안녕하세요 이번에 제가 다룰 주제는 Object Detection에서 아주아주 유명한 YOLO시리즈 중에서도 1~3에 대해서 다루겠습니다. 내용이 좀 많을 수 있는데 핵심적인 부분만 요약해서 소개하는식으로 리뷰를 해보겠습니다.
Object Detection 개요
Object Detection은 상당히 오래된 연구분야입니다. 딥러닝 이전에도 기계학습기반 방법을 이용하여 물체를 검출하는 방법론들이 있었고, 딥러닝 이후에 엄청난 발전을 이루었습니다. 그 발전에 대해서 어느정도 다들 알고 계시겠지만, 리마인드하는 의미에서 YOLO를 중심으로 설명드리겠습니다.
YOLO V1은 대표적인 Single-stage 방법론으로 SSD보다 약 6개월 일찍 나왔습니다. 당시에 R-CNN 계열이 나와서 좋은 성능을 보였지만, 아무래도 속도면에서 real-time으로 inference하기에 어려웠는데 이러한 단점을 극복하기위해 속도가빠른 Detector에 대한 연구가 많이 이루어졌고, 그러한 배경에서 나온게 바로 YOLO V1입니다.
YOLO V1은 비록 성능이 Two-stage 기반 방법론 대비 그리 좋지 못했지만, 속도가 엄청빨라서 Object Detection도 실시간으로 연산처리 할 수 있게 하였다는데 의의가 있습니다.
이후 속도와 성능을 개선하여 YOLO V2가 출시하였고, RetinaNet에서 사용하는 피라미드 네트워크 구조를 적극적으로 채택하여 YOLOv3가 세상에 알려졌습니다.
오늘 소개드릴 방법론들은 이렇게 욜로시리즈 1~3이며, 해당 시리즈를 마지막으로 원저자는 더이상 컴퓨터비전에 대해 연구를 진행하고있지 않습니다. 지금 세상에 알려진 욜로V4~5같은 시리즈들은 전부 원저자가아닌 다른 저자들에 의해서 연구개발이 된 것입니다.
일단 개인적으로 느끼는게 욜로를 이해하려면 V1부터 차근차근 이해하는게 중요하다고 생각합니다. 그 이유는 V1에서 사용되는게 V2에서도 사용되고 V2에서 사용되는게 V3에서도 사용되기 때문입니다. 사실 V3가 현재 가장 널리 알려진 욜로의 형태이며, 가장 혁신적인 아키텍쳐라고 생각이 되는데요. V3 논문을 읽어보시면 아시겠지만, 해당 논문만 읽어서는 YOLOv3를 이해할 수 없습니다. 때문에 V1과 V2에 대한 배경적인 내용과 최종적으로 V3까지 리뷰를 해보겠습니다.
1. YOLO V1

사실 아키텍쳐는 위와같으며 크게 어려울게 없습니다. 원본이미지를 다운샘플링하며 CNN레이어들을 통과시키고, 마지막에 FC레이어들을 통과시킨다음 다시 Reshape하여 7*7*channel 형태로 바꿉니다. 그리고 channel에는 bbox와 class score에 대한 정보가 담기게 됩니다. 예를들어 보행자인식 데이터셋이며, 클래스는 보행자 한개뿐이라고 해봅시다.
그럼 처음에 들어간 이미지는 다운샘플링되며 FC레이어를 통과하고, reshape되어 최종적으로 7*7*11형태를 갖게됩니다. 이때, 7*7은 위의 그림과 같이 grid를 의미하며, channel에는 [x1, y1, w1, h1, o1, x2, y2, w2, h2, o2, class score] 과 같은 정보가 담기게 됩니다. 이게 의미하는게 무엇이냐면, 각 그리드마다 2개의 bbox를 사용을 할 것이고, 그 bbox마다 오브젝트가 있는지 없는지에 대한 score가 바로 o 입니다. 그리고 class score에는 보행자 1개에 대한 확률값만이 나오게됩니다. 만약 class가 여러개인 경우에는 해당 값이 여러개 나오겠죠? 이때 주의하셔야 할것이, 다른 detector들과는 다르게 background에 대한 score를 추가하지 않습니다. 그 이유는 bbox마다 object이냐 아니냐에 대한 score가 들어가기 때문입니다.
이렇게 그리드마다 2개씩 bbox를 예측을 하였습니다. 근데 그 2개를 전부 사용하지는 않습니다. 대신에 2개중에서 GT와의 IoU가 더 높은 bbox를 “responsible”이라 정합니다. 그리고 responsible한 bbox와 non-responsible한 bbox를 loss텀을 계산할때 반영합니다. 이후 남은 98개의 bbox는 nms에서 다시한번 refine이 됩니다.

Loss는 위와같이 구성되며 해당 loss에 대한 이해는 욜로시리즈에서 전반적으로 사용하기 때문에 매우 중요합니다. 먼저 Localization loss를 보면 x,y에 대한 loss와 w,h에 대한 loss로 나뉘어져있습니다. 람다는 scale factor이며, 주로 5정도를 사용합니다. 그리고 시그마가 두개오게된 이유는 S라는 grid에서 bbox의 개수만큼 loss를 계산한다는 의미입니다. YOLO V1에서는 BBOX가 그리드마다 2개이므로 2개의 값에 대한 loss를 합해줍니다. 단순 차이의 제곱을 더한 것을 loss로 사용하며, 이때 obj인지 아닌지에 대한 confidence score를 곱해서 object가 아닌 background에 해당하는 경우에는 loss 식 계산에 패널티를 받습니다.
xy loss와는 다르게 wh loss에서는 제곱근을 씌워서 loss를 계산합니다. 이는 큰 bbox와 작은 bbox가 loss에 영향을 미치는 정도의 차이를 줄이기 위함입니다. bbox에 대한 정보들은 정규화되어서 들어가며, 그에 추가적으로 wh에 제곱근을 씌움으로써 스케일에 따라 loss에 영향을 미치는 차이를 최소화 시켰습니다.
Confidence loss는 binary classification이라고 생각하시면되며, object인지 아닌지에대한 confidence score를 계산합니다. 이때, 특이한점은 위에서 설명드렸듯이 2개의 bbox중에서 IoU기준으로 GT와 오버랩이 더 많이되는 bbox는 “responsible”, 나머진 non-responsible로 설정하였는데, non-responsible bbox도 Classification Loss 연산에서는 활용하였다는 점 입니다.
Classification loss에서는 각각 grid를 돌며 class의 개수만큼 loss를 계산을하여 합하는데요. object가 아닌경우에는 계산에서 제외하는 테크닉은 위에서 사용한 것과 동일합니다. class에 대한 score는 일반적인 softmax를 사용합니다.
2. YOLO V2
욜로 V2는 욜로 V1과 매우 흡사하지만 주요 변화들이 있습니다.
- 먼저, V1에서는 피쳐를 추출하는 백본을 Inception을 변형하여 사용하였다면, V2에서는 자체 개발한 DarkNet 19를 사용하였습니다. 사실상 ResNet과 비슷한거 같습니다.
- 그리고 V1에는 grid당 2개의 bbox를 사용하였으나, V2에서는 5개의 앵커박스를 사용하였고, 해당 앵커박스의 스케일과 ratio를 K-means Clustering을 사용하여 결정합니다. GT bbox의 width와 height를 xy평면에 뿌린후에 5개의 군집의 중심을 구합니다 그리고 해당 값을 anchor박스의 w, h로 사용합니다.
- FC레이어대신 Fully-convolution 형태를 취하였으며, 예측한 bounding box의 x, y 좌표가 중심 cell내에서 벗어나지 않도록 0~1로 바운딩시키는 Activation함수를 이용한 Direct Location Prediction도 사용하였습니다.
- 이 밖에도 인풋이미지의 해상도, grid를 나누는게 7*7에서 13*13으로 변화 등 사소한 변화들도 있습니다. 그러나 Loss함수등 주요한 개념은 동일하게 가지고 가게됩니다.
결과론적으로 성능과 속도 모두 향상시켰으며, 많은 발전을 이루어내게 됩니다. 뭔가 욜로시리즈는 느끼는게 좋다고하는 방법론들은 전부다 때려박아서 성능을 향상시키는 그런 엔지니어링 기법들이 많이 사용되는거 같습니다. 사실 V3에서도 마찬가지이구요.
위에서 설명한 1~4번 중에서 3번이 좀 이해하기 힘들거라고 생각되어서 논문에 있는 그림을 가지고 왔습니다.

위의 그림은 각각 의 grid Cell에 해당하며, bbox는 x,y,w,h 포맷으로 나타냈으며, p는 앵커박스를 의미합니다. 먼저 C좌표계로 원하는 grid셀의 왼쪽위 기준점을 구합니다. 그리고 해당 기준점에서 bbox 까지의 offset을 의미하는 t좌표계를 더해서 bbox 좌표를 구해줍니다. 이때, t좌표에 시그모이드를 씌워서 0과 1 사이로 바운딩 시킵니다. 즉, 해당 수식이 의미하는바는 원하는 grid cell이 있으면 해당 grid cell 내에서만 bbox의 centre지점이 존재하도록 constraint를 거는 것 입니다. 이후 앵커박스의 w, h 에 t좌표계에서의 w,h값이 곱해져서 최종적인 bbox를 예측하게됩니다. 글로 설명하는게 쉽지는 않은거 같은데 세미나때 좀 더 자세히 설명해보겠습니다.
3. YOLO V3
욜로 V1, V2를 어려움없이 이해하셨으면 V3는 좀 더 쉽게 받아드릴 수 있습니다.
먼저 차이점을 살펴봅시다
V2에 비해서 아래와 같은 내용들이 바뀌었습니다.
- 백본 네트워크 DarkNet 19 -> DarkNet 53
- 앵커박스 스케일3개 크기 3개의 조합으로 총 9개 사용 (k-means clustering은 그대로 사용)
- 13*13, 26*26, 52*52로 피쳐맵 총 3개 사용
- FPN 네트워크 채용 (욜로 v3가 나올당시 RetinaNet이 FPN을 사용하여 좋은 성능을 내었었음.)
- Softmax 대신 Logistic regression을 여러번 사용
사실상 가장큰 핵심적인 변화는 FPN구조를 사용한 것 입니다. 따라서 그 위주로 설명하겠습니다.
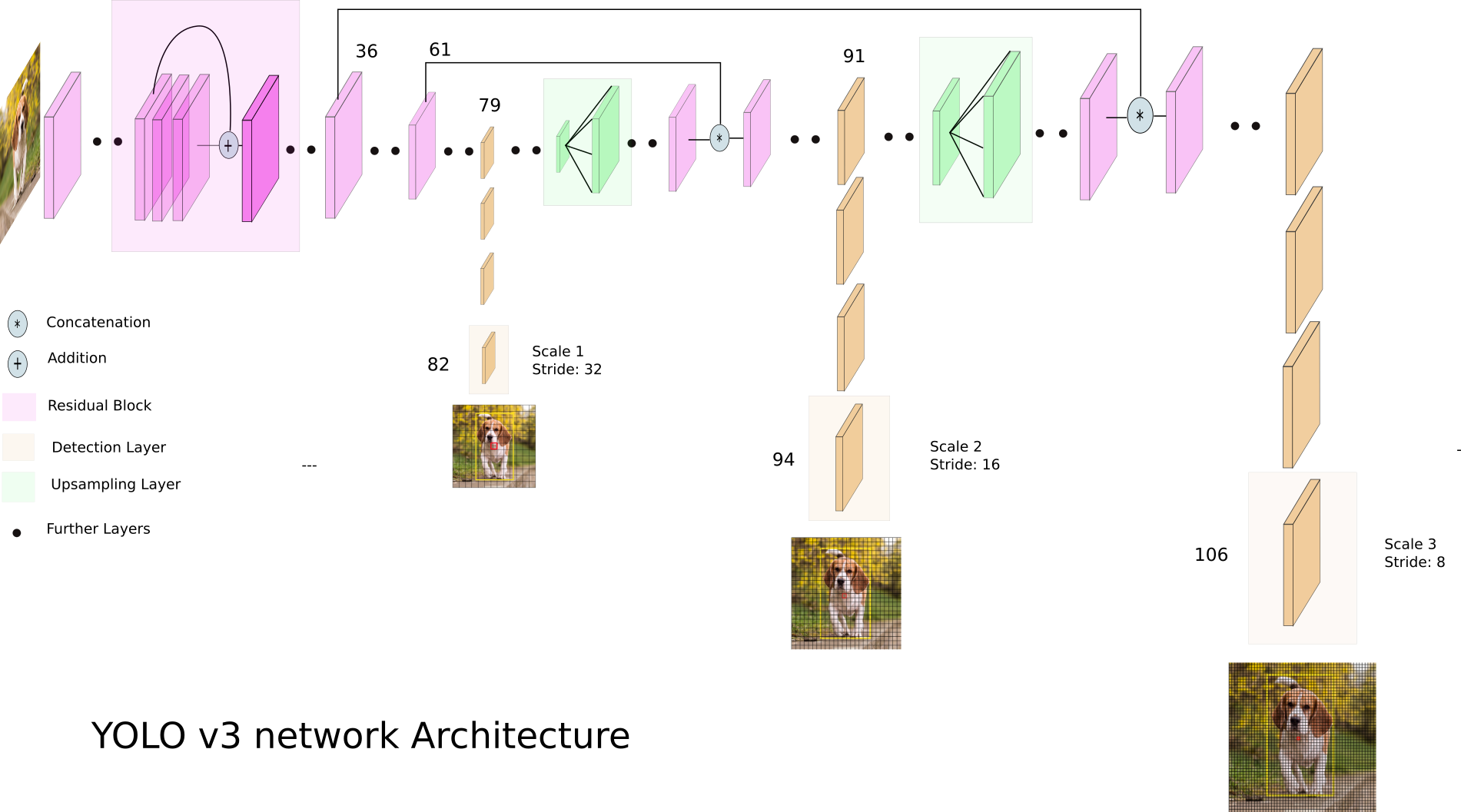
위의 그림은 전체적인 아키텍쳐입니다. 82, 94, 106번째 레이어들이 prediction feature map이구요. 총 3개의 피쳐맵을 이용하여 prediction을 합니다. 이때 각각의 피쳐맵에서는 욜로 v1, v2과 매우 흡사하게 bbox에 대한 정보와 class에 대한 정보를 학습합니다.
예를들자면 각각의 grid cell은 1개의 bbox 마다 x, y, w, h, o 를 포함하며 여기서 o는 object인지 아닌지를 나타내는 object score입니다. V3에서는 총 9개의 앵커박스를 사용하기 때문에
[x, y, w, h, o, x, y, w, h, o …. x, y, w, h, o, class1, class2…classN] 와 같은 값이 채널마다 담기게 됩니다.
즉, COCO데이터를 예로들자면, class의 개수가 80개 이기 때문에 각각의 channel에는 5*9*20개의 정보가 담기게 됩니다. 이러한 channel정보들을 갖는 grid cell로 구성된 grid map이 총 3개가 나오게 됩니다. 때문에 좀 더 스케일 강인한 디텍터를 설계할 수 있었습니다.
후기
욜로 저자는 괴짜인 천재라고 생각합니다. 특히나 V3같은 경우에는 일기쓰듯이 형식이 엉망으로 썼는데도 CVPR에 들어갔네요. 해당 리뷰를 작성하며 인터넷 소스들을 상당히 많이 활용했는데요. 블로그, 유튜브, 논문, 코드 등등 오픈소스가 많아서 이해하기에는 편했던거 같습니다. YOLO를 공부해보니 Object Detection이란 학문분야에 사용되는 컨셉들에 대한 이해가 좀 더 된거 같아서 좋았던거 같습니다. 사실 이번에 진행중인 프로젝트에서 v4를 사용하였었는데, AP가 25%까지 밖에 안오르는 버그가 있어서 해당 버그를 잡고자 좀 더 깊은 이해를 하기위해 yolo를 학습하게되었는데요. v1~v3에 대한 이해없이 처음부터 v4를 학습하는건 좀 무리가 있었던거 같습니다 .특히나 욜로시리즈는 너무 연관성이 많아서 v1부터 학습을 추천드립니다.
좋은 리뷰 감사드립니다.
박스 갯수 관련 질문이 있습니다. yolo는 7x7x11의 feature map을 가지고 예측을 한다고 하셨습니다. 그럼 최대 49개의 box에 대해 예측이 가능해보이는데 맞나요? 이에 대처하기 위해 다른 기법이 있을 거라고 생각합니다. 있다면 설명 가능할까요?
정확히는 클래스가 1개인경우의 yolo v1을 말씀하시는거라면 49*2개의 박스를 사용하고 1차적으로 49개로 걸러집니다. 그리고 다시 nms를 통해 2차적으로 걸러지고요. 그러나 여기서 1차에서 걸러지는 박스도 loss에 관여합니다. 그리고 다른 기법이라고하면 제가 리뷰에 작성해둔 yolo v3를 참고하시면 될거같습니다.
Multispectral pedestrian detection 에서 YOLO를 사용하시다보니 논문을 읽으신것 같습니다.
이와 관련해서 최근 Multispectral pedestrian detection 논문 공유드립니다.
Pedestrian Detection by Fusion of RGB and Infrared Images in Low-Light Environment
MAF-YOLO: Multi-modal attention fusion based YOLO for pedestrian detection
두 논문 모두 Miss-rate가 아닌 mAP로 평가하고있는데, 굉장히 성능이 높습니다……
화이팅..
오호 참고해보겠습니다.
안녕하세요 김형준 연구원님.
리뷰 흥미롭게 잘 읽었습니다.
덕분에 욜로의 초기 모델의 구조가 어떻게 설계되었고 변화되어 왔는지를 이해할 수 있어 좋았습니다. 추가로 욜로 v4 부터는 원저자가 아닌 자른 저자가 썼다는 것과 욜로 v1 이 ssd 보다 6개월 가량 먼저 나왔다는 점은 처음알게 된 사실인데 흥미롭네요!
질문 하나 드리자면. yolo v1 에서 하나의 그리드 셀에 대해 두개의 바운딩 박스를 최종적으로 예측하는 데요. 이는 다른 비율의 객체를 잘 찾기 위함인가요? 그리고 confidence loss를 구할 때 두 바운딩 박스에 대해서 gt와의 iou를 기준으로 구분짓고 모두 고려하는 이유도 궁금합니다.