이번 리뷰는 semi-supervised learning 기반의 object detection에 대해 소개하고자 합니다. 해당 방법론은 Paper with code 기준 COCO dataset에서 #1을 유지하다 근래에 #3에 위치한 방법론이기도 합니다. 해당 방법론은 self-learning 기법으로 유명한 FixMatch를 계승하여 기존의 SOTA 방법론의 성능을 끌어올려 제안한 방법론의 효과를 보여줍니다.

Intro
딥러닝의 학습 기법은 라벨의 유무 혹은 사용 정도에 따라 지도 학습(label-data), 비지도 학습(data), 자기지도 학습(data-data’), 준지도 학습(label-data, data)으로 나눠집니다. 특히 분류 문제에서 지도 학습 기반의 방법론 ResNet은 ImageNet 기준 사람의 인지 능력 에러율 5%를 뛰어넘는 3.6%를 보여줌으로써 제 3의 물결을 일으키게 됩니다. 이처럼 라벨과 데이터로 구성된 데이터 셋을 이용한 지도 학습은 뛰어난 성능을 보여주지만, 사람의 노력으로 데이터를 가공해야한다는 문제가 있습니다. 또한 Yann lecun 교수님은 인공지능이 앞으로 나아가기 위해서는 학습 정보를 주는 지도 학습이 아닌 자기 스스로 학습을 수행할 수 있는 자기 지도 학습(혹은 비지도 학습)으로 나아가야 한다고 이야기합니다.

++ 2019년 이전에는 자기지도 학습과 비지도 학습의 구분이 명확하지 않아 Yann lecun 교수님은 비지도 학습을 나아가야하는 방향으로 이야기 하시다. 2019년 4월 경, 트위터를 통해 용어로 인한 혼란을 피하기 위해 비지도 학습과 자기 지도 학습 구분 짓고, 자기 지도 학습을 입력 정보의 일부를 이용하여 학습하는 기법을 자기 지도 학습으로 정의합니다. 이후부터는 비지도 학습이 아닌 자기 지도 학습이 나아가야하는 방법이라고 강연 자료를 수정합니다.
+++ 위에서 언급한 학습 기법 외에 강화 학습이 있습니다. 강화 학습 또한 스스로 학습을 하지만 행동에 대한 패널티로 수행되는 알고리즘의 특성상, 현실 세계에서의 실패는 치명적인 문제가 될 수 있습니다.
모든 태스크에 자기 지도 학습을 적용하기에는 쉬운 일이 아닙니다. 자기 지도 학습은 예측값을 토대로 입력 또는 입력의 일부로 복원 혹은 관계를 측정하여 학습을 진행합니다. 하지만 분류 문제나 물체 검출 문제와 같이 입력값 대비 예측값에서 정보 손실이 크게 일어나는 경우에는 복원 혹은 관계에 대한 측정이 어려워 충분한 학습 정보를 획득하기 어렵습니다. 이러한 한계를 극복하고 나아가고자 지도 학습과 비지도 학습을 섞은 준지도 학습 기반 방법론들이 연구되어지고 있습니다.
준지도 학습 기반의 연구들은 크게 consistency method, pseudo-label method로 나눠집니다. 먼저 consistency method는 동일한 데이터에 노이즈가 발생해도 모델은 일관성을 가지도록 예측해야한다는 컨셉을 가진 방법론입니다. 대표적인 방법론으로는 RotNet, SimCLR이 있습니다. 남은 하나는 언라벨 데이터에서 예측된 정보를 label로 사용하는 pseudo-lable method가 있습니다. 더욱 다양한 데이터를 봄으로써 보다 강인한 예측이 가능해집니다. 대표적인 방법론으로 SeletiveNet이 있습니다. 이번 리뷰에서 다룰 방법론은 앞서 설명한 2가지(준지도 학습에서의) 방법론을 결합하여 사용합니다. 대표적인 예시로 FixMatch는 Teacher model로부터 pseudo-label을 생성할 뿐만이 아니라 student model은 teacher보다 강인한 구분력을 가지기 위해 입력 데이터에 weak augmentation, strong augmentation 가합니다. 이를 통해 student model은 teacher model보다 강인한 구분력을 가지게 되며, teacher model을 뛰어넘는 성능을 보여줍니다. 하지만 FixMatch는 분류 문제에서의 방법론입니다. 물체 검출에서는 보다 어려운 예측을 수행해야하며, 영상당 하나의 예측이 아닌 영상 내 물체의 갯수에 따라 변동적인 예측을 수행해야합니다. 그렇기에 저자는 FixMatch의 알고리즘을 따르되, 물체 검출에 적합하도록 새로운 방법론을 제안합니다.
Method
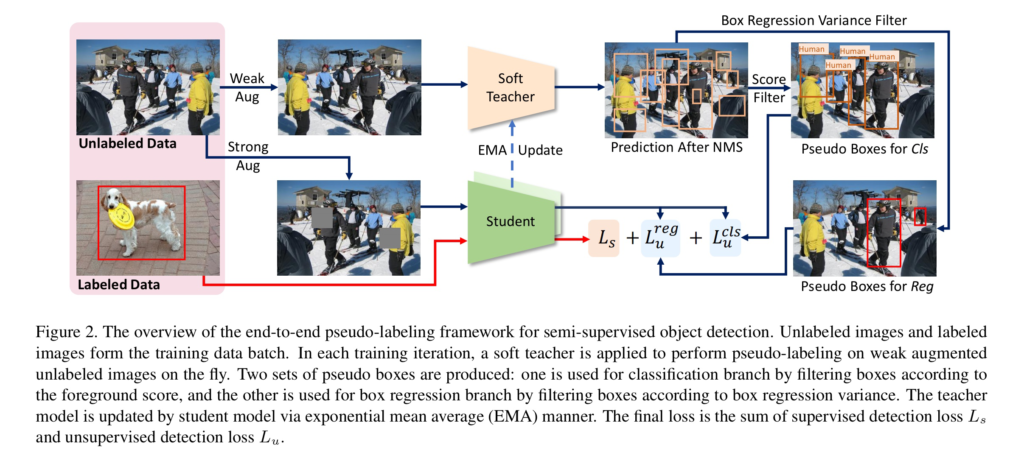
End-to-End Pseudo-Labeling Framework
해당 방법론은 pseudo-label 기반의 준지도 물체 검출 알고리즘으로 처음 end-to-end framework를 제안하였습니다. 이전 pseudo-label 기반 연구들과 동일하게 teacher-student training scheme를 가집니다. 학습 단계에서는 labeled data와 unlabeled data가 일정 비율로 섞여 랜덤하게 샘플링되어 batch로 입력됩니다. 그후 teacher model은 unlabeled data로부터 psuedo-label을 생성합니다. 그리고 student model은 labeled data와 unlabeled data 둘 모두 학습에 사용하며, labeled data는 ground truth를, unlabeled data는 pseudo-label을 ground truth로써 사용화여 사용합니다. 최종적으로 student model은 supervised loss L_s와 unsupervised loss L_u로 정의된 함수의 weight sum된 최종 loss L을 이용하여 학습이 진행되어집니다.
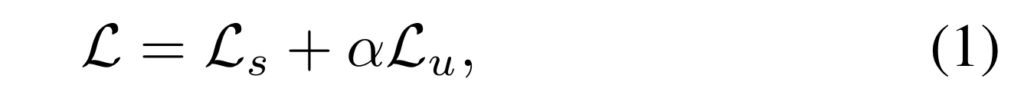
각각의 loss는 물체 검출를 고려하여 classification loss L_cls, regression loss L_reg로 구성되며, 영상 단위로 손실 함수를 계산합니다.
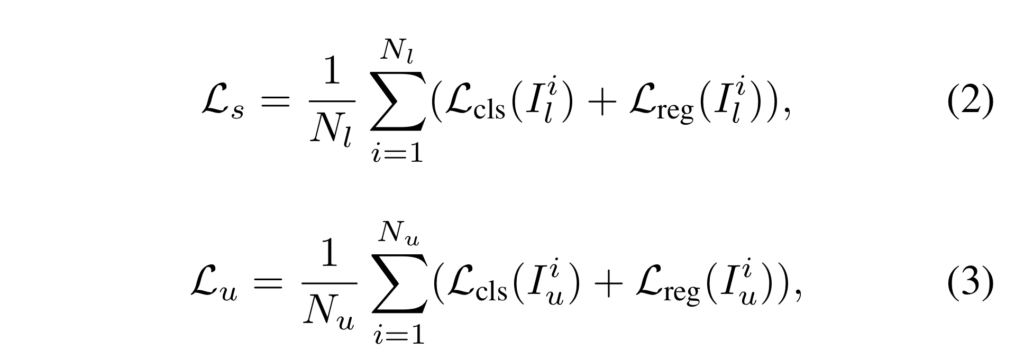
학습 초기에는 teacher model과 student model의 랜덤하게 초기화된 값을 사용하다가, student model이 loss로부터 wight를 업데이트가 진행된 후, teacher model은 student model로부터 exponential moving arverage(EMA)를 통해 파라미터를 업데이트 받습니다.
Pseudo-label은 teacher model의 오차마저 전달하기 때문에 teacher model은 불확실한 정보에 대한 필터링을 수행합니다. 가장 먼저 non-maximum suppression(NMS)을 수행하여 중복된 값들을 제거합니다. 하지만 여전히 전경이 아닌 불확실한 후보군들이 많기에 foregroud score가 임계값보다 높은 후보군만 남깁니다. 이에 대한 이야기는 후에 soft teacher에서 자세히 다루도록 하겠습니다.
그리고 높은 퀄리티의 psuedo-boxes와 student model의 학습을 용이하게 하기 위해서 최신 준지도 학습 기반인 FixMatch을 계승하여, weak augmentation과 strong augmentation을 unlabeled data와 pseudo-label에 대한 학습을 진행합니다. 또한 boxex의 신되도를 추정하여 필터링을 수행합니다. 해당 부분은 box jittering에서 자세히 다루도록 하겠습니다.
Soft Teacher
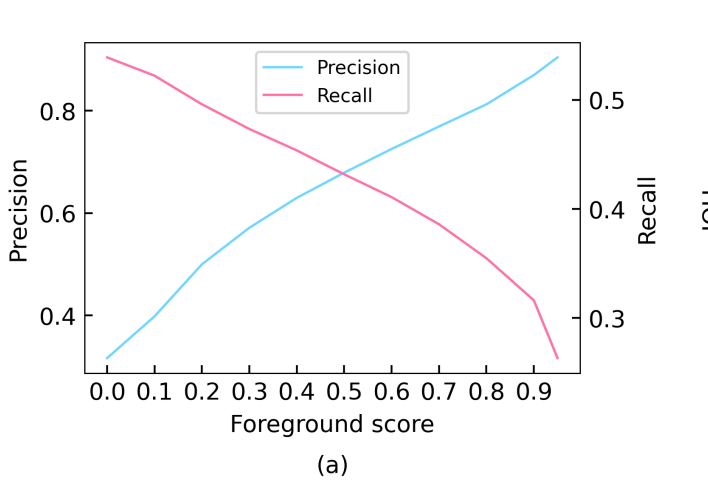
Pseudo-label의 정확도는 매우 중요한 요소에 해당합니다. 위의 그림과 같이 foreground score를 0.9로 지정하고 예측할 경우 precision은 0.89으로 가장 높은 성능을 보여줍니다. 하지만 recall인 경우 0.33의 저조한 성능을 보여줍니다. 이 이야기는 즉, 잘못된 예측이 전달된 가능성이 높아진다는 이야기 입니다. 이는 모델의 학습을 잘못되도록 이끌 수 있으며, 성능을 저조하게 만들 수 있습니다. 이런 문제를 해결하기 위해서 저자는 soft teacher를 제안합니다. Soft teacher는 예측된 값의 신뢰도를 추정하여 예측된 background에 가중 부여함으로써 False Negative의 케이스에 대한 방영을 할 수 있도록 합니다.
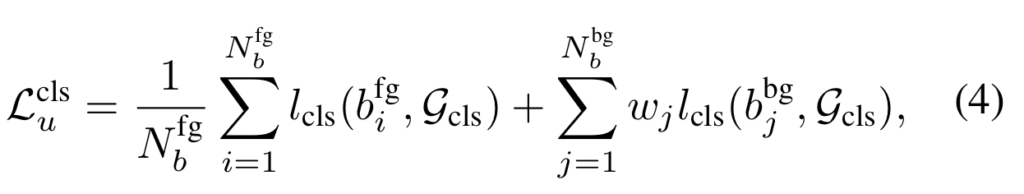
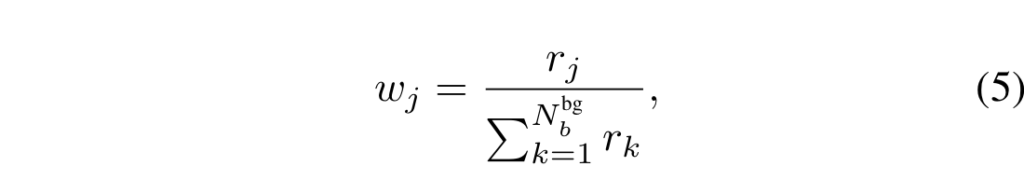
분류를 위한 psuedo boxes 집합 \mathcol{G}_cls 이며, l_cls는 classification loss에 해당합니다. j-th 배경의 background 후보의 신뢰도 score r_j에 해당합니다. 위에서 설명한 바와 같이 negative에 해당하는 값들을 필터링을 수행하기 위해서 배경 후보 박스들에 대한 가중치를 부여하여하기 위한 수식 4-5에 해당합니다. 하지만 신뢰도를 예측하는 방법은 매우 까다롭습니다. 저자는 이러한 케이스를 해결하기 위해 6가지 경우를 실험적인 방법을 통해 선별합니다.
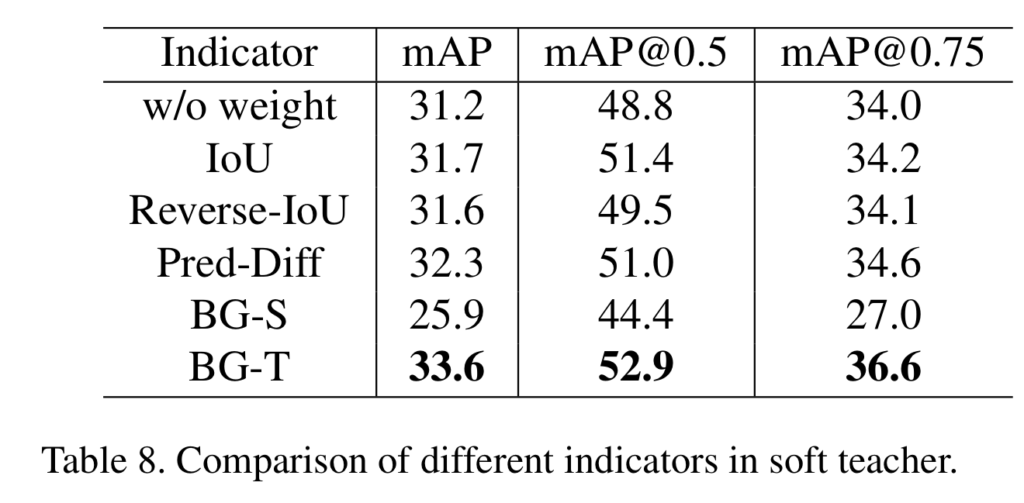
저자는 가중치가 없는 경우와 Pseudo-label과 student model의 예측 정보간 IoU를 이용하는 방법, 이에 대해 역치를 취한 방법, teacher-student class probability의 차이를 이용한 Pred-Diff, Student model의 background score ~ BG-S, Teacher model의 background score~BG-T를 이용하여 실험을 진행했습니다. 실험 결과, Table 8과 같이 BG-T를 신뢰도 점수 r로 사용했을 때, 가장 좋은 성능을 보였으며, 이를 이용하여 예측되지 못한 경우에 대해 보완을 했습니다.
Box Jittering
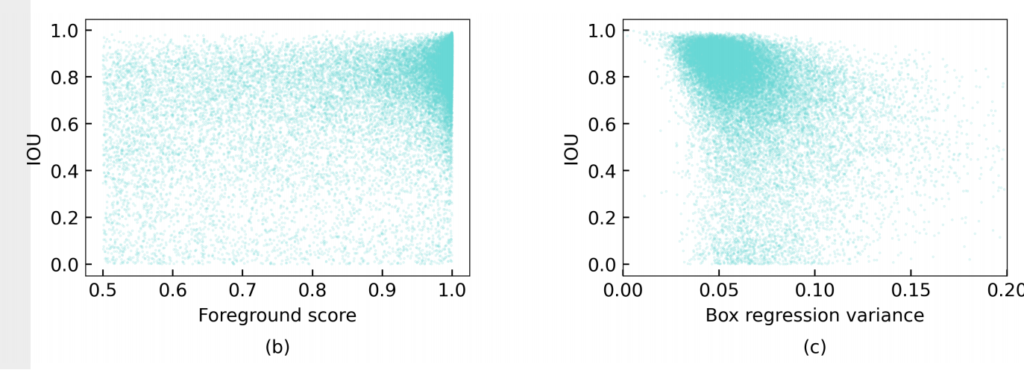
물체 검출은 class 분류 뿐만이 아니라, 물체의 위치에 예측도 수행되기에 정확한 pseudo-label을 생성하기 위해서는 bbox에 대한 보완이 이뤄져야합니다. 위의 IoU와 foreground socre의 관계가 표현된 그림 b를 보면 두 변수가 강한 상관관계를 가지지 못한 것을 볼 수 있습니다. 보완을 위해서 예측된 정보의 신뢰도를 측정해야하지만, 약한 상관 관계로 신뢰도로 사용하기에는 비적합한 모습을 보여줍니다. 저자는 이러한 상황 때문에 보다 적합한 방법을 요하게 됩니다. 이에 저자는 Box jittering을 제안합니다.
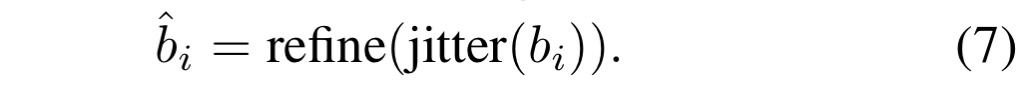
수식 7과 같이 예측된 bbox bi를 jittering을 수행합니다. 이후 teacher model에 다시 refine 됩니다. N개의 jittring을 수행하여, refined jittered boxes set { \hat{b_i_j} } 을 획득하고 이에 대한 각 box의 좌표 별 standard derivation \sigma_k 를 계산합니다.
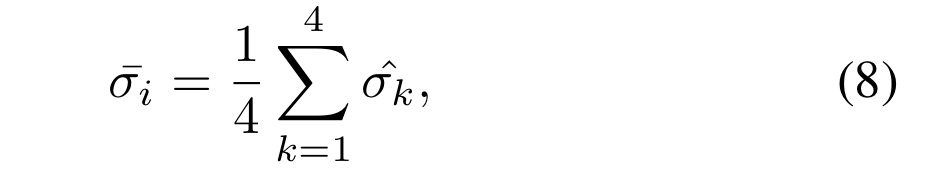
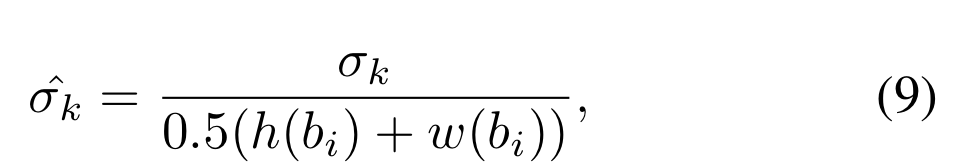
그 후, 수식 9와 같이 기존 box에 정규화를 수행 후, 수식 8과 같이 모든 값들을 더해 box regression variance를 획득합니다. 해당 값은 위의 그림 c와 같이 그림 b 보다 높은 상관 관계를 보여주고 있습니다. 이러한 점을 이용하여 저자는 먼저 foreground socre 0.5 이상의 값들에 대한 box regression variance를 구하고 일정 임계값 이하의 값들만을 이용합니다.
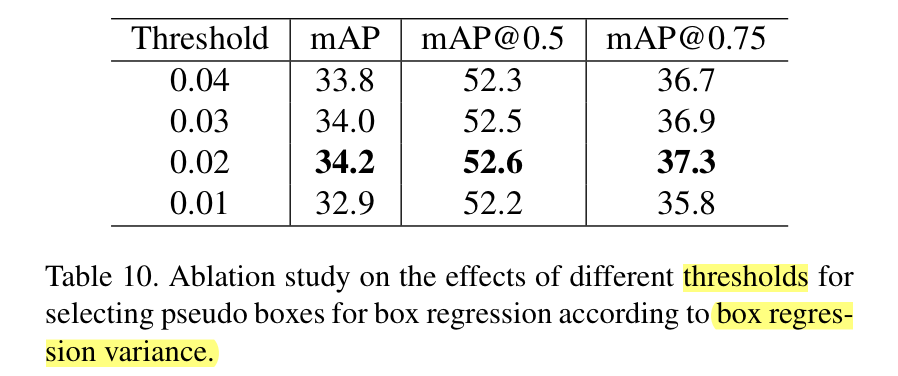
해당 값은 실험적으로 0.02를 이용했을 때, 가장 높은 성능을 보여주고 있다고 합니다.
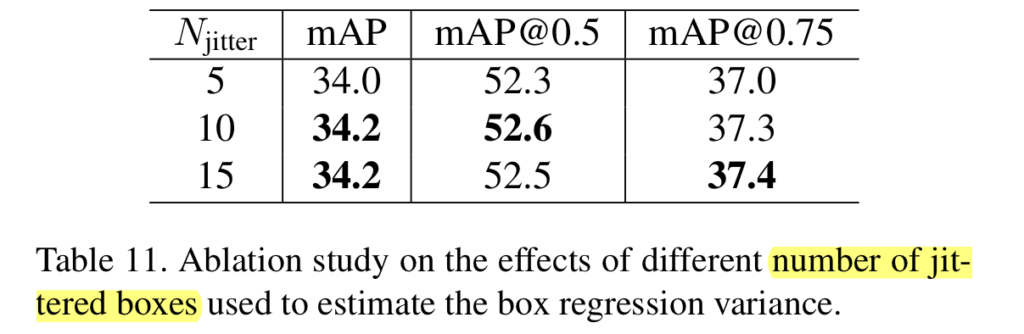
Jittering은 아래의 표와 같이 10개로 증강하여 사용했을 때 더 좋은 성능을 보여준다고 합니다./
Experiment
저자는 일반화된 검증을 위해 Fast-RCNN에서의 수행과 SOTA 모델인 HTC를 이용하여 실험을 진행했습니다. 모든 실험은 MS COCO에서 수행되어졌으며, unlabeled data인 경우 coco에 속한 unlabeled2017을 이용하였습니다.
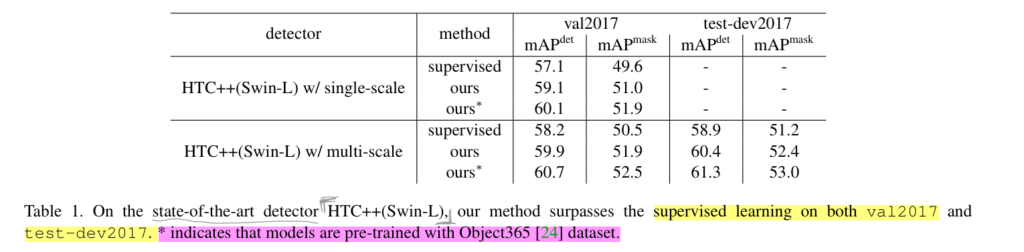
Table 1에서 보이는 바와 같이 SOTA인 HTC가 해당 방법론을 사용하여 성능이 향상된 것을 볼 수 있으며, pretrained weight를 사용하여 더 높은 성능으로 끌고 올라 최종적으로 물체 검출과 객체 분할 알고리즘에서 가장 높은 성능을 가져온 것을 볼 수 있습니다.
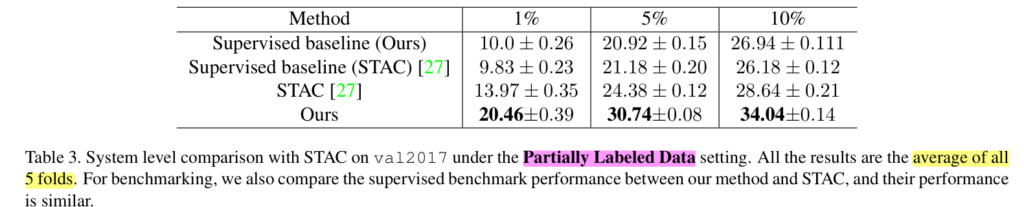
또한 물체 검출에서의 준지도 학습 방법론에서도 SOTA를 달성한 것을 볼 수 있습니다. 해당 실험은 train2017의 라벨 데이터의 비율을 {1, 5, 10}% 변경하고 수행한 실험이며, 확실한 검증을 위해 5-folds를 수행한 결과에 해당합니다.
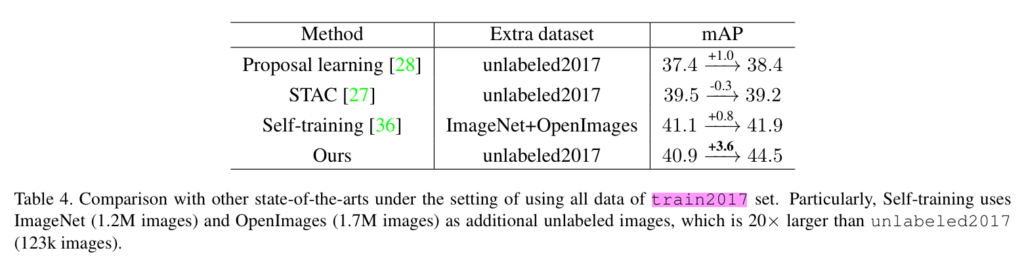
또한 외부 데이터 셋을 이용하는 준지도 학습인 경우에도 타 방법론보다 +3.6의 높은 성능 개선을 보여줌으로써 해당 방법론의 효율성을 보여줍니다.
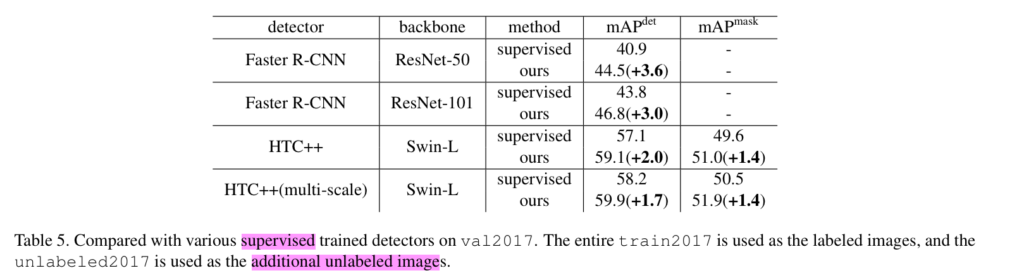
또한 Faster R-CNN에서도 실험을 진행하여, SOTA 모델 뿐만이 아니라 다른 물체 검출 알고리즘에서도 효과를 보일 수 있음을 증명합니다.
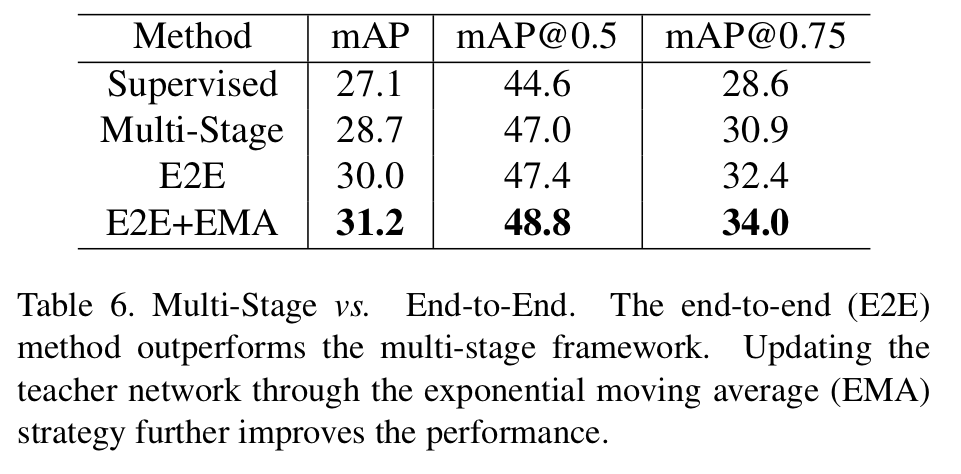
Table 6에서는 End-to-End로 변경함으로써 얻는 성능 개선을 보여주고 있습니다. 최종적으로 EMA를 추가하여ㅛ mAP 31.2의 성능을 보여주고 있습니다. 여기서 Multi-stage는 이전의 psuedo-label method들이 사용하고 있는 방법으로 teacher model과 student model을 별개의 phase로 보고 수행한다고 생각하시면 됩니다.
===========================================================
등잔 밑이 어둡다고… 생각하고 있던 그림이 SOTA로 존재하고 있어 아쉬움이 많았습니다. 그래서 그런지 여러 문제점들을 해결하는 부분에서 보다 충격적으로 다가왔고 역시 잘하는 사람들은 너무 많다는 것을 다시 한번 깨닫는 계기가 되기도 했습니다. 좀 더 기술적인 부분에서 문제를 정의하고 해결책을 고민하는 노력을 해야겠습니다.
좋은 리뷰 감사합니다. 제가 self-supervised object detection을 아예 몰라서 흐름이 이해가 안가는데, Method 처음 그림을 보면 soft teacher 모델에는 unlabeled image만 들어가는데 GT가 없는 상황에서 soft teacher 모델을 어떻게 학습하나요..?
student model 파라미터를 teacher model로 전달함으로써 학습을 합니다. 전달 시, EMA로 전달합니다. 이해를 돕기 위해 보다 상세히 설명드리자면, 해당 기법은 가중 평균으로 파라미터 값을 업데이트 하며 가중치는 student model의 파라미터 쪽에 0.9를 가하여 업데이트 합니다.
++가중평균:w_t’ = a×w_s + (1-a)×w_t, a=0.9