이번 논문은 중기청 과제 중 사용하고 있던 식물 마스크 기반 CopyPaste의 타당성을 찾다가 찾은 논문입니다. 해당 논문은 우리가 당연하게 생각하게 사용하는 Pre-training(대표적으로 ImageNet)이 과연 필요한가 의문을 가지고 시작하는 논문입니다.
Intro
Pre-training은 물체 검출, 영상 분할 등 컴퓨터 비전 분야에서는 빠지지 않고 필수적으로 사용되는 기법에 해당됩니다. 특히 특징 추출기로 backbone 모델을 사용하는 경우에는 흔히 ImageNet에서 분류기로 학습된 모델을 사용합니다. 근데 흥미롭게도 He.et.al, “Rethinking imagenet pre-training”, ICCV 2019 에서 Object Detection과 Instacne Segmentation에서 ImageNet으로 Pre-training된 값으로 초기화를 시킨 모델보다 Random initialization한 모델에서 제한적인 영향을 미친다는 연구 결과(하단의 그림과 표 참고)를 발표합니다.
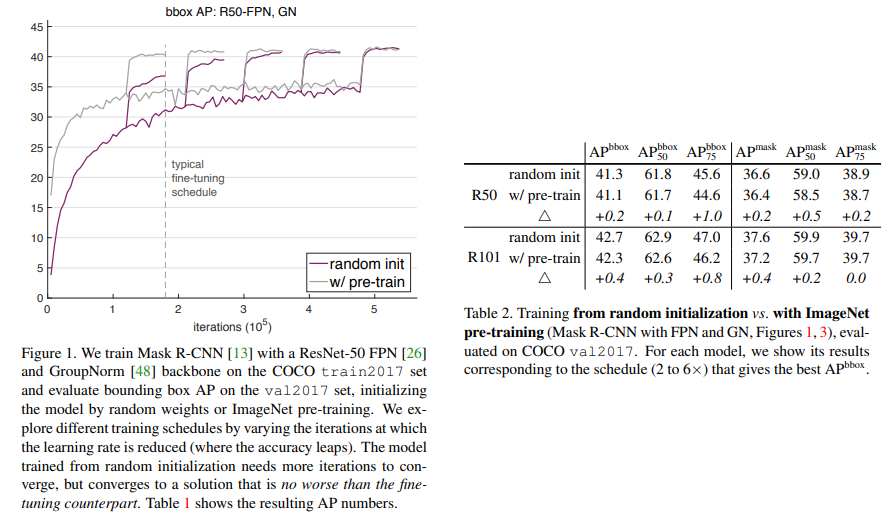
저자는 이에 영감을 받아 요즘에도 핫한 Self-training으로 확장하여 실험을 진행합니다. 저자는 Object Detection과 Segmentation에 집중하여 분석하였으며, COCO 이외에도 상대적으로 작은 데이터 셋인 PASCAL에서 실험을 진행하였습니다.
++ 여기서 이야기하는 Self-training은 Pseudo-label에 해당합니다.
Method
저자는 세가지 경우의 조합으로 실험을 진행하였습니다.
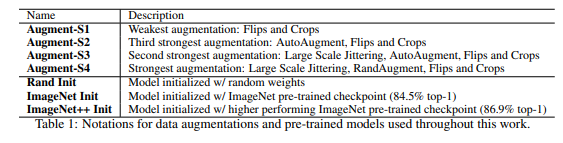
Data Augmentation. Table 1과 같이 4가지의 Data augmentation으로 나눠 실험을 진행하였습니다. 숫자가 점점 커질 수록 강한 변화가 일어납니다.
(AutoAugment는 RNN의 보상 정책을 이용하여 적절한 tramfomer를 채택하는 기법. RandAugment는 논문 기준 14개의 transform을 랜덤하게 적용하는 데이터 증강 기법. Lagre Scale Jittering은 random resize(0.1, 2.0)와 ramdom crop을 동일한 해상도에서 물체를 가까이 보거나 멀리 보는 효과를 모사한 데이터 증강 기법)
Pre-training. Table 1과 같이 3가지의 Initialization으로 나누어 실험을 설계합니다. 먼저 Rand Init인 경우, 별도의 pre-trained weight에 대한 초기화 없이 진행하는 예시입니다. Pre-trained에 해당하는 ImageNet Init와 ImageNet++ Init은 이름 그대로 ImageNet에서 사전학습된 모델의 weight로 초기화합니다. 다른 점은 ImageNet++ Init인 경우, Noise student 방식으로 unlabeled 데이터 셋인 JFT-300M을 사용하여 self-traning한 Model initialization에 해당합니다.
Self-trainig. Noise Student에 영감을 얻어 3가지 단계로 구성됩니다. 먼저 Teache model은 레이블이 지정된 데이터(e.g. COCO)에서 학습을 진행합니다. 그런 다음 Teacher model은 레이블이 지정되지 않은 데이터 셋(e.g. ImageNet)에서 Pseudo label을 생성합니다. 마지막으로 GT와 Pseudo label에 대한 손실 함수를 공동으로 최적화하며 훈련합니다.
++ Noise student와 차이점을 이전 연구는 분류 문제에 집중하였고, 저자는 물체 검출과 영상 분할에 집중하였으며, 사전 학습과 Self-trainig의 관계에 대해 연구하지 않았다고 합니다.
Experiment
The effects of augmentation and labeled dataset size on pre-training
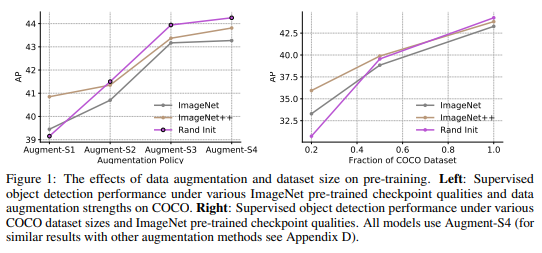
저자는 Fig 1 왼쪽에서 보이는 바와 같이 물체 검출의 Data augmentation 영향을 분석합니다. 약한 데이터 증가에서는 사전 학습된 모델에서 큰 효과를 보여주지만, 강한 데이터 증강을 사용하면서 모델 초기화 기법에서 성능 향상을 보여주고 있으며, Rand Init에서 가장 높은 성능(1.0 AP, 0.4 AP) 보여줍니다.
Fig 1의 오른쪽은 레이블이 존재하는 데이터 셋의 크기를 변경했을 때 모델 초기화의 영향을 분석합니다. 최종적으로 Rand Init에서 더 좋은 성능을 보여주고 있으며, 흥미로운 점은 데이터 셋의 비율 가장 적은 20%에서는 사전 학습된 모델에서 가장 좋은 성능을 보여주고 있다는 점입니다.
The effects of augmentation and labeled dataset size on self-training

해당 실험에서는 Table 2와 같이 데이터 증강 강도를 변화시키며 물체 검출에서의 성능을 분석합니다. 지도 학습(Rand init)와 사전학습, Self-training(Rand Init)에서 비교 실험을 진행합니다. 해당 실험에서는 Self-training이 데이터 증강 세기에 상관없이 높은 성능을 달성한 것을 볼 수 있습니다.
Self-training works across dataset sizes and is additive to pre-training.
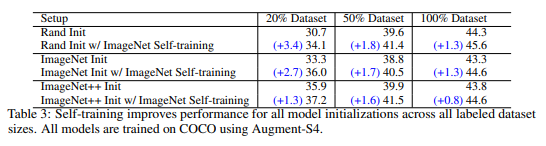
다음 실험으로 위의 실험과 동일한 경우에서 COCO 데이터 셋의 크기를 변경하며 self-training의 성능을 분석합니다. Table 3과 같이 Self-training에서는 데이터 셋의 크기에 상관없이 모든 모델이 크게 향상되는 반면에 사전 훈련은 오히려 성능이 떨어지는 것을 볼 수 있습니다.
Self-supervised pre-training also hurts when self-training helps in high data/strong
augmentation regimes
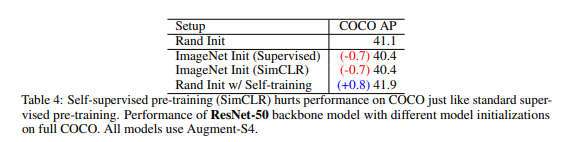
해당 실험에서는 지도 학습과 Self-Supervised learning 중 SimCLR[a]과 비교 실험을 진행합니다. 실험은 가장 좋은 성능을 낸 COCO Dataset에서 Augmentation-S4에서 진행이 됩니다. self-trainig에 비해 다른 두 방법론은 성능이 저하된 모습을 보여주지만 오히려 0.8 AP 성능 개선이 된 것을 통해 보다 효과적인 방법론이른 것을 증명합니다.
[a] Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020, November). A simple framework for contrastive learning of visual representations. In International conference on machine learning (pp. 1597-1607). PMLR.
PASCAL VOC Semantic Segmentation.
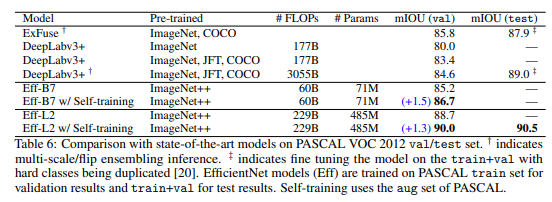
Semantic Segmentation에서도 개선된 성능을 보여주고 있으며 ImageNet에서 Psuedo label을 만들어 학습을 진행하였으며, PASCAL VOC 2012 중 aug set에서 성능 저하되는 현상을 발견하여 확인 결과, Fig 4와 같이 부정확한 라벨이 주어졌다고 합니다. 이에 라벨을 개선하기 위해서 Pseudo label을 이용하여 증강하였다고 합니다.



Table 8에서 보이는 바와 같이 train+aug인 경우 상단의 fig 4와 같이 부정확한 라벨 값을 이용한 학습 결과입니다. 하지만 aug w/ Self-trainig을 aug set에 대한 pusedo label에 해당하며 이전 경향성과 동일하게 데이터 증강이 강도에 따른 성능 변화를 보여줍니다.
=========================================================
흥미로운 실험 결과가 많지만 통찰을 주는 분석은 없어 아쉬웠습니다. 뭔가 읽는 내내 ‘우리도 왜 그런지는 잘모르겠지만 실험이 결과를 말해주고 있어, 이거 봐 모잘라? appendix에 있으니 찾아 읽어봐’와 같은 느낌이 들어습니다. 이런 부분에서 아쉬운 점이 있었습니다.
또한 COCO인 경우 120k로 20%여도 24K로 획득하기 어려운 데이터 양이기도 합니다. 진행 중인 과제에서는 아직까진 사전학습을 이용해도 괜찮아 보이며, self-training 기법을 고려해도 좋을 것 같습니다.