

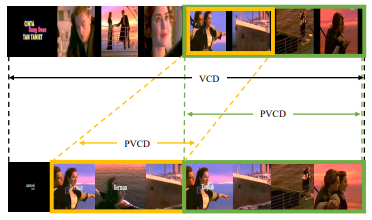
(VCD) and Partial Video Copy Detection (PVCD). VCD aims
to discover copy videos and PVCD focuses on localize both
video-wise and segment-wise copies
Video 시장이 커지면서 저작권 이슈도 많아졌으며, Copy를 탐지할 수 있는 Video-to-Video Retrieval(이하 V2V) 연구도 많아지고 있습니다. 그러나 현존하는 V2V 연구들은 frame-level의 feature를 활용하는 것이 video-level feature를 사용하는 것보다 좋은 성능을 보이며, 이는 다른 말로 frame-level에서보다 video-level에서 큰 비중을 차지하고 있는 temporal 정보가 feature에 잘 embedding 되지 않았음을 의미합니다. 오늘 리뷰하고자 하는 논문은 이러한 temporal 정보를 잘 반영하여 두 비디오 간의 유사도를 계산하고자, 두 비디오에서 유사한 부분인 PVCD(Partial Video Copy Detection) 중심의 embedding 방법을 제안합니다.
1. VIDEO SIMILARITY AND ALIGNMENT LEARNING (VSAL)
1.1 Problem Formulation
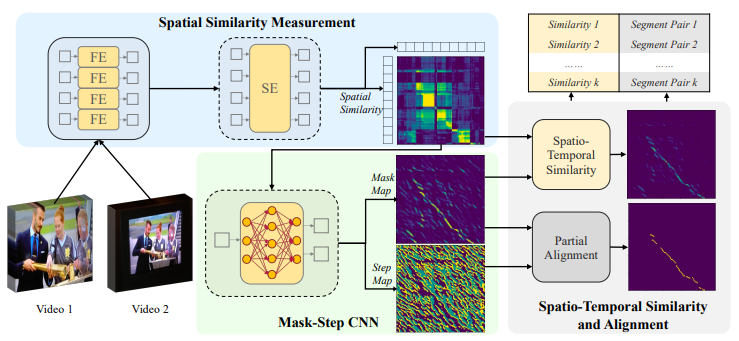
해당 논문에서 제안하는 방법을 설명드리기에 앞서 전제로 둔 비디오 간 유사도 측정 방식에 대해 설명하고자 합니다. 유사도를 측정하고자 하는 두 비디오 u, v의 길이가 각각 M, N (frame) 이라고 할 때, 두 비디오 간의 유사도는 식 (1)과 같이 총 세 가지의 요소로 측정됩니다. 여기서 S는 두 비디오에 속한 모든 프레임들을 각각 쌍으로 두어 프레임끼리 계산한 Spatial similarity를 의미하며, T는 각 비디오 프레임들 간의 정보인 Temporal similarity를 의미합니다. 그리고 P는 두 비디오 내의 서로 유사하다고 판단되는 영역을 나타내는 Partial Alignment를 의미하며 temporal segment라고도 불리웁니다. 그리고 만약 잘 매칭된 두 비디오의 유사도 맵을 구한다면(가로 축과 세로 축은 각 비디오의 프레임 인덱스를 나타냄), Fig 3의 첫 행과 같이 diagonal한 방향으로 직사각형이 나타나며 해당 영역을 Partial Alignment된 영역이라고 말합니다.
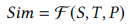
1.2 Spatial Similarity Measurement

우선 두 비디오 간의 유사도를 구하기 위한 요소 중 첫 번째로 S를 구하는 방법을 설명드리도록 하겠습니다. S는 하나의 scalar 값이 아닌 map으로 나타나며, map 내의 (i,j) 위치의 값은 u 비디오의 i번째 프레임과 v 비디오의 j번째 프레임 간의 유사도를 나타냅니다. 이는 s_{i,j}로 나타내며, 이를 구하기 위해 FE와 SE를 거치게됩니다. FE는 Feature Encoder를 나타내고 각 프레임 별로 feature를 추출합니다. Image retrieval 분야에서 global descriptor를 뽑는 것처럼 모든 프레임에 대해 feature를 추출한다고 생각하시면 됩니다. 이때 사용한 모델은 본 논문의 저자가 이전 논문에서 제안한 SVRTN_{f} 을 사용했다고 합니다. 비디오의 모든 프레임에서 feature를 추출한 뒤 SE를 거치게 됩니다. 이는 Sequence Encoder으로 프레임 feature 간의 interaction을 위해, 각 feature 간 self-attention 과정을 의미합니다. 이 같은 과정으로 두 비디오 u 와 v에서 각각 프레임 feature들을 추출하고 행렬 곱하여 S를 계산하게 됩니다.
1.3 Mask-Step CNN
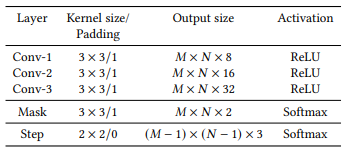
앞서 구한 S를 베이스로 T와 P가 계산됩니다. 이는 S를 세 개의 CNN layer로 구성된 backbone을 거친 후, Mask 와 Step 두 가지 branch를 거치며 각 layer는 Table 1 처럼 구성됩니다. 먼저 Mask branch의 output은 S와 동일한 크기인 M, N이며 각 원소 별로 해당 위치가 두 비디오의 유사한 부분인지 아닌지 판단하는 binary classification을 진행합니다. 해당 과정의 output인 mask map은 앞선 학습 방식으로 인해 temporal direction을 나타내기 때문에 Temporal similarity T로 사용된다고 합니다. 그리고 나머지 하나인 Step branch에서는 3 channel인 step map을 output으로 map 내의 각 원소별 진행 방향을 예측하는 classification이 진행됩니다. 이는 Fig 4와 같이 잘 매칭된 두 비디오 간의 유사도가 diagonal path를 갖기에, 이를 예측하는 하나의 task를 추가하여 전체적인 similarity 학습에 도움을 주기 위함입니다. 진행 방향은 오른쪽, 아래쪽, 대각선 우측 아래쪽과 같이 세 가지로 나누어 분류하게 됩니다. 위 두 가지 branch는 모두 self-supervised 방식으로 label을 생성해 학습하며, label을 만들 때는 특정 비디오와 그 비디오에 temporal & spatial transform이 적용된 비디오를 사용합니다. 이처럼 Self-supervised 방식으로 만들어진 label을 활용하여 BCE로 mask loss를 계산하고, CE로 step loss를 계산해 두 loss를 가중합한 multi-task loss를 두고 학습하게 됩니다.
1.4 Spatio-Temporal Similarity and Alignment

위에서 계산된 S와 T 그리고 mask map과 step map을 활용하여 두 비디오 간의 Partial Alignment를 계산합니다. 이는 Alg 1과 같이 계산되며 T의 원소 t_{i,j}가 일정 threshold \tau보다 클때부터 출발하여 1) boundary에 도달하거나 2) s_{i,j} t_{i,j}가 threshold \sigma보다 작은 경우가 세번이상 일때까지 keep 하고 조건에 도달하면 해당 위치를 k번째 Partial Alignment인 P_{k} 로 선정하게 됩니다.
앞서 구해진 S, T 그리고 P를 활용하여 비디오 간의 유사도를계산 하며 이는 식 (2)와 같이 P를 활용한 soft weight로 가중치를 주어 계산됩니다.
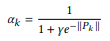
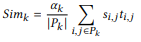
2. Experiments
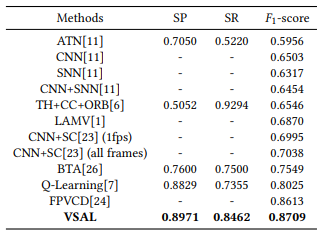
Table 2는 해당 논문이 제안한 방법론 VSAL의 VCDB 데이터 셋에서의 성능입니다. 평가지표로는 SP, SR, F1 score를 사용하였으며, SP는 Segment-level Precision, SR은 Segment-level Recall을 의미합니다.

Table 3는 본 논문의 또 다른 contribution인 FIVR-200K-PVCD 데이터 셋에서 평가한 Ablation Study 결과 입니다. FIVR-200K-PVCD는 FIVR-200K 데이터 셋에서 query와 relevant 비디오에 각각 temporal annotation을 한 뒤 제공한 데이터 셋입니다. 그리고 해당 표에서 HV는 제안된 patial alignment 방식이 아닌 Hough Voting 방식의 baseline이며 SE는 squential encoding, SW는 soft weight, SM은 step map, MM은 mask map을 의미합니다. 이를 통해 해당 방법론의 ablation 결과는 알 수 있으나, 다른 방법론과의 비교가 없는점이 아쉬웠습니다. 또한 원래 FIVR-200K 데이터 셋의 비교를 위해 mAP 지표를 사용하는데 해당 지표로 판단하지 않은 것도 아쉬웠으며, SP와 SR은 Localization과 Retrieval을 동시에 고려한 지표이기때문에 제안된 Patial Alignment 방식의 localization 성능만을 따로 비교하기위해 Action Proposal 분야에서 사용하는 AR@N으로 평가하는 것도 필요하지 않았나라고도 생각되었습니다.
3. Reference
[1] https://arxiv.org/pdf/2108.01817.pdf