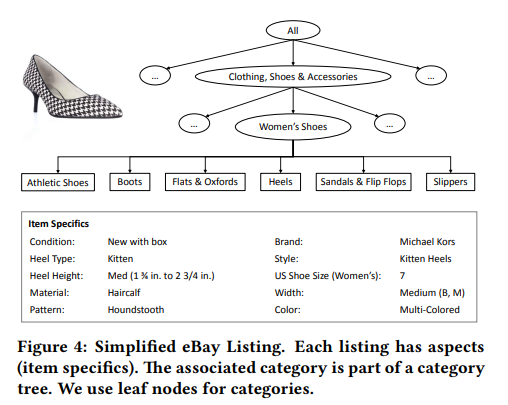
위와 같이 ebay에서는 카테고리와 연관되어 있는 다양한 정보들을 보유하고 있는데, 이러한 정보(이 논문에서는 aspect라고 부릅니다.)들을 예측하는 모델입니다. 참고로 Category Recognition에서 사용한 모델 위에 구현되고, 모든 aspect models는 main DNN 모델과 parameter를 공유합니다.
Leaf category를 one-hot encoding한 vector와 pool5의 feature를 임베딩해서 사용합니다. 이러면 시각적인 정보와 카테고리 정보를 한번에 표현할 수 있는데, 이걸 이용해서 multi-class classifiers에 사용합니다. 여기서 XGBoost와 같은 gradient boosting 방법론을 적용해서 속도와 효용성 모두 잡았다고 합니다.
Deep Semantic Binary Hash
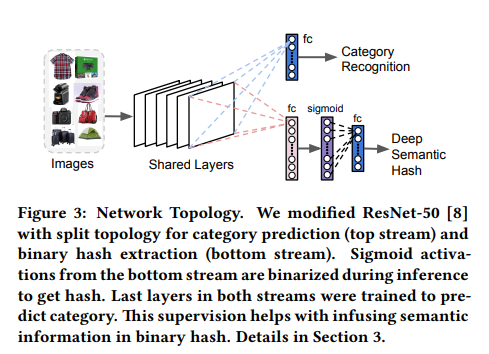
Feature를 직접 뽑을 수는 있지만, 그렇게 뽑은 feature가 속도와 성능을 고려해봤을 때 그렇게 장점을 가지지 않다고 합니다. 그래서 이 논문에서는 추가적인 FC 레이어와 sigmoid를 이용해서 binary semantic hash를 만들어 사용합니다.
binary인데 sigmoid를 쓰면 binary가 아니죠? 그래서 threshold 0.5를 기준으로 줘서 간단하게 이진화 시켰다고 합니다. 복잡한 이진화 방법들도 다 적용해봤는데, 이 간단한 방법이 성능 기준치를 만족시켜서 속도 문제도 있으니 이렇게 사용한다고 합니다.
최종적으로는 4096비트의 binary semantic hash를 사용합니다. 이러면 200M 이미지를 단 100GB에 저장할 수 있게 됩니다! (hash vector의 크기가 512byte니까요!) 원래대로 저장하면 6.1TB가 필요합니다. 또 하나의 장점은 계산 속도가 빨라진다는 겁니다. 기존의 방식대로라면 euclidian distance를 사용해야하지만, 이 방법은 hamming distance를 이용합니다. 그래서 유사도 계산에서도 빠르다는 장점을 가집니다.
Aspect-based Image Re-ranking
이 부분이 영어가 어려워서 잘 이해를 못했을 수도 있습니다. 일단 aspect라는 것은 쿼리 이미지로 부터 생성해낼 수 있는 한 종류의 feature라고 생각하시면 편할 것 같습니다. 뽑아낼 수 있는 만큼 aspect를 많이 예측하고, 정확하게 맞췄을 경우에 “reward point”로서 w라고 가중치를 줍니다. 여기에 ebay라는 특성상 유저의 구매에 영향을 미치는 aspect에는 가중치를 더 줍니다. 최종적인 유사도는 S = aS_{appearance} + (1-a)S_{aspect}가 되도록 조정됩니다. appreance는 hamming distance로 계산된 시각적 유사도를 말하고, aspect는 복잡한 수식이 있긴 한데 결국은 얼마나 많은 조건을 맞췄는지로 설명됩니다. a는 fusion 수치로 볼 수 있는데, 여기서는 고정값 0.75입니다. 그게 성능이 가장 좋았다고 하네요.

aspect re-ranking이 실제로 효과가 있는 예시는 위의 그림에서 확인할 수 있습니다. 위에서부터 색 정보, 브랜드 정보, neckline 정보를 바탕으로 re-ranking을 수행하면 전반적으로 유사한 결과를 얻을 수 있었습니다. deep feature가 놓치는 정보들을 aspect 정보들이 보완하여 정확한 검색 결과를 얻는 것입니다!
Expreriments on ImageNet
Deep Semantic Binary Hash 파트에서 classification 부분이 있는 것을 보실 수 있는데요. 해당 부분에서 top-1 validation error 25.7%, top-5 validation error 7.9%의 성능을 보였다고 합니다. 그리고 Hashing 파트는 24.7%와 7.8%라고 합니다.

ImageNet에서의 시각화 결과는 위와 같습니다. 실제로 분류가 어느정도 되어있는 모습입니다. 이 시각화 결과는 binary hash가 semantic한 정보를 보존하고 있기 때문에, hash collision을 고려했을 때 이 정보들을 인코딩 하는 것이 중요하다고 하네요.
Bit Distribution

Binary hash function을 사용할때 중요한 것 중 하나가 Bit가 잘 분배되어 있어야 hash collision을 막고, 구분이 잘 된다는 것입니다. 이 논문의 결과는 위 그림에서 확인할 수 있는데요, 딱 50%에 일치하지는 않지만, 적당히 잘 분배된 모습을 볼 수 있습니다.
Experiment 정리
3가지 부분에서 비교를 수행합니다. Category prediction / Similarity search / Timing으로 앞에서부터 분류를 잘 했는지, 그 다음은 비슷한걸 잘 찾았는지, 마지막으로는 검색 속도에 대한 비교입니다.

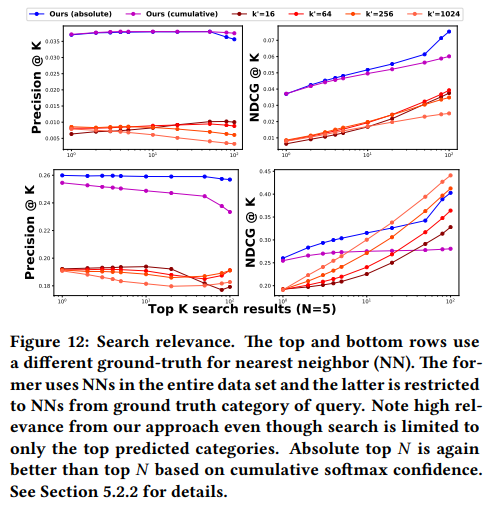
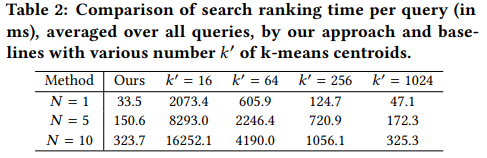
논문에는 순서대로 안되어있어 재정렬을 해보면 위와 같습니다. 여기서는 베이스라인 성능을 잡고, 그 성능과 이 프레임워크를 비교하고 있습니다. 물론 이 비교도 자체 데이터 기준입니다. 여기서는 ImageNet에서의 실험 결과를 드러냈으니 그걸 참고해도 되지만 여전히 좋은 성능인지는 잘 모르겠습니다.

논문에는 더 많은 정성적 결과가 있는데 일부만 발췌했습니다. 이베이에 없는 쿼리 이미지들을 바탕으로 검색을 수행했을 때, 유사한 물건을 잘 찾는 것을 볼 수 있습니다. 실제로도 다양한 서비스들에 적용된 예시들도 봤을때, 위에서 보인 성능은 꽤 좋은 성능임을 유추해볼 수 있습니다.