소개
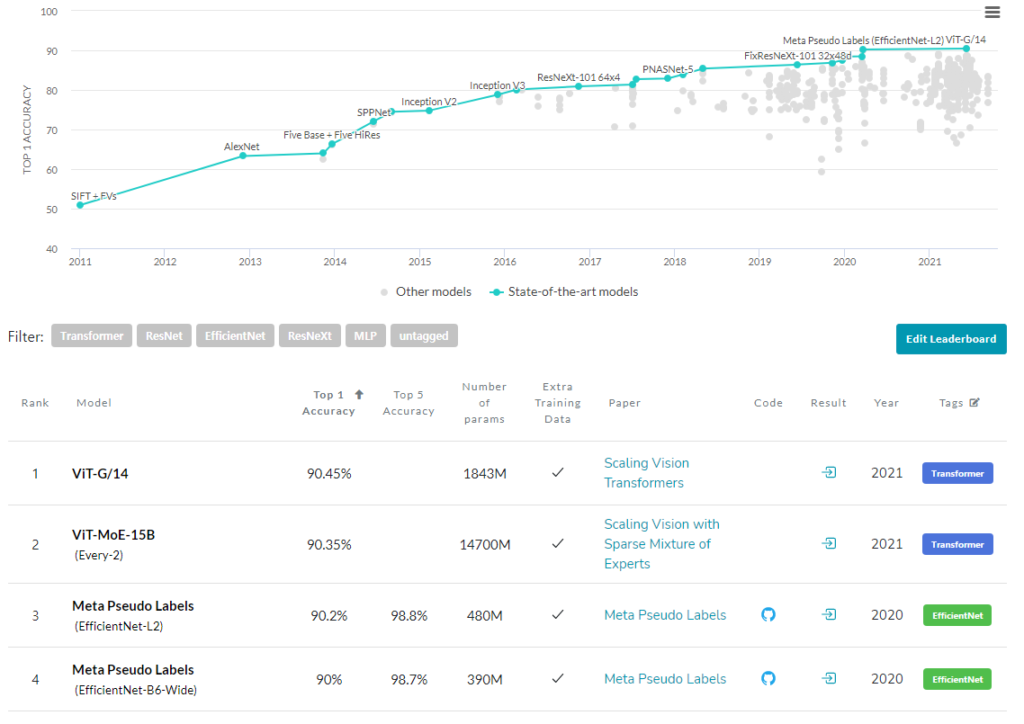
해당 논문은 새로운 semi-supervised learning 방식에 대해 소개한다. 해당 논문은 ImageNet에서 top-1 accuracy 기준 90.2%로 높은 성능을 보였으며 supervised learning 방식에 대적할 정도로 높은 성능임을 확인할 수 있다.
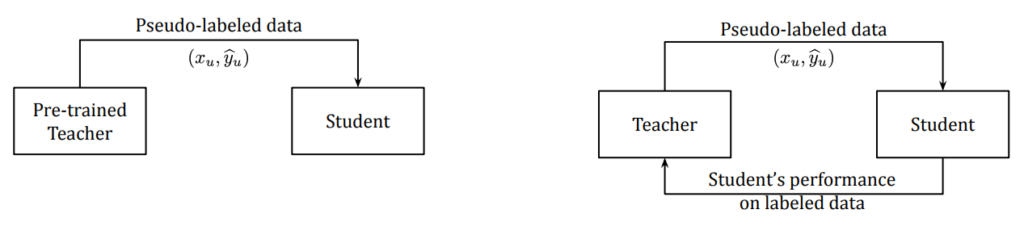
기존 Pseudo Labels 혹은 Self-Training이라고 불리는 학습방식은 주로 Label을 생성하는 Teacher model과 생성된 라벨로 학습하는 Student model로 구성됩니다. 이러한 학습 방식이 직면하는 문제점 중 하나는 Teacher model이 생성한 라벨이 잘못되었을 경우 student model의 학습이 제대로 이루어지지 않는다는 점이다. 기존의 모델은 한번 학습된 Teacher model이 업데이트 되지 않고 Pseudo 라벨을 생성하는데 사용되기 때문에 이러한 문제점은 학습 과정 중 개선되지 않는다. 제안하는 논문은 학습과정 중 업데이트되는 Teacher model을 설계하여 이러한 시스템적 문제를 해결한다.
방법
논문이 제안하는 self-learning 방식은 간단하다. 고정된 Teacher model을 사용했던 기존 방식과 달리 student model의 작동 성능을 reward로 받아 Teacher model을 업데이트 하는것이다. 업데이트 Loss는 다음과 같다. Student 모델은 Teacher 예측과 같은 예측을 하기 위해 다음과 같은 목적함수로 학습한다.
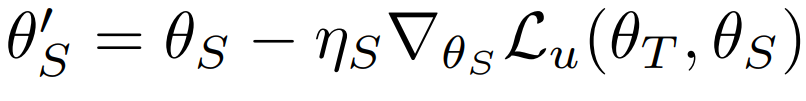
Teacher 모델은 student 모델의 업데이트식은 다음과 같다. Student 모델의 예측 정확도를 cross-entropy로 계산하여 이를 업데이트한다.
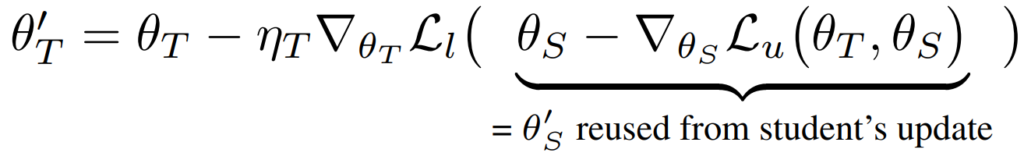
학습 순서는 다음과 같다. 우선 Teacher model을 Labeled data로 학습 한 이후, UDA objective를 이용하여 unlabeled data에 대해 학습을 진행한다. 마지막으로 student 를 unlabeled data와 생성한 pseudo label로 학습한다. 학습의 효과를 확인하기 위해 논문에서는 Small scale(CIFAR, SVHN) 실험과 Large scale(ImageNet) 실험을 모두 진행하였다.
실험
- TwoMoon
해당 실험은 다음과 같이 마주보는 달처럼 생긴 2D 데이터를 분류하는 간단한 실험으로 본 실험을 통해 Meta Pseudo Label(제안)과 Supervised Learning, Pseudo Label간의 작동을 비교하기 위한 실험이라고 한다.
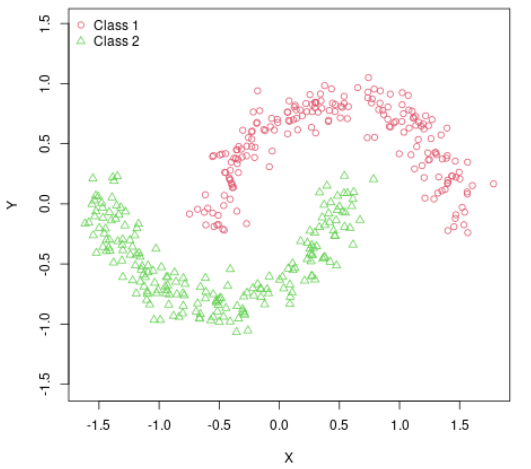
실험을 위해 2개의 은닉충을 가진 neural network를 설계하였으며 sigmoid 를 활성함수로 사용했다고 한다. 모델은 -0.1~0.1 값으로 초기화 되었으며 SGD를 이용해 learning late 0.1로 학습하였다고 한다. 아래의 결과를 보면 복잡한 Two-moon data에 대해서도 제안하는 Meta Pseudo Labels은 잘 분류함을 확인할 수 있다.

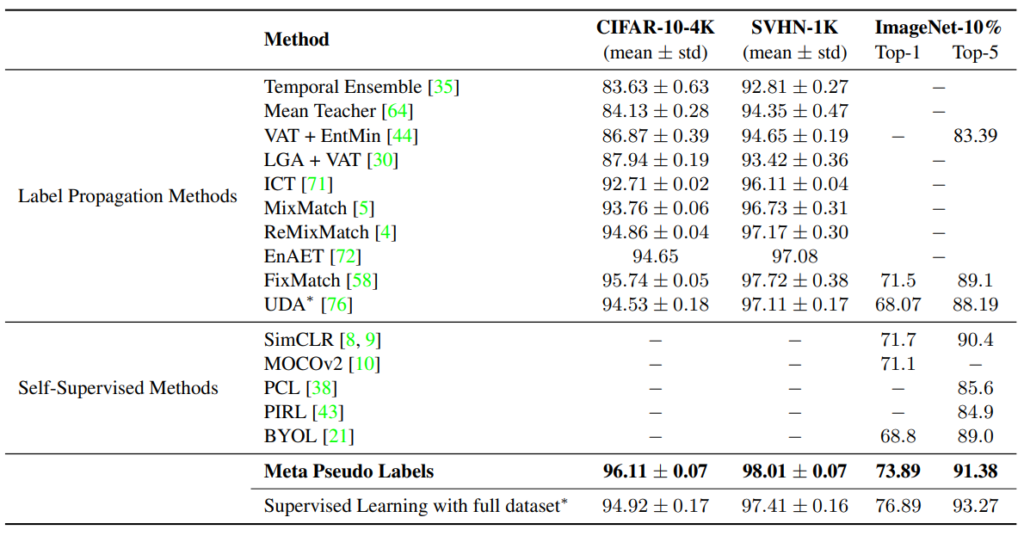
2. Various scale (CIFAR-10-4K, SVHN-1K, and ImageNet-10%)
32×32 사이즈의 CIFAR-10-4K, SVHN-1K데이터와 large scale(224×224)의 ImageNet데이터로 다양한 scale의 data benchmark에 실험을 보여주었다.
정리
해당 논문은 기존의 Self-supervised 방식처럼 학습된 Teacher 모델로 생성한 pseudo label을 이용하여 student model을 업데이트하는 방식이 아니라 Teacher모델 또한 student model의 feedback으로 업데이트하여, Teacher model이 잘못 학습되었을 때 이를 개선해 student model의 성능 향상으로 이어질 수 있도록 하는 새로운 학습 방식이다. 제안하는 방식은 low-resource benchmark에 대해서는 SOTA의 성능을 보였으며 ImageNet과 같은 큰 benchmark에서도 존재하는 semi-supervised 방식 중 가장 높은 성능을 보였다.