1. 요약
해당 논문은 데이터의 레이블이 없는 Unlabeled 데이터의 가치를 효과적으로 판단하는 모델을 학습하기 위해 Labeled data의 Annotation 정보와 Labeled data+Unlabeled data의 State 정보(=Labeled/Unlabeled)를 모두 사용하는 논문이다. 기존의 논문은 주로 Annotation 정보나 State 정보만 사용했다는 점에서 위의 특징은 논문의 contribution이 된다.
2. 배경 기술 소개
Active Learning은 데이터 레이블링 과정을 최대한 효율적으로 진행하기 위한 연구 분야로, 모델이 학습이 필요하다고 판단한 데이터를 쿼리로 전송하여 해당 데이터에 대한 레이블링만을 진행함으로써 가공해야할 데이터의 수를 줄이는것을 목적으로 한다. Active Learning의 프로세스는 다음과 같다. 우선 Labeled data로 모델을 학습한다. 다음으로 학습한 모델이 Unlabeled data들 중 쿼리로 요청할 데이터를 선정하여 요청한다. 요청된 데이터의 레이블링이 끝나면 이를 Labeled data에 합한다 위의 3단계를 레이블링에 사용할 예산을 소진할 때 까지 반복한다.
모델이 데이터의 가치를 판단하기 위하여 다음의 두 가지 중 하나를 기준으로 한다. 1) 데이터에 대한 모델의 학습 정도 (Uncertainty), 2) 데이터의 다양성 (Distribution). 해당 논문에서는 1)을 데이터 가치판단의 기준으로 한다. 데이터에 대한 모델의 학습 정도를 측정하는 방식은 다양하다. 가장 쉬운 방법은 (classification의 경우) 예측값의 분산과 같은 정보를 이용하는 것이다. 예를 들어 어떠한 사진이 개, 고양이, 토끼 클래스 중 하나에 속할 때, 사진에 대한 예측값이 [개:0.4 고양이:0.3 토끼:0.3]인 경우 A와 [개:0.7 고양이:0.2 토끼:0.1]인 경우 B가 있을 때, B의 분산이 비교적 작으며 예측값에 대한 확신도가 크다고 볼 수 있다. 즉 B의 경우가 Uncertainty가 작은 경우며 이러한 데이터는 모델이 이미 잘 학습하였기 때문에 레이블링을 요청할 필요가 없다.
Uncertainty를 예측하기 위한 학습방법 중, 데이터의 Annotation 정보를 이용하는 방식과 데이터의 State(Labeled/Unlabeled)를 이용하는 방식이 있는데, 위의 예시의 경우는 데이터 가치판단을 위해 Annotation 정보(=class 정보) 를 사용한 경우이다. State를 이용하는 경우 가치판단하는 방식의 예시는 다음과 같다. 모델이 어떤 데이터를 Unlabeled data라고 예측했다면, 이는 모델이 해당 데이터에 대한 정보가 없다고 판단하는 것이므로, Unlabeled data라고 예측하는 확신도가 높을수록 Uncertainty가 높다고 판단하는 것이다. 두 방식은 각각 특징이 있다. 먼저 State 방식의 장점은 Active Learning의 iteration 중 추가적인 사람 개입이 필요 없다는 점이다. 데이터에 사용되는 레이블링 정보가 Labeled or Unlabeled 이기 때문에 추가적인 레이블링과정이 필요 없다. 다음으로 Annotation을 이용하는 방식은 Labeled data의 정보를 최대한 사용할 수 있다는 것이 장점이다.
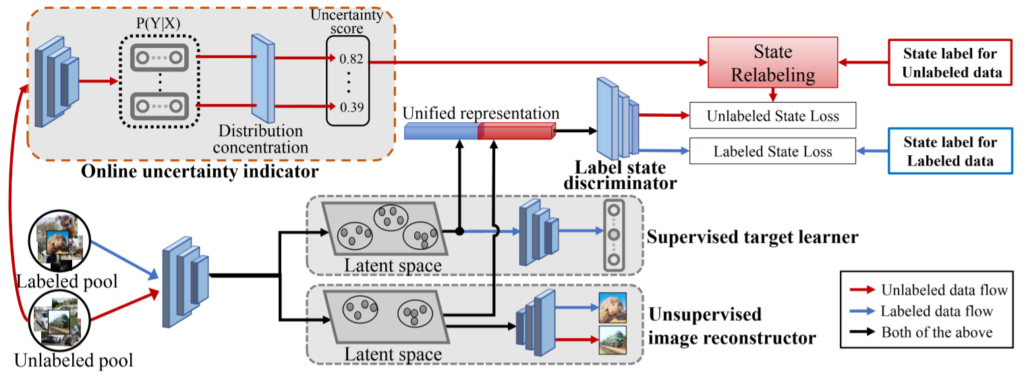
해당 논문은 Annotation 정보와 State 정보를 모두 이용하여 학습할 수 있는 모델을 구성하기 위해 <그림1>과 같이 네트워크를 구성하였다. 방법론 소개를 위해 네트워크의 구성과 데이터를 샘플링 전략을 나누어 소개하겠다. 마지막으로 논문의 contribution 중 하나인 초기 샘플링 알고리즘에 대해서 소개하고 마친다.
3.1 네트워크 구성
네트워크는 Unified representation generator와 labeled/unlabeled state discriminator 로 구성되었다. 먼저 Unified representation generator는 state discrimator의 입력값인 Unified representation을 생성하는 역할을 하며 <그림1>에서 Unsupervised image reconstructor(UIR)과 Supervised target learner(STL)로 구성되었다. Unified representation은 입력 데이터 x에 해당하는 정보와 라벨인 y정보를 모두 갖는 표현 형식을 말하며 UIR이 x정보를, STL이 y정보를 생성한다. UIR은 variational autoencoder(VAE) 구조로 Unlabeled data과 Labeled data를 모두 입력으로 하며 encoding된 Latent space의 데이터가 원본 이미지를 생성하도록 학습한다. 다음으로 STL은 VAE의 decoder 구조로 학습시에는 Labeled data를 입력으로 하여 해당 데이터의 라벨값을 예측하며 지도학습 방식으로 학습한다.
다음으로 labeled/unlabeled state discriminator는 생성된 Unified representation이 어떤 State인지 판별한다. 이때 논문에서는 State 값을 기존 연구에서 주로 사용하던 0,1(Labeled/Unlabeled) 이진분류가 아닌 [0,1]에 속하는 연속적인 값으로 relabeling하여 사용한다. relabeling을 위해 Online uncertainty indicator(OUI)에서 계산하는 Uncertainty score를 새로운 label로 이용하며 이는 예측 벡터를 기반으로 계산한다. 계산과정은 수식 (3), (4)와 같으며 V는 예측 벡터이다. OUI의 네트워크는 target model의 구조로 task에 따라 다르다. 예를 들어 논문의 CIFAR data에 대한 실험에서는 ResNet-18 구조이다. Label state discriminator의 구조는 [Link]와 같다. 이처럼 generator와 discriminator 구조를 만들어 Adversarial 학습을 진행한다.
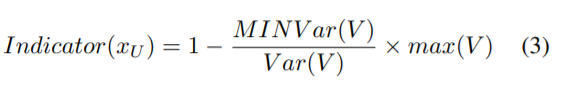
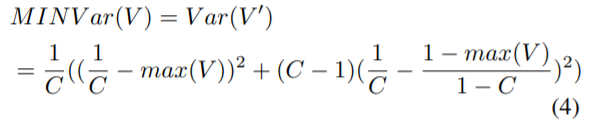
3.2 샘플링 전략
쿼리로 요청할 데이터를 선별하기 위해서 Unified representation generator로 Unlabeled data에 대한 Unified representation을 생성하고 이를 통해 Uncertanty score를 예측한다. Score가 높은순으로 top-K만큼 쿼리로 요청하며 K는 상수이다.
3.3 초기 샘플링 알고리즘
기존 연구의 대부분은 Labeled pool에 대한 언급이 없으며 대부분 random으로 n%씩 선택하여 사용한다. 해당 논문은 Labeled Pool을 구성하기 위한 k-center 연구에서 영감을 받은 초기화 방식을 소개한다. 해당 알고리즘은 data의 subset들 중 모든 분포를 포함할 수 있으면서 데이터간 거리 중 가장 긴 거리가 가장 짧은 subset을 초기 Labeled Pool로 사용한다. 이는 Core-set approch와 비슷한 개념이다.
4. 실험
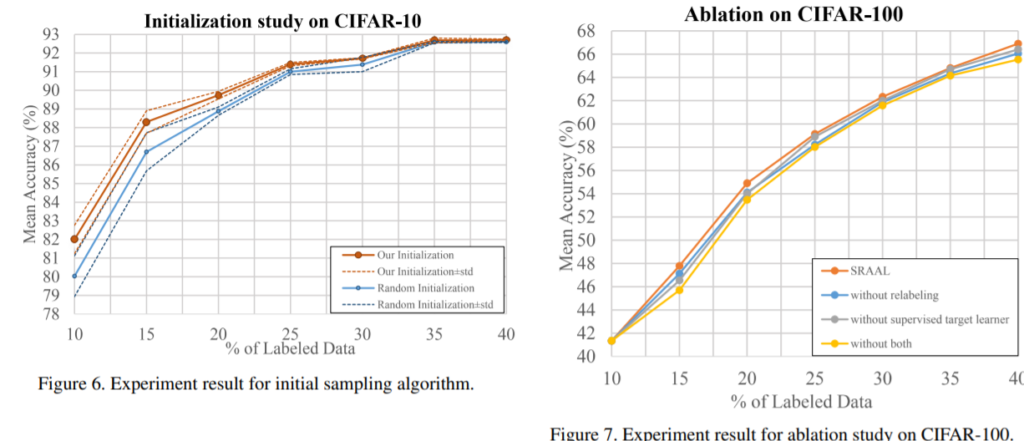
실험은 Image Classification( CIFAR-10, CIFAR-100, Caltech-101 ), Semantic Segmentation (Cityscapes) 에 대한 성능 평가와 3.3에 제안한 초기화방식과 relabeling, Unified representation에 대한 분석을 진행하였다. 실험 결과 기존 방법론인 VAAL, LL4AL, Core-set, MC-Dropout, Random 보다 모든 테스크와 모든 업데이트 사이클(Active Learing 과정 중 하나의 반복 과정)에서 좋은 성능을 보였다. 또한 초기화 역시 기존의 Random 초기화보다 효과적임을 <그림2>의 좌측 그래프에서 보였으며 <그림2>의 우측 그래프에서 제안한 방법론(relabeling, Unified representation)이 실제로 효과가 있음을 Ablation study로 보였다.
5. 요약
Annotation과 State 정보를 모두 이용하여 가장 좋은 Unlabeled data를 쿼리로 선택하는 Active Learning 모델을 생성했다. 이를 위해 online uncertainty indicator로 relabeling을 진행하였으며 annotation이 내재된 데이터 형식인 Unified representation 을 만들어 discriminator의 입력으로 사용하였다. 마지막으로 k-centor 방식에서 영감을 받아 초기 Labeled Pool을 구축하는 알고리즘을 적용하여 효과적인 Active Learning을 진행하였다.
안녕하세요! 기존 연구의 대부분이 Labeled pool에 대한 언급이 없는 이유가 무엇인가요? (3.3)
Labeled 면 Annotation 등 정보 더 있으니까 오히려 기존 연구들이 그쪽을 unlabeled 보다 먼저 했어야 하지 않나…? 라는 생각이 들어 질문 남깁니다.
Labeled pool은 분류기(target task를 위한 최종 네트워크) 학습을 위해 사용하고 active learner를 위한 학습에 사용되지 않는다는 의미였습니다. active learner에 분류기(classifer)가 포함되는 경우가 많지만, 해당 논문처럼 직접적으로 사용되지 않는다는 점에서 차이가 있습니다.