논문소개
“Self-supervised” 를 간단하게, 이상적으로 설명하자면 무엇이 떠오르시나요?
바로 어느 이미지에든,어느 unbounded dataset에서든 배울 수 있어야 한다는 것 입니다.
해당 논문은 512 개의 GPU를 사용해 이상적인 상황처럼 random하고 uncurated 한 이미지들을 감독없이 학습하여 self-supervised의 가능성을 보였습니다. 논문의 final SEER(SElf-supERvised) 모델은 RegNetY로 B개의 데이터를 학습할 때 1.3B의 파라미터를 사용한다고 합니다. 매우 큰 모델을 매우 많은 랜덤한 데이터셋으로 감독없이 학습하는 것에 대해 실험을 한 해당 논문은 결과가 성공적이라면 앞으로 pretraining 분야에서 매우 큰 영향을 미칠것이며 많은 과정이 효율적이게 될것입니다. 해당 논문은 이러한 실험을 통해 제안하는 방법이 pretraining 기법으로써 효용성을 보였고 다양한 downstream tasks에서 Supervised ImageNet pretraing 보다 좋은 성능을 보였습니다.
방법론
우선 해당 논문에서는 모델 아키텍쳐를 1. 효율성과 작동 수준의 trade off 간 조화가 좋고 2. 모델 파라미터를 유동적으로 조절하기 쉬운 ResNet 기반의 모델을 사용하였으며, 큰 데이터를 빠르게 학습하기 위핸 SwAV를 self-supervised method로 사용하였다고 한다.
SwAV:
SwAV는 주석 없이 CNNs 모델을 학습시키는 online clustering 학습 방식이다. 이는 동일한 이미지의 다양한 변형을 같은 cluster로 학습시키면서 학습을 진행한다.
RegNetY:
data와 model 용량을 모두 증가시키는 것은 memory와 runtime 관점에서 효율적인 모델을 이용해야한다. RegNet은 이러한 목적에 부합하게 설계되어 해당 아키텍쳐를 기반으로 RegNetY를 디자인 하였다고 한다. RegNetY 는 기존 ResNet에 구조에 squeeze-and-extraction 구조를 덧붙여 ResNet의 performance를 개선했다. 모델의 디테일은 다음과 같다.
4 stage convnets의 deep (2, 7, 17, 1)
4 stage convnets의 widths (528, 1056, 2904, 7392)
총 parameter: 695.5M
8704개의 이미지를 6125ms로 작동하였으며 512개의 V100 GPU를 사용했다고 한다.
Main Results
- ImageNet 에 대한 finetunning 실험. Large scale(non-EU instagram images)로 pretrain한 모델을 ImageNet에 대해 finetunning 시킨 결과를 통해, 제안하는 pretrain 방식의 효용성을 보인다.
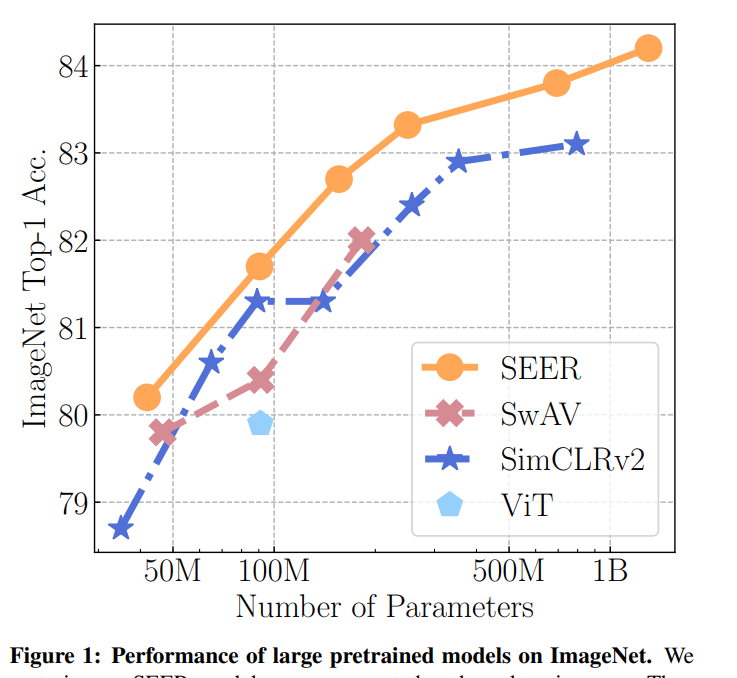
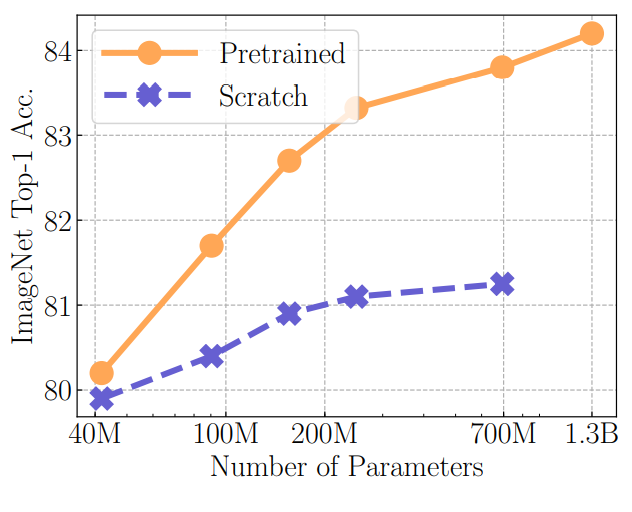
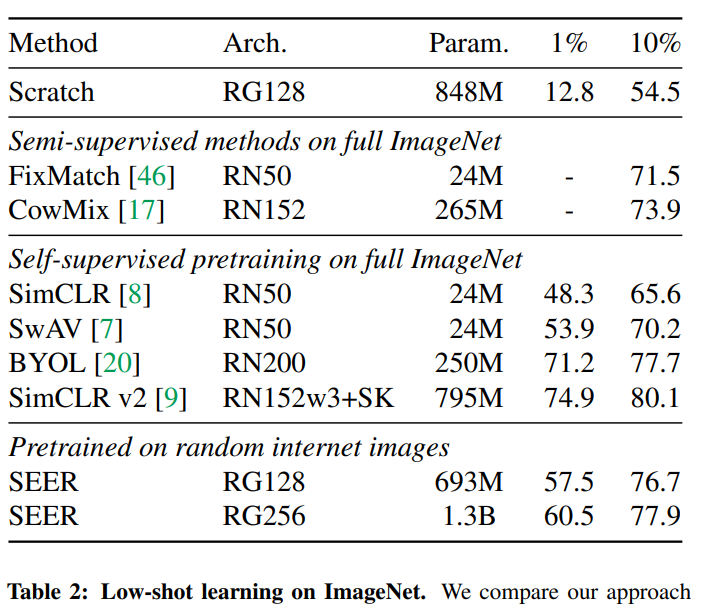
2. Low-shot learning. 논문은 제안하는 self-supervised 학습방식을 pretraining에 사용할 수 있을 뿐만 아니라 Low-shot learning 방식에서도 사용할 수 있음을 보인다.
Results on ImageNets.
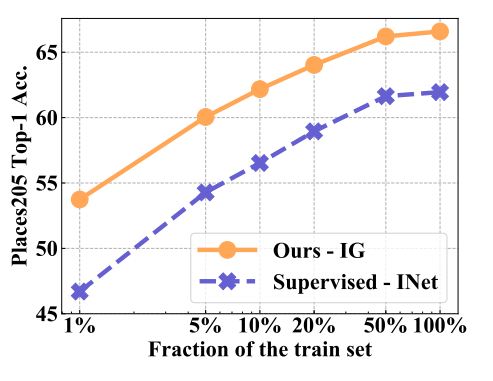
Results on Places205.
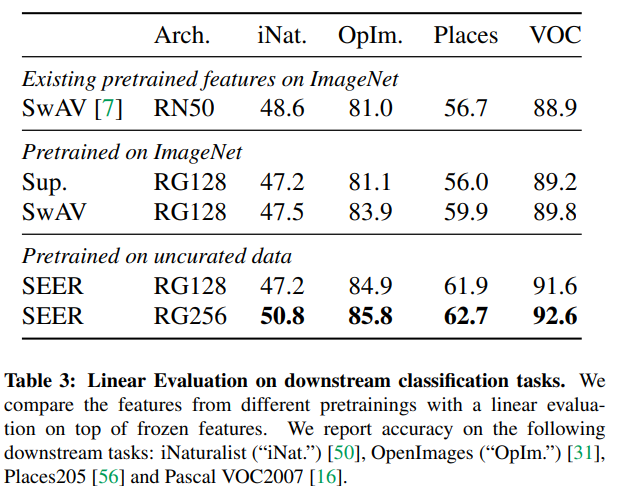
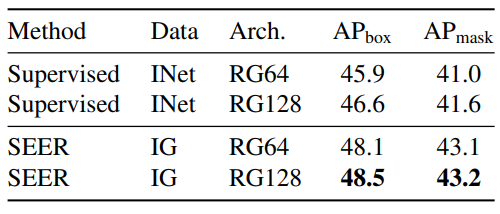
3. 다양한 Downstream Task에 적용. 다양한 Downstream Task에 적용하여 그 효용을 보였다.
결론
해당 논문은 annotation이 없는 random image에 대해서 pretraining 하는것이 모델 성능에 긍정적인 영향을 끼침을 보였고, 이를 통해 데이터 측면에서 효율적인 pretraining 방식을 소개하였다.