이번 논문은 현재 Paper with code에서 Fine-grained classification에서 SOTA를 달성한 방법론입니다. 제목에서도 유추가 가능하다시피 Transformer를 기반으로 설계된 네트워크이며, 추가로 각 클래스간 차별성을 극대화하기 위해 Contrative loss와 주 관심 영역을 patch 단위로 선택하는 Part Selection Module이 추가된 방법론입니다. 중기청 과제 중 작물 병해 검출을 위해 관심을 가진 논문이며, 추후 CAM을 이용한 병해 위치 검출 모델로 확장을 고려하고 있던 방법론입니다.
Intro
먼저 Fine-grained classification을 모르시는 분들을 위해 간단한 설명을 드리겠습니다. 컴퓨터 비전 분야 중 가장 기초에 해당하는 분류 문제는 크게 두 가지로 구분 할 수 있습니다. 하나는 Coarse-grained classification이라고 칭하는 큰 분류(e.g. 분류학의 목)에서의 분류 문제입니다. 예를 들면 사람, 고양이, 개, 책상 등 ImageNet이나 VOC 데이터 셋 등 대부분의 분류 데이터 셋에서의 분류기 모델이 이에 해당한다고 보시면 됩니다. 이번 리뷰에서 주로 다룰 Fine-grained classification은 작은 분류(e.g. 분류학의 종)에서 분류 문제에 해당합니다. 예를 들면 고양이, 새 품종 분류, 같은 품종의 작물 병해 분류 등을 볼 수 있습니다.
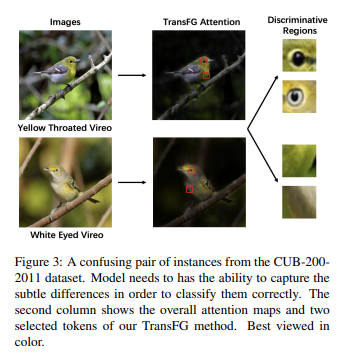
Fine-grained classification은 Corase-grained classification보다 좀 더 어려운 문제를 해결해야만 합니다. Fig 3에서 볼 수 있다시피 Yellow Throated Vireo와 White Eyed Vireo은 매우 유사한 형태를 가지고 있지만, 이름에서 유추할 수 있다시피 목과 눈을 통해 구분이 가능합니다. 이런 작은 차이는 새 전문가가 아닌 비전문가가 봤을 때는 구분하기 힘든 미세한 차이라고 볼 수 있습니다. 이처럼 Fine-grained classification은 유사한 분류 대상의 미세한 차이로부터 구분할 수 있는 능력을 가져야만 합니다.
미세한 차이로부터 강한 분류 능력을 가져야하는 분류 대상 간 미묘한 차이가 아닌는 크게 두 가지 방법으로 구분되어져 연구되어졌습니다. 하나는 분류 대상 혹은 차별 영역의 지역적 위치를 먼저 찾고 분류를 수행하는 방법으로 대표적인 알고리즘으로 Mask-RCNN과 CRF 기반의 segmentation이 있습니다. 허나 이는 주석을 위한 추가적인 노동력이 필요하고 또한 주석을 만들기 위해서는 특징을 구분하기 위한 전문가의 판단이 필요하다는 단점이 있습니다. 또한 위치를 찾아도 feature extractor를 통해 추가적인 분류를 수행해야하기 때문에 충분한 구분 능력을 갖추기 위한 충분한 해결책은 아니였습니다. 또 다른 한가지는 Feature-encoding 에서 차별성을 극대화하는 방법하는 방법입니다. 대표적인 알고리즘으로 Contrative learning이 이에 해당합니다. 차별성을 가진 정보들을 대조적으로 배치함으로써, 그들 사이에서 미묘한 차이를 포착할 수 있도록 학습을 유도하도록 합니다. 하지만 이는 모델이 하위 범주의 미묘한 차이를 어떻게 구분하는지 원인을 알 수 없다는 문제가 있습니다. 즉, 배경의 차이, 혹은 분류 대상의 촬영 각도 혹은 포즈 등 분류 대상 간 미묘한 차이가 아닌 다른 요소로부터의 패턴을 검출하여 구분할 가능성이 있어, 환경 불변한 성능을 갖추지 못할 가능성이 높다는 문제가 있습니다.
저자는 기존의 Fine-grained classification 문제점을 영상을 패치 단위로 나눠 feature-encoding을 수행하는 Transformer의 특성을 이용하여 분류 대상의 위치에 해당하는 구역 패치를 선택하는 Part Selection Module과 차이를 가진 정보를 대조적으로 배치하여 스스로 차별성을 기르는 contrative loss를 통해 Fine-grained classification의 두 분류의 장단점을 결합한다고 이야기합니다.
Method
Vision transformer as feature extractor
기존 ViT는 중복되는 구역 없이 영상으로부터 패치를 생성합니다. 하지만 저자는 이는 인접한 정보를 상실하는 문제를 가져가기 때문에 중복된 영역을 고려하여 패치 x_p를 생성하야한다고 주장합니다.
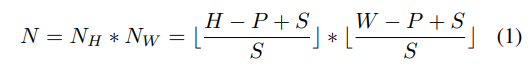
식 1과 같이 패치를 생성합니다. ++ 수식 1은 컨볼루션 필터랑 동일하게 생성한다고 보시면 될 것 같습니다.
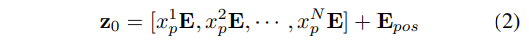
각각의 패치들은 수식 2와 같이 위치 정보 E를 가진 상태에서 패치 임베딩이 수행됩니다.
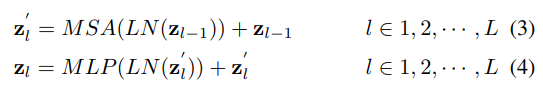
Transformer encoder는 수식 3과 수식 4와 같이 각 레이어에서 Multihead self-attention(MSA)와 Multi-layer perception(MLP)가 수행됩니다. ++LN은 Layer Normalization
최종적으로 생성된 global feature는 분류기를 통해 최종 분류 결과를 출력합니다.
++ 전형적인 ViT 구조를 설명한다고 보시면 됩니다.
TransFG Architecture-Part Selection Module
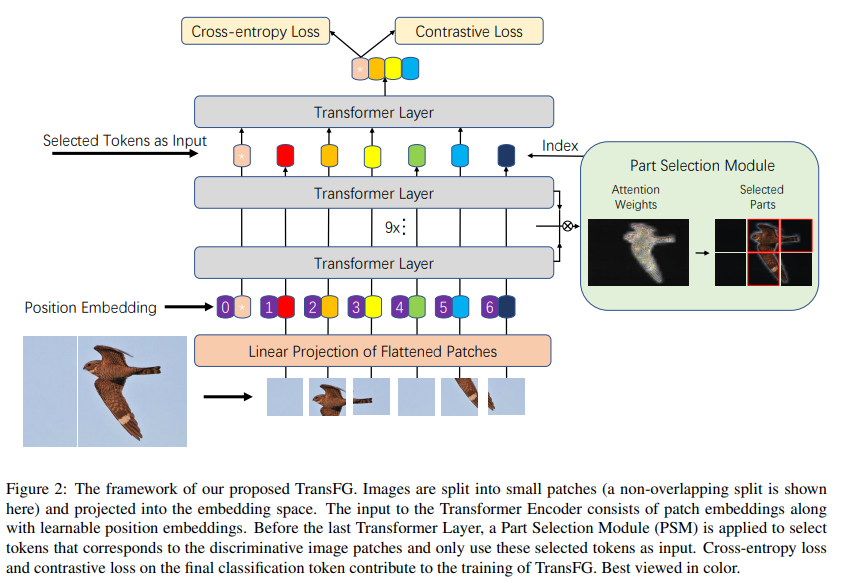
앞서 설명한 바와 같이 미세 분류는 작은 분류간 미세한 차이를 찾는 것이 매우 중요한 요소입니다. ViT는 이에 매우 적합한 모델에 해당하며, 패치의 위치 정보와 attention 기법으로 인해 위치 정보도 수용할 수 있다는 매우 큰 장점이 습니다.
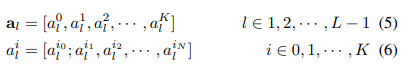
저자는 이러한 기능을 더욱 강인하게 만들기 위해서 수식 5와 6과 같이 각 레이어에서 수행된 MSA의 attention a을 고려하여 다시 한번 집중하고자 하는 patch 구역을 선별하고자합니다.
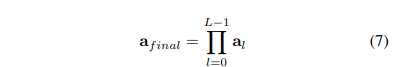
각 레이어에서 생성된 정보를 고려하기 위해 수식 7과 같이 각 레이어 별 attention weight 에 대한 곱 연산을 수행합니다. ++ 수식 7, global attetion로 (K, K)의 matrix가 생성됩니다. K는 Multi-head atention의 head 갯수에 해당합니다.
그 다음 수식 7의 값에서의 최대과 되는 index (K, ) A를 추려 모델이 집중해서 보는 영역들을 거르도록 합니다. 이를 통해 모델이 생성하는 특징 정보 중 노이즈가 될 수 있는 영역들은 버림으로써, 집중하고자하는 특징이 존재하는 정보들만 사용할 수 있게된다고 합니다.
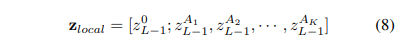
++ 수식 8이 PSM에 해당하며, 0 번째인 경우, patch 자체의 정보에 해당하기 때문에 정보를 그대로 사용합니다.
Contrastive feature learning
기존 ViT에서는 크로스 엔트로피 로스만을 이용하여 분류기를 학습합니다. 하지만 미세 분류에서는 해당 로스만 사용할 경우 작은 분류에서의 미세한 차이가 매우 작은 값으로 생성될 가능성이 높기 떄문에 적합하지 않다고 합니다. 그렇기에 같은 레이블 간의 차이는 최소화하고 다른 레이블에서의 차이를 극대화하는 Contrative loss를 채용하여 모델을 학습할 것을 제안합니다.
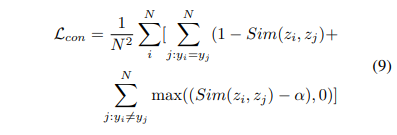
수식 9와 같이 일반적인 Contrative loss를 사용합니다. 여기서 유사도 점수는 cosine similarity를 이용하여 계산합니다. 저자는 최종적으로 수식 10과 같이 크로스 엔트로피와 contrative loss를 같이 사용할 것을 제안합니다.
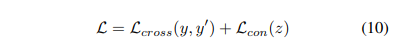
Experiments
해당 논문에서는 미세 분류 데이터 셋으로 유명한 CUB-200-2011, Stanford Cars, Staford Dogs, NABirds, iNat2017에서 평가를 진행하였습니다.
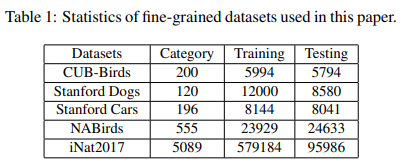
++ 각 데이터 셋에 대한 보다 구체적인 설명이 논문에는 없어 추가적인 조사가 필요했습니다. 자세한 정보가 궁금하신 분이 계신다면 추가로 기재하도록 하겠습니다.
모든 실험은 ViT-16-B를 기반으로한 모델을 이용하였으며, Random horizontal flipping, AutoAugment를 데이터 증강으로 적용하였습니다. ++ 코드에서는 데이터에 따라 CenterCrop 혹은 RandomCrop을 추가로 수행하였습니다.
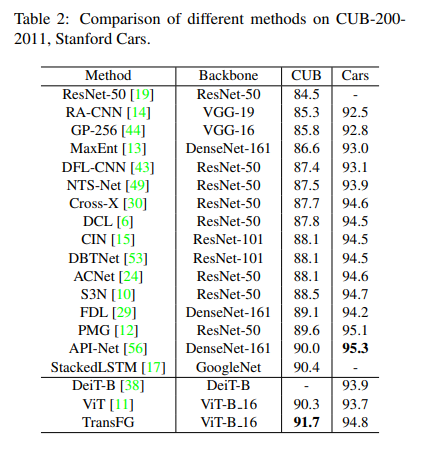
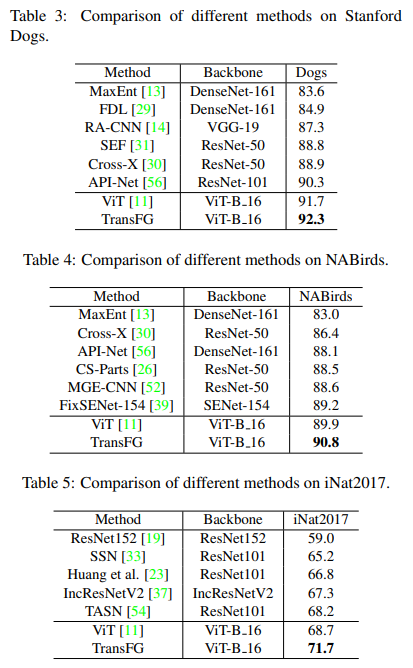
각 데이터 셋에서 ViT보다 0.9-3%의 성능 개선을 보여주며, SOTA를 달성한 것을 볼 수 있습니다. 이를 통해 PSM을 이용하여 위치 정보를 더 가하는 것이 미세 분류의 성능 개선을 보여준다는 것을 증명하고 있습니다.
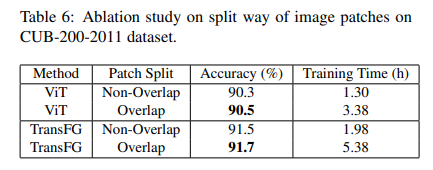
또한 Table 6을 통해 중복된 패치와 중복 패치를 사용한 결과에 따른 성능을 보여줍니다. 이를 통해 인접 픽섹의 정보를 같이 활용하는 것이 보다 구분력이 강한 특징을 임베딩한다는 것을 보여줍니다.
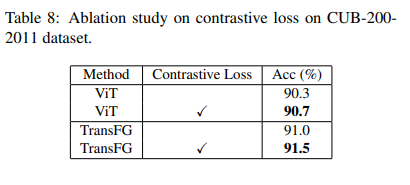
Table 8에서 Contrative loss에 대한 ablation study를 수행하였습니다. 미세 분류에서 contrative loss가 ViT와 TransFG에서 효과를 보여주며,
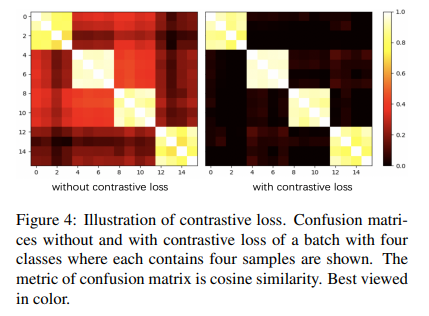
Fig 4를 통해서 같은 클래스간 feature가 점점 유사해짐을 보여주고 있습니다.

Fig 5는 각 클래스에서의 token postion 시각화 그림입니다. 1, 3번째 행은 상위 4개의 토큰 위치를 시각화한 정보이며, 2,4번째 행은 PSM을 통해 획득한 global attetion에 해당합니다. 1,3번째 행으로 통해 각 클래스 별로 고유 특징이 될 수 있는 지역을 주 관심 지역으로 보고 있는 것을 확인 할 수 있으며, 2,4번째 행으로 통해 전경과 배경을 구분하는 모습을 확인 할 수 있습니다.
=======================================================================
해당 방법은 영상 패치화로 지역 정보를 더 고려한 ViT에서 더 나아가 global attetion을 통해 다시 한번 집중하는 구역을 인덱싱함으로써 더욱 고도화된 위치 정보를 부여합니다. 실험적인 결과로 간단한 방법으로만으로도 성능이 개선된 모습을 보여주고 있으며, 또한 정성적인 결과를 통해 설명 가능한 모델의 가능성을 보여줍니다.
추후 기회가 된다면, 정상 작물로부터 Image Transloation으로 생성한 병해 작물을 해당 모델에 contrative learning으로 학습을 시킨 후, Grad CAM 혹은 Patch-level의 attetion을 이용하여 병해 위치를 검출하는 알고리즘을 실험해볼 예정입니다.