이번에 리뷰할 논문은 다소 옛날? 논문인 2018년도 논문으로 가져와봤습니다. 해당 논문을 알게 된 계기는 Swin-transformer가 segmentation을 평가할 때 사용한 decoder로 해당 논문의 네트워크를 사용했다고 해서 알게 되었으며 앞으로 Segmentation 공부를 좀 해봐야겠다 싶어서 해당 논문을 읽게 되었습니다. (근데 읽다보니 해당 논문은 Segmentation이긴 한데 조금 결이 다른 것 같더군요.)
Introduction
결론부터 말하면 해당 논문은 단순히 Semantic Segmentation을 잘하는 방법론을 소개할게! 는 아닙니다. 오히려 기존의 segmentation task에서 더 추가적인? task를 제안합니다.
먼저 저자는 사람이 어떠한 영상 내에서 물체들을 인지할 때 단순히 그 공간이 어디이며 물체는 어디에 존재하는지만을 인지하는 것이 아니라고 합니다. 더 세부적으로는 그 물체의 재질은 어떠하고, 물체 내에서도 서로 다른 복합적인 부분부분 마다 어떠한 texture를 가지는지 다 인지할 수 있습니다. 한마디로 물체 자체만을 분석하는 것이 아닌, 물체 내부에 있는 세밀한 것들(texture, part, material) 등도 인지할 수 있다는 것이죠.
예를 들어봅시다. 그림1을 살펴보면 해당 영상이 찍힌 곳은 거실이라는 것을 알 수 있구요, 물체들 중에는 커피 테이블, 그림, 소파 등을 확인할 수 있네요. 더욱 세밀하게 확인해본다면 커피 테이블은 다리가 4개짜리 인 것을 확인할 수 있고 해당 테이블이 나무로 만들어져있다는 것을 알 수 있습니다.
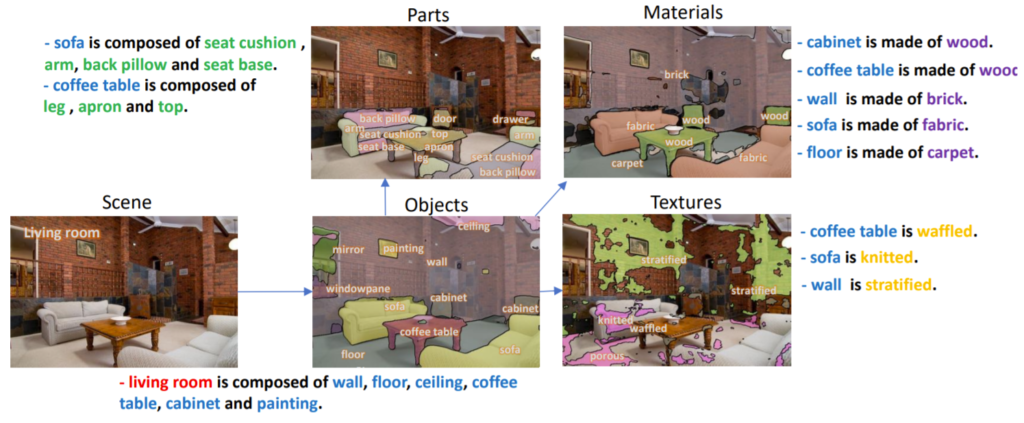
이처럼 사람은 한장의 영상을 통해 장소, 물체, 물체의 구성품(외형은 어떻고 재질은 어떠한지) 등을 한번에 알 수 있지만, 다양한 visual recognition task들은 이러한 활동들을 한번에 하지는 않은 체 구분해서 수행합니다. 예를 들어 해당 장소가 거실인지 아니면 야외인지를 찾는 scene recognition task, object가 어디에 놓여있는지를 pixel level로 예측하는 segmentation task, texture나 material이 무엇인지를 인지하는 task 등 각각을 구분두어서 연구하고 있다는 것이죠.
저자는 이러한 기존의 연구들을 두고 neural network가 인간의 시각 체계처럼 다양한 visual recognition task들을 동시에 수행을 못하는거야? 라는 의문을 품게 됩니다. 이러한 저자의 생각은 이 논문을 작성하게된 동기로 볼 수 있겠죠. 그래서 저자는 저자가 꿈꾸는? 동시에 여러가지를 인지하는 새로운 task Unified Perceptual Parsing(UPP) task를 소개합니다.
새로운 task를 제안하기 위해서는 보통 dataset도 같이 필요하겠죠. 저자는 기존의 각각 독립적으로 연구되던 분야들(Scene Recognition, Semantic Segmentation, Texture and Material Perception etc..)의 데이터셋을 새롭게 가공하여 하나의 통일된 데이터 셋을 제작합니다.
그리고 위에서 제안한 새로운 task UPP는 어찌보면 multi task이므로 이를 수행하기에 새로운 학습 framework 및 네트워크를 소개합니다. 자세한 내용은 밑에서 다시 설명하도록 할게요.
Defining Unified Perceptual Parsing
먼저 UPP를 수행하기 위한 dataset 가공 설명입니다. 서론 부분에서 계속 설명했다시피 저자는 새로운 task를 제안하는 것이고 이 때문에 저자가 하고자 하는 동시에 다양한 multi task를 수행하기 위한 데이터 셋은 존재하지 않습니다. 보다 자세히 설명하자면 영상 속 장소는 어디이며, 물체마다 semantic한 label도 있고 동시에 각 물체의 재질 및 텍스쳐에 대한 label을 하나의 영상에 모두 가지는 데이터 셋은 존재하지 않죠.
그래서 저자는 기존의 이미지 어노테이션을 가지고 있는 몇몇 데이터 셋을 합치는 작업을 먼저 진행했습니다. 처음 접하는 데이터 셋이 많아 데이터 가공 설명을 이해하는데 있어 한계가 있더군요. 간결하게 설명하는 점 양해바랍니다ㅎㅎ.
일단 저자는 Broadly and Densely Labeled Dataset(Broden)을 활용하였는데 해당 데이터 셋은 다양한 Segmentation 및 recognition dataset을 합쳐놓았다고 합니다. Broden dataset에 사용된 데이터 셋은 다음과 같습니다.
- ADE20K
- Pascal-Context
- Pascal-Part
- OpenSurfaces
- Describable Textures Dataset(DTD)
위에 데이터 셋들은 각각 scenes, objects, object parts, materials, textures 등 다양한 분야에서 널리 사용되는 데이터 셋들입니다. 여기서 object, object parts, material의 경우 pixel level로 annotation이 되어 있는 반면, scene과 texture의 경우 image level에서 annotation이 되어 있다고 합니다.
저자는 이러한 Broden dataset을 가공해서 사용하였는데 Broden dataset이 서로 다른 데이터 셋들을 섞어서 만들었다 보니 서로 다른 클래스의 샘플들이 균형이 맞지 않았기에 segmentation 학습을 하는데 있어 보다 적합하게끔 만들고자 하였습니다.
첫번째로는 서로 다른 데이터 셋의 유사한 항목들을 합치는 작업을 수행합니다. 예를 들어 ADE20K, Pascal-Part, Pascal-Context 내에 존재하는 object와 parts 항목들을 하나로 합치는 것이죠.
둘째로는 object 클래스 중에서 최소 50장 이상의 영상을 지니고 있으며 라벨링된 픽셀의 수가 최소 5만개 이상인 클래스들만을 남기고 그 외에는 제거하는 작업을 수행합니다. 아마 해당 작업을 통해 클래스 불균형이 발생하는 것을 해결하는 것 같네요.
세번째로는 세부 항목들을 상위 항목으로 묶는 작업을 수행합니다. 이게 무슨 말이냐면 openSurface 데이터 셋에서는 stone과 concrete라는 세부 항목들로 구성되어 있는데 이를 모두 stone이라고 명칭하는 것입니다. 또한 clear plastic과 opaque plastic 모두 plastic으로 묶어버리는 것이구요.
최종적으로 가공된 데이터 셋의 카테고리 및 클래스 등 각종 세부 정보들은 아래 그림과 표에서 확인할 수 있습니다.
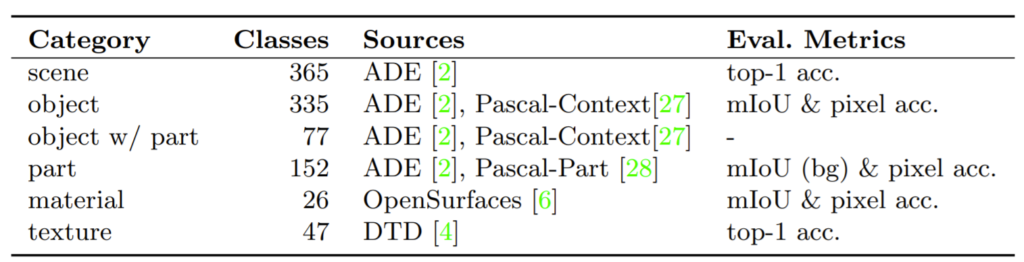
그림3은 가공된 데이터 셋을 정성적으로 보여주고 있습니다.

Designing Networks for Unified Perceptual Parsing
다음으로는 저자가 제안하는 네트워크에 대해서 알아봅시다. 저자가 제안하는 네트워크의 구조는 그림 4를 통해 확인할 수 있습니다.
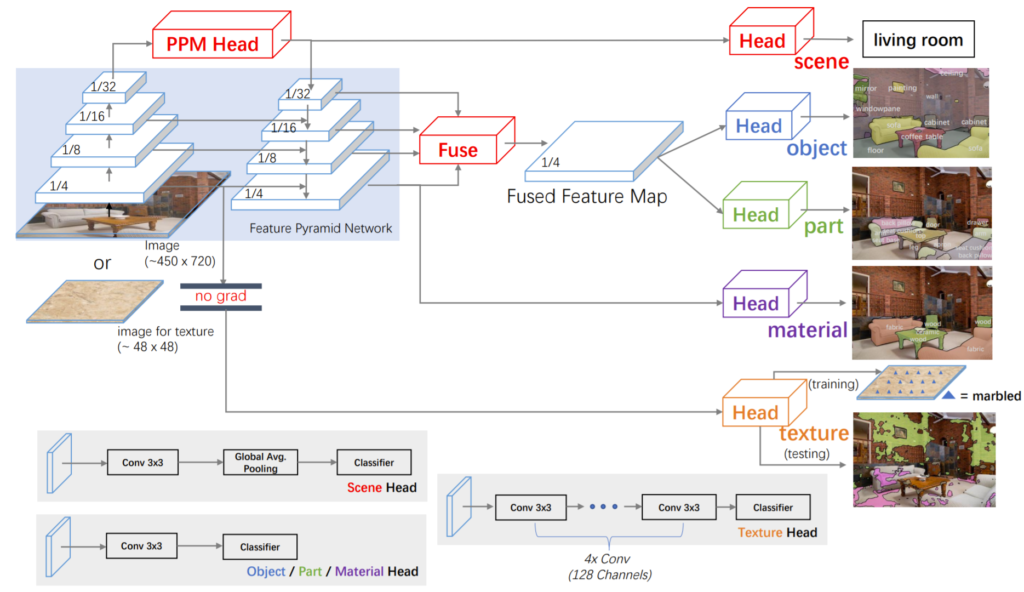
일단 전체적인 구조는 Feature Pyramid Network(FPN)으로 구성되어 있습니다. 그리고 맨 위에(top) feature map이 Pyramid Pooling Module을 통과한 후에 top-down으로 내려가게 됩니다. PPM의 경우 저자가 새로 제안한 모듈은 아니고 기존에 segmentation task에서 사용된 방법론이라고 합니다. 논문에서는 따로 구체적인 설명을 하지 않고 참조 걸었으니 알아서 보고 와라 라는 식으로 나와있네요;;
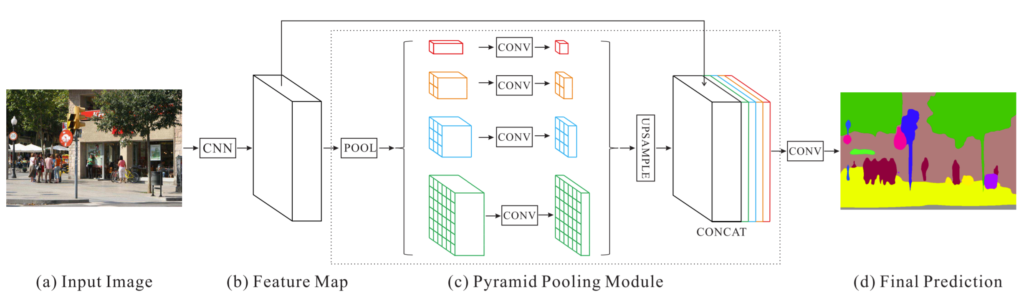
그래서 한번 찾아가서 살펴보니 그림5와 같은 구조로 이루어져있다고 합니다. 대충 해당 방식을 사용하게 된 이유에 대해서 살펴보면 CNN 네트워크가 보다 deep layer로 갈수록 receptive field가 넓어지는 것은 맞지만, 그럼에도 한계가 존재한다고 합니다.
그래서 보다 global한 정보를 주기 위해서 Global Average Pooling이라던지 등등을 사용하기도 했었지만, GAP의 경우 전체 해상도에 대해 압축해서 정보를 주다보니 복잡한 환경에서는 잘 동작하지 않았다고 합니다.(아마 단순히 ImageNet처럼 하나의 대상이 크게 있는 것이 아닌 세부적인 디테일이 필요한 복잡한 환경을 의미하는 것이겠죠.)
그래서 보다 세부적이면서 동시에 Global한 정보를 취득하고자 각 해상도별로 feature map을 다시 구한 후 이를 동일한 해상도로 upsampling하여 concatenation을 한다고 합니다. 아무튼 결과적으로 마지막 레이어의 receptive filed를 보다 확장시켜 global한 정보를 배우겠다가 해당 PPM의 취지인 듯 합니다.
자 그러면 다시 UPNet으로 돌아와서, 그림4에 Bottom-UP를 [C_{2}, C_{3}, C_{4}, C_{5}]라고 명칭할 것이며, Top-Down에서의 feature map을 각 단계별로 [P_{2}, P_{3}, P_{4}, P_{5}]라고 정의합니다. 여기서 눈여겨보실점이 C_{2}, P_{2} 가 입력 해상도의 0.5 스케일이 아닌, 0.25 스케일이라는 점입니다.
일반적으로 CNN 네트워크들은 2배씩 Down sampling하는데 해당 논문은 FPN기반이다보니 첫 단계의 feature map들이 4배로 다운 샘플링 되었더군요. 그래서 아마 이름도 C_{1}이 아닌 C_{2}부터 시작하는게 아닌가 싶습니다. (그리고 이러한 원인이 Swin-Transformer에서 UPNet을 사용한 이유가 아닌가 싶네요.)
자 그러면 이제 네트워크가 어떤식으로 Multi task를 수행하는지 보도록 합시다. 먼저 가장 꼭대기에 해당하는 layer P_{5}만을 이용해서 Scene label을 예측합니다. 이는 Scene label의 경우 영상 전체에 대한 요소들을 보고 해당 장소가 어디인지 예측하는 Image Classification과 유사하기 때문에 가장 Abstract 레벨의 feature map만을 사용한게 아닌가 싶습니다.
다음으로 Object label과 Object part label 경우 FPN의 모든 Feature map을 다 사용합니다. 이는 저자가 제일 아래 layer인 P_{2}만 사용했을 때보다 전체를 다 사용하는 것이 좋다는 것을 경험적으로 판단하였다고 합니다. 아무래도 다양한 스케일에 강인하다보니 그런게 아닐까 싶네요.
Texture label의 경우에는 학습할 때 다른 task의 이미지들과 함께 학습하게 될 경우 학습을 방해하는 현상을 보인다고 합니다. 이게 무슨 말이냐면 Texture label도 Scene label과 동일하게 pixel level이 아닌 image level의 annotation을 가집니다.
그나마 Scene recognition의 경우는 가장 꼭대기인 Top layer만을 이용해 예측하면 되니 아래 bottom쪽 layer들에는 큰 영향을 주지 않았지만, Texture label의 경우 아래 P_{2}를 이용해 예측을 하려다보니 다른 테스크를 예측하는데 있어 학습에 큰 영향을 준다고 합니다.
그러면 Scene recognition처럼 top layer에서 예측하면 안되나? 싶겠지만 저자는 texture label을 픽셀 레벨에서 예측하고 싶었기 때문에 반드시? P_{2}를 사용해야하는 것이죠. 그래서 저자는 먼저 Scene, object, part 등 다양한 task에 대해서 먼저 네트워크를 학습시켜놓고, 그 뒤에 네트워크를 freeze 시킨 뒤 texture만을 예측하는 head layer만 학습시키는 방식을 사용했다고 합니다.
이렇게 설계한 이유는 먼저 texture가 가장 낮은 단계의 시각적 속성이며 굳이 상위 레벨의 정보들이 필요 없었다고 합니다. 또한 다른 테스크와 동시에 학습할 때 학습에 방해가 된다는 것도 이유 중 하나였으며 마지막으로 texture prediction의 경우 receptive field가 더 작을수록 다양한 영역에서 픽셀레벨로 prediction을 수행할 수 있다고 생각했기 때문입니다.
Experiments
다음은 실험 내용입니다. 일단 논문에서 제안하는 네트워크 구조를 다른 방법론들과 비교하였을 때 더 좋다라는 것을 보여주기에는 사실 어렵습니다. 왜냐하면 저자는 이전에는 없던 완전히 새로운 task를 제안하였기 때문이죠.
그래서 다른 방법론들과 비교하였을 때 더 좋다는 것을 보여주고자 ADE20K dataset에서 semantic segmentation 성능을 비교하였습니다. 이것저것 다양하게 예측한다 하더라도 결국 semantic segmentation이 주 task이긴 하니깐요.
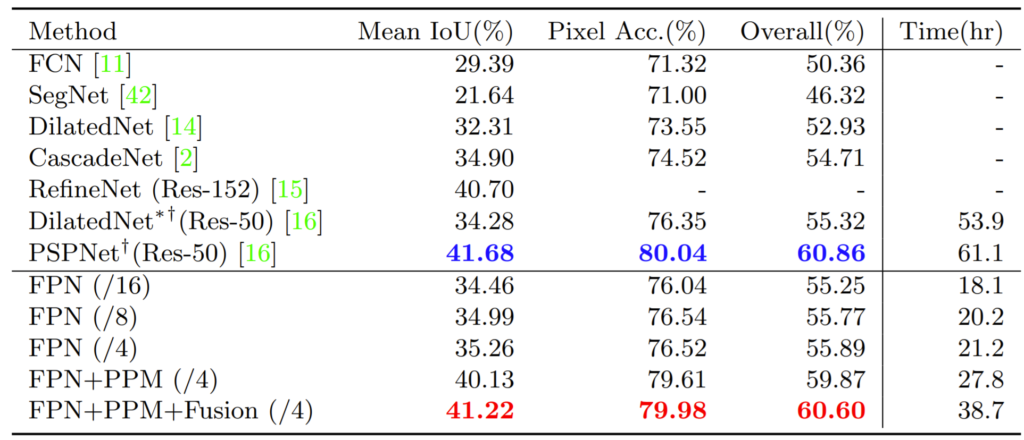
결과는 위의 테이블과 같습니다. 보시면 먼저 FPN이 가장 베이스라인으로 볼 수 있습니다. FPN 뒤에 /16, /8, /4에 대해서는 논문에서 따로 설명을 안해서 정확히 무엇인지는 모르겠으나 추측해보자면 Top-down에서 feature map을 합치는 과정 중 어디까지 합치는지에 따른 결과인 것 같습니다.
예를 들어 /16의 경우 입력 해상도보다 16배 더 작은 feature map까지만을 사용해 concat을 하는 것이고, /4이면 모든 feature map을 사용한다는 뜻이겠죠.(정확하지는 않습니다만 정확도 향상과 추가로 시간이 증가하는ㄱ ㅓㅅ을 보았을 때 그럴 것 같습니다.)
아무튼 저자는 자신들의 네트워크 설계가 비록 PSPNet보다는 성능이 조금 미치지 못하더라도 시간적인 측면을 보았을 때 훨씬 빠르다고 얘기합니다. 동일한 PPM을 사용했지만 PSP Net의 경우 PPM 모듈에 들어가는 feature map의 해상도가 큰 반면, UPnet의 경우 가장 높은 레벨의 feature를 PPM의 입력으로 사용한 것이다보니 훨씬 더 빠르게 동작하겠지요.
다음은 저자가 그토록 하고싶던? Unified Perceptual Parsing task의 성능입니다.
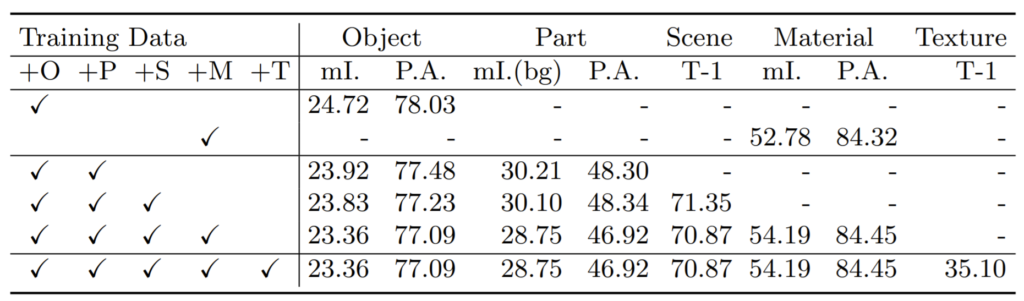
multi task의 수를 늘릴수록 각 분야의 성능들이 조금씩 떨어지는군요. 아마 약간의 성능 향상을 기대했지만 아쉽게도 학습해야할 class가 더 늘어났기에 성능이 떨어진게 아닌가 싶네요.
다음으로 정성적 결과에 대해서 살펴봅시다.

결론
이런류의 논문은 처음봐서 새롭기도 하고 조금은 막막하기도 했었네요. 하지만 문제를 정의해서 새로운 task를 직접 만들고 이를 수행하는 과정이 쉽지만은 않았을 터이고 실제로도 제가 리뷰에는 다 담지 못했지만 논문에서 꼼꼼하게 디테일들을 작성하였기에 ECCV에 기재된게 아닌가 싶습니다.
덤으로 FPN에 대해서 이름과 구조에 대해서만 간략하게 들어보고 어떻게 동작하는지에 대해서 구체적으로 알지는 못했는데, 이제 조금 감을 잡은 것 같네요.
데이터셋에 대해 질문이 있습니다. 그러면 데이터셋을 가공하여 한 이미지에 대해 scenes, objects, object parts, materials, textures 에 대한 모든 어노테이션이 있는 데이터셋이 되는 건가요? 그리고 한번의 학습으로 이 정보 들을 모두 예측할 수 있는 모델이 만들어지는 것 맞나요?
음 매우 좋은 질문입니다.
제가 리뷰 내용에 넣는 것을 깜빡했는데 가공된 데이터 셋도 영상 한장에 모든 task annotation이 되어있는 것은 아니구요 annotation이 존재하는 class만을 학습으로 사용합니다.
예를 들어서 데이터로더에 받아온 영상이 여러 데이터 셋 중 ADE20K 데이터셋이라면, object와 part에 대한 annotation만 존재할테니 해당 부분만 학습하고 그 외에 task는 GT가 없으니 학습 반영을 안하는 것이죠. 그 다음 iteration에서 만약 해당 영상에 scene label만 있다면 scene label에 대해서만 학습을 하는 것이구요.
학습 또한 texture를 제외하고는 모두 한번에 학습되는 것이 맞습니다.