해당 리뷰는 중기청 관련 논문을 작성 중 현재 푸는 방법과 매우 유사한 방법을 발견하여 정보 기록 및 공유를 위하여 작성하였습니다.
Intro
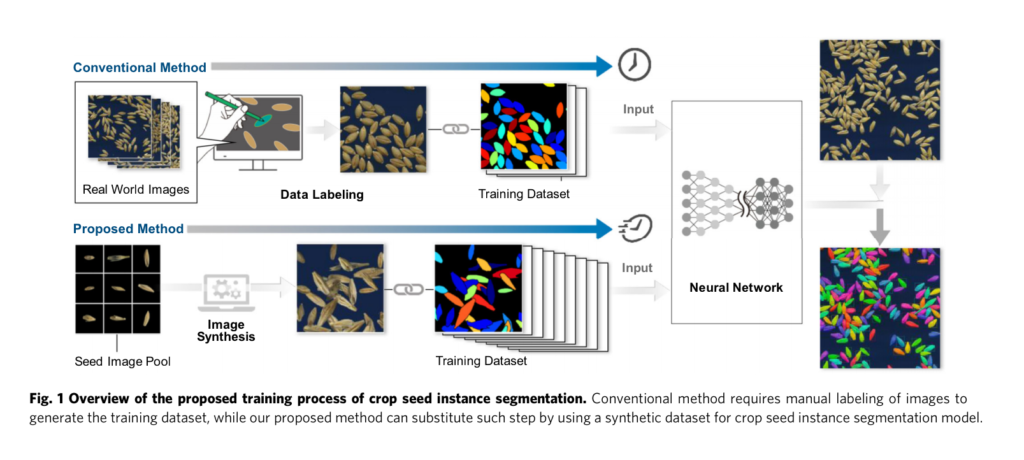
해당 방법론은 이전에 말씀드린 객체를 붙여 instance segmentation의 성능을 올린 Simple CopyPaste 방법론과 매우 유사합니다. 몇가지 다른 점은 다음과 같습니다.
- 씨앗에 한정된 데이터
- 경계면에 대한 Gaussian blur
- 이전에 존재한 장면에 추가하는 것이 아닌 아무것도 없는 배경에서 가상의 데이터를 생성 (저자는 해당 방법을 sim2real 혹은 Domain Randomization이라고 주장)
저자는 위와 같은 방법으로 추가적인 사람의 노동 없이 데이터를 생성하였으며, 해당 데이터를 기반으로 instance segmentation 방법론 중 Mask R-CNN을 학습하여 real dataset에서 효과를 보여줍니다. 이를 통해 씨앗의 형태를 손쉽게 분석할 수 있으므로써, 씨앗 유전학 분야의 발전 가능성을 시사합니다.
Method
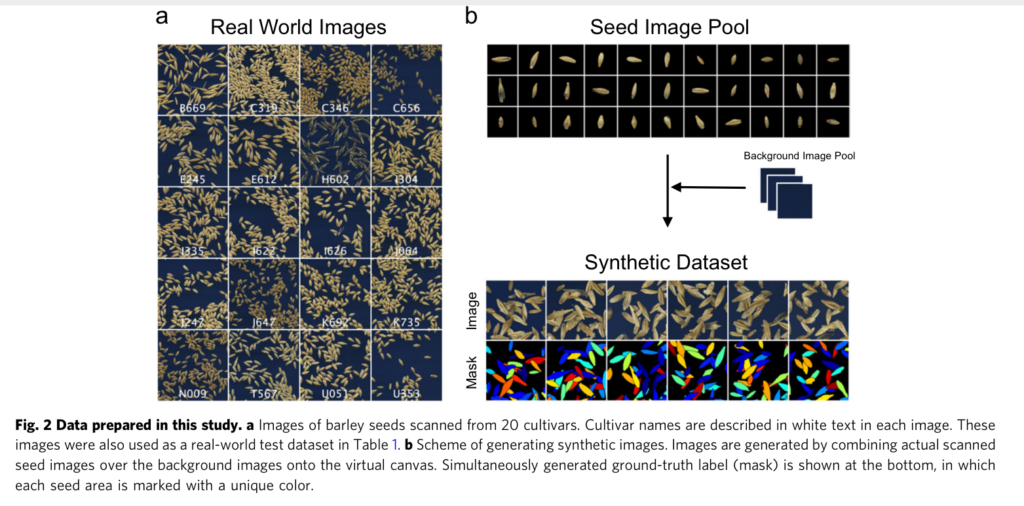
Synthentic image generation
데이터를 증강하는 방법은 매우 간단합니다. Fig 2 b와 같이 품종당 단일 씨앗 영상(총 400개, 20개의 품종당 20개의 이미지)를 촬영 후, 수동으로 주석을 생성합니다. 그 후, 1024×1024의 검은 배경(Background Image Pool, RGB(0, 0, 0))을 생성합니다. 검은 배경에 주석 처리가 된 단일 씨앗 영상을 무작위로 붙입니다. 붙여진 씨앗과 배경의 인공적인 형태를 줄이기 위해 경계면에 가우시안 블러를 진행합니다. 또한 랜덤하게 회전을 부여하여 형태의 다양성을 가지도록 합니다. 추가로 기존에 붙여진 씨앗과 IoU가 0.25를 초과할 경우, 새롭게 붙여질 영상을 취소하고 다른 위치에 붙여 occlusion을 제거합니다. 개별적으로 씨앗 영상이 붙여짐과 동시에 마스크를 생성합니다. 완성된 가상의 영상을 4등분하여 잘려진 씨앗 영상을 모사할 수 있도록합니다. 최대 70개의 씨앗을 붙이도록 설정하였으며, 총 1200개의 가상의 영상을 생성하였다고 합니다.
Model train & test
사용된 모델은 ResNet101을 feature extractor로 가진 Mask R-CNN을 이용합니다. Mask R-CNN은 COCO dataset을 이용하여 사전 학습된 모델을 사용합니다. 사용된 모델 파라미터는 아래와 같습니다.
- 40 epoch
- learning rate 0.001
- Batch size 2
- SGD
생성한 1200개의 가상의 데이터 셋은 학습에 989장, validation 11, test 200를 구성하였다고 합니다. 학습 시, 789×789 영상 크기를 변경하여 사용했다고 합니다.
테스트에는 20장의 fig 2 a와 같은 실제 영상(2000×2000)을 사용하여 평가합니다.
Experiment
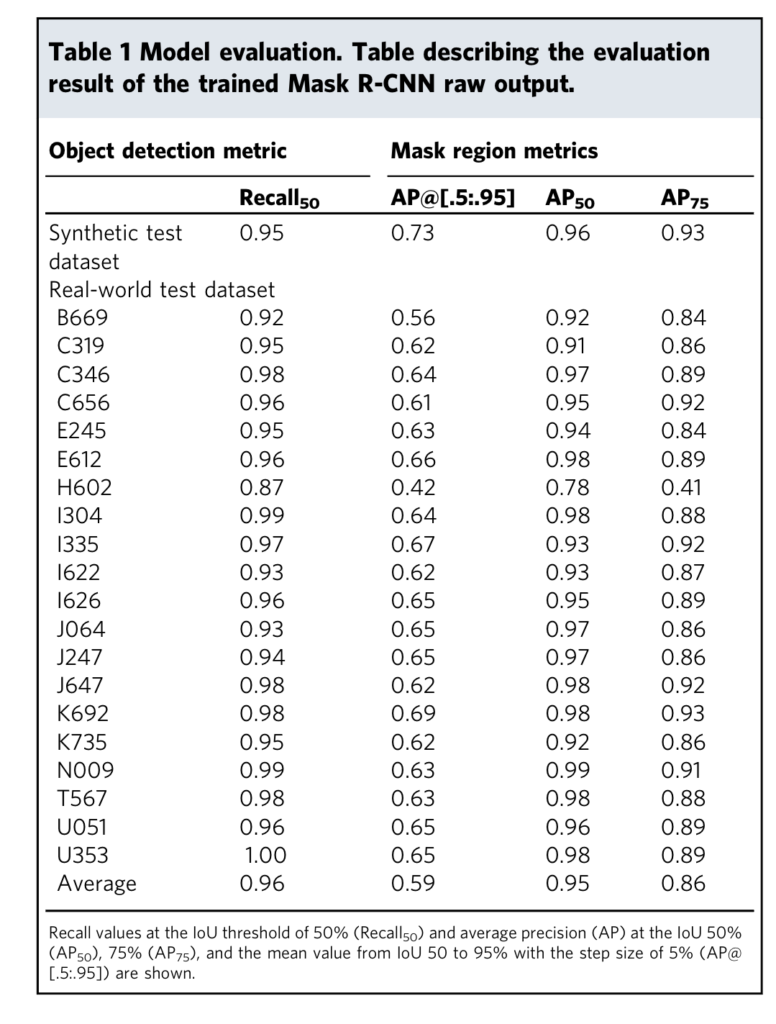
평가 메트릭으로는 COCO에서 사용되는 평가 방법을 사용하였습니다. 위의 표는 20개 품종의 씨앗 영상에서의 평가 결과에 해당합니다. 저자는 AP50 0.95, Recall 0.96을 달성함으로써 가상의 데이터 셋이 씨앗의 회전과 품종에 대해 강인성을 보장한다고 합니다. 또한 Real dataset으로 학습 하는 것 보다 낫다고 암시한다고 합니다. 특히 물리적으로 서로 접촉하고 밀집된 경우에 극대화되는 형상을 보여준다고 합니다. (해당 내용은 Supplementary에서 확인이 가능하다고 하여 확인했지만… 정성적인 결과만 있네요.. 학습한 데이터도 평가 데이터와는 다른 형태를 가집니다. 컴퓨터 비전이 아닌 타 분야라서 결과에만 집중하셔서 그런 것 같습니다.)
===========================================================
확실히 컴퓨터 비전 분야가 아닌 타 분야에서 컴퓨터 비전을 활용한 연구라는 측면이 커서인지… 너그럽게 넘어간 부분들이 많아 보였습니다. 특히 real data를 보시면 작은 크기의 씨앗이 밀집된 경우가 많습니다. 이러한 경우, 예측된 한 객체가 밀집된 씨앗들을 적당히 포용한 경우에도 IoU가 0.5가 넘는 경우가 발생할 수 있습니다. 그렇기에 mAP(여기서는 AP@[.5:.95])를 보고 평가하는 것이 타당해보입니다. 가장 아쉬운 부분은 실제 데이터 셋으로 학습한 경우 입니다.
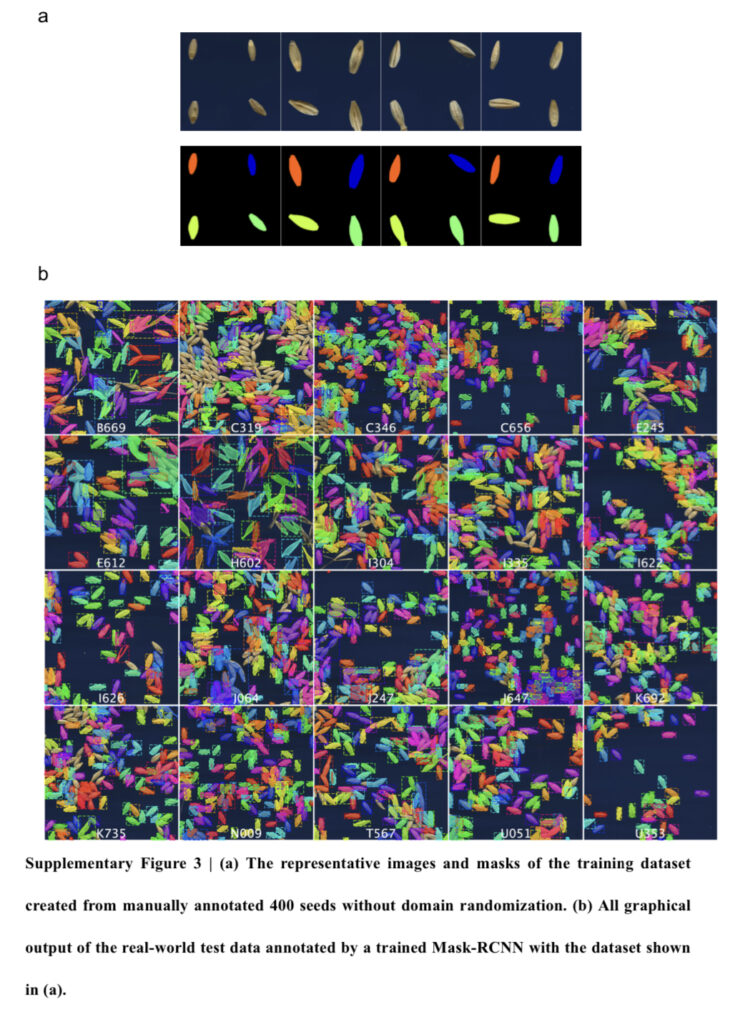
위의 영상이 실제 데이터 셋에서 평가한 결과 입니다. 학습에 사용된 데이터는 400장으로 위의 그림 a와 동일한 형태라고 합니다. 테스트 영상과는 매우 다른 양상을 가진 학습 데이터를 이용한 점과 가상의 데이터 셋은 989장을 학습 데이터로 사용한 점에서 매우 아쉬운 비교라고 생각합니다.
하지만 이는 다른 분야를 접목시켜 생물학 분야에서 가지고 있는 문제를 해결 방안을 제시했다는 점에서 기여를 인정 받았다고 생각합니다. 사회에 기여하기 위한 방법으로 한쪽에 편견된 관점을 가지지 않고 폭 넓은 시야를 가지는 것도 중요하다는 것을 보여주는 논문이라고 생각합니다.