이번 논문은 Image Generation, Image to Image Translation 쪽 분야 논문입니다. Image Generation 분야에서 매우 유명한 StyleGAN을 기반으로 자신들이 제안하는 새로운 Encoder를 통해 Image Translation까지 수행할 수 있다…가 해당 논문의 핵심인 것 같습니다.
Introduction
Image Generation과 Image Translation은 얼추보면 동일한 분야인 것 같지만, 사실 엄연히 다른 분야라고도 볼 수 있습니다. Image Generation은 흔히 우리가 알고 있는 Latent vector를 입력으로 하여 새로운 얼굴이나, 차 등을 만드는 것이죠. 여기서 영상을 생성하는 모델은 우리가 학습시키고자 하는 타겟 도메인의 분포를 latent vector 분포에 강제로 맞추는 역할이라고 보시면 될 것 같습니다.
반면 Image Translation은 A라는 도메인의 입력으로 B라는 도메인을 만들어 내는 말 그대로 입력 영상을 기반으로 하여 다른 도메인으로 변환하는 것이죠. 사실 Image Translation은 마치 Semantic Segmentation이나 Depth Estimation과 유사하기 때문에 더 직관적으로 이해하실 수 있을 것 같습니다.
아무튼 이러한 Image Generation분야에서는 StyleGAN이 매우 대표적인 방법으로 알려져 있습니다. StyleGAN이 유명하게 된 이유는 바로 latent space를 어떻게 하면 disentangle 할 수 있을까?에 대하여 잘 해결하였기 때문입니다.
Disentangled latent space라는 말이 어떤 의미인지 감이 안잡히시는 분들을 위해 간략하게 소개를 드리면, 어떠한 학습 데이터 셋의 분포가 그림1-(a)와 같다고 생각해봅시다. 위에서도 설명했다시피 Image Generation task는 Generator가 학습 데이터의 분포를 input latent space에 강제로 끼어맞춘다고 얘기를 했었죠?
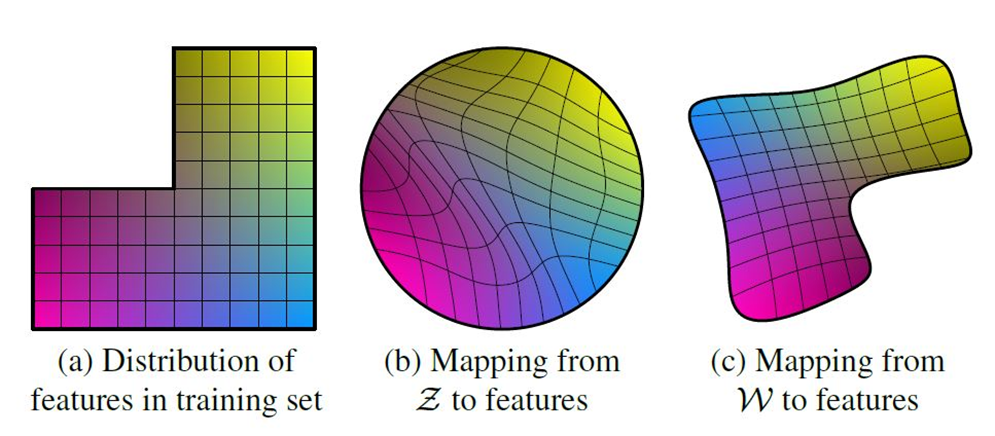
우리가 모델의 입력으로 넣는 어떠한 latent space는 사실 random한 분포인 것처럼 보여도 어떠한 모형을 가지는 분포를 가지고 있습니다. 위 그림1-(b)에서 Z라는 latent space는 동그란 구형을 가지고 있네요.
자 그러면 애초에 학습 데이터의 분포는 1-(a)와 같이 ㄴ자로 누워있는데, 이를 동그란 분포에다가 강제로 끼워맞추려면 잘 될까요? 물론 모델의 학습은 Z 공간에서 추출한 vector를 가지고 어떻게든 학습 데이터와 유사하게 만들어야하다 보니 무언가를 만들고자 학습을 하겠지만, 데이터의 분포 모양이 너무 상이하다보니 1-(b)처럼 찌그러지는 모습을 볼 수 있습니다.
저렇게 왜곡된 곳에서 추출한 벡터맵은 원래의 학습 데이터와 유사하게 영상을 생성하기에는 불가능에 가깝겠죠. 그래서 StyleGAN 저자는 FC 레이어들로 구성된 어떠한 projection function f를 설계하여 Z를 새로운 latent space W로 보냅니다.
이 W라는 공간은 FC 레이어가 학습을 하면서 더 무한하게 설계될 수 있기 때문에 학습 데이터 셋과 유사한 분포를 가지게 될 수 도 있을 것이며 만약 그렇게만 된다면 그림1-(c)와 같이 학습 데이터 분포가 매우 유사해질 수 있을 것입니다.
이러한 가정을 토대로 모델을 설계한 StyleGAN은 그 당시 다른 방법론들과 비교하여 매우 자연스럽게 영상을 생성하였습니다. 그리고 이러한 StyleGAN의 방법론들을 따라 다양한 파생 연구들이 제안되어왔었죠.
하지만 논문의 저자는 이 StyleGAN을 기반으로 한 방식들은 문제가 있다고 합니다. 문제가 무엇인고 하니, 일단 이미지를 StyleGAN에서 제안한 latent space(W)로 인버팅을 먼저 한 후, 그 다음에 그 벡터w를 Generator에 적용하는 invert first, edit later 방식이 실제 영상과 같은 리얼함을 주기에는 부족하다는 것입니다.
기존의 StyleGAN은 512차원의 w 벡터를 생성하였는데, 이 단순한 512차원 벡터를 generator의 각 위치에 능동적으로 적용한다 하더라도 사실적인 영상을 생성하기 어렵다는 것이죠. 그래서 이 이후의 방법론 중 하나는 1개의 w 벡터가 아닌 18개의 서로다른 512차원 w 벡터를 새로운 latent space에서 추출한 뒤 concatenate하여 generator에 사용하고자 했는데, 이 방식은 영상 하나를 통해 많은 latent vector를 새롭게 추출하려다 보니 오랜 시간이 걸리는 문제가 발생합니다.
그래서 저자는 이러한 문제들을 해결하고자, 새로이 확장된 latent space W+으로 부터 임베딩 벡터를 추출하는 encoder를 제안합니다. 해당 encoder는 Feature Pyramid Network(FPN)과 동일한 구조를 가지고 있는데, 이러한 구조는 멀티 스케일의 encoder feature를 추출할 수 있으며 각 스케일 별로 style vector를 추출하여 사전학습된 generator에 전달만 해주면 된다고 합니다.
그럼 해당 방법론이 이전의 방법론들과 무슨 차이가 있을까요? 아까도 얘기했지만 StyleGAN 기반의 이전 방법론들은 반드시 영상 자체를 인버팅을 해야만 했습니다. 그래서 Image Translation처럼 입력 영상 자체의 컨디션은 유지한 채로 새로운 도메인의 스타일을 입힐 수가 없었죠.
하지만 해당 방법론은 FPN 구조로 스타일을 추출한 후 이미 학습된 StyleGAN Generator에 style을 전달해줌으로써 마치 image-to-image translation과 같은 작업을 진행할 수 있었다고 합니다.
pSp(pixel2Style2pixel) Framework
서론이 너무 길었으니 본론을 최대한 간단?하게 설명해보고자 합니다.
일단 논문에서 제안하는 pSp network의 전체 파이프라인은 그림2와 같습니다.
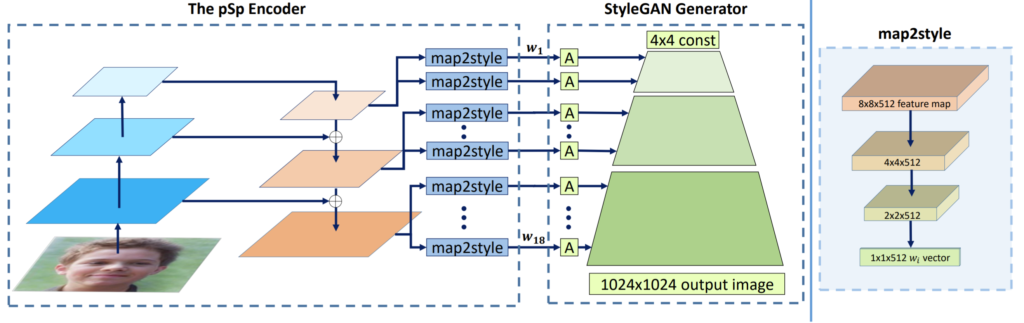
앞에 pSp encoder라고 적힌 부분이 저자가 제안하는 새로운 인코더 모듈이며 사실 구조는 FPN과 유사하지만, 기존의 StyleGAN과 비교하면 파격적인 변신이라고 보시면 될 것 같습니다.
이 pSp encoder를 통해 추출한 multi scale feature map을 map2style이라는 모듈을 통해 각각 스타일 벡터로 추출해주며 추출된 style vector들은 사전학습된 StyleGAN Generator에 입력으로 들어가 새로운 영상을 만들게 되는 것입니다.
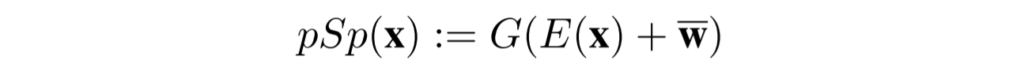
수식으로 보면 다음과 같은데, E와 G는 각각 pSp Encoder와 StyleGAN Generator를 의미하는 것이며, \bar{w} 는 사전 학습된 generator의 평균 스타일 벡터라고 보시면 될 것 같습니다.
즉 위의 수식은 pSp encoder가 평균 스타일 벡터를 따라 latent code를 학습시킨다고 보시면될 것 같습니다.이 방식이 가장 좋은 초기 설정을 통해 좋은 결과 영상을 생성해줄 수 있다고 합니다.
Loss Function
다음은 loss function에 대한 설명입니다.
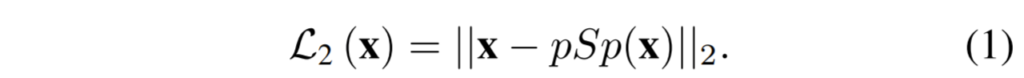
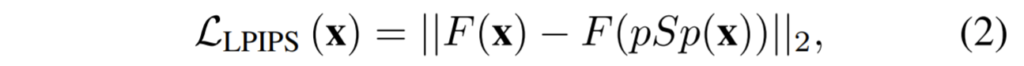
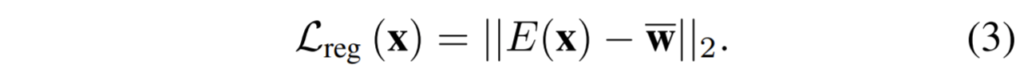
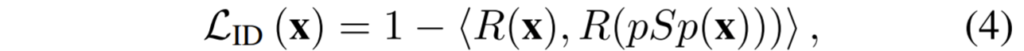
학습에 사용하는 loss는 위에 4개가 전부입니다. 1번 식은 pSp를 통해 만들어진 결과와 실제 결과에 대하여 단순히 L2 loss를 계산하는 것입니다.
수식 2는 만들어진 결과와 실제 결과에 대하여 perceptual 유사도를 계산한 것인데, LPIPS는 쉽게 말해 Image Quality Assessment 용 네트워크를 통해 얼마나 잘 생성됐는지를 loss값으로 사용한 것이라고 보시면 될 것 같습니다.
수식3은 아까 전에 설명드린 평균 스타일 벡터와 Encoder를 통과해서 나온 스타일 벡터가 서로 유사해지도록 하는 일종의 regularization loss입니다. 이를 적용한 이유에 대해서는 약간 실험적으로 자신들의 encoder가 더 퀄리티가 좋은 결과를 생성해낼 수 있었다는 결과에 따라 사용한 것으로 판단됩니다.
마지막 수식4번의 loss는 facial image를 encodere하는 과정에서 더 입력 자체의 고유성? 식별성?을 유지하고자 하는 loss라는데, 아무래도 실험 결과에서 다양한 facial generation 및 translation 실험을 하다 보니 해당 테스크를 위한 loss 설정으로 판단됩니다.
최종적인 total loss는 다음과 같습니다.
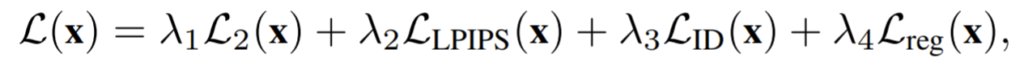
The Benefits of the stylegan domain
해당 방법론의 이점이라 하면 기존의 StyleGAN과 달리, Image Translation 분야에서도 StyleGAN을 사용할 수 있다.. 가 큰 장점으로 보이는데, 그렇다면 그냥 Image-to-Image Translation을 초점으로 둔 네트워크를 사용하면 되지 해당 방법론을 왜 사용해야만 할까요?
저자는 StyleGAN의 장점인 Style을 쉽게 조작할 수 있는 style manipulation이 훨씬 유용하다고 합니다. 이게 무슨 의미냐면 기존의 StyleGAN은 새롭게 재투영시킨 w latent vector를 가지고 generator의 다양한 스케일 레벨에 적용해줌으로써 각 스케일별로 차별적인 스타일을 적용할 수 있었습니다.
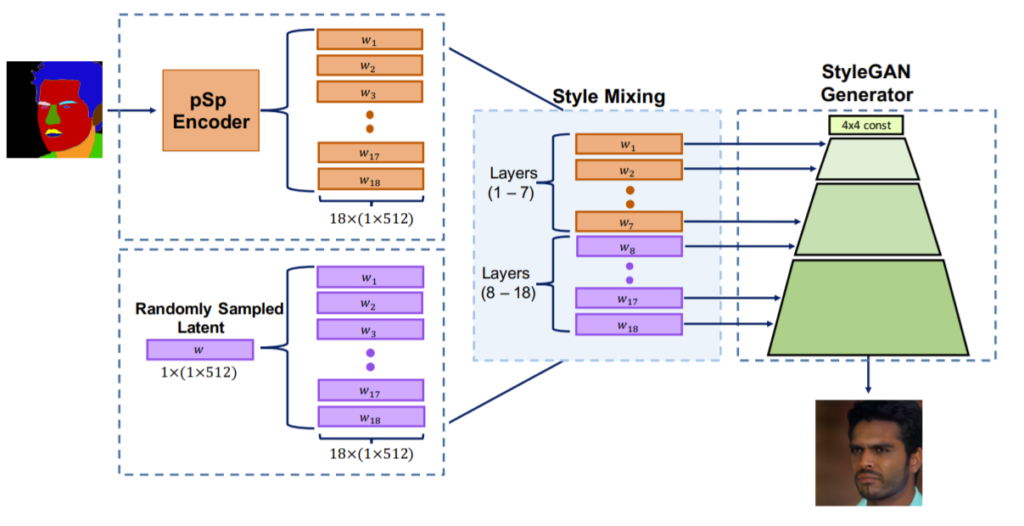
이와 유사하게 어느 층에 어떠한 w latent vector를 적용해줌에 따라 보다 더 다양한 스타일을 가지는 영상을 생성할 수 있게 된다는 것이죠.
아까 위에서도 설명했지만 FPN 네트워크를 통해 총 18개의 w vector를 생성할 수 있으며 이 때 일부는 그림3 예시와 같이 세그멘테이션 map에서 추출한 vector를 사용하고 나머지 일부는 random하게 샘플링된 latent vector를 적용하여 각기 다르게 스타일을 적용해볼 수 있다는 것입니다.
일반적인 Image Translation은 학습 때 본 하나의 도메인만으로 영상을 변환할 수 있는 반면 해당 방법론은 다양한 도메인을 적용해볼 수 있는 장점이 있는 것이죠.
Experiments
실험 결과에 대해서 알아보겠습니다.
가장 먼저 해당 방법론은 Image Translation과 같이 입력에 대하여 새로운 도메인으로 생성이 가능하다고 했습니다.

위 그림을 살펴보시면 사람의 스케치가 입력으로 들어왔을 때 pix2pixHD와 비교하여 pSp가 훨씬 자연스러운 결과를 만든 것을 확인할 수 있습니다. 이는 자신들의 Generator가 StyleGAN 기반의 Image Generation 방법론이기 때문에 훨씬 더 다양성이 넘치는 결과를 생성할 수 있었다고 합니다.
Sketch뿐만 아니라 Segmentation에서도 유사한 결과를 볼 수 있습니다.

또한 놀라운 점은 영상을 부분적으로 변환시킬 수도 있다는 점입니다.

위에 그림과 같이 실제 얼굴에 다른 사람의 눈 또는 입을 붙이고 이를 모델의 입력으로 넣을 경우 매우 그럴듯하게 변환한다는 점입니다. 이것도 multi-scale로 style vector를 추출하여 적용했기 때문일까요..? 이건 잘 모르겠네요.
아무튼 그 외에도 저해상도의 영상을 입력으로 넣거나 영상 자체를 crop하였을 때도 모두 높은 퀄리티의 실제 영상처럼 생성하는 결과들을 보여주고 있습니다. 궁금하신 분들은 논문의 appendix를 참고해주시면 좋을 듯 합니다.
결론
해당 방법론은 Image Translation과 Image Generation의 장단점을 서로 보완하여 둘의 장점을 온전히 사용할 수 있게끔 해준 논문으로 보입니다.
비록 방법론 자체가 너무나 간단해보일 수도 있지만, 다양한 분야의 실험에서 모두 의미있는 결과를 보였다는 점에서 높은 점수를 받았지 않은가 싶습니다.
되게 신기하네요… 그림만 그리면 얼굴이 생성된다니… 이런 기술은 어디에 쓰려고 연구하는지도 궁금해지네요. U-NET 리뷰도 방금 읽고 왔는데, 그러면 이렇게 생성해낸 가짜 이미지들을 discriminator와 같은 모델을 통해, 진짜인지 가짜인지 찾는 것일까요?
최근 뉴스로는 해당 기술들을 활용하여 AI가상애인? 같은 어플도 만들고 그러더군요ㅋㅋ.
아마 조영래 연구원님이 작성해주신 U-Net based Discriminator 논문을 말씀하시는 것 같은데, 보통 일반적인 Image to Image Translation 논문은 이광진 연구원님이 말씀해주신대로 생성해낸 가짜 이미지를 Discriminator를 통해 학습하지만, 제가 이번에 리뷰한 방법론은 loss 설명식에서도 나와있듯이 Discriminator를 활용한 GAN loss를 사용하지 않습니다.
이렇게 할 수 있었던 이유로는 이미 Discriminator를 통해 사전에 학습된 StyleGAN Generator를 그대로 가져다가 freeze 시킨 뒤 encoder만 학습하는 거라서, 따로 GAN loss를 사용할 필요는 없었다고 합니다.
image generation 분야를 저 연구에 사용ㅇ을 못할 것이라 생각했는데 이 와같이 하면 적용 할 수 있을 것 같네요. 같은 생각 이신지
Image Translation에서 UNIT이나 MUNIT과 같이 다양한 도메인으로 변환하는 확장 연구들까지는 봤어도 Style을 입맛대로 바꾸지는 못하였는데 마치 Style Transfer처럼 Style을 마음껏 바꿀 수 있다는 점에서 매우 괜찮다고 본 논문입니다.
하지만 저희 연구에 적용하기에는 살짝 애매하다고 생각하는게 결국 사전 학습된 StyleGAN Generator를 사용하는것이라 RGB 풍의 도로주행 환경으로 학습된 StyleGAN Generator가 있어야하지 않을 듯 싶네요.
기존의 StyleGAN 에서 데이터 분포 모양을 유지하고자 latent space(W) 로 인버팅 이라는 과정을 거친 뒤에 generator 를 통해 새로운 영상을 생성했을때 실제와 같은 리얼함을 주기엔 어려워서, 인버팅을 하는것이 아닌 latent space W+ 에서부터 임베딩 vector 를 추출하는 encoder를 제안했다는 식으로 이해했습니다. 인버팅이라는 과정을 잘 몰라서 이해를 잘 못하는 것일수도 있는데, 인버팅이라는 과정을 거치게 되면 왜 리얼함을 주기에 어려운건가요? 저자는 직접 영상을 생성해서 확인을 해 본 건가요?
“인버팅이 문제다” 라기 보다는 :기존 StyleGAN 방법론의 인버팅 방식이 너무 단순하다” 라는 것이 조금 더 어울리겠네요. 만들고자 하는 영상이 만약 사람의 얼굴이라는 가정으로 예를 들자면, 사람의 얼굴을 구성하는 요소에는 다양한 것들이 존재합니다. (예를 들면 눈, 코, 입 눈썹, 머리 종류와 색, 주름 등등)
즉 사실적인 영상을 만들려면 위에서 예시로 든 다양한 요소들에 대해 다 고려하고 반영이 되어야만 하는데, StyleGAN은 그저 ‘w’라고 표현된 latent space에서 vector를 가져다가 영상을 생성하기 때문에 저 수많은 요소들을 다 고려하지 못하고 이는 리얼한 영상을 생성하지 못한다고 저자는 생각하는 것 같습니다.(물론 제가 이렇게 표현했다고 하더라도 StyleGAN은 그 당시에 뛰어난 성능을 가지며 현재 많은 논문들의 영감을 준 논문이기 때문에 결코 무시할 수 없는 좋은 논문임을 다시 알려드립니다.)
아무튼 그래서 저자는 w벡터 하나만 사용하는 기존 방식과 달리 w1~w18까지 총 18개의 세분화를 통해 각자 다르게 style vector를 적용함으로써 보다 사실적인 영상을 만들려고 한 것입니다.