제가 이번에 리뷰할 논문은 의료 분야에서 self-supervised 방식의 instance segmentation을 적용한 논문입니다.
Abstract
자궁경부세포의 객체 분할을 위해 Mask-guided Mean Teacher framework with Perturbation-sensitive Sample Mining (MMT-PSM)을 제안하였습니다. 제안한 방법론을 작은 변화에는 일관적인 예측 결과가 나오는 것을 목표로 하였습니다. MMT-PSM은 semantic distillation을 빠르고 효과적으로 하기 위해 대규모의 상황에서 정보 샘풀을 선택합니다. 그리고 배경의 노이즈를 제거하기 위해 segmentation 마스크 예측을 이용하여 전경을 강화합니다.
Introduction
Pap smear 검사는 조기 자궁경부 검진 절차로 세포의 유형과 세포학적 특징을 추정하여 적절한 지침이나 의학적 관리를 제공하고자 한다고 합니다. 즉 세포 검사를 통해 적절한 의료적 행위를 제공하는 것이라 합니다. 세포 분할을 자동화 하면 의사가 시간이 소모되는 일로부터 자유로워질 수 있고 관찰자에 따른 가변성도 줄일 수 있습니다. (관찰자에 의한 가변성이 감소한다는 것은 주관성이 줄어든다고 이해하면 될 것 같습니다.) DeepLearning 방법론이 유망하지만 최적화는 고밀도의 annotation을 가진 대량의 데이터에 의존하므로 시간과 비용이 많이 드는 데이터에 의해 정확도와 일반화 성능이 제한됩니다. 따라서 unlabeled 데이터에 label을 할당해 모델의 파라미터를 최적화 할 수 있는 self-training 방법론을 제안합니다.
본 논문에서 제안하는 MMT-PSM은 semi-supervised knowledge disillation 방법론으로 semantic, feature distillation이 함께 수행됩니다. end-to-end 방식으로 teacher, student 모델로 이루어져 있고 작은 변동을 가진 샘플이 주어졌을 때 두 네트워크로부터의 예측 결과가 일관적일 수 있도록합니다. teacher 네트워크에서 K번 augmented 된 샘플들의 mean prediction은 student 네트워크에 pseudo label로 이용됩니다. Perturbation-sensitive sample mining 방식은 불균형과 방대한 데이터의 쉬운 상황에서의 무의미한 지침을 해결하는 데 사용됩니다. 게다가 배경의 noisy로 인한 부작용을 줄이고자 전경으로만 구성된 mask-guided 특징 증류를 제안합니다.
Method
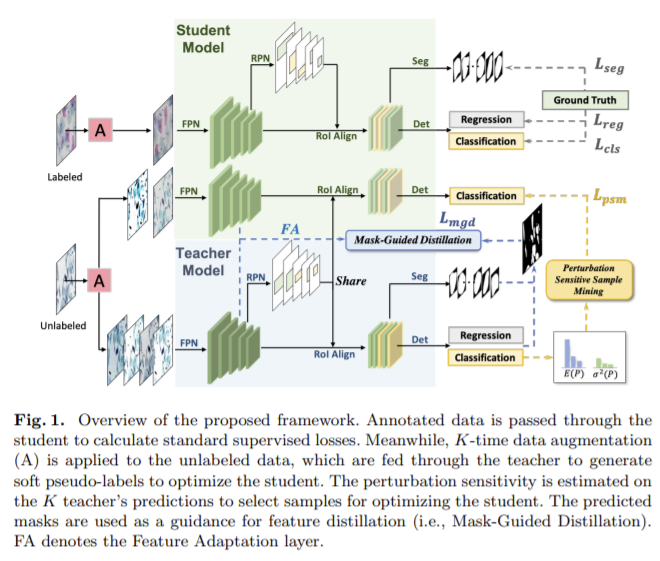
- Mean Teacher Framework for Instance Segmentation
D_{L} = \{{(x_i,y_i)}\}^N_{i=1} 를 labeled 데이터, D_{U} = \{{(x_i)}\}^{N+M}_{i=N + 1} 를 unlabeled 데이터라 정의하면 semi-supervised 학습은 unlabeled 데이터에 있는 숨은 정보를 활용하여 성능을 높이고자 합니다.
본 논문에서는 Teacher와 Student의 backbone으로 Mask R-CNN을 이용하여 객체 분할을 하며, 각 모델은 4개의 모듈로 구성되어 있습니다.
1. 다른 모듈의 input이 되는 FPN(feature pyramid network)__(teacher와 student가 공유함)
2. RPN 이 RoI Align layer와 함께 구성되어 객체가 존재할 영역 제안
3. detection branch (Det)를 통해 detection score 예측
4. segmentation branch(Seg)를 이용하여 spacial revision 벡터와 segmentation 예측
Mean Teacher (MT) 알고리즘을 기본 프레임워크로 사용하며 EMA를 이용하여 학상의 가중치를 교사모델로 활용합니다.
2. Perturbation-sensitive Samples Distillation
객체분할에 MT를 사용하면 표본 불균형에 의해 모든 예측에 대한 loss를 계산하는 것은 효과적이지 못합니다. 따라서 K-time augmented sample의 평균 예측을 T 에서 신뢰할 수 있는 대상으로 이용해 민감도에 따라 샘플을 선택합니다.
Self-ensembling pseudo-label stochastic Augmentor(A)를 이용하여 teacher 와 student 모델에 각 각 K , L 개의 샘플로 증강합니다. 증강한 데이터들의 평균 예측을 통해 teacher 모델에서 soft pseudo-label을 생성한 뒤 엔트로피 최소화를 위해 sharpen function ![]() 을 이용합니다.
을 이용합니다.
Perturbation-sensitive sample mining. Teacher 모델과 Student 모델의 정확도가 큰 차이가 있는 샘플(perturbation-sensitive sample)이 학습에 유용하다고 가정하고 클래스 확률이 최대인 클래스가 hard pseudo-label로 할당됩니다. (teacher 모델과 student 모델 사이의 예측이 비슷하도록 하고자 하기 때문에 두 결과가 큰 차이가 있는 샘플이 학습에 유용하다고 가정한 것으로 이해하면 될 것 같습니다.) 그 후 K번 증강된 샘플의 분산을 perturbation-sensitive로 계산하고 다음의 식(3)을 통해 변동에 민감한 샘플 마이닝 loss를 구할 수 있습니다.
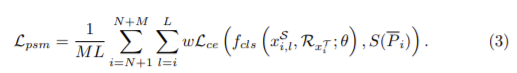
f_{cls}(·;θ)는 student의 Det, R_{x^T_i}, \bar{P_i}는 perturbation-sensitive sample의 proposal과 soft pseudo-labels, \mathcal{L_{ce}}는 cross entropy loss, w는 class-balanced 가중치
3. Mask-Guided Feature Distillation
전체 feature map의 차이를 이용하여 학습을 하게 되면 배경에서 노이즈가 발생할 수 있으므로 semantic segmentation의 결과를 이용하여 student가 teacher를 따라가도록 합니다.
FPN의 출력층 이후에 feature distillation를 위해 1×1 conv로 구성된 adaptation 층을 넣고 입력 feature의 차원을 반으로 줄입니다.
Student와 Teacher의 feature 값을 Z^{S}_{tijc}와 Z^{T}_{tijc}라 하고 feature간의 거리를 최소화 하기 위해 mask-guided distillation loss를 제안하였고 다음 식으로 표현됩니다.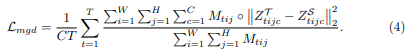
Total loss
전체 loss는 \mathcal{L_{sup}} Mask R-CNN의 classification loss와 regression loss, segmentation loss의 합이고 λ(t)는 초반에는 \mathcal{L_{sup}}가 우세하고 학습을 진행하며 점차 증가하다 마지막에 천천히 감소하도록 하는 함수이고 γ는 5로 설정된 balanced weight입니다.
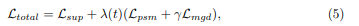
Experiments
- D_{L} : 학습에 사용된 데이터는 환자들로부터 채취된 세포로 4439개의 세포질 및 4789개의 핵에 대한 주석을 가진 데이터 세트를 사용하고 train:valid:test = 7:1:2로 데이터를 구성합니다. train은 1000×1000의 크기로 0.75의 비율로 겹치게 crop하고 validation과 test데이터는 겹치지 않도록 자릅니다. ( train 961장, valid 50장, test 98장)
- D_{U} : 1000×1000해상도로 무작위로 crop된 주석이 없는 4371장의 이미지로 구성되어있습니다.
Average Jaccard Index(AJI)와 mean Average Precision(mAP)를 평가지표로 사용합니다.

labeled 데이터로만 학습된IR-Net과 비교했을 때 성능 향상을 확인할 수 있습니다.(tabel 1) 또한 다른 semi-supervised 방식과 비교했을 때 준지도학습이 지도학습보다 성능이 좋은 것을 확인할 수 있습니다.
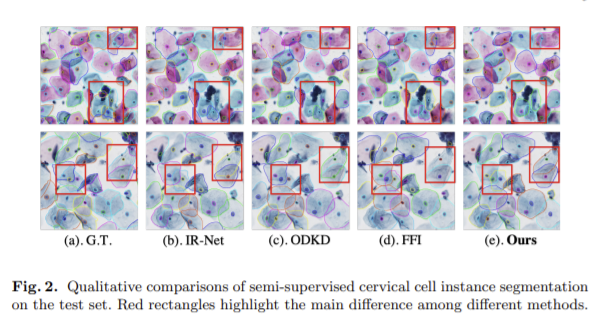
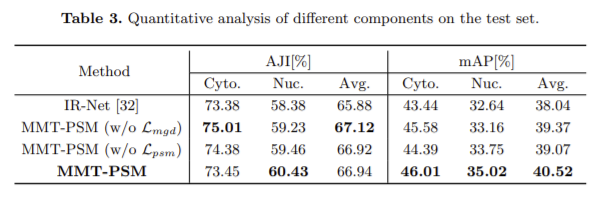
지도학습과 해당 방법론의 성능 비교는 확실하지만 다른 준지도학습 방식과 비교했을 때는 성능 향상이 뚜렷하다고 할 수는 없는 것 같습니다. 본 논문에서 수식으로 표현을 많이 했는데 활용을 하면 좋을 것 같습니다.
1. 해당 방법론에서는 Pseudo-label을 만들 경우, K번의 augmentation을 수행한다고 했습니다. 이에 대한 ablation study는 없었나요? 또한 어떤 augmentation을 수행했는지 궁금합니다.
2. 제안된 방법론의 이전 제안된 방법론과 차별성은 무엇인가요? ‘Perturbation-sensitive Samples Distillation’ 해당 모듈 말고는 없나요?
샘플의 작은 변동 / 변화라는 게 어떤 뜻인가요?
그에 대한 정량적인 기준이 있는 것인지 궁금합니다. (ex. n 픽셀 차이, 몇 도 rotate 같은…?)